
ML @weaviate_io | Occasional maker of things, regular breaker of things.
Joined February 2009
- Tweets 446
- Following 585
- Followers 494
- Likes 1,980
33 Photos and videos



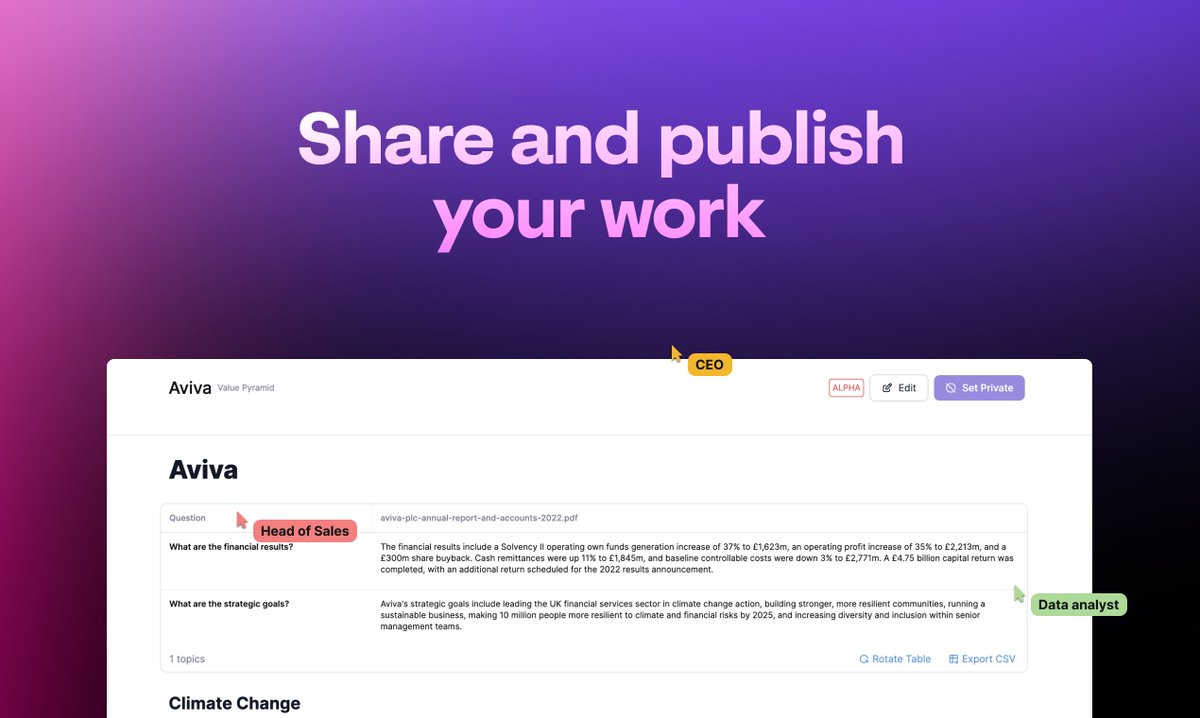







Pinned Tweet

13 Apr 2023
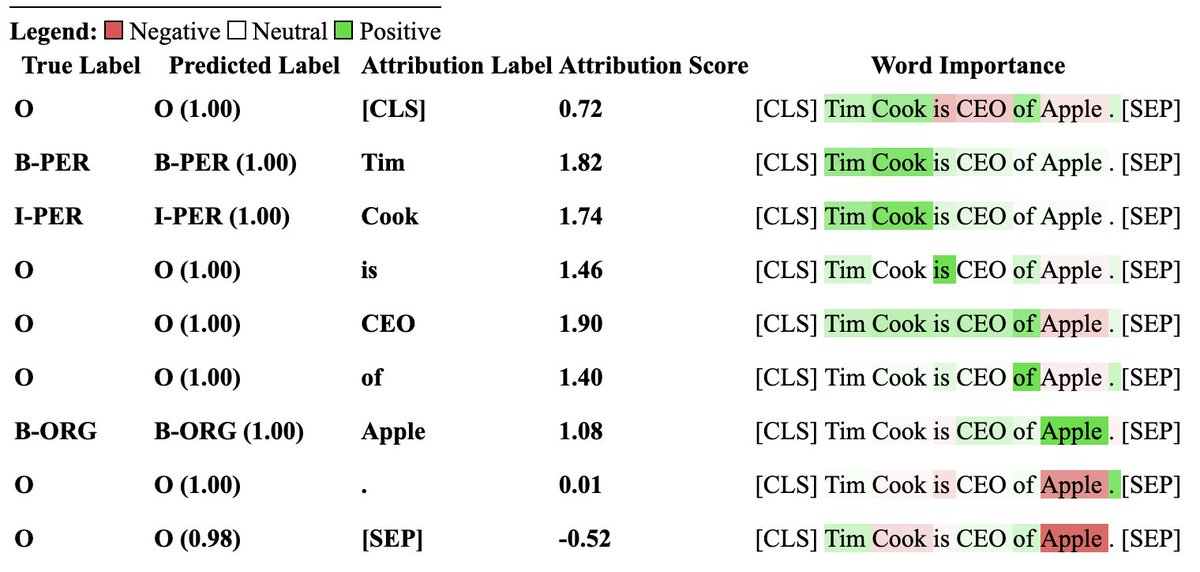
Very proud to see Transformers Interpret hit 1k stars today with over 200,000 downloads. Maintaining a library has been one of the hardest and most rewarding things I've done. Looking forward to adding some very cool new explainers **cough** Seq2Seq LLM's models very soon 👀
1
10
1,354
Charles Pierse retweeted

🚢 Toot! The team is shipping again!
We’re seeing a massive wave of developers & agents building advanced AI memory capabilities on top of Weaviate. To make that even easier, we just launched Engram, a dedicated memory service built right on our database.
1
5
11
1,264
Charles Pierse retweeted
Most agent memory systems are just glorified context windows.
And this is exactly why production agents fail at scale.
We've been working on this for months, and it's finally here: 𝗘𝗻𝗴𝗿𝗮𝗺 𝗶𝘀 𝗻𝗼𝘄 𝗚𝗔.
If you've been building agentic applications, you know the problem. Agents that should get smarter over time stay flat instead. They forget user preferences, re-solve the same problems repeatedly, and waste tokens on work that can't be reused. Long context windows help, but cramming them full degrades accuracy, inflates costs, and increases latency.
𝗘𝗻𝗴𝗿𝗮𝗺 𝘀𝗼𝗹𝘃𝗲𝘀 𝘁𝗵𝗶𝘀.
It's a managed memory service built on Weaviate that 𝘢𝘤𝘵𝘪𝘷𝘦𝘭𝘺 𝘮𝘢𝘪𝘯𝘵𝘢𝘪𝘯𝘴 memory instead of just storing it. Asynchronous pipelines extract relevant information from raw data, reconcile it with existing memories (handling deduplication, preference changes, time-evolving facts), and persist clean, structured memory state ready for retrieval.
𝗞𝗲𝘆 𝗰𝗮𝗽𝗮𝗯𝗶𝗹𝗶𝘁𝗶𝗲𝘀:
𝗙𝗶𝗿𝗲-𝗮𝗻𝗱-𝗳𝗼𝗿𝗴𝗲𝘁 𝗔𝗣𝗜 → Add raw data and continue working. Pipelines run asynchronously in the background with durable execution.
𝗧𝗼𝗽𝗶𝗰𝘀 𝗮𝘀 𝗺𝗲𝗺𝗼𝗿𝘆 𝗺𝗮𝗴𝗻𝗲𝘁𝘀 → Natural language descriptions that pull matching information from raw data. You control what's worth remembering.
𝗦𝗰𝗼𝗽𝗲𝘀 𝗳𝗼𝗿 𝗶𝘀𝗼𝗹𝗮𝘁𝗶𝗼𝗻 → Project-wide, user-scoped, or property-scoped memories with hard and soft isolation enforced at the platform level.
𝗖𝗼𝗺𝗽𝗼𝘀𝗮𝗯𝗹𝗲 𝗽𝗶𝗽𝗲𝗹𝗶𝗻𝗲𝘀 → Extract, transform, buffer, and commit steps that manage memories dynamically based on data type and preferences.
𝗕𝘂𝗶𝗹𝘁 𝗼𝗻 𝗪𝗲𝗮𝘃𝗶𝗮𝘁𝗲 → Memory retrieval inherits Weaviate's vector keyword metadata search on the same production stack you already trust, using native multi-tenancy to isolate instances.
Whether you're building chatbots that remember user preferences, agents that learn from experience, or multi-agent systems that need shared context, Engram gives you memory as infrastructure.
As a promotional offer, we’re giving $75 in credits for your first three months of Engram! Sign up before July 15th to claim it.
Read the blog: weaviate.io/blog/engram-gene…
Get started: docs.weaviate.io/engram?utm_…
5
12
43
2,950
Charles Pierse retweeted

May 14
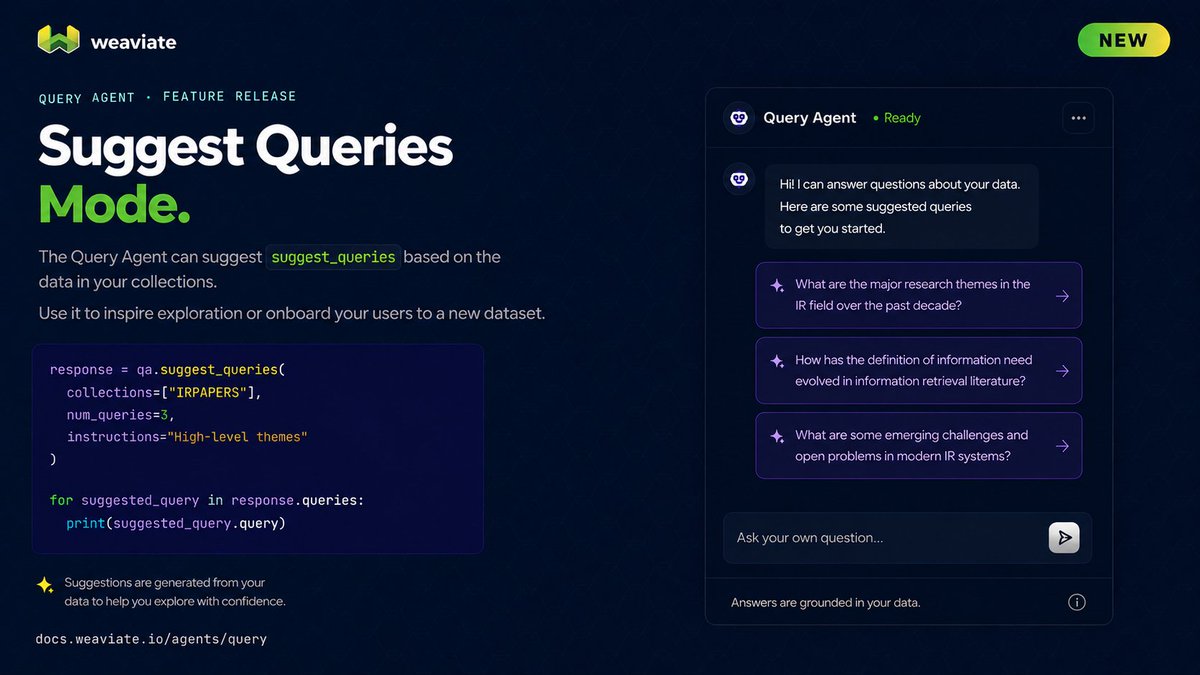
Introducing Suggest Queries Mode 💚
Weaviate’s Query Agent can now suggest queries that are answerable by the data in your collections.
This helps users discover what kinds of questions they can ask! 💬
2
4
18
730
Charles Pierse retweeted

Apr 28
𝗨𝗻𝗽𝗼𝗽𝘂𝗹𝗮𝗿 𝗼𝗽𝗶𝗻𝗶𝗼𝗻: The best hires aren't experienced.
They're hungry. And we're searching for two of them right now.
We have two open positions in the Growth team at @weaviate_io:
𝗗𝗲𝘃𝗲𝗹𝗼𝗽𝗲𝗿 𝗚𝗿𝗼𝘄𝘁𝗵 𝗜𝗻𝘁𝗲𝗿𝗻
𝗗𝗲𝘃𝗲𝗹𝗼𝗽𝗲𝗿 𝗠𝗮𝗿𝗸𝗲𝘁𝗶𝗻𝗴 𝗠𝗮𝗻𝗮𝗴𝗲𝗿
We're looking for people who aren't afraid to work hard, who want to grind, and who are hungry to learn how to define narratives and win on social media.
Not people who check boxes. Not people who want a comfortable 9-5. We want the next diamonds - people who see an opportunity to learn from a team that's built a developer community from the ground up and think "I want to know how they did that."
You'll learn:
• How to craft narratives that cut through noise
• What actually works on social media (not what the courses tell you)
• How to build genuine engagement with developer communities
• The difference between marketing 𝘢𝘵 developers and marketing 𝘸𝘪𝘵ℎ them
This isn't going to be easy. But if you're the type of person who gets excited by that statement rather than intimidated by it, you might be exactly who we're looking for.
Apply here: weaviate.io/company/careers?…
Complete the challenge. Impress us. 💎
1
5
34
2,313
Charles Pierse retweeted
Apr 27
How do we build search systems for Agents? 👾🔎
I am SUPER EXCITED to share a new episode of the Weaviate Podcast with Zijian Chen (@zijian42chen) and Xueguang Ma (@xueguang_ma) from the University of Waterloo on AgentIR! 🎙️💚
When humans search, we write short queries and keep our reasoning in our heads. Deep Research agents do the opposite. They leave reasoning traces that reflect on prior results, clarify intent, and plan what to search next. Existing retrievers completely ignore this signal because they were designed for human queries. 💭
AgentIR jointly embeds the agent's reasoning trace alongside its query, training a retriever that actually understands what the agent is thinking. AgentIR-4B hits 68% accuracy on BrowseComp-Plus compared to 52% for conventional embedding models twice its size. 📊
One idea I found especially interesting is how AgentIR raises context management questions for agents: what should be remembered, compacted, or retrieved just in time? The current reasoning trace naturally curates history by summarizing confirmed findings and filtering out wrong guesses. Forgetting becomes a feature, not a bug. 🔬
We also covered BrowseComp-Plus, their benchmark for disentangled evaluation of agents and retrievers, and the open question of scaling search deeper vs. wider.
If you're working at the intersection of Agents and Search, I think you'll get a lot out of this one! Links below! 🎉

2
17
52
26,381
Feb 4
We've been tinkering away on something new at @weaviate_io about the role memory plays not just for chatbots but for the agents you have deployed in prod.
It's become clear that memory isn't a nice to have but that it's essential layer for you apps and agents to succeed in the long run.

Your AI agent worked perfectly in January.
By June, it's confidently giving you wrong answers. Here's why:
As AI applications graduate from PoCs to production, we're hitting a wall that better models can't solve: 𝗹𝗮𝗰𝗸 𝗼𝗳 𝗰𝗼𝗻𝘁𝗶𝗻𝘂𝗶𝘁𝘆.
𝗧𝗵𝗲 𝗹𝗶𝗺𝗶𝘁𝗲𝗱 𝗹𝗼𝗼𝗽 𝗽𝗿𝗼𝗯𝗹𝗲𝗺
Today's AI applications treat each interaction as largely disposable. You've felt it already: repeating preferences, restating context, and re-teaching the same facts.
At agent scale, the problem worsens. Agents re-derive the same conclusions, regenerate identical facts, and discard half-finished work, and what looks like forgetfulness for humans turns into systemic chaos for machines.
𝗪𝗵𝘆 𝗻𝗮𝗶𝘃𝗲 𝗺𝗲𝗺𝗼𝗿𝘆 𝘄𝗶𝗹𝗹 𝗳𝗮𝗶𝗹
Here's what happens with a basic memory implementation:
Week 1: Magic! The agent remembers.
Month 3: Responses slow down as memory bloats.
Month 6: Answers drift wildly as the model pulls from conflicting and outdated context.
Helpful continuity has slowly turned into accumulated noise.
𝗧𝗵𝗲 𝘀𝗵𝗶𝗳𝘁: 𝗺𝗲𝗺𝗼𝗿𝘆 𝗶𝘀𝗻’𝘁 𝘀𝘁𝗼𝗿𝗲𝗱, 𝗶𝘁’𝘀 𝘮𝘢𝘪𝘯𝘵𝘢𝘪𝘯𝘦𝘥.
Useful memory systems actively manage context through write control, deduplication, reconciliation, amendment, and purposeful forgetting.
Without these, memory becomes an ever-growing pile of notes. With them, it becomes 𝗿𝗲𝗹𝗶𝗮𝗯𝗹𝗲 𝘀𝘁𝗮𝘁𝗲.
At Weaviate, we treat memory as a first-class data problem: durable, governable, and safe under change.
Read the full blog post on our vision for memory and signup for the product preview: weaviate.io/blog/limit-in-th…

1
4
680
Jan 27
When we were building Weaviate's Transformation Agent out, we knew we needed to saturate our GPUs as much as possible and squeeze every bit of utilization we could. Not only was this possible with @modal but it made the whole process of implementation incredibly straightforward.

It's time to run your own LLM inference. The open models and open source engines are ready. Are you?
We've been working with leading teams like @DecagonAI, @weaviate_io, and @reductoai to ship production-grade inference.
Here's how we do it:
2
9
4,567
Charles Pierse retweeted
18 Dec 2025
Search Mode is now available in the Weaviate Console! 💻🎨
A new button lets you toggle between Ask and Search! 🖱️
Another cool aspect of this is that you can switch to Search Mode in the middle of a conversation with Ask Mode! 💬
Check it out! 👇
1
9
18
819
Charles Pierse retweeted

28 Nov 2025
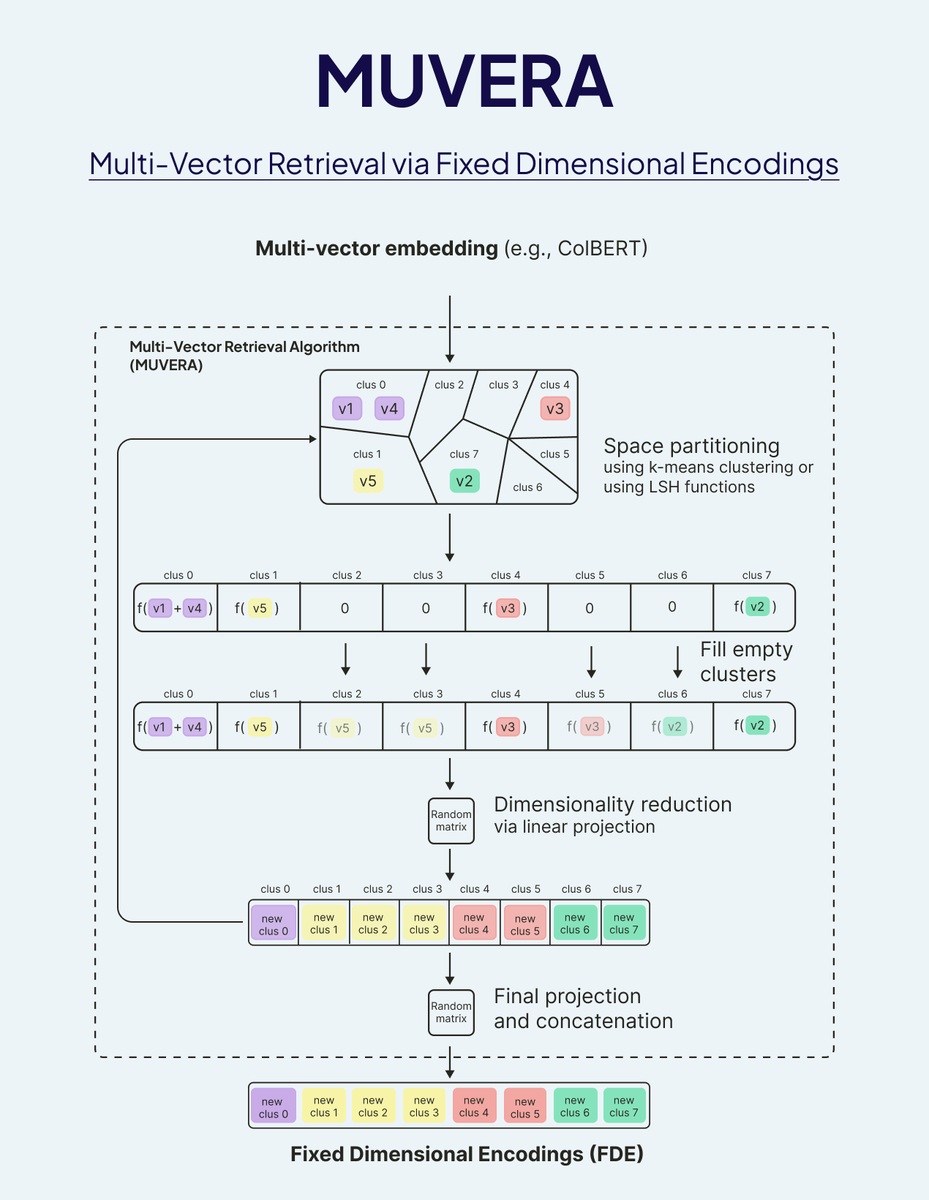
Multi-vector models like ColBERT and ColPali are incredible for retrieval quality, but they eat memory for breakfast. We're talking 10-13x more memory than single-vector embeddings because you're storing hundreds of vectors per document instead of one.
MUVERA (Multi-Vector Retrieval via Fixed Dimensional Encodings) changes this by encoding multi-vector embeddings into single fixed-size vectors through space partitioning and dimensionality reduction.
Real results from our LoTTE benchmark tests:
- Memory footprint: 12GB → <1GB (~70% reduction)
- Import speed: 20 minutes → 3-6 minutes
- Recall: 80-90% with proper HNSW ef tuning
The trade-off? Some recall loss that you can mitigate with higher ef values, though that reduces query throughput. But when you're looking at tens or hundreds of thousands of dollars in cloud costs per year, this is a no-brainer for large-scale deployments.
Available in Weaviate 1.31 and it's literally just a couple lines of code to enable!
1
2
12
844
Charles Pierse retweeted

20 Nov 2025
I've been learning about agent memory for the past few weeks.
This new blog summarizes everything I've learned so far:
• What is agent memory, and why do you need it
• What are the types of memory (and what categorization approaches are there?)
• How do you manage memory in AI agents
Join me in learning about memory for agents:
leoniemonigatti.com/blog/mem…
27
100
718
57,963
Charles Pierse retweeted
3 Nov 2025
I am SUPER EXCITED to publish the 130th episode of the Weaviate Podcast featuring Xiaoqiang Lin (@xiaoqiang_98), the lead author of REFRAG from Meta Superintelligence Labs! 🎙️🎉
Traditional RAG systems use vectors to retrieve relevant context, but then throw away the vectors, just giving the content to the LLM. REFRAG instead feeds the LLM these pre-computed vectors, achieving massive gains in long context processing and LLM inference speed! 🧬
REFRAG makes Time-To-First-Token (TTFT) 31x faster and Time-To-Iterative-Token (TTIT) 3x faster, boosting overall LLM throughput by 7x while also being able to handle much longer contexts! 🔥🔥
There are so many interesting aspects to this and I loved diving into the details with Xiaoqiang! I hope you enjoy the podcast! 🎙️

5
17
43
16,900
Charles Pierse retweeted
7 Oct 2025
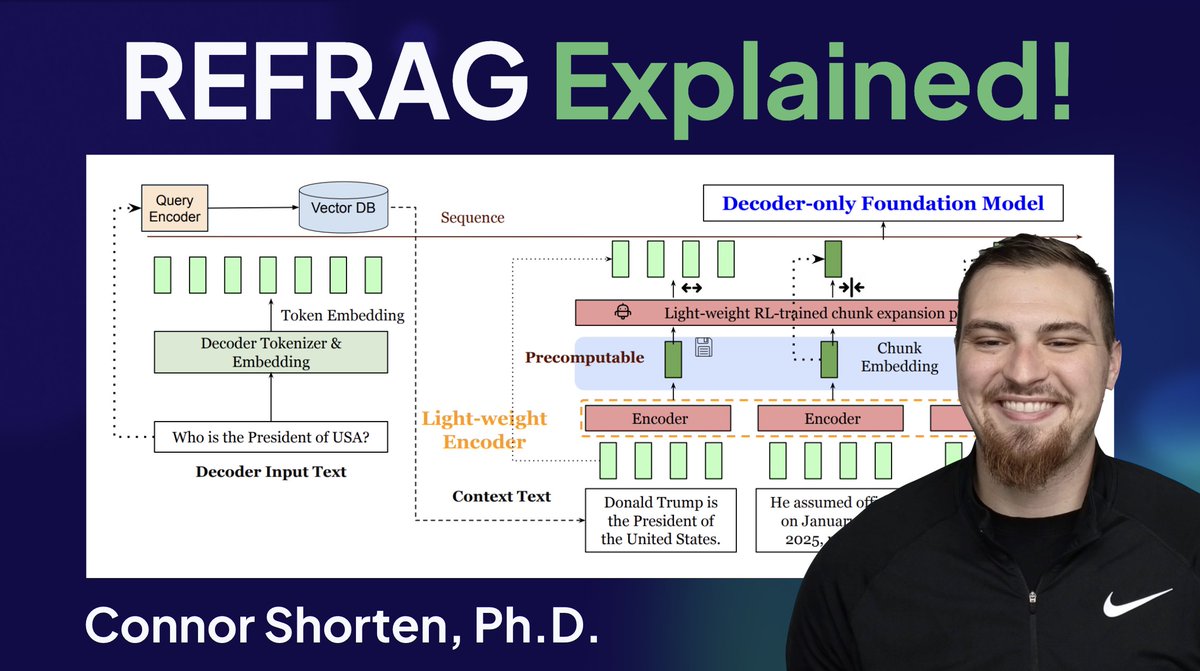
As a quick TLDR, there are two key aspects to understanding how REFRAG works:
1. The particular way REFRAG represents context tokens and injects them into LLM decoding, as well as how this speeds up LLM inference. ⚡️
2. The training algorithm used to align the encoder, projection layer, decoder, and selective chunk expansion policy! 🏭

7 Oct 2025

REFRAG from Meta Superintelligence Labs is a SUPER EXCITING breakthrough that may spark the second summer of Vector Databases! ☀️🏖️
REFRAG illustrates how Database Systems are becoming even more integral to LLM inference 🧬
By making clever use of how context vectors are integrated with LLM generation, REFRAG is able to make TTFT (Time-to-First-Token) 31X faster and TTIT (Time-to-Iterative-Token) 3X faster, overall improving LLM throughput by 7x!! REFRAG is also able to process much longer input contexts than standard LLMs! 🔥🔥
How does it work? 🔬
Most of the RAG systems today that are built with Vector Databases, such as Weaviate, throw away the associated vector with retrieved search results, only making use of the text content. REFRAG instead passes these vectors to the LLM, instead of the text content!
This is further enhanced with a fine-grained chunk encoding strategy, and a 4-stage training algorithm that includes a selective chunk expansion policy trained with GRPO / PPO. 🏭
Here is my review of the paper! I hope you find it useful! 🎙️
1
3
24
1,768
Charles Pierse retweeted

23 Sep 2025
We benchmarked the Query Agent’s Search Mode vs. Hybrid Search across 12 IR benchmarks from BEIR, LoTTe, BRIGHT, EnronQA, and WixQA.
The results? 17% average improvement in Success @ 1 and 11% in Recall @ 5!
Learn more about the benchmarks and dive into our experimental details:
📊 Blog post: weaviate.io/blog/search-mode…

12
32
12,029
Charles Pierse retweeted

23 Sep 2025
I just finished reading @weaviate_io new blog on Search Mode benchmarks , and it’s a real milestone for the vector search LLM community.
Search Mode is Weaviate’s new compound retrieval system , basically a smarter way of doing search that goes beyond “hybrid” (keyword vector).
To go beyond standard hybrid search , Weaviate has developed several important methods .
Query Expansion :
Adds related terms so the engine doesn’t miss relevant docs.
Query Decomposition :
Breaks a complex user request into smaller parts.
Reranking :
Intelligently reorders results so the best answers rise to the top.
Think of it as search that not only finds but also understands how to shape the question, and the response!
Benchmarks tested :
1. BEIR (standard IR benchmark across multiple datasets)
2. LoTTe (long-tail, hard questions)
3. BRIGHT (biomedical retrieval)
4. EnronQA (enterprise email data)
5. WixQA (real-world domain-specific QA)
On every one of these, Search Mode shows gains over hybrid search!
As Weaviate is increasingly turned to as the preferred Search engine for mission critical applications, there are important benefits.
For RAG pipelines, higher precision means fewer hallucinations.
For agentic systems, decomposition means the retriever can keep up with multi-step reasoning.
For enterprises, messy datasets (emails, docs, portals) become far more searchable without manual tuning.
Amazing, absolutely amazing!
23 Sep 2025
We benchmarked the Query Agent’s Search Mode vs. Hybrid Search across 12 IR benchmarks from BEIR, LoTTe, BRIGHT, EnronQA, and WixQA.
The results? 17% average improvement in Success @ 1 and 11% in Recall @ 5!
Learn more about the benchmarks and dive into our experimental details:
📊 Blog post: weaviate.io/blog/search-mode…
2
6
926
Charles Pierse retweeted
23 Sep 2025
I am SUPER excited to share our new Information Retrieval benchmarks! 🥳
Search Mode is a Compound Retrieval System that utilizes Query Expansion, Query Decomposition, Reranking, and more to achieve super accurate search results! 🎯
The blog post demonstrates how it performs compared to Hybrid Search on the BEIR, LoTTe, BRIGHT, EnronQA, and WixQA benchmarks! 📊
We also describe further what these benchmarks are and why we chose them! I hope you find this interesting! 👇👇
23 Sep 2025
We benchmarked the Query Agent’s Search Mode vs. Hybrid Search across 12 IR benchmarks from BEIR, LoTTe, BRIGHT, EnronQA, and WixQA.
The results? 17% average improvement in Success @ 1 and 11% in Recall @ 5!
Learn more about the benchmarks and dive into our experimental details:
📊 Blog post: weaviate.io/blog/search-mode…
3
9
23
3,635
Charles Pierse retweeted
22 Sep 2025
I am SUPER excited to publish the 128th episode of the Weaviate Podcast featuring Charles Pierse (@cdpierse)! 🎙️🎉
Charles has lead the development behind the GA release of Weaviate's Query Agent! 🔎
The podcast explores the 6 month journey from alpha release to GA! Starting with the meta from unexpected user feedback, collaboration across teams within Weaviate, and the design of the Python and TypeScript clients. 👋🤝🎨
We then dove deep into the tech! Discussing citations in AI systems, schema introspection, multi-collection routing, and the Compound Retrieval System behind search mode. 🛠️
Back into the meta around the Query Agent, we ended with its integration with Weaviate's GUI Cloud Console, our case study with MetaBuddy, and some predictions for the future of the Weaviate Query Agent! 🚀
I had so much fun chatting about these things with Charles! I really hope you enjoy the podcast! 🎙️

5
11
24
7,961
17 Sep 2025
We've been heads down the past few month getting the Query Agent ready for graduation to GA 🎓
Super proud of all the work from the team at @weaviate_io that has gone into getting it to where it is today.
If you want to supercharge your retrieval or build a complex chatbot on top of your Weaviate data, its a simple as a single line of code with Query Agent!
17 Sep 2025
We’re excited to announce:
The Weaviate Query Agent is now GA!
WQA is a Weaviate-native agent that transforms natural language questions into precise database operations, giving you reliable, fully transparent results.
It supports:
• Dynamic filters
• Smart routing across collections
• Aggregations
• Accurate results with full source citations
The result? Faster, more reliable, and fully transparent data-aware AI.
How to get started:
• 𝗜𝗻 𝘁𝗵𝗲 𝗖𝗼𝗻𝘀𝗼𝗹𝗲: Explore your data with natural language. See the Agent's "thought process" and the sources it used.
• 𝗩𝗶𝗮 𝗔𝗣𝗜𝘀/𝗦𝗗𝗞𝘀: Embed this intelligent querying directly into your applications, reducing boilerplate and shipping faster.
Key benefits:
• Say goodbye to custom query-rewriting pipelines.
• Get structured, predictable data back.
• Full transparency: see every filter, aggregation, and source.
• Automatically handles queries across multiple data collections and tenants.
Try it yourself:
🔬 Colab quickstart → github.com/weaviate/weaviate…
✍️ Launch blog → weaviate.io/blog/query-agent…

4
6
1,547
Charles Pierse retweeted
17 Sep 2025
We’re excited to announce:
The Weaviate Query Agent is now GA!
WQA is a Weaviate-native agent that transforms natural language questions into precise database operations, giving you reliable, fully transparent results.
It supports:
• Dynamic filters
• Smart routing across collections
• Aggregations
• Accurate results with full source citations
The result? Faster, more reliable, and fully transparent data-aware AI.
How to get started:
• 𝗜𝗻 𝘁𝗵𝗲 𝗖𝗼𝗻𝘀𝗼𝗹𝗲: Explore your data with natural language. See the Agent's "thought process" and the sources it used.
• 𝗩𝗶𝗮 𝗔𝗣𝗜𝘀/𝗦𝗗𝗞𝘀: Embed this intelligent querying directly into your applications, reducing boilerplate and shipping faster.
Key benefits:
• Say goodbye to custom query-rewriting pipelines.
• Get structured, predictable data back.
• Full transparency: see every filter, aggregation, and source.
• Automatically handles queries across multiple data collections and tenants.
Try it yourself:
🔬 Colab quickstart → github.com/weaviate/weaviate…
✍️ Launch blog → weaviate.io/blog/query-agent…
3
11
33
9,182
Charles Pierse retweeted
12 Aug 2025
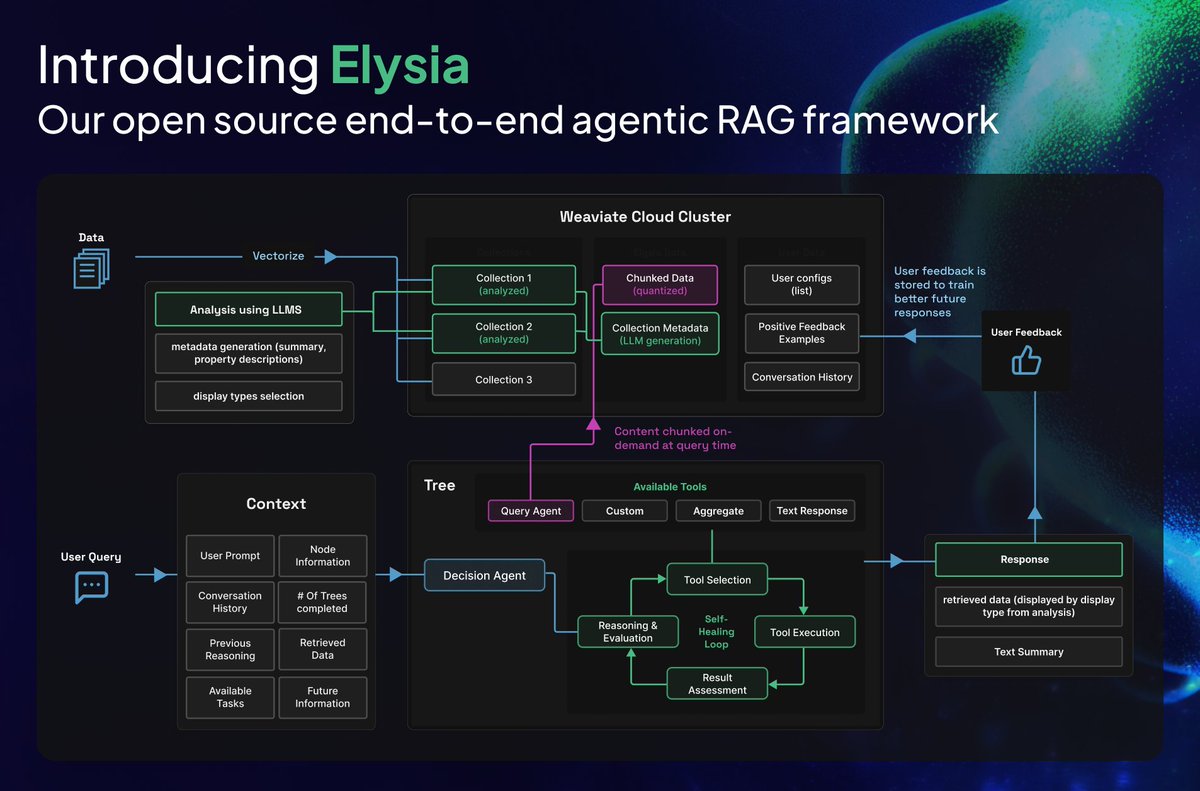
We just released an open source framework that sets up agentic search and RAG in a full web UI on your own data in just two terminal commands.
Meet Elysia - a decision tree based agentic system that dynamically displays data, learns from user feedback, and chunks documents on-demand.
Most AI chatbots are stuck in a text-in, text-out world. But what if your AI could dynamically decide not just what to say, but 𝗵𝗼𝘄 𝘁𝗼 𝘀𝗵𝗼𝘄 𝗶𝘁? Elysia is designed to completely rethink how we interact with data through AI.
Three features that set it apart:
🌳 𝗗𝗲𝗰𝗶𝘀𝗶𝗼𝗻 𝗧𝗿𝗲𝗲 𝗔𝗿𝗰𝗵𝗶𝘁𝗲𝗰𝘁𝘂𝗿𝗲: Unlike simple agentic platforms, Elysia uses a pre-defined web of nodes, each orchestrated by a decision agent that evaluates its environment and strategizes the best tool to use. You can watch the entire decision process in real-time.
🎨 𝗗𝘆𝗻𝗮𝗺𝗶𝗰 𝗗𝗶𝘀𝗽𝗹𝗮𝘆 𝗙𝗼𝗿𝗺𝗮𝘁𝘀: Elysia can choose from 7 different ways to present your data - tables, product cards, tickets, conversations, documents, charts, and more. It automatically analyzes your data structure and picks the most appropriate format.
🧠 𝗔𝘂𝘁𝗼𝗺𝗮𝘁𝗶𝗰 𝗗𝗮𝘁𝗮 𝗘𝘅𝗽𝗲𝗿𝘁: Connect your Weaviate Cloud instance and Elysia becomes an instant expert on your data. It analyzes collections, generates metadata, and understands your data structure before performing any queries.
Getting started is ridiculously simple:
pip install elysia-ai elysia start
That's it. You get a full web interface AND a Python library.
Bonus features we're excited about:
• Chunk-on-demand: No more pre-chunking everything • Feedback system that learns from your preferences
• Multi-model strategy for cost optimization
• Everything runs from a single Python package
We're already using Elysia to power the chat interface in our AI skincare app, Glowe. The entire project is open source and designed with customization in mind.
Get started:
🔗 GitHub: github.com/weaviate/elysia
📖 Demo: elysia.weaviate.io
🎮 Blog post: weaviate.io/blog/elysia-agen…
7
59
322
49,718
Charles Pierse retweeted
6 Aug 2025
Ever watched a loading spinner for 10 seconds waiting for your LLM to respond? 😅
Your users have too - and they're probably not happy about it.
Even the most powerful AI applications can feel sluggish when users have to wait for complete responses to be generated. But what if your app could start showing results immediately, creating a smooth, ChatGPT-like experience?
That's where 𝘀𝘁𝗿𝗲𝗮𝗺𝗶𝗻𝗴 comes in. Instead of waiting for the entire response to generate, streaming lets you display results as they're being created.
The Weaviate 𝗤𝘂𝗲𝗿𝘆 𝗔𝗴𝗲𝗻𝘁 now supports streaming responses out of the box, meaning you can:
• Show partial results as they arrive
• Keep users engaged during complex queries
• Reduce perceived latency without changing your infrastructure
Implementation? Easy peasy. The Query Agent handles all the complexity - you just enable streaming and watch your user experience transform.
Getting started is ridiculously simple:
• Available now for all Serverless Cloud users (yes, including free Sandbox!)
• Works with your existing collections
• No complex setup required
• Handles both search and aggregation queries automatically
Check out the docs to get started: docs.weaviate.io/agents/quer…
Sometimes the best optimization isn't making things faster - it's making them 𝑓𝑒𝑒𝑙 faster 🤔
6
15
1,759