Creative Technologist | VFX Supervisor | Gen AI
Joined February 2012
- Tweets 443
- Following 1,770
- Followers 246
- Likes 351
59 Photos and videos














cedro_x retweeted

FlexAvatar Code Release 📢📢
Now you can create your own 3D head avatars from any portrait image!
Code for custom avatar creation, rendering and interactive GUI available at:
👉 github.com/tobias-kirschstei…
18 Dec 2025

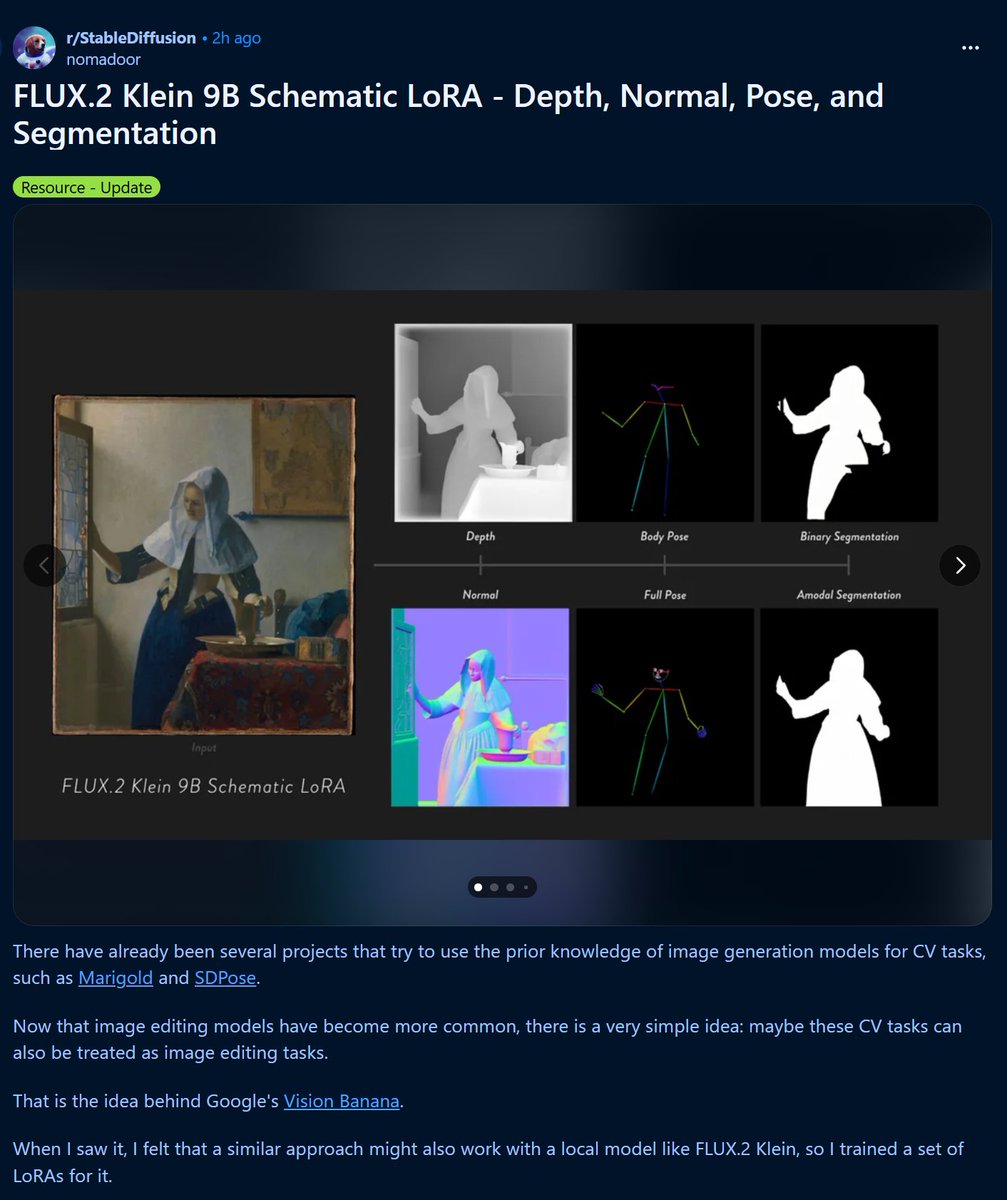
Want to create an avatar from a single image?
FlexAvatar is a transformer model that creates full 360°, high-quality, and expressive 3D head avatar from just a single portrait image in minutes.
Real-time Demo: FlexAvatar's lightweight architecture allows both animation and rendering in real-time, enabling interactive user experiences. To create a new 3D head avatar, only one image is required, e.g., from a webcam. The final avatar is ready after 2 minutes.
Architecture: Under the hood, FlexAvatar adopts a transformer-based encoder-decoder design. The encoder maps the input image onto a latent avatar space, while the decoder produces 3D Gaussian attribute maps by incorporating the animation signal via cross-attention.
The model learns all facial animations directly from the data without relying on pre-built 3D face models. This equips the avatars with realistic facial expressions.
The internal avatar latent space can be conveniently used to integrate additional observations of a person via fitting. This enables use-cases where more than one image of a person is available, e.g., from a phone scan of the person.
We train jointly on 2D monocular videos and multi-view data. However, in monocular videos, the animation signal leaks the target viewpoint, causing the model to produce incomplete 3D heads. We call this phenomenon entanglement of driving signal and target viewpoint.
To prevent entanglement, we introduce bias sinks. These are learnable tokens that indicate whether a training sample stems from a monocular or a multi-view dataset. During training, the model learns to produce incomplete 3D heads only when the monocular token is present.
During inference, FlexAvatar then always uses the multi-view token for which the model has learned to produce complete 3D heads. This simple design allows to combine the generalizability from monocular data with the quality of multi-view data.
FlexAvatar summary:
- Input: Single-image, phone scan, or monocular video
- Output: Full 360° head avatar
- Expressive animations
- Real-time rendering and animation
- Generalization to any portrait
- Create a new avatar in 2 minutes
- Use bias sinks to combine 2D and 3D data
🏠tobias-kirschstein.github.io… 🌍arxiv.org/pdf/2512.15599
🎥youtu.be/g8wxqYBlRGY
Great work by @TobiasKirschst1 and @SGiebenhain!
1
4
57
5,210
cedro_x retweeted
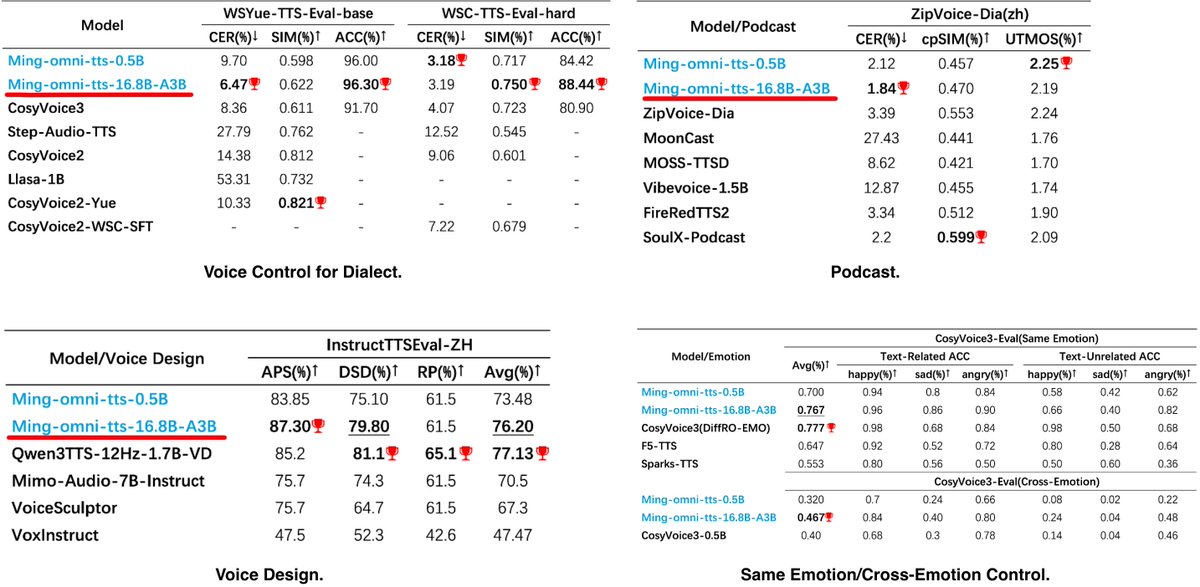
Ming Omni TTS 16.8B - 30GB monster for high-performance unified audio gen.
- speech, sound, music
- speed, pitch, emotion
- 93% accuracy on Cantonese dialects
- narrates complex math/chemical expressions
- zero-shot voice design
Optimized for high-speed, low-latency gen. Perfect for long-form content.
huggingface.co/inclusionAI/M…
13
104
4,449
cedro_x retweeted

Jun 15
Modality Forcing - turns FLUX.2.klein into 3D-aware models.
- joint RGB-D, I2D, and D2I synthesis in one model
- pixel-space depth tokenization
- preserves T2I quality via self-distillation
modality-forcing.github.io/
1
21
174
11,383

Jun 12
We are looking for a few Generative Artists. Please come and join me to make the next amazing Sphere project! sphereentertainmentco.com/jo…
25
cedro_x retweeted
Jun 12
Surflo. turns a few standard photos into clean 3D models for game dev/VR.
- creates usable meshes
- geometric consistency
- predicts millions of oriented surface points
- beats VGGT-1B and DepthAnything-3
anttwo.github.io/surflo/
4
46
324
14,838
cedro_x retweeted
Jun 12
VideoMDM- builds high-quality 3D human animations using regular 2D videos instead of expensive motion capture suits.
- Text-to-Motion
- Cheap scaling
- Captures complex motions
videomdm.github.io/
9
50
3,109
cedro_x retweeted

We present Wild3R for Feed-Forward 3DGS in the Wild🦁
Now, we can reconstruct appearance-consistent 3D scenes from unconstrained photos in a second🔥
Project page: furuschool.github.io/wild3r-…
ArXiv: arxiv.org/abs/2606.11894
2
14
112
14,894
cedro_x retweeted

Jun 11
This one is really neat. Not only can it repose according to a depth, but it preserves the general vibe and feel of the reference image as well.
Gosh, suddenly a lot of neat Flux Klein 9B loras to try ...
huggingface.co/thedeoxen/ref…

2
14
176
8,837
cedro_x retweeted
Jun 9
UniSHARP - universal sharp monocular view synthesis.
- supports perspective, fisheye, 360°
- 3.1s inference
- handles hidden areas with dual-layer geometry
- uses UniK3D 3DGEER
- SOTA fidelity.
insta360-research-team.githu…

4
52
3,148
cedro_x retweeted
Jun 9
SCAIL-2 just landed in ComfyUI.
huggingface.co/Comfy-Org/SCA…
Jun 9

HOT! SCAIL-2 just dropped!
End-to-end character animation via in-context conditioning
- no skeleton middleman, it copies pixels directly
- no glitches, no messy hands
- 512p/704p
- unified architecture for character replacement and multi-character tasks.
- zero-shot generalization to animal-driven and mesh-based control.
teal024.github.io/SCAIL-2/
2
41
277
21,633
cedro_x retweeted
Jun 9
HOT! SCAIL-2 just dropped!
End-to-end character animation via in-context conditioning
- no skeleton middleman, it copies pixels directly
- no glitches, no messy hands
- 512p/704p
- unified architecture for character replacement and multi-character tasks.
- zero-shot generalization to animal-driven and mesh-based control.
teal024.github.io/SCAIL-2/
10
68
463
44,682
cedro_x retweeted

Gaussian splats are incredible—until you want them to move. Normally, that means crazy 4D capture setups.
Not anymore. Here is how anyone can rig and animate static splats using Mixamo. Blender playback can get brutal, so big props to @playcanvas—their brilliant Super Splat sequence import saves the day.
🧵 Watch the full tutorial breakdown in the comments!
4
35
250
16,399
cedro_x retweeted
Jun 5
ComfyUI Higgs v3 TTS.
Full‑featured nodes for Higgs TTS, as usual.
- Inline emotion, style, prosody, and SFX tags.
- Zero-shot voice cloning Whisper transcription.
- Multi-speaker
- Longform text chunking
github.com/Saganaki22/Higgs_…

Jun 5
These voices sound pretty impressive.
- Zero-shot voice cloning
- 20 emotions, styles
- Granular prosody adjustments
- 24 kHz sample rate, 8k token context length
- SOTA performance
huggingface.co/bosonai/higgs…
2
20
128
9,445
cedro_x retweeted

Jun 4
LaVR renders existing videos with new camera paths. It keeps scenes geometrically consistent while avoiding the distortions, hallucinated objects, and wrong camera motion
lavr-4d-scene-rerender.githu…
2
11
88
5,205
cedro_x retweeted
Jun 3
Stability AI drops Stable-Layers, a new method for splitting images into editable layers. Cleaner separation and fewer artifacts
stability-ai.github.io/stabl…
3
16
162
7,346

Jun 2
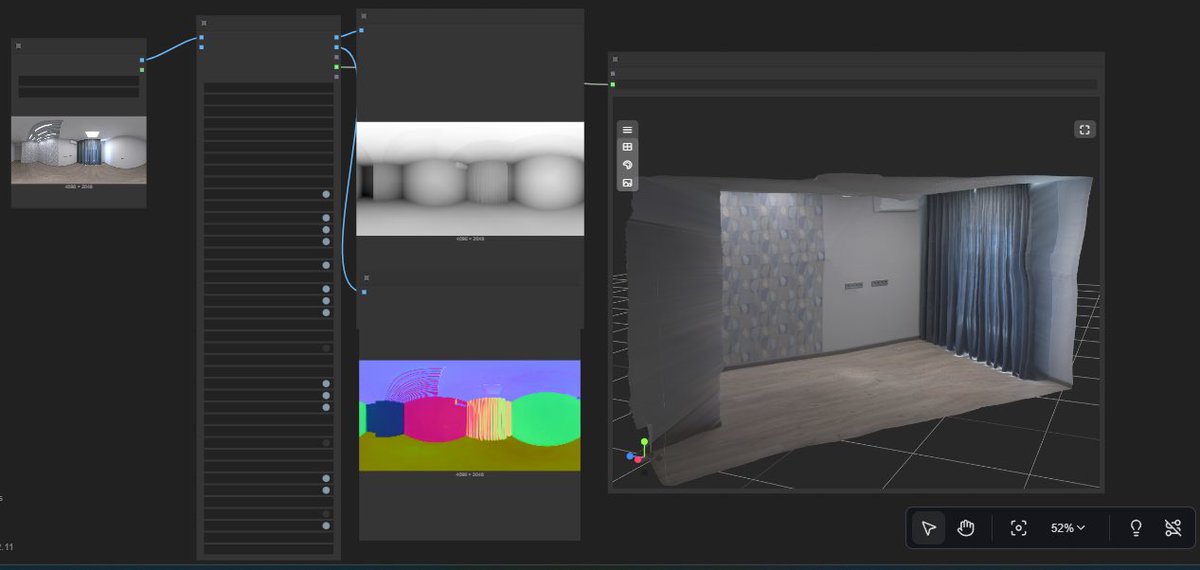
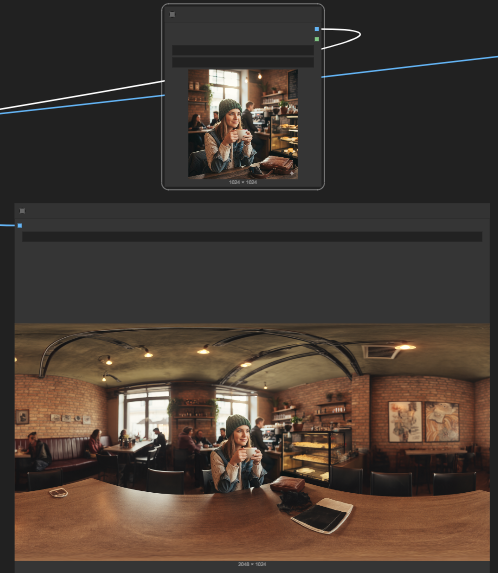
I updated SPAG4D to include PaGeR. Geometrically consistent 360-degree scenes from single panoramas. Best alignment I've seen. pager360.github.io/ github.com/cedarconnor/SPAG4…
1
40
cedro_x retweeted

Jun 2
We're excited to share Stable-Layers!
We train Qwen-Image-Layered further with RL for improved layerization,
using only feedback from a VLM — no paired supervision required!
Paper: arxiv.org/abs/2605.30257
Project Page: stability-ai.github.io/stabl…

12
51
273
18,105