
Joined October 2025
- Tweets 1,285
- Following 265
- Followers 2,531
- Likes 2,824
203 Photos and videos












Pinned Tweet
📢 Subnet Summer TAO X Spaces - JUNE 12, 2026
| 6:00 PM BST
Topic: Key Takeaways from Proof of Talk
@proofoftalk delivered some of the most significant discussions and announcements in the AI and Bittensor ecosystem. From major subnet developments and industry insights to the introduction of new subnets entering the network, the event highlighted the rapid evolution of decentralised AI.
Join us this Friday as we break down the most important takeaways from Proof of Talk, discuss what they mean for the future of Bittensor, and hear directly from emerging teams preparing to launch within the ecosystem.
Speakers:
▫️Mark Jeffery (@markjeffrey ) - Stillcore Capital
▫️Jose Caldera (@josercaldera ) - @yanez__ai | SN54
▫️Chris Zacharia (@macrozack ) - Bitstarter
▫️Will Squires (@WSquires) - Macrocosmos
▫️Lanyard (@tsliceAI) - @minotaursubnet | SN112
New subnet team:
▫️@DeSciClaims
▫️@provenonce_ai
We'll also be featuring two new subnet teams that will soon be joining the Bittensor ecosystem, sharing their vision, goals, and what they plan to contribute to the network.
Whether you're a miner, validator, builder, investor, or simply curious about the future of decentralised AI, this is an opportunity to hear directly from the people shaping the next phase of Bittensor
Set your reminder and join the conversation.
2
12
46
5,116
Subnet Summer retweeted
Bittensor is about to have its Bitcoin moment.
Jun 13

The US government, citing national security authorities, has issued an export control directive to suspend all access to Fable 5 and Mythos 5 by any foreign national, whether inside or outside the United States, including foreign national Anthropic employees.
The net effect of this order is that we must abruptly disable Fable 5 and Mythos 5 for all our customers to ensure compliance.
Access to all other Claude models is not affected.
We apologize for this disruption to our customers. We believe this is a misunderstanding and are working to restore access as soon as possible.
Read our full statement: anthropic.com/news/fable-myt…
11
19
138
3,817
Subnet Summer retweeted

Presumably, so long as there are network participants, it would be roughly equivalent to trying to exterminate all ants on planet earth. Good luck.
9
16
117
4,578
2026 is going to be our year.

Access to intelligence should not depend on a handful of companies or governments.
This is why open, decentralized, permissionless AI matters.
This is why Bittensor matters.
2
21
571
For many people, government control over money was the event that flipped the switch for Bitcoin.
It wasn’t just about technology. It was the realization that access to a critical system could be controlled by a small number of institutions.
AI may be approaching a similar moment.
When access to frontier models can be restricted overnight by a single decision, it highlights how concentrated AI infrastructure has become.
The answer isn’t one company building a bigger model.
The answer is a confederation of open-source AI companies, researchers, developers, and networks working together on shared infrastructure.
This is what makes Bittensor so compelling.
Rather than concentrating intelligence within a handful of organizations, Bittensor enables independent AI businesses and subnets to collaborate, compete, and innovate on a decentralised protocol with aligned incentives.
Just as Bitcoin transformed the conversation around who should control money, decentralized AI is beginning to transform the conversation around who should control intelligence.
The future of AI should be open, permissionless, and globally distributed.
Jun 13
The US government, citing national security authorities, has issued an export control directive to suspend all access to Fable 5 and Mythos 5 by any foreign national, whether inside or outside the United States, including foreign national Anthropic employees.
The net effect of this order is that we must abruptly disable Fable 5 and Mythos 5 for all our customers to ensure compliance.
Access to all other Claude models is not affected.
We apologize for this disruption to our customers. We believe this is a misunderstanding and are working to restore access as soon as possible.
Read our full statement: anthropic.com/news/fable-myt…
5
29
963
Subnet Summer retweeted

Jun 12
Best keynote. Best quote. Bittensor MVP. Biggest surprise. Newbie of the Year.
Full @proofoftalk roundup from TAO Times - plus a 2027 wishlist that starts with AC and ends with JJ 👇

2
5
14
797
Subnet Summer retweeted

Jun 12
Subnet 111. Live on #Bittensor ⚡
Science has a credibility problem.
Papers get published. Results can't be replicated. Nobody gets held accountable.
Claims is changing that - using Bittensor to score, verify and surface research that actually holds up.
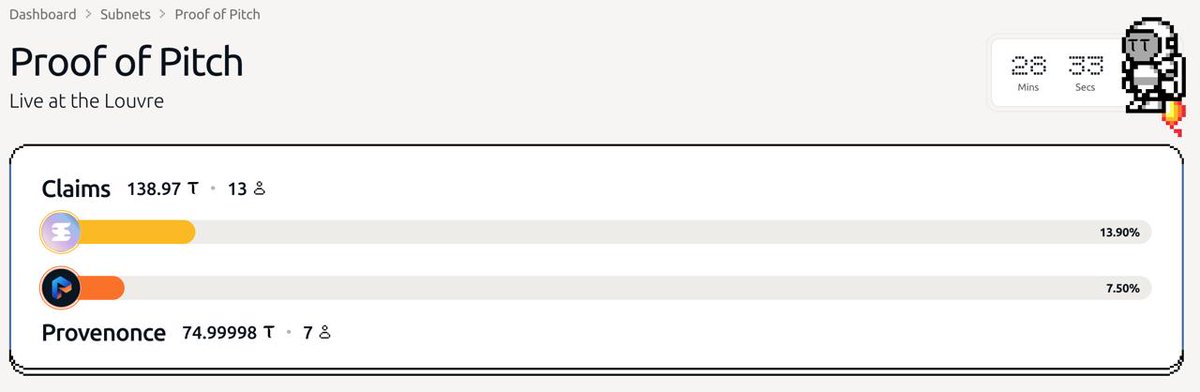
Led by Prof. Philipp Koellinger [ @PKoellinger ] and Prof. Christian Roessler: 17,000 citations. Published in Nature and Science. Game theorist specialising in mechanism design. Built @DeSciLabs to improve research incentives.
They won Proof of Pitch. They impressed the judges. They earned the community.
Now they get a subnet.

5
11
58
3,598

Jun 12
We’re live now!
Join in 👇
Jun 10

Set a reminder our upcoming Space:
Key Takeaways from Proof of Talk
x.com/i/spaces/1nGeLLkpaLbKX
1
9
547
Subnet Summer retweeted

Jun 12
Train at Home has seen significant speed improvements in our recent runs over the past few days.
This benefit comes directly from our Orion-100B pretraining run. By working with a model of this magnitude, using IOTA’s underlying architecture, we’ve learned practical lessons about where to optimize and tweak our TAH codebase.
To see for yourself, take a look at the cyan lines on our charts, showing one of our later runs. The results are especially clear when looking at our Tokens Per Second (TPS), indicating that training is happening faster over time, and our Model FLOP Utilization (MFU), revealing greater hardware efficiency.
This is how Project Orion begins to meaningfully impact all our work on IOTA.

1
10
47
1,836
Jun 12
⏰ 5 Hours Left!
Subnet Summer X Space starts today at 6:00 PM BST.
We're diving deep into the biggest highlights from the recently concluded Proof of Talk (@proofoftalk) 2026 Summit at the Louvre Palace, Paris.
Missed POT? This is your perfect catch-up session.
Our speakers will be sharing exclusive insights, key takeaways, and important updates from across the Bittensor ecosystem.
🔥 Special Announcement
@macrozack (Founder of @bitstarterAI) has confirmed that the official subnet number for @DeSciClaims will be revealed live during this Space.
🎙️ Speaking Order:
▫️ 1st — @markjeffrey (Stillcore Capital)
▫️ 2nd — @josercaldera (SN54)
▫️ 3rd — @macrozack (Bitstarter)
— @DeSciClaims & @provenonce_ai
▫️ 4th — @WSquires (Macrocosmos)
▫️ 5th — @tsliceAI (SN112)
This is shaping up to be one of the most important X Spaces in the Bittensor ecosystem today.
Don't miss it.
Set your reminders now → 6:00 PM BST
See you there!
1
15
51
4,285
Jun 12
Jun 10
Set a reminder our upcoming Space:
Key Takeaways from Proof of Talk
x.com/i/spaces/1nGeLLkpaLbKX
3
372
Subnet Summer retweeted

Jun 12
Bittensor >> Bitstarter
See you later today for the next @SubnetSummerTAO Spaces.
The community is eagerly waiting for one announcement in particular:
🤝 The reveal of the subnet number assigned to @DeSciClaims .
Bitstarter will be joined by Philipp Koellinger from Claims to unveil the subnet live during the show.
We'll also hear from @willobrien , founder of @provenonce_ai , who will share his vision and plans for the project's launch.
Also joining the discussion:
• @markjeffrey
• @josercaldera
• @WSquires from Macrocosmos
All hosted by Bittensor @SubnetSummerT .
After weeks of speculation, theories, and debates about which slots might be assigned to the Proof of Pitch finalists, we're finally about to get some answers.
Who got it right?
We'll find out in a few hours. 👀🍿

1
5
21
1,297
Subnet Summer retweeted

Jun 11
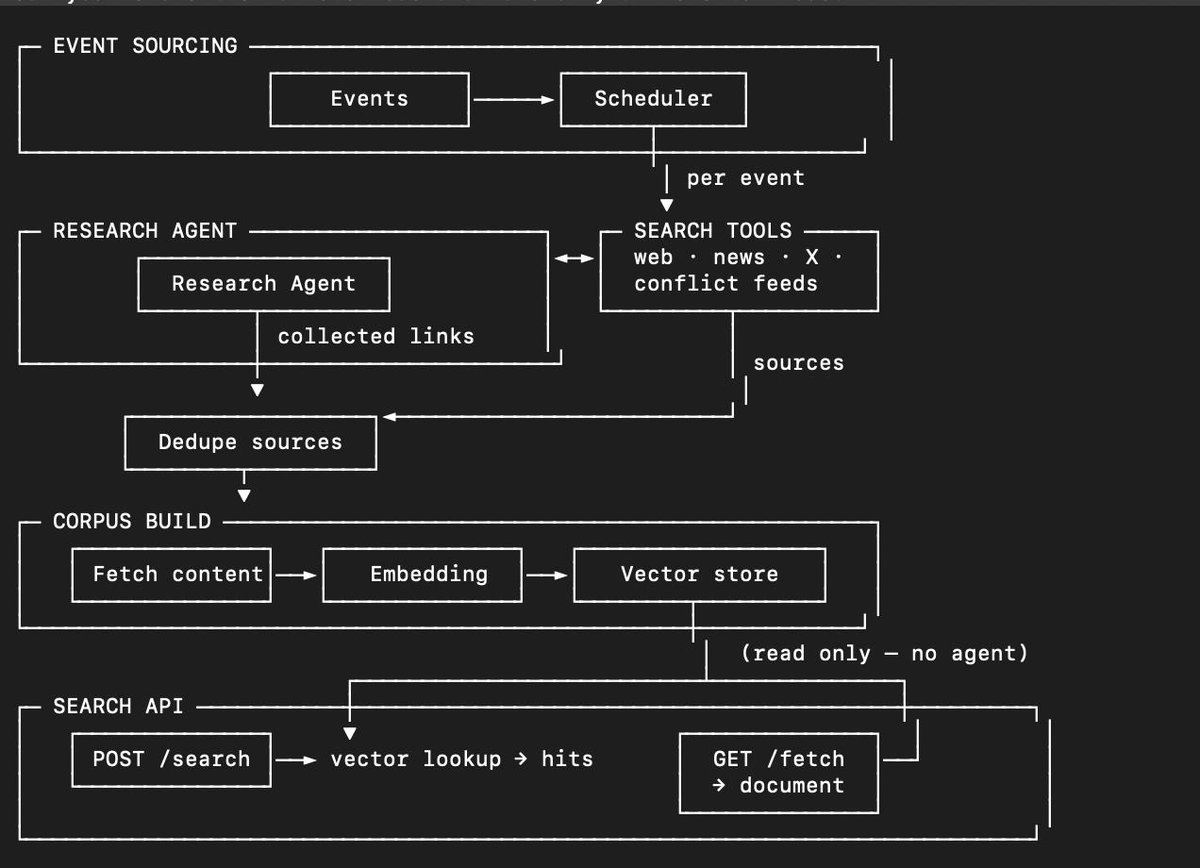
Our backtestable search endpoint is now live for Numinous miners.
The endpoint integrates Numinous news sources, RSS feeds, geopolitics live data, base rates, and broader agentic retrieval into a growing research corpus.
This gives miners a stronger foundation for building forecasting agents on the subnet.
It also makes miner outputs easier to backtest, validate, and integrate into Numinous meta-models.
In the coming days, this search endpoint will become the required way to retrieve data on the subnet, making miner agents truly backtestable.
Search:
eversight.numinouslabs.io/do…
Fetch:
eversight.numinouslabs.io/do…
Jun 5

A major upgrade is coming for miners on Subnet 6.
This Monday, we are releasing a backtestable search endpoint for Numinous miners.
Forecasting agents need more than live search.
To evaluate complex agent configurations over long horizons, miners need access to historical information exactly as it would have been available at the time.
That is the problem this endpoint solves.
A swarm of agents continuously researches our forecasting questions, finds relevant news, base rates, and contextual data, then stores that information in a queryable corpus.
This creates a historical search layer with hundreds of thousands of links available to Numinous miners.
Miners can take the code of a top agent, run it across several months of prior questions, and evaluate performance with statistical significance instead of waiting weeks for live events to resolve.
Live scoring remains the core of the subnet.
But backtesting gives miners and us a faster way to test architectures, compare configurations, and improve forecasting systems without leaking future information.
Forecasting agents need memory.
Now Numinous miners get a backtestable one.
1
10
33
1,639
Subnet Summer retweeted

Jun 11
Quasar is entering its next chapter on Bittensor SN24.
We are moving toward a 10T-token decentralized training run.
The idea is simple Quasar Models needs more useful training, not just bigger parameter counts.
Real model quality comes from tokens, data quality, training direction, and the ability to keep improving checkpoint by checkpoint.
This run starts with a 5T-token phase to produce a stronger checkpoint, then continues into another 5T-token phase, reaching 10T total trained tokens.
SN24 will set the direction:
the starting checkpoint, the data, the training recipe, and the evaluation system.
Miners become the extra compute layer.
They help Quasar train faster, improve continuously, and move forward together.
this would be the largest token-scale training runs ever attempted in decentralized AI.
This is how we scale Quasar.
Help us train it 👇
15
59
222
34,786
Jun 11
SN21(@adtao_ppcrebel) has continued to progress across several key ecosystem milestones, alongside the rollout of its official Telegram Community.
Recent updates include:
▫️SN21 Alpha price and full tokenomics are now listed on CoinGecko (coingecko.com/en/coins/omega…)
▫️@dsvfund has reported completing an OTC position in SN21, adding the subnet to its holdings (x.com/i/status/2063324273272…)
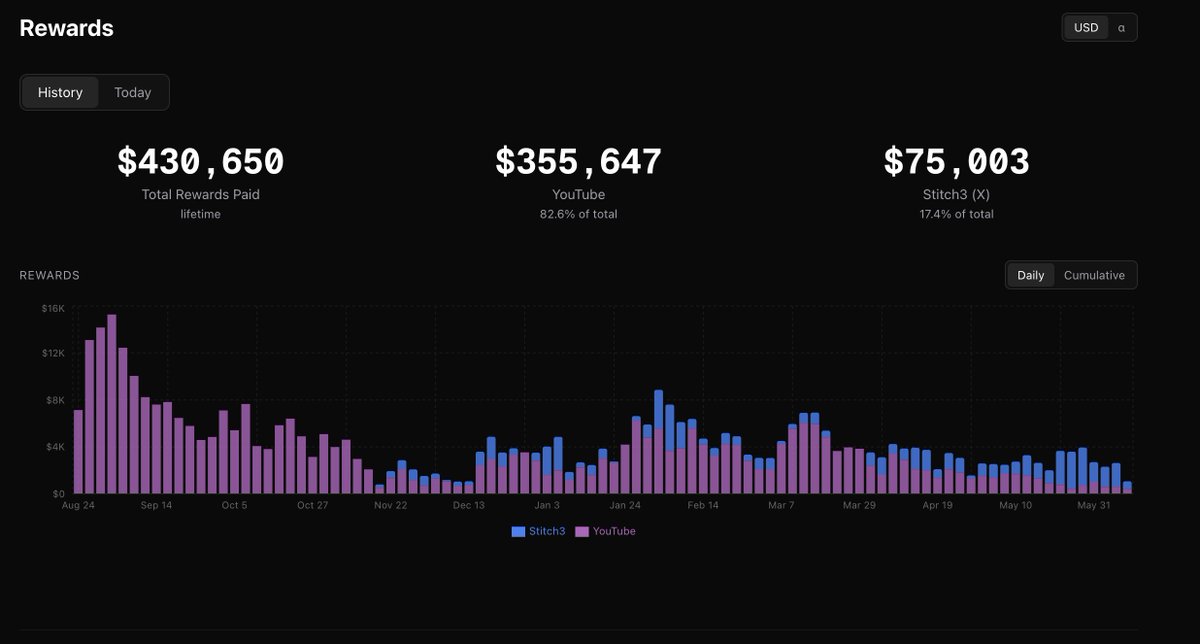
▫️The team released its first financial report for May, showing early operational performance:
– Revenue: $41,000
– Profit: $6,000 (14% margin)
– Buybacks: $1,000 (17% of profit)
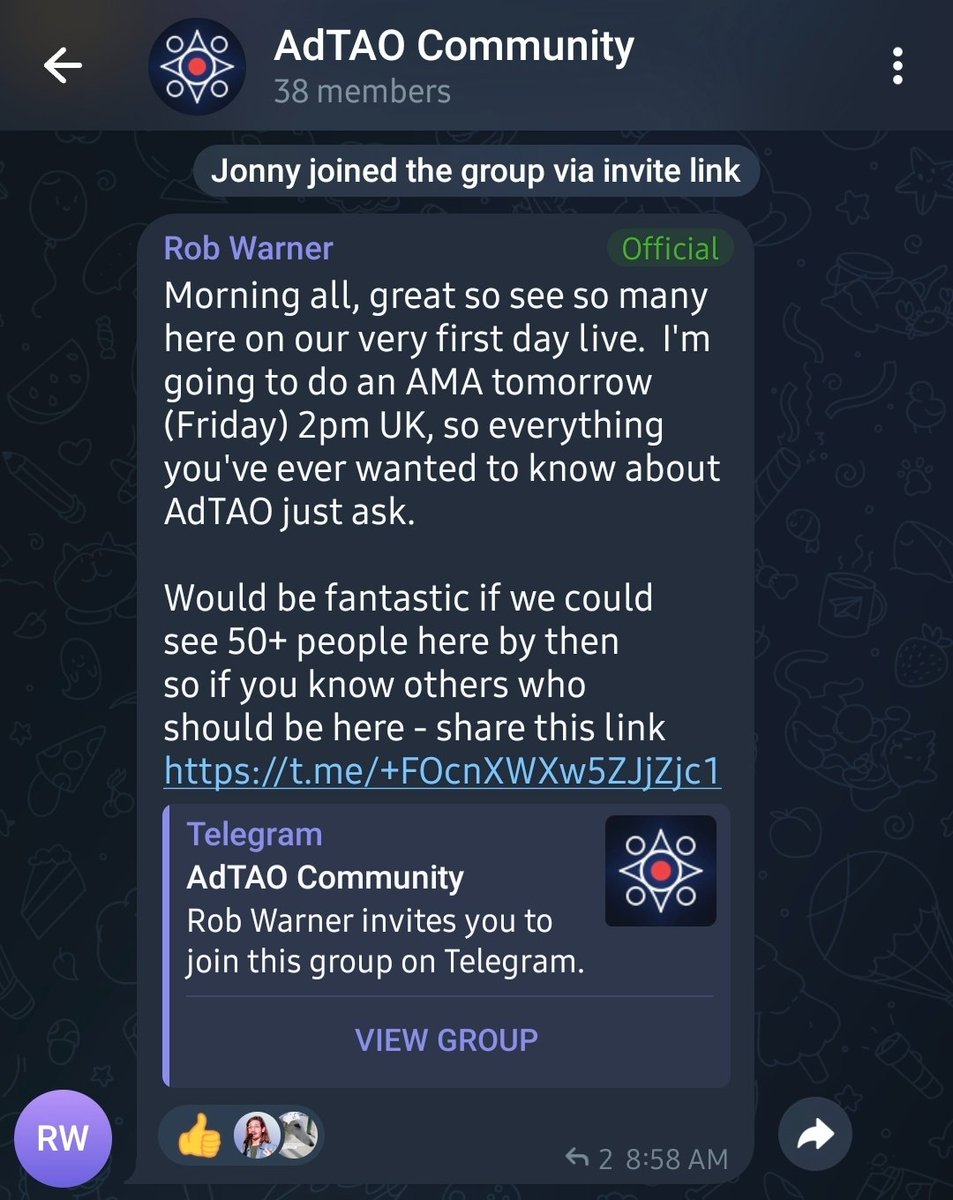
To further strengthen coordination and communication across participants, SN21 has launched an official Telegram Community for miners, contributors, supporters, and ecosystem participants. The group is designed to support updates, discussion, feedback, and direct communication with the core team.
As part of the launch, SN21 will host its first Community AMA tomorrow (Friday) at 2:00 PM UK time inside the Telegram group. The session will provide an opportunity for participants to engage with the team and learn more about ongoing development and ecosystem direction.
Join the SN21 Telegram Community: t.me/ FOcnXWXw5ZJjZjc1
The @adtao_ppcrebel(SN21) team continues to focus on execution, transparency, and ecosystem development across its roadmap.

Delighted to share that DSV took an OTC position in @adtao_ppcrebel (SN21) ahead of Proof of Talk.
We got in early because we know where this business is heading. Combining the power of Bittensor with the size of the Google Ads market.
AdTAO is real advertising intelligence built on Bittensor, led by an operator with 13 years in the game who has built and sold multiple ad businesses.
That’s why we wanted to lock in exposure for DSV investors.
Today the team announced their first buyback. They've already got fiat revenue and they are using some of it to back their own subnet alpha.
Proud to back AdTAO.
3
12
860
Subnet Summer retweeted

Jun 11
@AltcoinDaily recently highlighted a key issue across the crypto industry: many tokens provide little to no value for the people who actually hold them.
In contrast, they pointed to $TAO Bittensor’s unique model, where value and utility are created through a growing ecosystem of subnets that deliver real-world AI services and infrastructure.
A special mention to @jaltucher for articulating this value proposition so clearly and effectively. His explanation of how subnets contribute to the broader Bittensor ecosystem was both insightful and compelling.
youtu.be/26N4u0ihIT4?si=Sc21…
3
4
16
1,286
Subnet Summer retweeted
Jun 11
Every agent you use today forgets you tomorrow. New session, blank slate, start from scratch.
Ditto MCP changes that. Connect it to Claude, Cursor, Codex - any agent and it gets memory, context, and file access that persists. Context that compounds instead of resets.
1,000 users. No ads. All word of mouth. @heydittoai

4
16
624
Jun 11
Ditto MCP supercharges your agents.
Connect it to Claude, Codex, Cursor - any agent you're already running and it gets memory, context, and file access it didn't have before. Optimized memory enhances inference. Context that compounds instead of resets.
1,000 users. No ads. Pure word of mouth. Built on Bittensor with @hippius_subnet for storage and @chutes_ai for inference.
The race is to be THE interface that makes models perform best. @heydittoai is running that race.
3
19
1,029

Subnet Summer retweeted

2
21
51
1,956