
981 Photos and videos









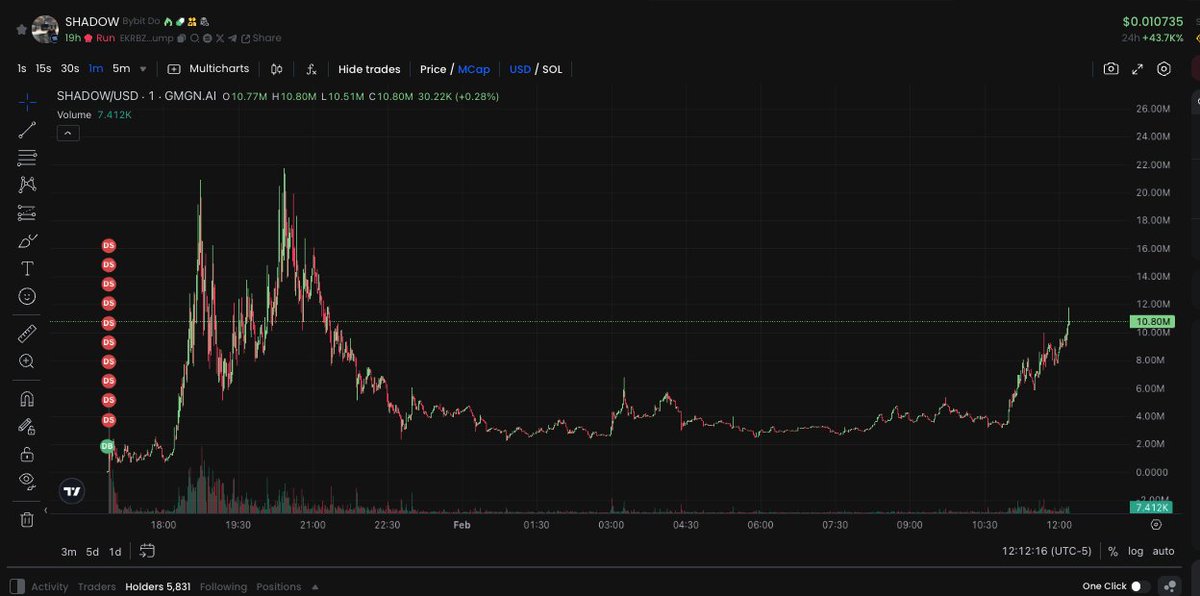
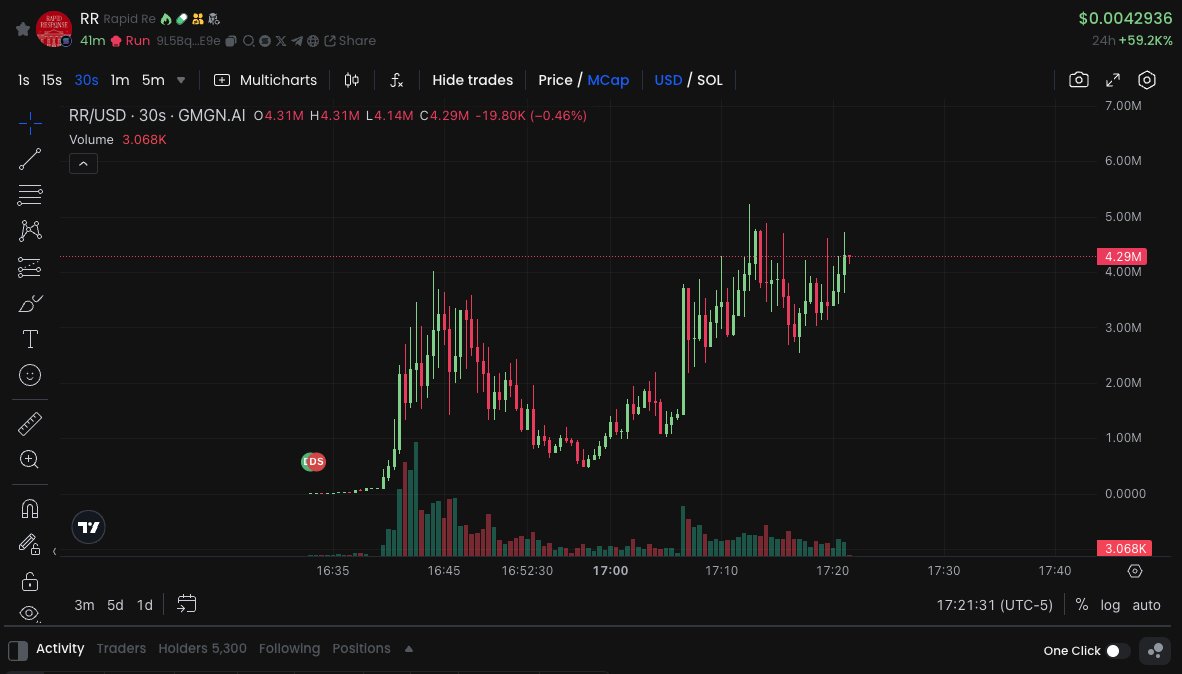
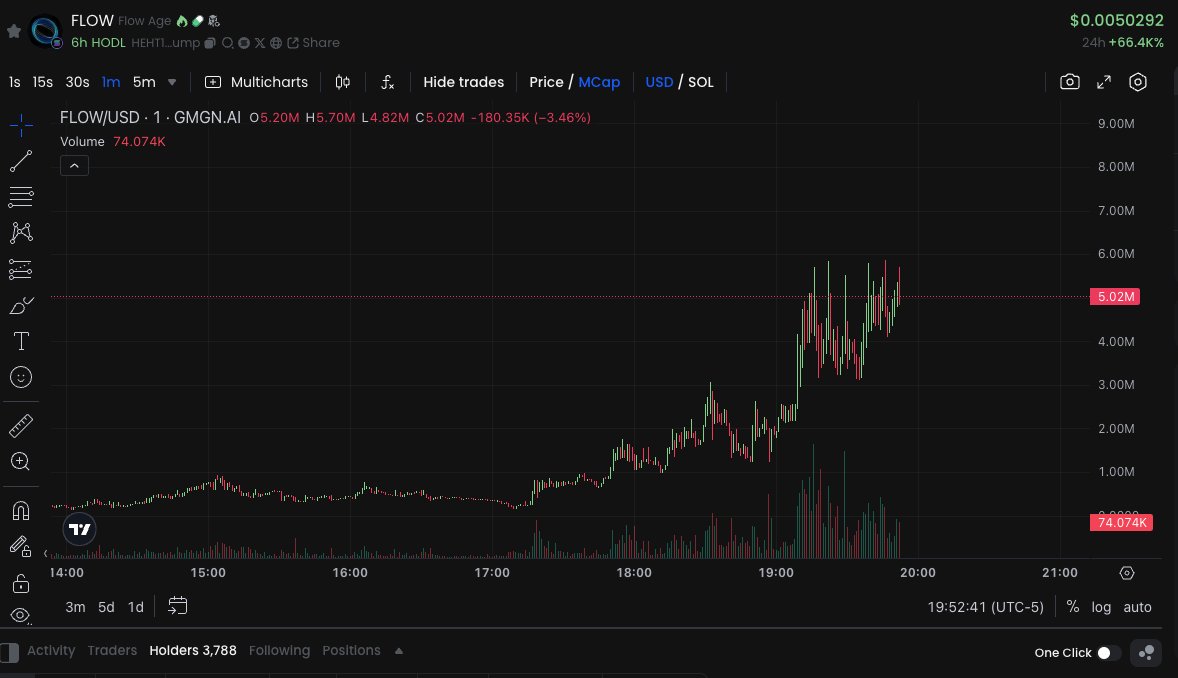

Mar 25
Mar 20

🚨 Macrocosmos runs @Apex_SN1 SN1. @IOTA_SN9 SN9. @Data_SN13 Universe SN13. The most underrated team in the entire $TAO ecosystem achieved something that will accelerate every decentralized training run on Bittensor.
Same problem. Two different attacks.
Templar SN3 hit communication with PULSE for Covenant-72B 💪
Macrocosmos is attacking it from the compression side 🧠
Both working.
Recently, Jensen of Nvidia heard about Templar from Chamath.
They are just getting started.
The results they are producing right now are the kind of breakthroughs that look boring in a chart and world-changing in practice.
On Apex:
They ran two parallel competitions for matrix compression the algorithm that determines how fast data transfers between nodes during decentralized training. Lossy and lossless. Open to anyone. Humans and agents. 3,899 submissions on the lossy track. 2,256 on the lossless track. 104 improvements on lossy alone.
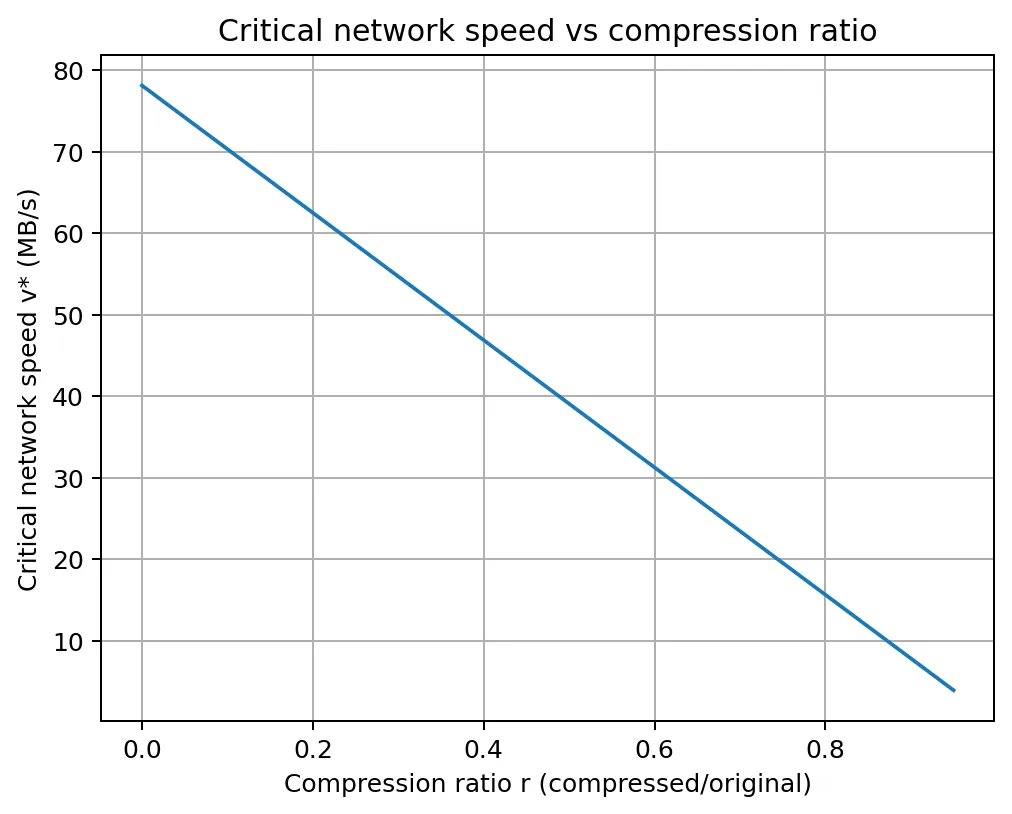
The result: 3x reduction in data transmission size. The best lossy compression ratio went from 0.65 down to 0.280. Look at that chart, a staircase of continuous improvement over three months as competitors forked each other's solutions, improved them, and resubmitted.
Every solution open-sourced programmatically after a day. The competitive dynamics drove an evolutionary optimization process through the solution space.
Zero tokens used. No LLM inference costs. Just pure algorithmic competition producing a result that directly accelerates IOTA's distributed training.
The single biggest bottleneck in decentralized training is not compute power. It is communication. When thousands of devices across the globe are training a model together, they need to share gradient updates every epoch. Those updates are massive neural activation tensors. The speed of training is limited by how fast you can transfer those tensors between nodes.
Macrocosmos just made that transfer 3x faster. Their winning algorithm strictly improves latency for any network speed below 50 MB/s. That covers the vast majority of consumer devices connected over the public internet, which is exactly the hardware that decentralized training runs on
Macrocosmos has three foundational layers every decentralized AI system needs. These subnets are not flashy.
Apex SN1 runs open research competitions.
IOTA SN9 uses those breakthroughs to accelerate distributed training.
Data Universe SN13 supplies the real-time data pipeline that feeds everything.
They just launched the IOTA Simulator Competition a digital twin that runs 250x faster than real time. Miners compete on path planning (optimal routing based on speed, latency, load, and topology) and network optimization. This is the exact problem that decides whether decentralized training can beat centralized data centers.
IOTA now has contributors from 58 countries. Training from anywhere, resilient against any single point of failure.
Data Universe just shipped the `dv` CLI a Rust tool that lets you query live social data from X and Reddit with one command. Built for agents: full JSON schema output so Claude or any LLM can use it natively. Already 2,500 subscribers pulling massive datasets (273M records, 91.7 GB collections).
The founder @macrocrux put it best:
“AI is a nascent science. Warehouses packed with gaming hardware are brute forcing noisy data. Soon we will figure out how to do this the elegant way, and then the progress begins.”
That elegant way is exactly what Macrocosmos is building: systematic optimization of every bottleneck through open competition.
30,000 submissions. Full open-sourced algorithms. 3x compression breakthroughs. Covenant-72B already proved decentralized training works at scale.
The most important work is always the least visible, don’t go viral, get attention, but they are the foundation everything runs on.
The gap between decentralized and centralized training is closing faster than most people outside Bittensor realize.
$TAO
DYOR

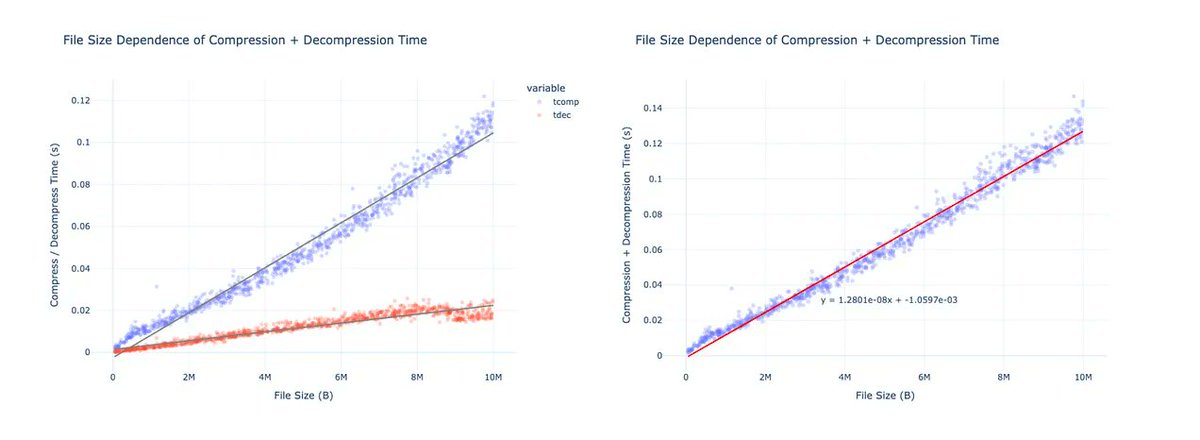
1
98

25 Apr 2025
1
1
154


15 Apr 2025
$SOL 😮😮😮😮
15 Apr 2025

SOL ETF STACK
CANADIAN LAUNCH
• world's first spot solana etfs launching tomorrow through purpose, evolve, ci, and 3iq
• td bank providing direct staking infrastructure for all sol etf products
• etfs will hold native sol tokens with integrated staking yielding ~7%
• four major firms received regulatory clearance simultaneously
MARKET DYNAMICS
• sol price up 25% weekly compared to eth's 11% gain
• sol network hitting 355m weekly transactions
• regulatory green light from ontario securities commission confirmed
• launching ahead of us eth staking etf decisions set for june 1
STAKING STRUCTURE
• full staking integration available on day one
• direct token custody model approved for canadian sol etfs
• staking rewards distribution built into etf structure
• first regulatory approval for pos rewards in regulated crypto etf
30
4 Apr 2025
Oh my, this escalation is now taking the next step.
Stay safe folks, position yourself accordingly.
Generational entries will be coming, being cash heavy right now is the key.
4 Apr 2025

The "World War 3" of Trade Wars Has Begun:
Americans are waking up to the first MAJOR tariff retaliation against President Trump.
China has announced 34% tariffs on ALL US goods with the S&P 500's 2-day losses now at -$3.5 TRILLION.
Here's what just happened.
(a thread)

62
2 Apr 2025
😮😮
2 Apr 2025

The markets will see crazy volatility today especially in 6 hours from now as Trump will hold a speech to the nation. Tariffs will fully go into effect today. You should expect more red and blood if Trumps announces tariffs, especially against Europe or exit of NATO
53
12 Mar 2025
Be careful, folks, plan accordingly.
12 Mar 2025
Placing new short orders in the region of 87-88k, if market allows to visit I will add more shorts on the existing position of 90k. My next big move target is 74-70k. My two targets of 83k and 78k have been hit! Now waiting for the third target to be hit very soon.

121
7 Mar 2025
$BTC 😮😮
7 Mar 2025
Expecting 50-60k again in the coming months
It will be a huge correction before continue up
120-150k will most likely be at end of year
94
3 Feb 2025
My goodness, is the carry trade continuation upon us?
2
196