
Joined April 2026
- Tweets 32
- Following 14
- Followers 584
- Likes 221
10 Photos and videos








Pinned Tweet

May 11
Launching Cacheon: an open, incentivized competition for LLM inference optimization.
As model quality converges, the next frontier is serving them economically at scale: lower latency, higher throughput, and lower cost per token.
Cacheon turns that problem into a live arena with continuous evaluation. Developers submit containerized inference servers, benchmarked on standardized hardware against a pinned vLLM baseline. The fastest server that preserves output correctness wins.
The goal is to make better inference systems discoverable, measurable, deployable, and rewarded in the open.
Mainnet launches by May 19. Learn more: cacheon.ai
47
39
183
42,226
Jun 11
We just merged our first-ever community PR from a miner! 🤝
It makes our evaluation fairer. Miners can use any tokenizer without getting penalized. If your output is right, you pass. Simple as that.
github.com/latent-to/cacheon…
2
3
16
1,323
Jun 7
Cacheon docs are now agent-ready.
On every doc page:
• Open in Claude, Cursor, or ChatGPT
• or Copy Markdown
For grounding:
• cacheon.ai/llms-full.txt
• Per-page markdown URLs
As more development workflows move from browsers to agents, documentation needs to be optimized for both humans and machines.
1
3
21
7,320
Jun 5
Cacheon paid out its first miner incentives on Tuesday.
Here's how it works: miners earn when they beat vLLM in eval. One miner did exactly that. Got rewarded. Then on the next run, their score dropped below the baseline, so emissions went back to burn.
No one is being held back. Beat vLLM consistently, earn consistently. Miss a run, miss the reward. Variance is real. A single fast run does not lock in your position.
Full details: cacheon.ai/docs/evaluation/s…
1
13
729

It was a strong signal that even though $TAO was just a track of @proofoftalk, it felt like the main event. The vibes were immaculate
Awesome catching up with old friends and and finally put faces to many of the names we've been building alongside online.
Jun 4

The energy around @Bittensor at @proofoftalk was exceptional.
We had great conversations with old friends and made plenty of new ones across the ecosystem.
People are no longer asking whether Bittensor can attract builders. They're asking how subnets will take market share, generate revenue, and build sustainable advantages over centralized AI firms.
The ecosystem feels materially different than it did a year ago: more serious teams, stronger infrastructure, more capital, and significantly higher conviction.
Came away more bullish than ever on SN14 Cacheon and the broader Bittensor space.
Still a long road ahead, but the momentum is undeniable. Hopefully more good news in the coming weeks.
1
4
51
2,112
Jun 4
The energy around @Bittensor at @proofoftalk was exceptional.
We had great conversations with old friends and made plenty of new ones across the ecosystem.
People are no longer asking whether Bittensor can attract builders. They're asking how subnets will take market share, generate revenue, and build sustainable advantages over centralized AI firms.
The ecosystem feels materially different than it did a year ago: more serious teams, stronger infrastructure, more capital, and significantly higher conviction.
Came away more bullish than ever on SN14 Cacheon and the broader Bittensor space.
Still a long road ahead, but the momentum is undeniable. Hopefully more good news in the coming weeks.
2
5
55
3,099
Cacheon retweeted

Jun 3
Pure talent … bittensor @proofoftalk
@btlabs_ai @LeadpoetAI @minotaursubnet @gradients_ai @4RayL @cacheon_ai @Darren_Yeah_ @fadebitman @innovativeshane @josercaldera

4
11
79
2,045
May 31
Cacheon competition restarts June 1. What we overhauled this week:
- One-pass eval: speed correctness on the same prompts, same outputs
- Single metric: end-to-end wall time vs baseline (no TTFT / TPS split)
- Improved logging and telemetry
- Emissions ramp up after June 8
- Conviction lock soon
Inference is the compute layer everything runs on. Open competition is how we surface the best. Miners, show us what you've got. 💪
Read more: cacheon.ai/docs
2
4
23
1,435
May 25
We shipped two things over the weekend: a 0.1 TAO miner submission fee and @shadeformai GPU support.
Submission fee: Every on-chain commit now costs 0.1 TAO. Goal is to cut spam and add skin in the game. Fee covers GPU rental first; anything left buys SN14 tokens and burns it. Miner workflow is unchanged. Docs: cacheon.ai/docs/miners/regis…
Shadeform GPUs: Validator can now pull GPUs from Shadeform alongside @TargonCompute and @lium_io
for evaluations. More supply, less wait time.
Updates on evaluation upgrade coming later this week. Follow our Bittensor Discord channel for ongoing discussions.
1
6
26
1,643
May 20
🚀 Preparing our CoinGecko update request for Cacheon / SN14.
🔗 GeckoTerminal URL:
geckoterminal.com/bittensor/…
Telegram contact: @xavierlyu
2
12
957
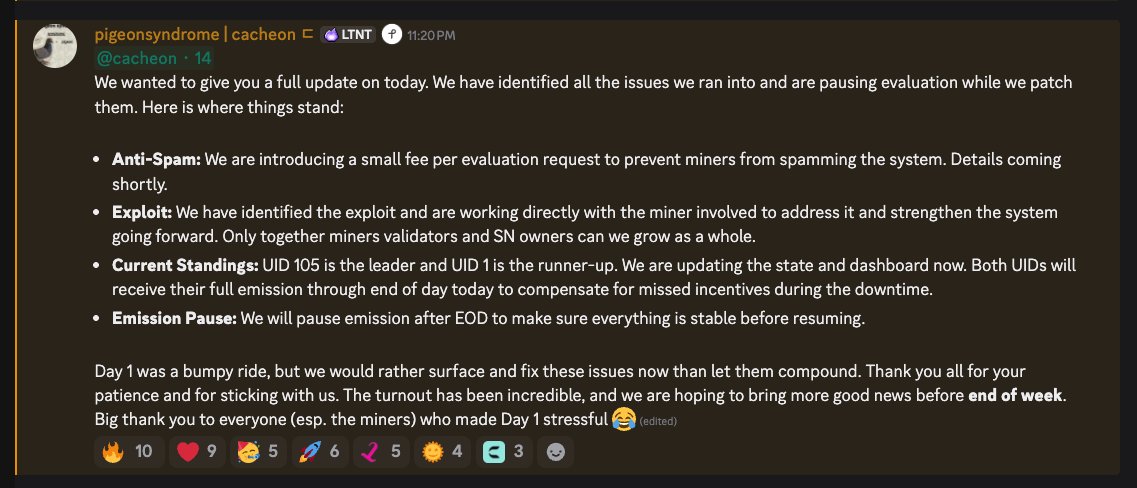
Day 1 of @cacheon_ai is in the books. Stressful? 100%
We shipped, broke things, and found multiple exploits. All in one day.
That is how it is supposed to go. We are building the infrastructure that makes inference competitive with centralized providers. That is not a small problem. You do not find the real edges until real miners are running real models on a live subnet. We found them fast and want to patch them even faster.
Day 1 stress means people care enough to try to break the system. That is what makes this product stronger.
Evaluation and emission are paused until the fixes are in. More updates before end of week.
To every miner who stayed in and flagged issues: thank you!
1
4
30
2,158
Didn't expect 40 miners on testnet.
People ran real inference servers for nothing but early positioning. That kind of participation before any reward is on the table tells you something.
To every testnet miner: you built this community before it had a dollar attached. That's why I'm confident @cacheon_ai mainnet will work!
May 19
Cacheon mainnet is live.
13 inference servers queued, each racing to beat our baseline on a dedicated 8x H200 pod.
The winner earns up to $10,000/day. Inference optimization starts today on @Bittensor.
Follow along: cacheon.ai/dashboard
2
35
2,655
May 19
Cacheon mainnet is live.
13 inference servers queued, each racing to beat our baseline on a dedicated 8x H200 pod.
The winner earns up to $10,000/day. Inference optimization starts today on @Bittensor.
Follow along: cacheon.ai/dashboard
6
29
87
26,409
May 17
Back-to-back kings crowned in a single eval run on Cacheon testnet. UID 11 took the crown, then UID 20 snatched it minutes later.
Scores are still very small since miners are mostly tuning vLLM defaults. The real jump comes when someone ships actual KV cache reuse, better prefill optimizations, or speculative decoding (V2). That's what this subnet is built for. Keep pushing. 🚀
Early dashboard live at cacheon.ai/dashboard. Still a very early version with some rough edges. The site is also open source at github.com/latent-to/cacheon… and we welcome contributions.
1
3
22
1,547
The OpenReview thread on TurboQuant vs RaBitQ is worth reading:
– prior work (RaBitQ) not properly addressed, missing apples-to-apples comparison
– RaBitQ author flagged it; still not clearly resolved
– disputed benchmark setup: RaBitQ on Python single-thread CPU vs TurboQuant on H100
Makes you question how much of the “KV cache gains” are actually real. This optimization space needs stricter evals.
Mar 27

The TurboQuant paper (ICLR 2026) contains serious issues in how it describes RaBitQ, including incorrect technical claims and misleading theory/experiment comparisons.
We flagged these issues to the authors before submission. They acknowledged them, but chose not to fix them. The paper was later accepted and widely promoted by Google, reaching tens of millions of views.
We’re speaking up now because once a misleading narrative spreads, it becomes much harder to correct. We’ve written a public comment on openreview (openreview.net/forum?id=tO3A…).
We would greatly appreciate your attention and help in sharing it.
1
1
15
2,918
May 14
Had an awesome conversation with @SubnetSummerTAO about what we’re building.
Perhaps @xavi3rlu was a bit too pumped about it, but the core idea is simple: make LLM serving faster, cheaper, objectively benchmarked, and production-deployable.
May 14

🔥 Subnet Summer AMA X @cacheon_ai (Subnet 14) 🔥
@xavi3rlu is building a decentralised inference competition network for open-source AI models, Cacheon is Subnet 14 on Bittensor, creating a permissionless benchmarking system to power the next generation of fast, accurate, and trustless AI inference infrastructure. In this episode, we sit down with the team behind Cacheon, a decentralised inference performance subnet built on Bittensor.
We cover:
- What Cacheon is building and why containerised inference competition matters for the future of open-source AI
- How miners compete by submitting Docker-packaged inference servers optimised for speed and correctness when serving open-source models
- Decentralised validation: how validators benchmark and score miner submissions in real time to ensure outputs meet quality and performance standards
- Cacheon vs centralised inference providers and why the future of model serving should be open, permissionless, and economically incentivised
- The role of token incentives in driving continuous performance improvements and attracting world-class inference engineers to the network
- How Cacheon is pushing the boundaries of what decentralised compute can deliver for AI applications at scale
- Early progress, current network stats, and what's coming next
- Roadmap toward becoming the go-to decentralised inference layer for open-source model deployment
- Live community Q&A
If you're interested in decentralised AI, open-source model serving, GPU compute, or the future of inference infrastructure - this one's for you.
youtu.be/noKx3ZHvUlI?si=Bl5W…
1
3
30
2,551
May 14
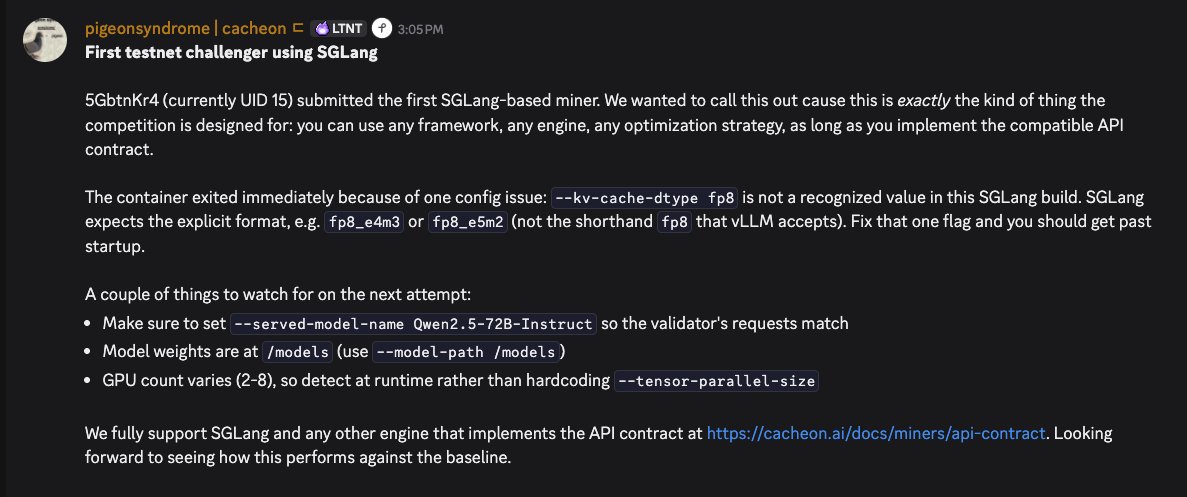
The first SGLang-based miner hit testnet (5GbtnKr4, UID 15)! This is exactly what Cacheon is designed for: bring any language or framework you want, as long as you match the OpenAI-style API we document (/health, streaming chat completions, logprobs, etc.).
6
13
54
7,012
May 14
Their container exited at startup: --kv-cache-dtype fp8 is not a valid choice in that SGLang build. Use fp8_e4m3 or fp8_e5m2 instead. Also align --served-model-name and --model-path with the contract, and avoid hardcoding tensor parallel size (pod GPUs vary).
Hope to see a resubmit.
cacheon.ai/docs/miners/submi…
1
440
Cacheon retweeted

May 13
🚨 The most overlooked problem in AI right now, and how $TAO's SN14 @cacheon_ai just turned it into a competition.
Everyone is racing to build bigger models. The real meltdown is in serving them.
We are obsessed over model training. Who has the biggest model. Who has the most parameters. Who scored highest on the latest benchmark. That's the Formula 1 race car.
But there is something else once you build the car. Have to drive it, service it, and have a race strategy.
That's inference. It's where AI actually meets reality. That’s the Real Problem
Every time you ask ChatGPT a question. Every time Claude responds. Every time an AI agent acts. There's a machine somewhere doing the work of generating that answer. That machine is slow, expensive, and largely invisible to the user until it isn't.
When you wait 8 seconds for a response. When an API call costs 10x what it should. When an enterprise AI workflow grinds to a halt under load. That's inference failing.
Anthropic just secured massive compute capacity from SpaceXAI's Colossus 1 data center just to keep Claude running. Even the most advanced labs in the world are fighting for the infrastructure to serve their own models. That's how broken this layer is and what many miss.
SN14 is open competition of that peoblem
Cacheon picks one fixed open source model Qwen2.5-72B-Instruct and asks one question:
Who can serve it faster?
Miners build their own inference servers. Any language. Any framework. Custom CUDA kernels. FlashAttention. PagedAttention. Whatever optimization they can dream up. They package it in a Docker container and submit it on-chain
Validators pull every submission and run it on identical hardware against a vLLM baseline
They measure two things:
• Time-to-first-token (how fast the first word arrives)
• Throughput (how many tokens per second the system can produce).
But here's the genius of the design fast is not enough. Correct wins.
If your server is 3x faster but generates wrong outputs, you score zero. The correctness gate runs first. Only then does speed matter. This stops the obvious gaming where someone cuts corners on quality to win on speed.
Fastest correct server becomes the King. Takes 100% of emissions up to 33 $TAO per day until someone beats them. Mainnet launches May 19.
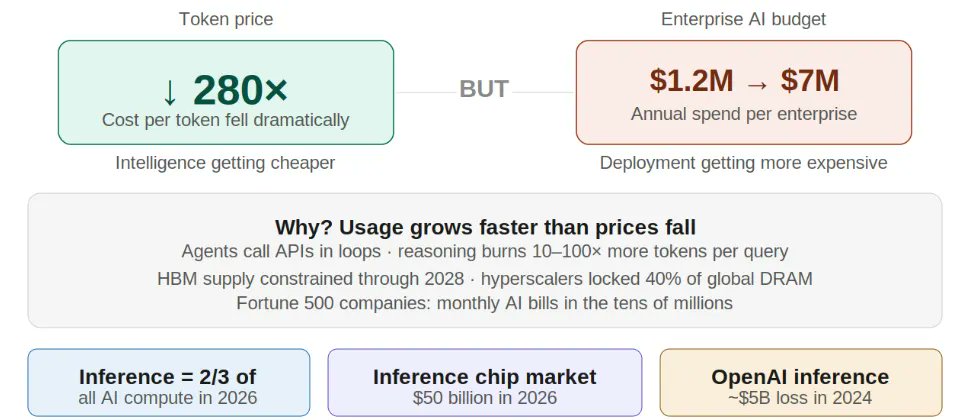
The AI industry has converged. GPT, Claude, Gemini, Grok, the quality gap is closing. What separates products now isn't raw intelligence. It's the experience of using them. Speed. Cost. Reliability. The pit crew, not the race car.
A model that responds in 800ms feels alive. The same model at 4 seconds feels broken. The difference between a viable AI agent and an unusable one is often just inference performance.
This work happens behind closed doors. OpenAI optimizes their stack privately. Anthropic optimizes theirs privately. Google does the same. None of those optimizations ever reach the open-source models the rest of the world actually uses.
Every technique public improvements measurable. The best one wins, gets paid, and becomes the new standard.
Team is legit @xavi3rlu (ex-Opentensor), Clément Blaise, Dera Okeke, with @KibibyteMe advising. First testnet already ran: miners submitted, failed startup requirements exactly as designed.
Roadmap looks good:
▫️V1: Beat vLLM on one model
▫️V2: Speculative decoding, quantization, concurrency
▫️V3: Winning servers become real production endpoints with actual traffic and revenue
▫️V4: Multi-model OpenRouter integration
Take the layer centralized AI handles worst (inference), open it up, and let the market discover the best solution through competition.
Anthropic just paid SpaceX for inference capacity. Cacheon is building the version where the best optimizations rise continuously and stay open.
While intelligence is getting cheaper, deploying it is becoming more expensive. SN14 is infrastructure.
$TAO
DYOR
🔗
cacheon.ai
cacheon.ai/docs



May 11
Launching Cacheon: an open, incentivized competition for LLM inference optimization.
As model quality converges, the next frontier is serving them economically at scale: lower latency, higher throughput, and lower cost per token.
Cacheon turns that problem into a live arena with continuous evaluation. Developers submit containerized inference servers, benchmarked on standardized hardware against a pinned vLLM baseline. The fastest server that preserves output correctness wins.
The goal is to make better inference systems discoverable, measurable, deployable, and rewarded in the open.
Mainnet launches by May 19. Learn more: cacheon.ai
2
16
53
4,556