
Political economy, corporate taxation, professional labor markets. PhD in Accounting, University of Florida. On the 2026-2027 academic job market.
Joined March 2023
- Tweets 583
- Following 282
- Followers 380
- Likes 1,572
11 Photos and videos







Pinned Tweet
🚨Early version of my JMP! 🚨
To what extent is the contact between corporate lobbyists and federal government officials publicly disclosed?
In other words, how big is the market for "shadow lobbying"?
The Lobbying Disclosure Act mandates quarterly disclosure of lobbying "contacts" subject to many caveats. Watchdogs have long complained about lacunae in the LDA, but there is little evidence of the size of shadow lobbying market.
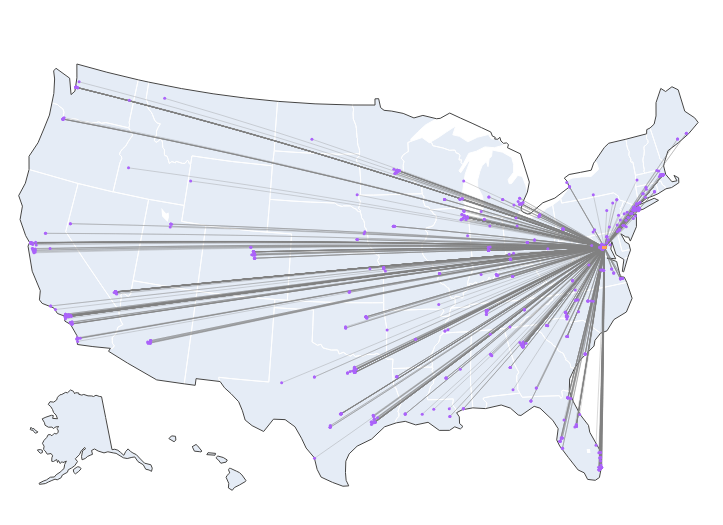
In my JMP, I use 4.5 trillion pings from 179 million smartphones spatially merged to building shapefiles and observe movement between lobbyists' offices, corporate headquarter buildings, and the federal government in Washington DC.
See below: movement of lobbyists from corporate HQs to federal government buildings:
ALT Movement of lobbyists from corporate HQs to federal government buildings in Washington DC.
10
76
436
147,156



May 21
Overheard with (new) wife at a winery near Napa:
Guide (British guy, 60 ): what brings you guys here?
Customer (Vineyard Vines polo, mid 30s): So I asked Gemini and it said y’all were one of the better small batch shops
Guide: ah, very good
2
168
Eashwar Nagaraj retweeted

May 21
Math grad student friend comments on the recent Erdős proof.

63
137
4,006
279,403
May 13
True ball knowledge
May 13

(Also, he was appropriately scandalized that I didn’t have a preferred IPL team and if you find yourself in the same situation driving somewhere with Eashwar, you *will* wind up a CSK fan)
380
May 13
Luke is such a mensch for remembering a conversation from more than a year ago and for giving me a shout out. @lukestein - thank you for this for the ride back to Boston btw!
May 13
I spent a fantastic few hours with Eashwar driving back from @IrlbeckSteve’s Bretton Woods Finance/Accounting Conference
Eashwar’s a deep thinker and a great interlocutor. I bet he’d make an amazing colleague.
3
574
At the Geospatial Business Analytics Conference @SLU_Official trying to convince @MarcusOwen5, @IrlbeckSteve and the audience that shadow lobbying is pervasive.
Full paper here: papers.ssrn.com/sol3/papers.…
2
2
10
1,552
Thanks to the @TaxFoundation @EconoWill @ahardtospell for hosting me for a talk today! In my JMP I use the 2019 Tax Prom as a validation test for my identification of lobbyists' cellphones. You can see devices labelled "lobbyists" start spiking at 6-7pm when the Tax Prom started in the National Building Museum on Nov 21, 2019. Full paper here: papers.ssrn.com/sol3/papers.…

🚨Early version of my JMP! 🚨
To what extent is the contact between corporate lobbyists and federal government officials publicly disclosed?
In other words, how big is the market for "shadow lobbying"?
The Lobbying Disclosure Act mandates quarterly disclosure of lobbying "contacts" subject to many caveats. Watchdogs have long complained about lacunae in the LDA, but there is little evidence of the size of shadow lobbying market.
In my JMP, I use 4.5 trillion pings from 179 million smartphones spatially merged to building shapefiles and observe movement between lobbyists' offices, corporate headquarter buildings, and the federal government in Washington DC.
See below: movement of lobbyists from corporate HQs to federal government buildings:
ALT Movement of lobbyists from corporate HQs to federal government buildings in Washington DC.
4
723
🚨Early version of my JMP! 🚨
To what extent is the contact between corporate lobbyists and federal government officials publicly disclosed?
In other words, how big is the market for "shadow lobbying"?
The Lobbying Disclosure Act mandates quarterly disclosure of lobbying "contacts" subject to many caveats. Watchdogs have long complained about lacunae in the LDA, but there is little evidence of the size of shadow lobbying market.
In my JMP, I use 4.5 trillion pings from 179 million smartphones spatially merged to building shapefiles and observe movement between lobbyists' offices, corporate headquarter buildings, and the federal government in Washington DC.
See below: movement of lobbyists from corporate HQs to federal government buildings:
ALT Movement of lobbyists from corporate HQs to federal government buildings in Washington DC.
10
76
436
147,156
I use "issued-based campaigns" launched by the IRS' Large Business & International division as the setting to identify the timing and a firm-specific reason for initiating lobbying. See here for an example of a lobbying response (RED) to an audit selection (BLUE):
2
1
40
5,997
Some of my own data collection is now public: go to economeash.com/data/ to use an interactive tool to visualize public corporations' buildings as of 2019.
2
45
4,332
Eashwar Nagaraj retweeted

Since 1966, historic districts have steadily expanded to cover much of Lower Manhattan.
As more areas are covered, new housing is effectively banned there, driving displacement and higher rents.
18
58
682
135,993
Eashwar Nagaraj retweeted

Apr 4
JUST IN: GitHub COO reveals annual commits are on pace to jump 1,300% year over year.
116
118
2,262
214,673
Synthetic controls be like

Kiss a man
1
191


Eashwar Nagaraj retweeted

Mar 9
Three days ago I left autoresearch tuning nanochat for ~2 days on depth=12 model. It found ~20 changes that improved the validation loss. I tested these changes yesterday and all of them were additive and transferred to larger (depth=24) models. Stacking up all of these changes, today I measured that the leaderboard's "Time to GPT-2" drops from 2.02 hours to 1.80 hours (~11% improvement), this will be the new leaderboard entry. So yes, these are real improvements and they make an actual difference. I am mildly surprised that my very first naive attempt already worked this well on top of what I thought was already a fairly manually well-tuned project.
This is a first for me because I am very used to doing the iterative optimization of neural network training manually. You come up with ideas, you implement them, you check if they work (better validation loss), you come up with new ideas based on that, you read some papers for inspiration, etc etc. This is the bread and butter of what I do daily for 2 decades. Seeing the agent do this entire workflow end-to-end and all by itself as it worked through approx. 700 changes autonomously is wild. It really looked at the sequence of results of experiments and used that to plan the next ones. It's not novel, ground-breaking "research" (yet), but all the adjustments are "real", I didn't find them manually previously, and they stack up and actually improved nanochat. Among the bigger things e.g.:
- It noticed an oversight that my parameterless QKnorm didn't have a scaler multiplier attached, so my attention was too diffuse. The agent found multipliers to sharpen it, pointing to future work.
- It found that the Value Embeddings really like regularization and I wasn't applying any (oops).
- It found that my banded attention was too conservative (i forgot to tune it).
- It found that AdamW betas were all messed up.
- It tuned the weight decay schedule.
- It tuned the network initialization.
This is on top of all the tuning I've already done over a good amount of time. The exact commit is here, from this "round 1" of autoresearch. I am going to kick off "round 2", and in parallel I am looking at how multiple agents can collaborate to unlock parallelism.
github.com/karpathy/nanochat…
All LLM frontier labs will do this. It's the final boss battle. It's a lot more complex at scale of course - you don't just have a single train. py file to tune. But doing it is "just engineering" and it's going to work. You spin up a swarm of agents, you have them collaborate to tune smaller models, you promote the most promising ideas to increasingly larger scales, and humans (optionally) contribute on the edges.
And more generally, *any* metric you care about that is reasonably efficient to evaluate (or that has more efficient proxy metrics such as training a smaller network) can be autoresearched by an agent swarm. It's worth thinking about whether your problem falls into this bucket too.

960
2,124
19,521
3,659,409