
PhD, political scientist @polscicph @uni_copenhagen. Retrospective voting, social groups, political behavior.
Joined August 2015
- Tweets 1,905
- Following 2,101
- Followers 1,077
- Likes 17,338
51 Photos and videos








Pinned Tweet

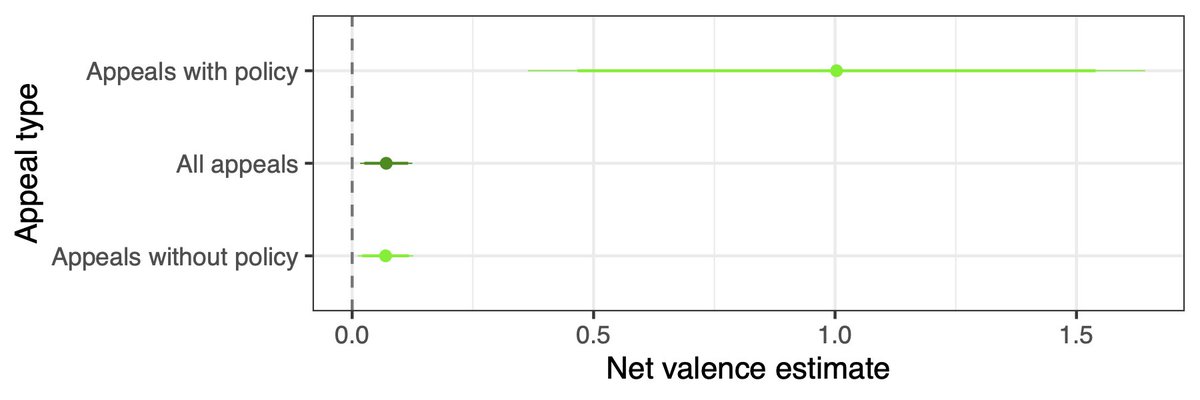
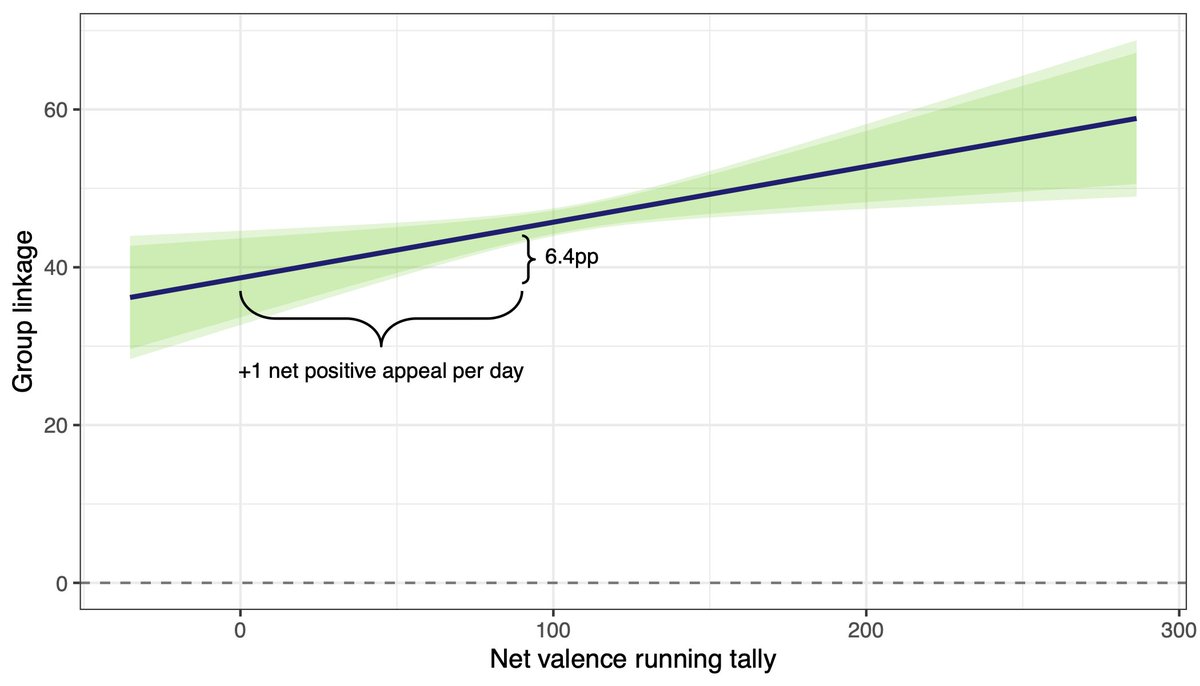
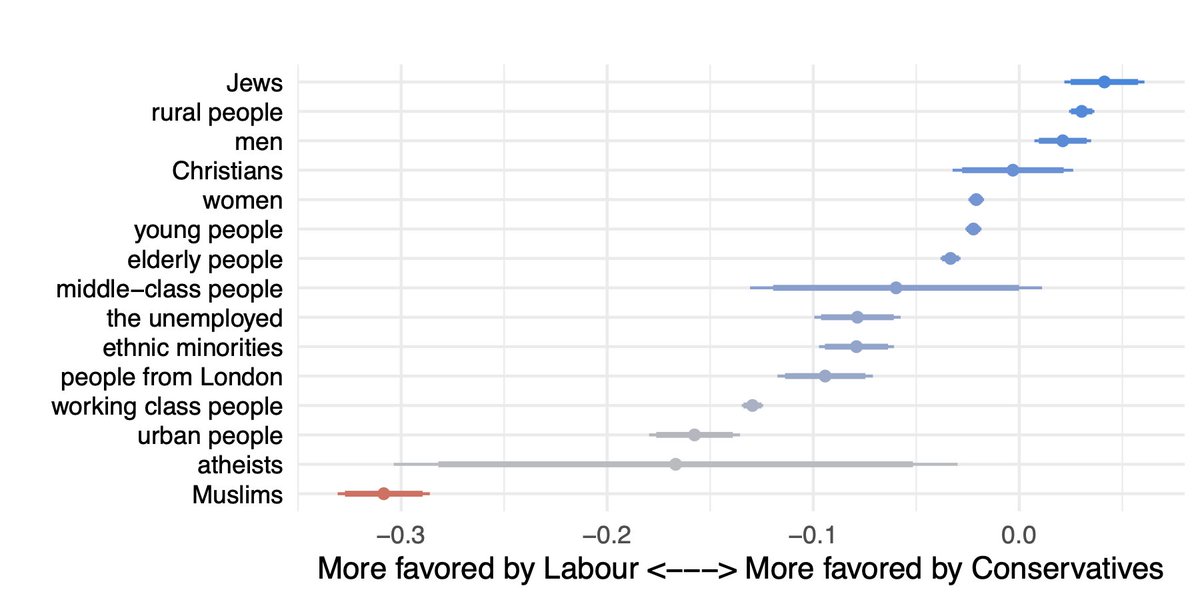
Very excited that the first paper of my PhD is out in @AJPS_Editor! 🎉
I theorize and test the idea of "group-based" economic voting using experimental observational evidence from Denmark UK US.
1/🧵
4
24
114
6,999
Christoffer H. Dausgaard retweeted

A lot of interesting policy debates turn out to hinge on really tedious methodological questions.
slowboring.com/p/the-neglect…
3
6
59
23,957
Christoffer H. Dausgaard retweeted

🚨New NBER working paper alert 🚨
🤔2021–2024 was the worst U.S. inflation in four decades. The question: Did voters react to the rising prices, or to the shrinking paychecks?
😱We approached this paper with one major surprise: there is no official measure of inflation at the county level in the U.S.
🌟To study the relationship between inflation and electoral outcomes during, we first had to construct local inflation measures using county-level data on family budget costs and incomes.
The answer? -> Check it out! 👇
🔗 nber.org/papers/w35301



6
51
263
57,917
Christoffer H. Dausgaard retweeted

Jun 8
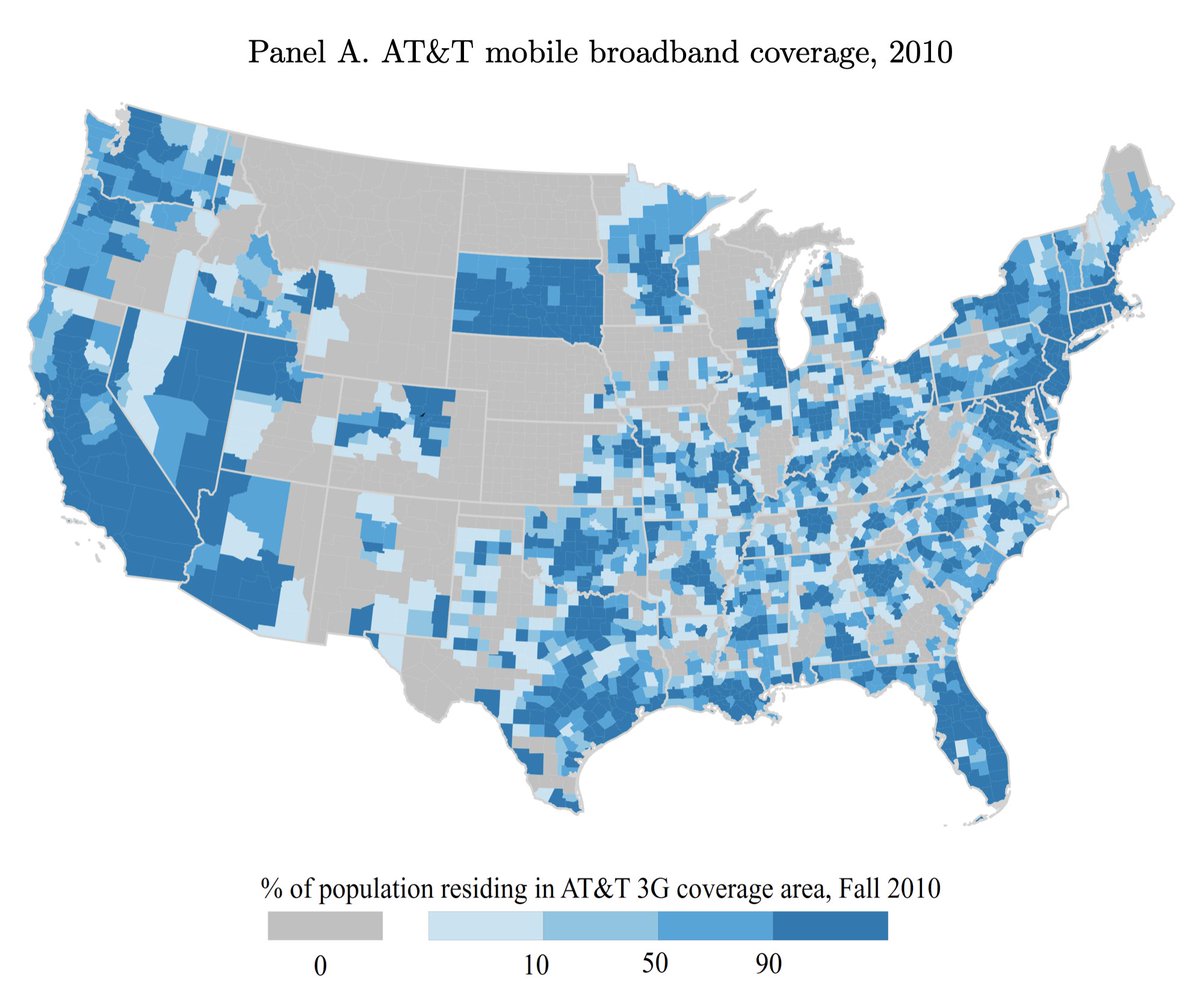
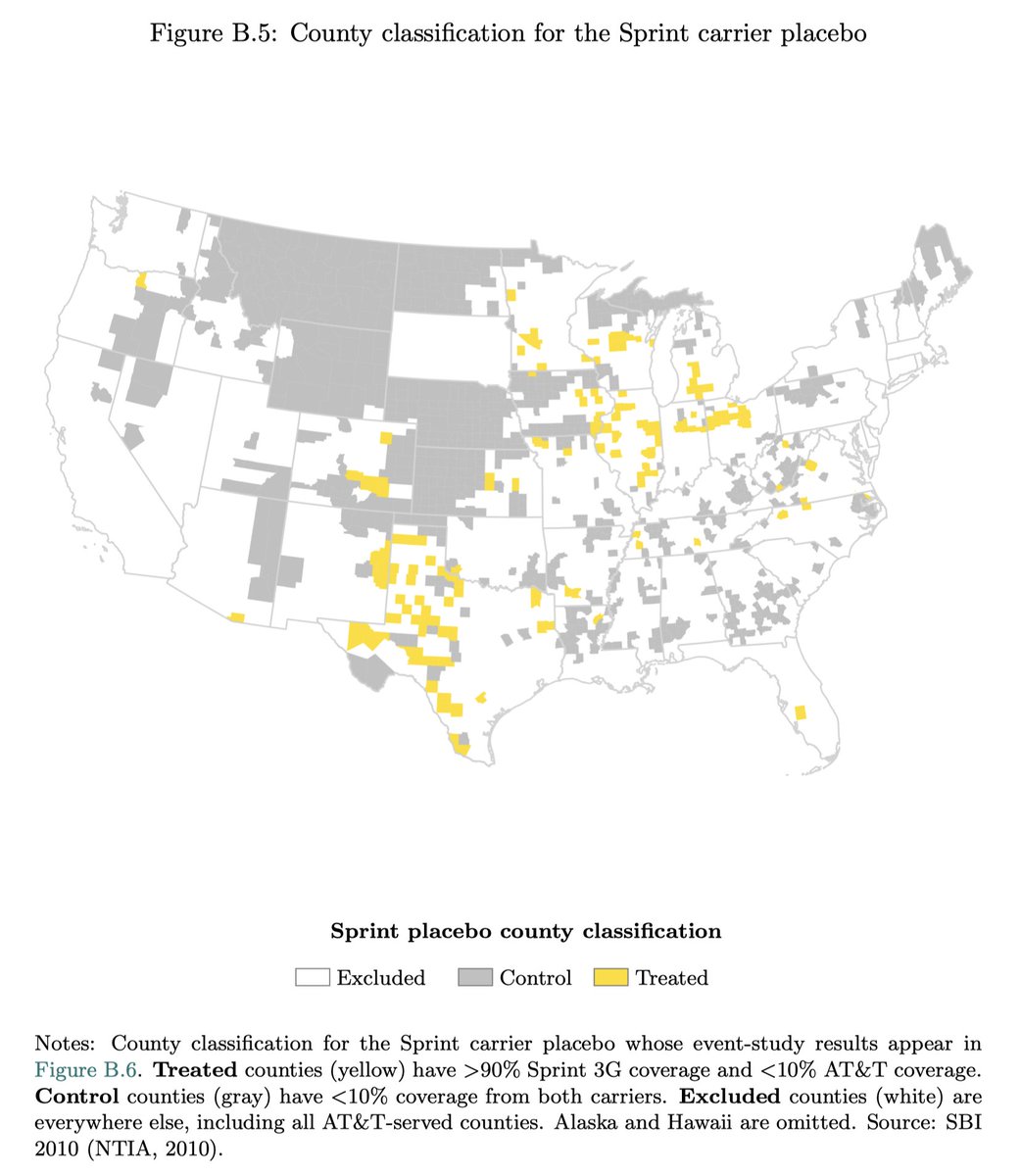
I fear that the new cellphones-cause-low-fertility NBER working paper has found a potentially genuine divergence between the fertility rate in rural and urban counties in the US, then labelled it "iPhone."
The problem is that AT&T coverage was heavily urban, resulting in an imbalance between the control and treated group.
The matched Poisson regression is supposed to address that by overweighting the small number of notionally urban counties that did not have iPhone coverage. But I believe that by "urban," they mean counties in which just 33% or more of the population were in towns of 2,500 people. It would therefore included a lot of places that are, in fact, rural.
To me, it seems like there's a failure of identification.
Hence, the SDiD result could reflect iPhones or a differential effect of the Panic of 2007 on rural and urban areas. We don't know.
The other-carrier placebos are also uninformative because they are structurally incapable of reproducing the urban-rural confound, given how they are mapped.
The paper is here: nber.org/papers/w35310.

19
61
394
53,804
Christoffer H. Dausgaard retweeted

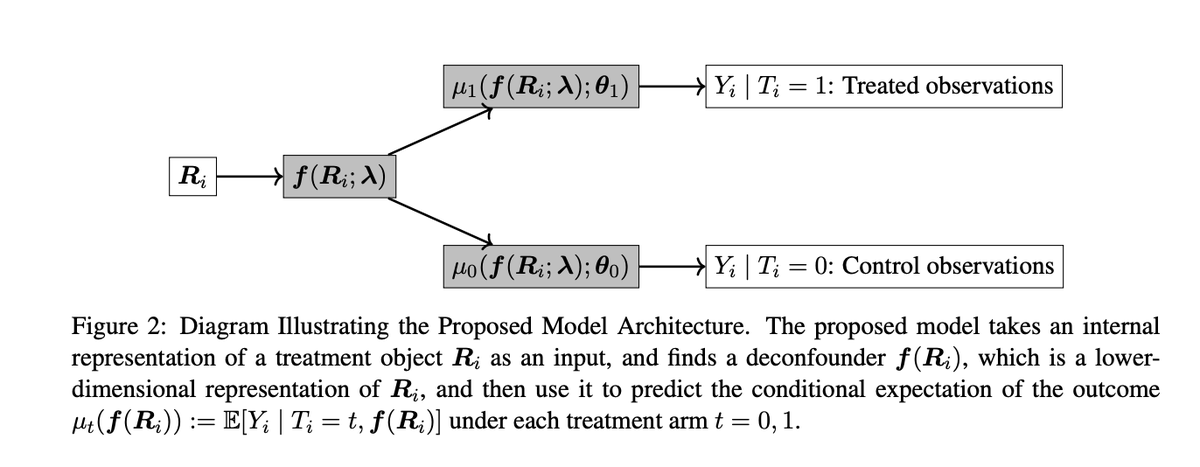
Did the treatment work because it included moralizing language, as your theory predicted, or because it was packed with political references and written in an informal style?
A new JASA paper by Imai and Nakamura offers a clever approach to these questions and others: leveraging generative AI models to extract and control for latent confounds.
As researchers start relying more on generative AI outputs as treatments, this kind of approach serves as a useful post-hoc robustness check. But this isn't solely for AI-generated treatments. It also works for human-generated treatments, since the vast semantic information captured by these models can help adjust for features we may have trouble measuring or articulating.
Exciting to see an emerging workflow that uses AI at multiple stages of the experimental design process.
imai.fas.harvard.edu/researc…
7
50
3,544
Christoffer H. Dausgaard retweeted

Jun 2
Forthcoming in the AER: "Taxing Top Wealth: Migration Responses and their Aggregate Economic Implications" by Katrine Jakobsen, Henrik Kleven, Jonas Kolsrud, Camille Landais, and Mathilde Munoz. aeaweb.org/articles?id=10.12…
43
127
26,146
Christoffer H. Dausgaard retweeted

May 28
Want to use agents like Codex or Claude Code to speed up academic projects? Want to tell the agents what changes to make to each figure and table and then watch the changes appear in the book, dissertation, or article? Then, you might find repo helpful. ...
Feb 24

Codex has taken the pain out of finishing a data-heavy book. Here’s a paragraph about it. I use high effort for planning, medium for execution with a ChatGPT plus. Yet to hit a limit, despite talking to it many hours a day (using Wispr Flow). Academia sure is changing.

1
4
22
3,130
I mean this is just pretty obviously collider bias, right?
By conditioning on Nature comms acceptance it induces a spurious negative correlation between reviewer leniency and paper quality. Very obvious that papers that *survived* tougher reviews are higher quality on average.
May 25

People often complain about tough peer reviews
But papers that elicited stronger criticism from reviewers and required more-extensive revisions received more citations tha did papers that drew light comments and sailed through the peer-review process.
We need to embrace constructive criticism if we want to do stronger work. nature.com/articles/d41586-0…

3
14
126
17,211
Christoffer H. Dausgaard retweeted

May 26
I have been testing it *very* extensively, and I think that, as of right now, the confidence is warranted. However I do think that people should have a clearer sense of what it's saying when it says something is 100% AI generated. It breaks the item down into chunks, generally 350-400 words, and makes a prediction about whether that chunk contains some AI. So "This paper is 100% AI generated" really means "100% of the tokens in this paper are in a chunk that we believe has AI in it".
3
3
102
9,696
Christoffer H. Dausgaard retweeted

May 25
Oof this paper is a bit of a worry. nber.org/papers/w35240?utm_c…
4
15
93
13,102
Excellent and thoughtful piece.
May 25

New Substack piece where I argue for the need to give symmetrical explanations of political beliefs--you can't explain the ones you don't like by saying they serve some psychological or social need and the ones you like by saying they just reflect the evidence. Link in the reply.

1
3
399
Christoffer H. Dausgaard retweeted

May 20
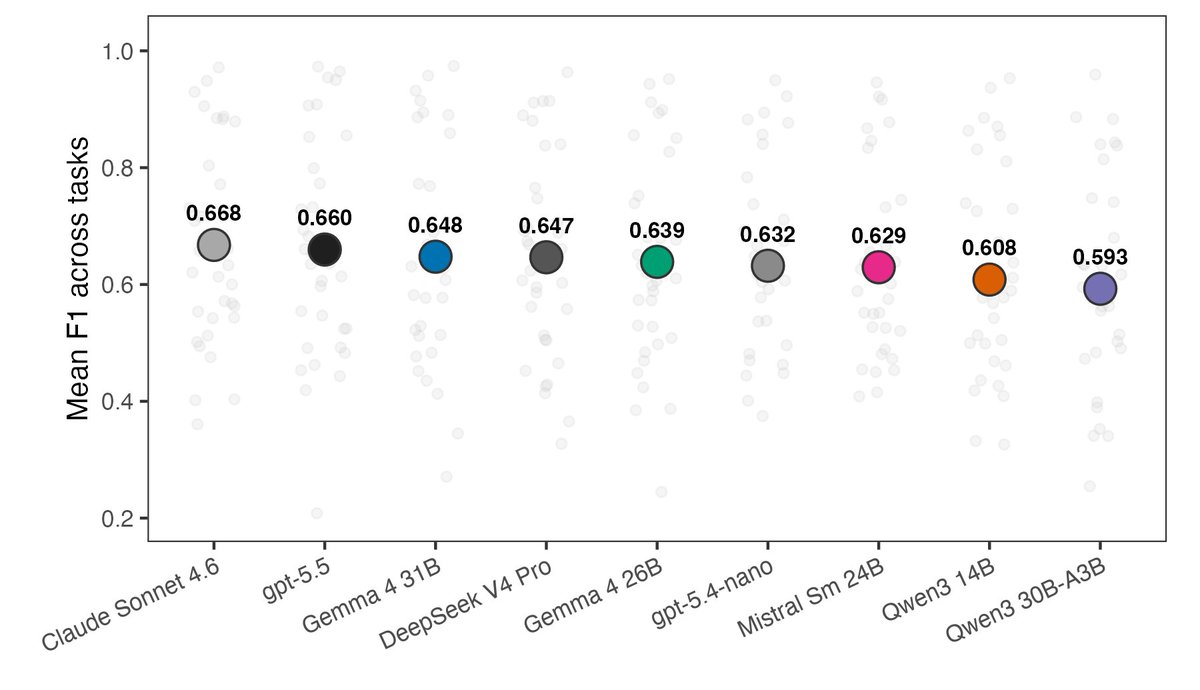
Update on my benchmark of local vs. commercial LLMs for text classification, focusing on political science applications.
I compared 5 local open-weight models with 4 API models on 34 coding tasks (~147k predictions). Tasks include tweets, news, survey responses, policy texts, etc
The best local LLMs are often close and sometimes perform better. Local models match or exceed API on 9/34 tasks. The average API advantage is pretty small, at 0.015 F1.
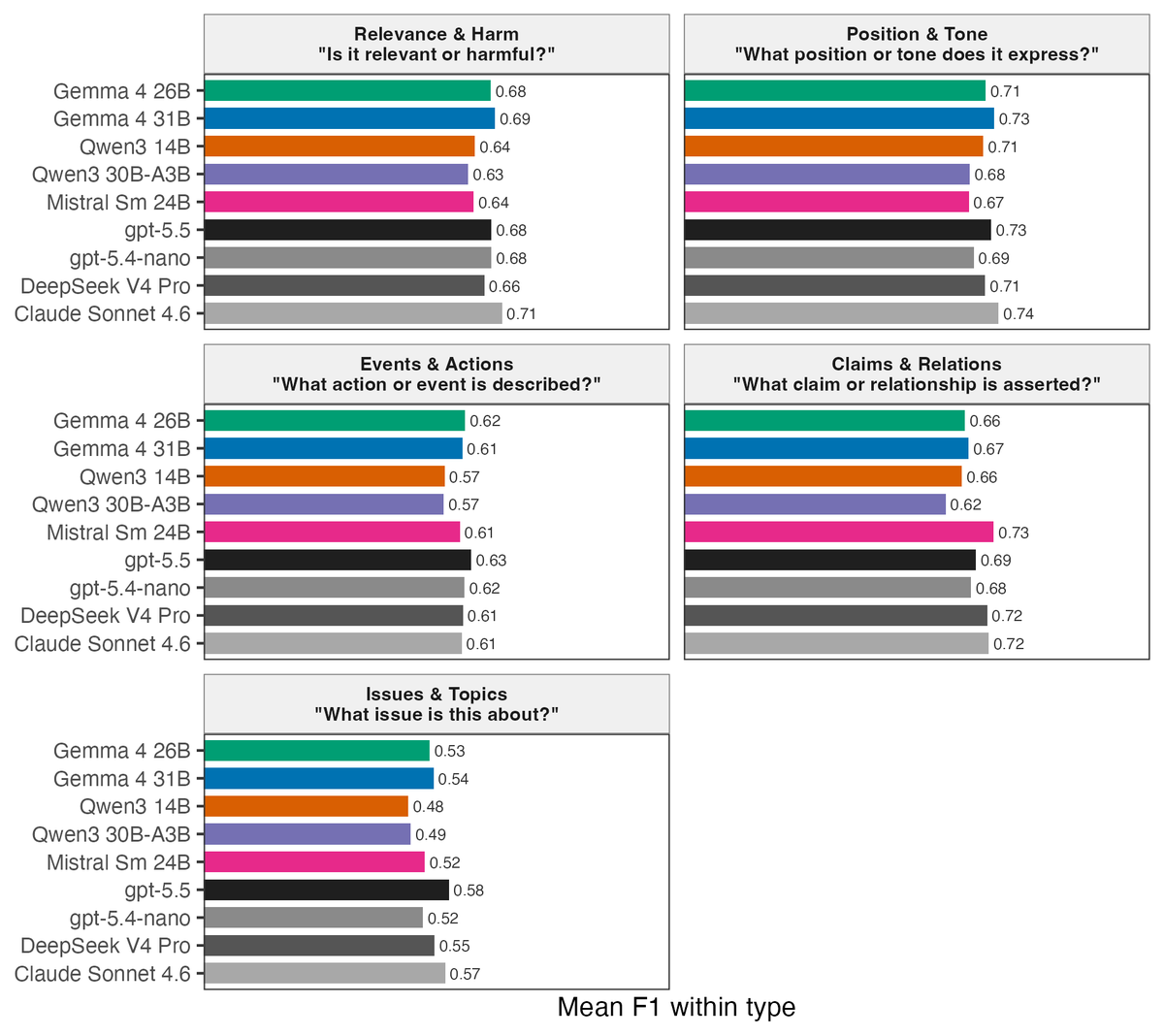
3
17
45
5,397
Christoffer H. Dausgaard retweeted

May 14
The local elections in one chart. Labour has been squeezed between the Greens in young wards and Reform in older working-class wards

87
511
4,844
689,637
Christoffer H. Dausgaard retweeted

🚨Early version of my JMP! 🚨
To what extent is the contact between corporate lobbyists and federal government officials publicly disclosed?
In other words, how big is the market for "shadow lobbying"?
The Lobbying Disclosure Act mandates quarterly disclosure of lobbying "contacts" subject to many caveats. Watchdogs have long complained about lacunae in the LDA, but there is little evidence of the size of shadow lobbying market.
In my JMP, I use 4.5 trillion pings from 179 million smartphones spatially merged to building shapefiles and observe movement between lobbyists' offices, corporate headquarter buildings, and the federal government in Washington DC.
See below: movement of lobbyists from corporate HQs to federal government buildings:
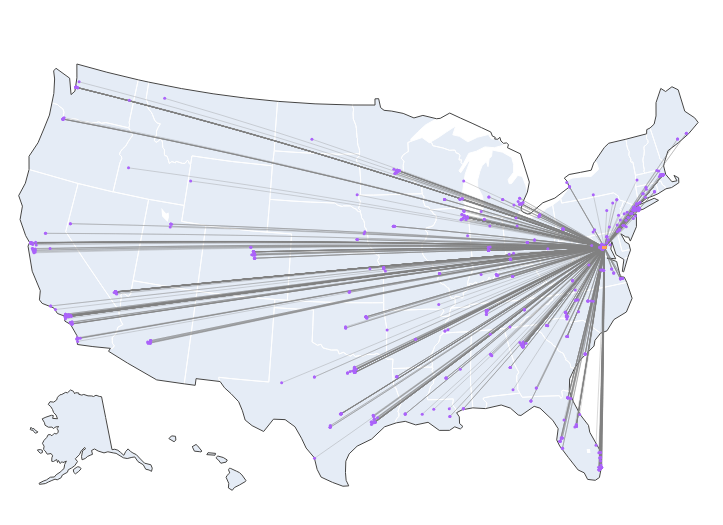
ALT Movement of lobbyists from corporate HQs to federal government buildings in Washington DC.
10
76
436
147,155
Christoffer H. Dausgaard retweeted

May 13
1/ New @Nature! We study how powerful institutions shape the information environment for LLMs. Commercial LLM training is opaque, so we trace a path from state-coordinated media -> training data -> model responses.

4
69
177
26,700
Christoffer H. Dausgaard retweeted

May 10
The reason elite chess players have lower IQs is the same reason "successful founders dropped out" is bad advice.
Once you select for the top of any field, the traits required to get there become negatively correlated. Elite chess players need both IQ and chess-specific skill. Within them, the lower-IQ players must have higher pure chess skill to compensate, or they wouldn't be elite. The correlation is mechanical. It comes from how you drew the sample.
Apply this to founder advice. Among the general population, education and outcomes correlate positively. Among elite founders, dropouts had to compensate with something else: world-class technical skill, family capital, or an exceptional network. The "missing" trait in dropout-founders forced the other traits higher. Copying the dropout move without the compensating trait does nothing.
Every refrain from a top performer follows this pattern:
"I never networked, I just built great products." Within elite founders, the ones who skipped networking had exceptional products. The constraint selected for them.
"I sleep 4 hours a night." Within elite executives, sleep trades against output. In the general population, less sleep correlates with worse cognitive performance. You're hearing the substitution pattern of survivors.
"I don't read books." A top 0.01% operator who doesn't read requires compensation somewhere: raw memory, decades of operating reps, or a network that fed them what books would have.
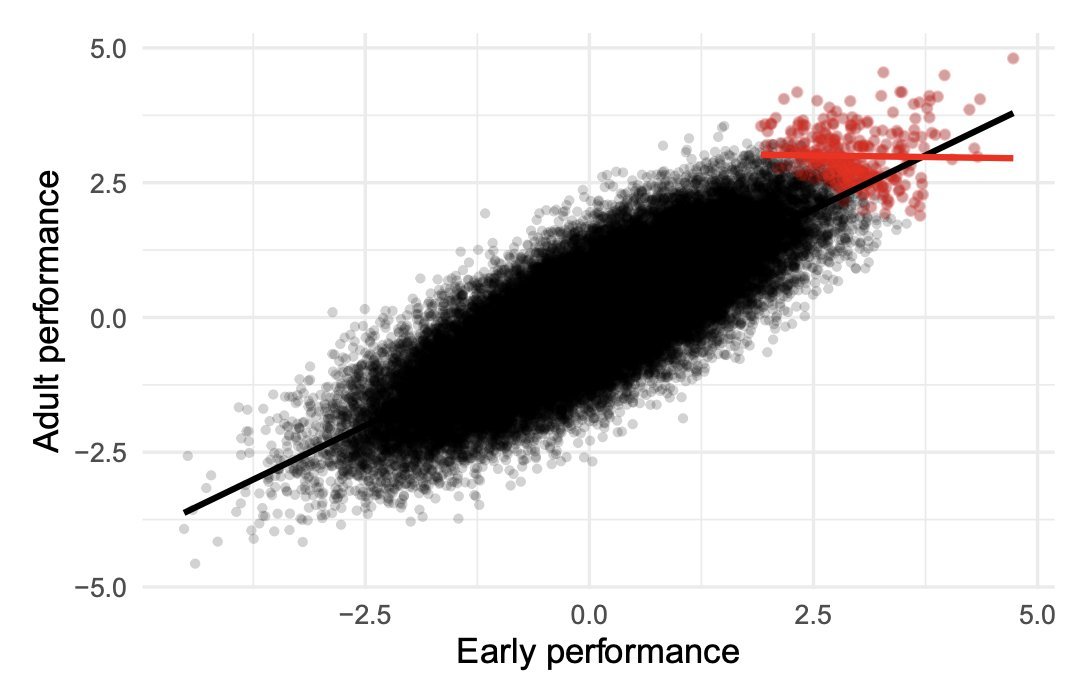
The chart is the cleanest version of this you'll ever see. Black dots are the full population, strong positive correlation between early and adult performance. Red dots are the elite subset. Slope near zero.
Every advice book lives in the red dots. Every "what makes top performers different" study lives in the red dots. Every Forbes profile lives in the red dots. You're learning the substitution patterns of people who already won. Their path is in the red dots. Yours lives in the black.
When someone elite tells you what made them successful, the real question is what they had to be elite at to have the option of skipping the conventional path.

Among elite chess players, those with the lowest IQ are the best.
Among NBA players, the shortest ones are the best.
Among Hollywood actors, the least attractive are the most talented.
Among elite academics, those with poorer early academic performance are the best.
Among people with high LDL & high plaque burden, LDL is barely correlated with plaque burden.
Learn collider bias. Nice catch by @AlexTISYoung
36
283
1,892
310,372
Christoffer H. Dausgaard retweeted

May 10
There are so many insane wildly misleading stories coming out about data centers almost every day now that I'm mostly having to give up on commenting on them to focus on actually getting blog posts out, but it feels like a tsunami. I'll share one from just today as an example.
60
270
2,645
412,434
Christoffer H. Dausgaard retweeted

May 4
Sharing a video based on my recent @SociologicalSci article: youtu.be/5OAXBmBmQEY?si=bY5R… via @YouTube. The prominent finding that U.S. policy ignores average citizens and lower income groups results because of Simpson’s paradox. More here: medium.com/p/b60d0440e756.
3
22
82
58,271
Christoffer H. Dausgaard retweeted

May 4
ICE is everywhere.
In 2022, @ICEgov made arrests in 30% of counties.
In 2025, @ICEgov made arrests in 62% of counties.
We ask: Do ICE arrests spark political action?
Theory and prior evidence suggest it should.
We find that ICE activity mostly does not mobilize citizens.


4
25
96
17,431
Christoffer H. Dausgaard retweeted
Apr 30
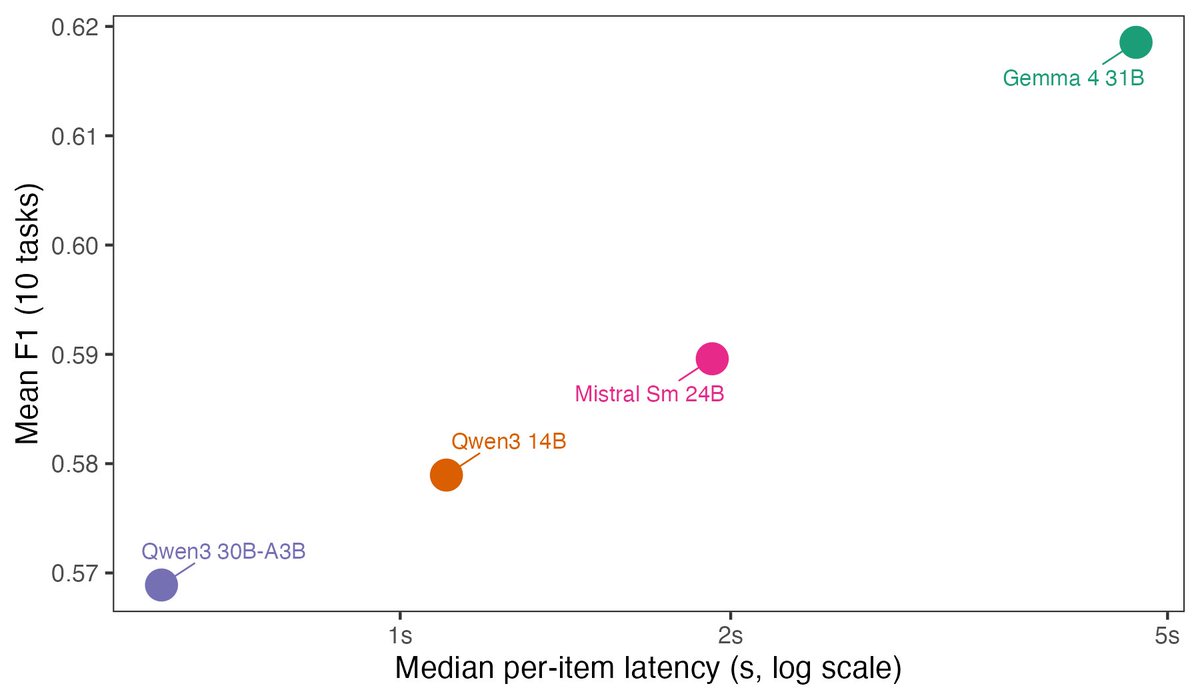
For applied research in political science / social science, there aren't many benchmarks of how the most recent local open-weight LLMs compare with commercial API calls for classification tasks.
I was running a small one, might be useful for others. I ran four local models against gpt-5.5, gpt-5.4-nano, and Claude Sonnet 4.6 on ten political science classification tasks (500 items each). The top three (gpt-5.5, Claude Sonnet 4.6, and the local Gemma 4 31B) tie within 0.002 mean macro F1, and all seven fall within 0.05. Total: 35,000 predictions across seven models on a 32 GB M2 MacBook.
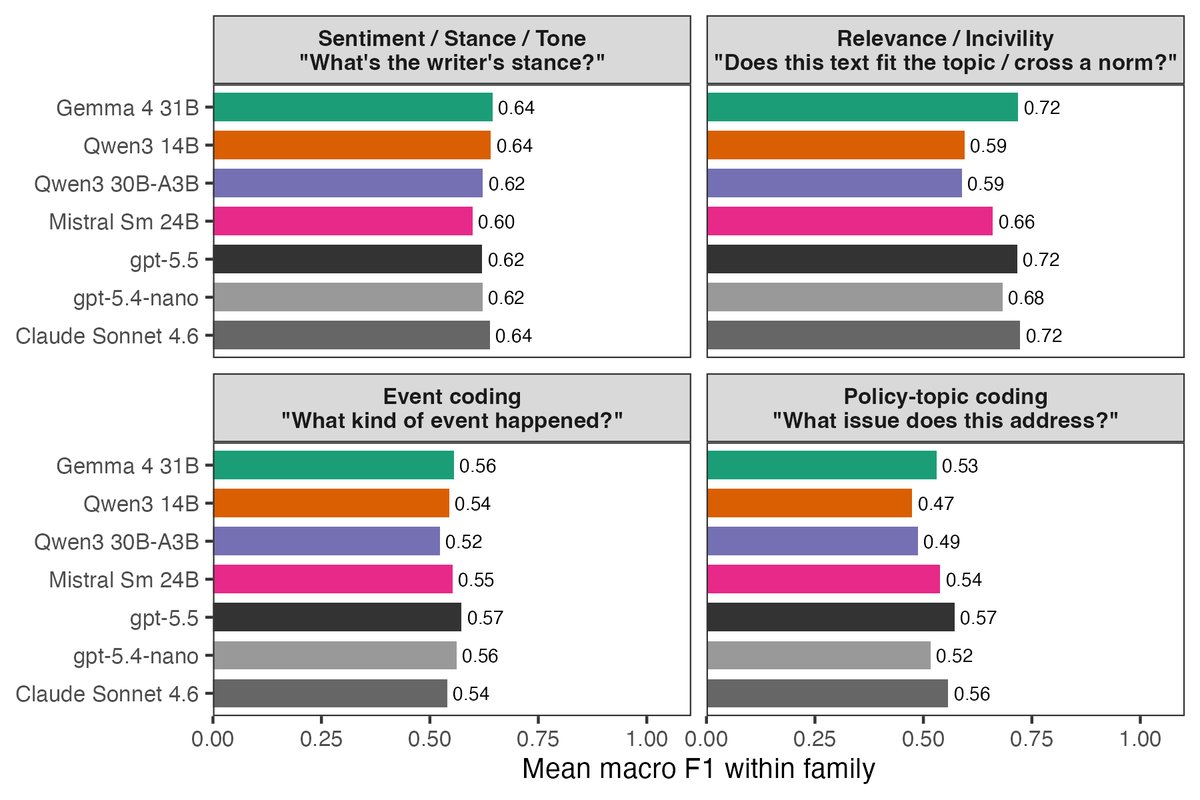

2
14
54
7,750
Cannot recommend this enough.
High quality papers, excellent papers, great company.

🚨 The 6th *Nordic Political Behavior Workshop* takes place in Copenhagen on September 24-25, 2026.
Come for high-quality feedback and great networking opportunities.
Abstract deadline: May 29.
Read more and apply here:
politicalscience.ku.dk/event…
Please distribute widely!
1
3
492