
Machine Learning Researcher @Raidium_med. PhD in Deep Learning from Sorbonne Université. Graduated from MS. at @GeorgiaTech and @CentraleSupelec.
Joined March 2009
- Tweets 313
- Following 248
- Followers 314
- Likes 929
17 Photos and videos






Excited to be at CVPR in Denver for the two workshop days, June 3 and 4 to present our research on foundation models in radiology! We'll be at the FMV workshop on June 3. Feel free to contact me for a chat about our research!
1
5
188

Today @cdancette from @raidium_med stopped by to talk about Curia, a multi-modal open-weights foundation model for radiology building in the style of DINOv2 with tons of downstream applications.
Do check it out!



1
6
17
675
Corentin Dancette retweeted

15 Oct 2025
I am starting a venture on top of LeRobot!
We’re at a pivotal time. AI is moving beyond digital to the physical world. Embodied AI will change our surroundings in ways we can barely imagine. This technology holds the potential to empower everyone. It must not be controlled by just a few.
This conviction led me to propose an ambitious open-source AI robotics project to Thom, Clem, and Julien back in 2024. Hugging Face, home to a community of millions of AI builders and a team of experts who brought us transformers, datasets, and the Hugging Face Hub, was the perfect place to launch LeRobot.
I’m incredibly grateful for all the support that allowed me to build LeRobot alongside an amazing team and community. In such a short time, we built one of the most adopted open-source robotics platforms, used by startups, universities, and research labs. It is helping countless people take their first steps in robotics. Together, we’ve even assembled the world’s largest open robotics dataset. And this is only the beginning for LeRobot!
Building on this momentum, I now feel the urgency to start something new on top of LeRobot. It will push the limit of what robots are capable of and commoditize them within society. Like LeRobot, it will start in Paris, leveraging its vibrant international AI scene. Stay tuned!
As LeRobot continues to expand, it’s now in the best possible hands with @AractingiMichel, @pepijn2233 and Steven Palma taking the lead. Watching the team deliver exceptional results over the last weeks has been one of the most rewarding experiences. Their creativity, dedication, and capability to ship fast is proving just how strong the team is today!
I am extremely grateful to the many people who contributed to making LeRobot at Hugging Face and within its powerful community. Many thanks to Thom, Clem, Julien, Simon, Rob, Michel, Pepijn, Steven, Gloria, Adil, Martino, Caroline, Marine, Mishig, Guillaume, Pablo, Lysandre, Arthur, Quentin, Florent, Brigitte, Victor, Marina, Mustafa, Francesco, Jess, Jade, Ville, Leo, Max, Julien, Alexander, Flavien, Raphael, Adina, Tao, Dana, Batu, Olivier, Matthieu, Eugene, Theo, Guilherme, Hynek, Loubna, Clémentine, Merve, Vaibhav, Anna, Jeff, Adrien, Emily, Johanne, Adrien and others. There are too many of you to be all named!
Thanks again and see you soon!!! :)
~ Remi
99
85
763
124,087

9 Sep 2025
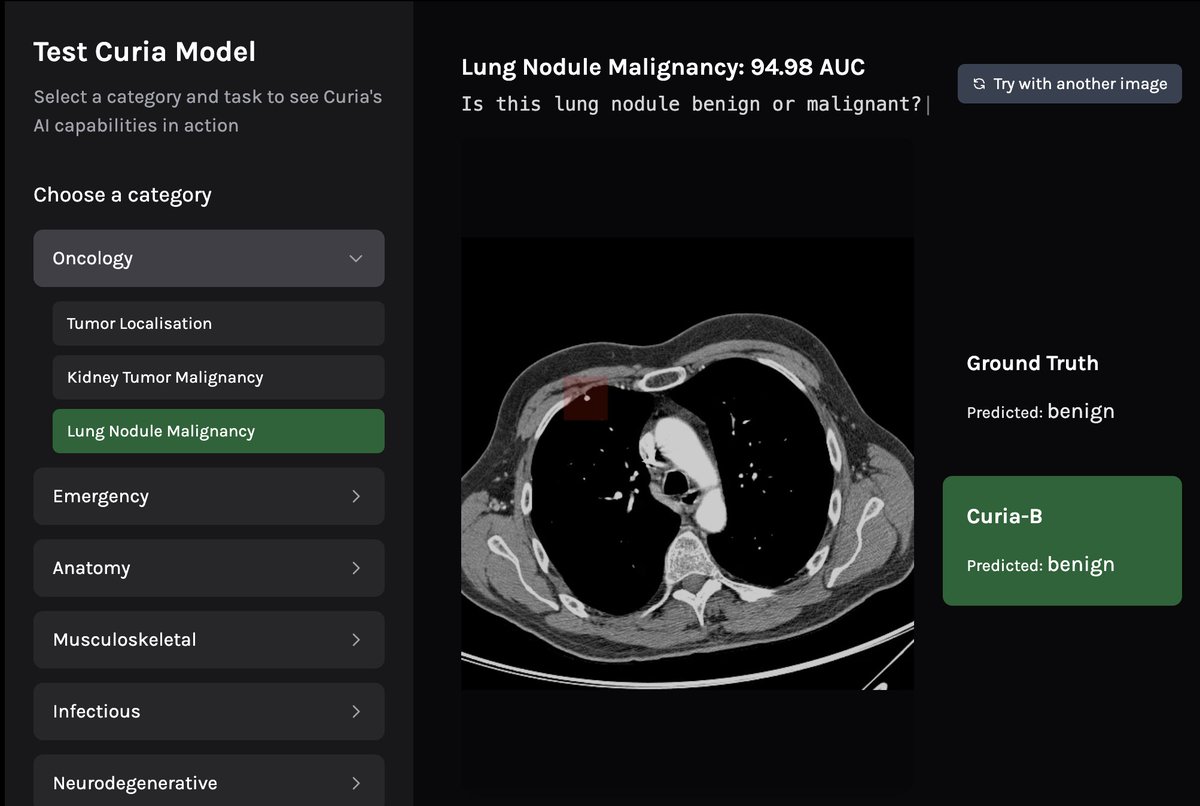
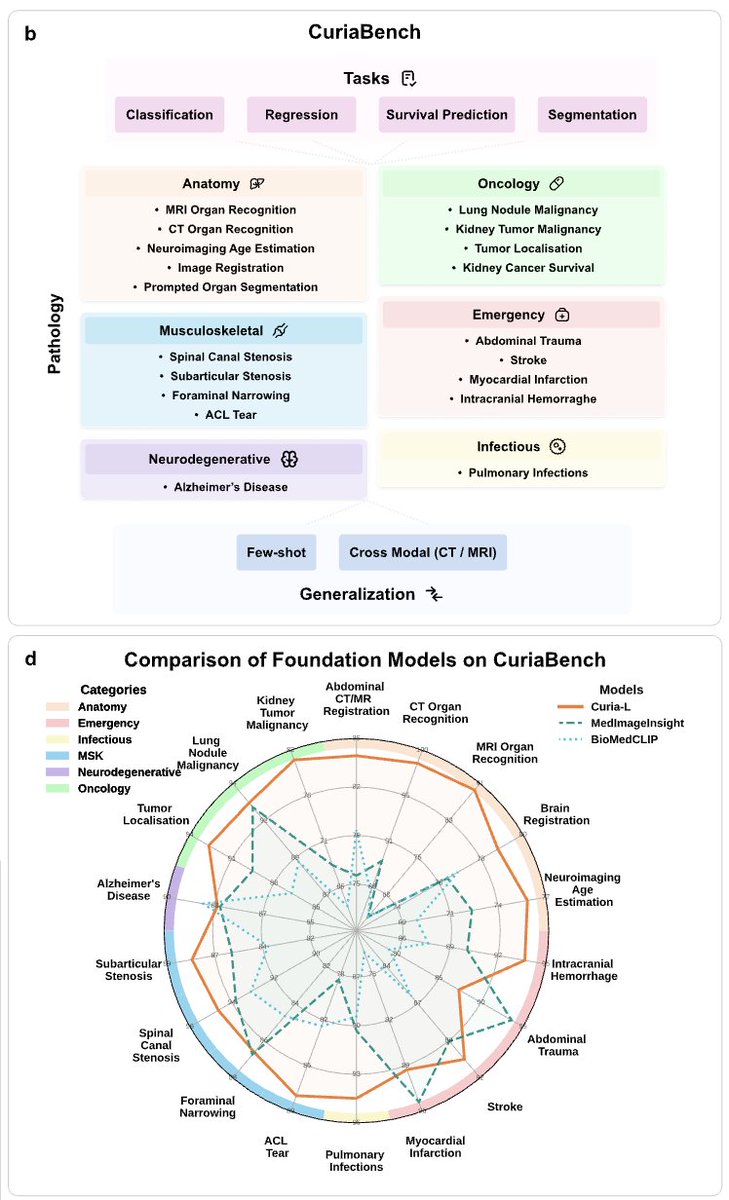
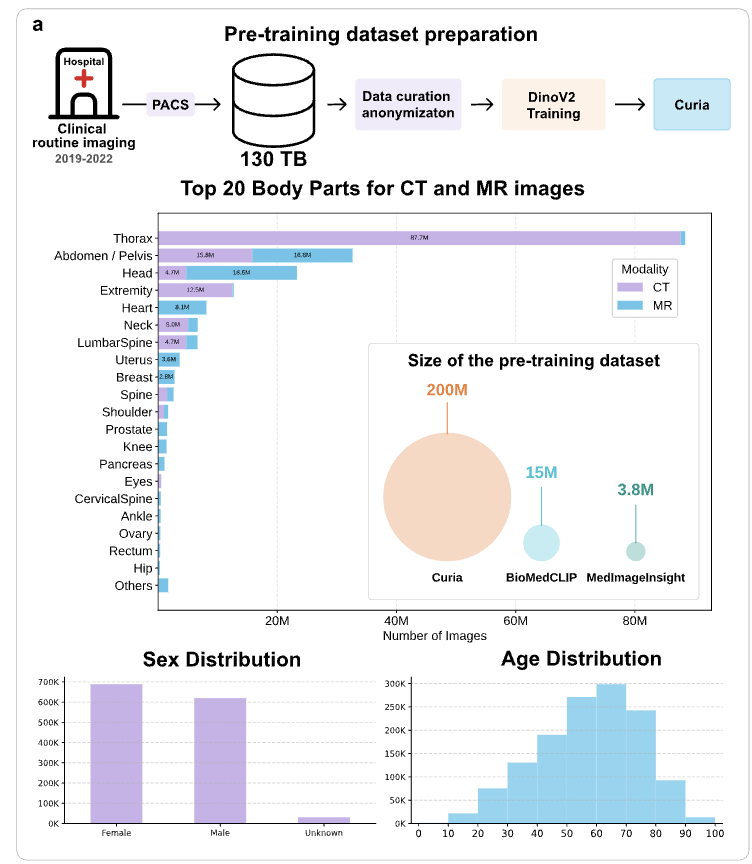
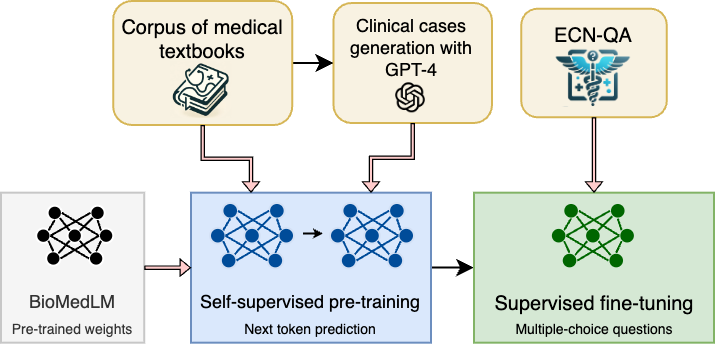
Excited to share our latest work at @raidium_med
Curia: A Multi-Modal Foundation Model for Radiology.
Pre-print: arxiv.org/abs/2509.06830
We are releasing our base model's weights, Curia-B, to the research community: huggingface.co/raidium/curia
1
5
6
405
9 Sep 2025
Congrats to the whole Raidium team, @SovanKhlt, Antoine Saporta, Helene Philippe, @Elferodie_bis , Baptiste Callard, Théo Danielou, Léo Alberge, Léo Machado, Daniel Tordjman, Julie Dupuis, Korentin Le Floch, @Phylliade, @paulherent, and @Beleyem
1
2
3
193
9 Sep 2025
And thanks a lot to our co-authors for all their help: @jeandut14000, @Moshirimd, @laurentdercle,Tom Boeken, @Jules_GREGORY_, @maximeronot, François Legou, Pascal Roux, and Marc Sapoval
1
2
70
15 Jul 2025
Second,
RAPS-3D: Efficient interactive segmentation for 3D radiological imaging (arxiv.org/abs/2507.07730) by Théo Danielou.
We propose an efficient 3D-native promptable segmentation model for organ segmentation. It will be presented this week at MIUA in Leeds, UK!
1
1
1
81
15 Jul 2025
Happy to share two publications by our team!
First, RadSAM: Segmenting 3D radiological images with a 2D promptable model by @SovanKhlt. We show how to adapt SAM for 3D CT images, using an iterative inference. arxiv.org/abs/2504.20837
It will be presented at MICCAI 2025 in Seoul!
1
3
5
720
Corentin Dancette retweeted

3 Jun 2025
The Worldwide @LeRobotHF hackathon is in 2 weeks, and we have been cooking something for you…
Introducing SmolVLA, a Vision-Language-Action model with light-weight architecture, pretrained on community datasets, with an asynchronous inference stack, to control robots🧵

6
78
436
84,032
Corentin Dancette retweeted
28 Apr 2025
We are organizing a CVPR in Paris event the 6th of June. It will feature poster sessions for papers accepted at CVPR, and Keynotes from Alexei Efros, @dlarlus and @AlexAlahi.
You can register here: cvprinparis.github.io/CVPR20…

1
7
32
2,385
Corentin Dancette retweeted
11 Apr 2025
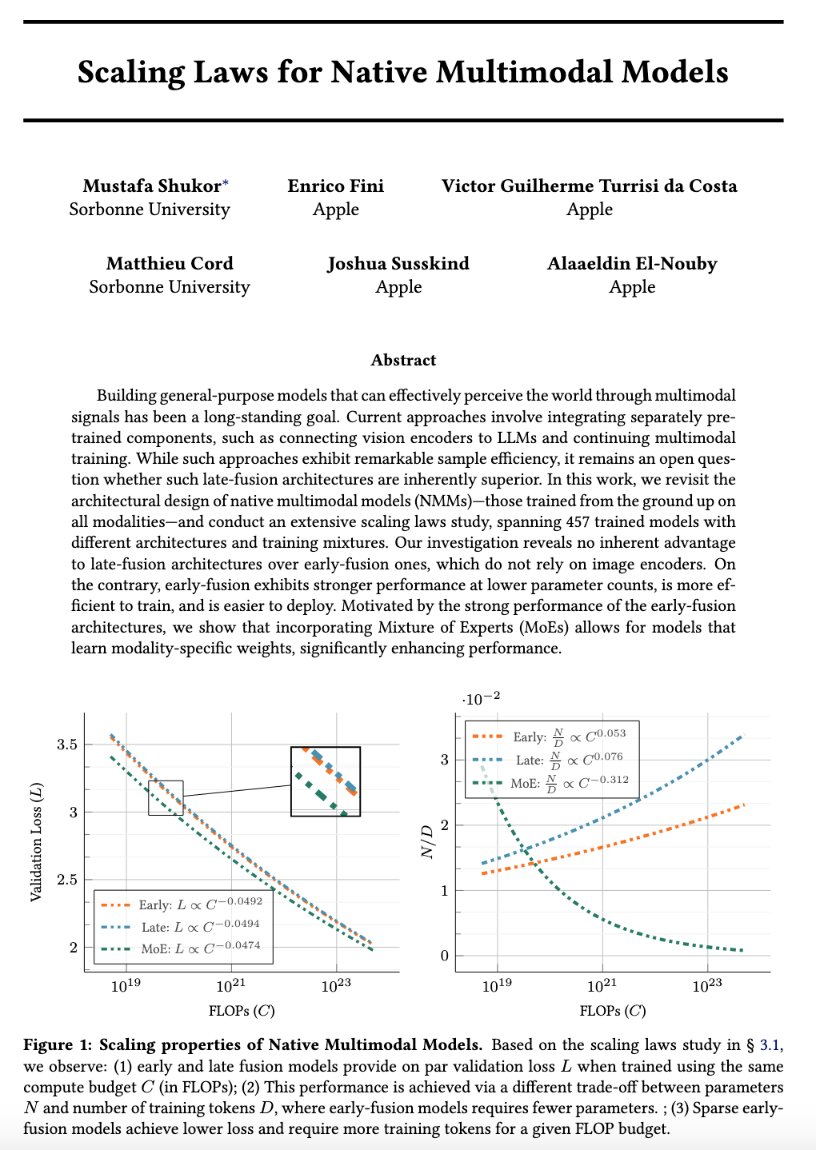
We release a large scale study to answer the following:
- Is late fusion inherently better than early fusion for multimodal models?
- How do native multimodal models scale compared to LLMs.
- How sparsity (MoEs) can play a detrimental role in handling heterogeneous modalities? 🧵
10
80
459
86,208

Want to check out the source for the "AlexNet" paper? Google has made the code from Alex Krizhevsky, @ilyasut, and @geoffreyhinton's seminal "ImageNet Classification with Deep Convolutional
Neural Networks" paper public, in partnership with the Computer History Museum.
As I said in the press release, "Google is delighted to contribute the source code for the groundbreaking AlexNet work to the Computer History Museum".
computerhistory.org/press-re…

28
145
1,007
108,441
Corentin Dancette retweeted
18 Mar 2025
Join us for a hackathon in Paris from April 11-13 😇
Register now! lu.ma/roboticshack

6
24
157
8,870
Corentin Dancette retweeted

28 Dec 2024
Hot take: I rarely if ever do "git add *" or "git add ."
"git add -p" is super underrated. You basically do a mini code-review before making the commit. Essential part of my workflow


178
120
3,883
517,366
Corentin Dancette retweeted
22 Nov 2024
We release AIMv2, a major step in scaling vision encoders.
Properly scaling vision encoders has been challenging and lagging, compared to LLMs. The main bottleneck is training and evaluating on single image modality, (1/n)

2
30
163
18,117
Corentin Dancette retweeted

8 Oct 2024
Avec le prix Nobel de physique pour l'apprentissage et les réseaux de neurones, il est clair qu'on est face à un changement majeur (type électricité, nucléaire, télécom). Il nous faut une politique nationale plus ambitieuse! Jean Zay est déjà trop petit! @Genci_fr @sup_recherche
1
5
22
2,812