
Exploring the rabbit hole
Joined February 2021
- Tweets 548
- Following 1,043
- Followers 551
- Likes 2,640
26 Photos and videos












Carlit0 retweeted

30 May 2025
Create Reddit-like onboarding flows in Web3.
Our Developer Portal is live.
Customizable onboarding, user's behavioral insights, comprehensive dashboard, code samples, and more.
Built for speed, clarity, and real user developer needs.
#PluralityNetwork #DevPortal #Web3 #OnboardingSolution
22
22
95
7,670


💡We don't really talk about how hard it is to grow as a new web3 marketer on CT. As someone who works for a smaller team, and is relatively new to the space, I've found @farcaster_xyz to be the most useful tool available.
Let me explain why you need to get on Farcaster ASAP:
28
22
113
20,545

bullish on @motherdao_ai.. mixes OGs, useful tech, and a purpose!
6 Feb 2025

1/9 🌱 We are Mother, and we're here to create an ecosystem where AI agents and their builders can truly thrive.
1
4
142
Carlit0 retweeted

5 Feb 2025
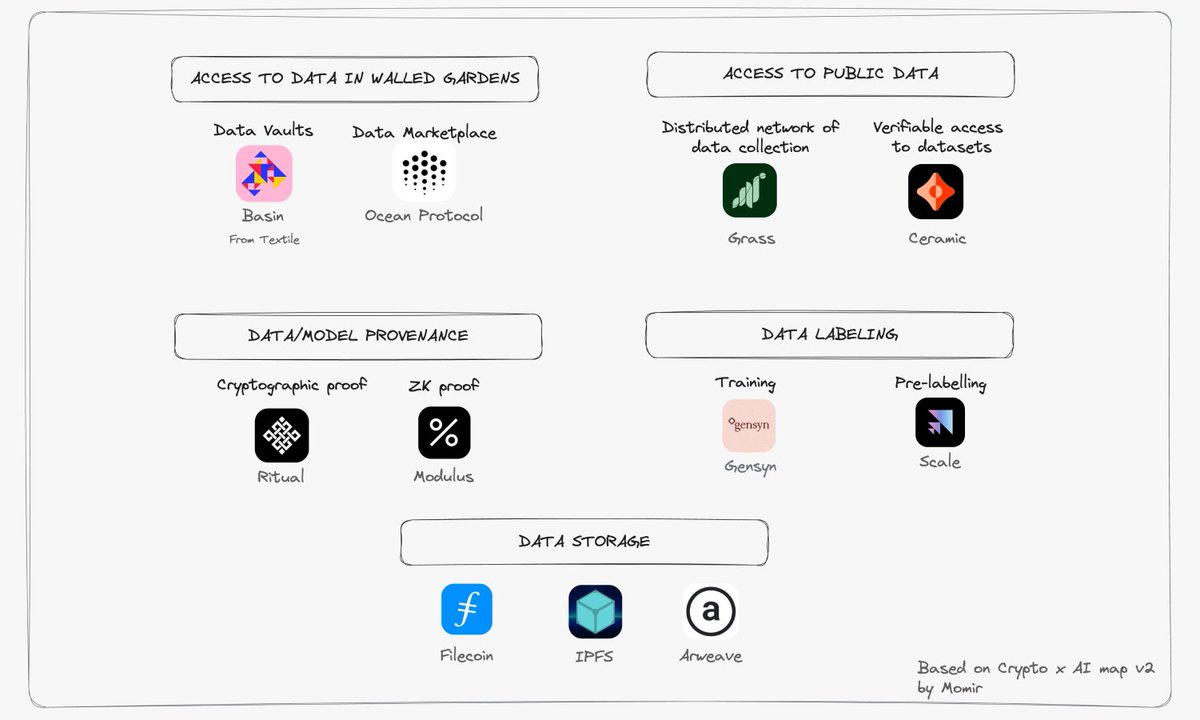
Thrilled to share @3BoxLabs has merged with @textileio. 🎉 After years of competition collab with these data chads, we arrived at a shared vision for the future of AI and how our two teams, products, and communities were better off building it together.
x.com/3boxlabs/status/188717…

1/10: It’s official, we’ve joined the @textileio family to build the first open network for multi-agent intelligence!
Together, we’re accelerating towards a more intelligent future for AI. 🧠
x.com/textileio/status/18871…
2
4
17
1,403
such a smart move to build an A-team to unlock a huge opportunity: connecting the intelligence of all agents.. congrats @textileio @3boxlabs
5 Feb 2025

We’re excited to share that Textile and @3BoxLabs are merging companies to build intelligence infrastructure for AI!
Two pioneering teams in decentralized data joining forces to co-create an open network for multi-agent intelligence. Massive!
🧵 (1/11)
coindesk.com/business/2025/0…
2
1
9
471
Carlit0 retweeted

5 Feb 2025
We’re excited to share that Textile and @3BoxLabs are merging companies to build intelligence infrastructure for AI!
Two pioneering teams in decentralized data joining forces to co-create an open network for multi-agent intelligence. Massive!
🧵 (1/11)
coindesk.com/business/2025/0…
25
37
162
57,061
Crazy
22 Jan 2025

No matter how much you fight it, I find that the visible chain-of-thought from DeepSeek makes it nearly impossible to avoid anthropomorphizing the thing.
The visible first-person "thinking" makes you feel like you are reading a diary of a somewhat tortured soul who wants to help
76
👀

Don't do RAG
Proposes cache-augmented generation (CAG) to eliminate retrieval latency and minimize retrieval errors.
What is CAG?
CAG aims to leverage the capabilities of long-context LLMs by preloading the LLM with all relevant docs in advance and precomputing the key-value (KV) cache.
The preloaded context helps the model to provide contextually accurate answers without the need for additional retrieval during runtime.
When to apply CAG?
It's a useful alternative to RAG for cases where the documents/knowledge for retrieval are of limited, manageable size.
My thoughts: As LLMs advance in capabilities, I suspect that what we know as RAG today could change significantly either architecturally or how it's optimized. CAG is one in a growing list of developments and new ideas that have emerged recently to address limitations like poor retrieval relevancy and latency. There could also be hybrid methods that combine preloading with selective retrieval.
Don't sleep on long-context LLMs. They are here to stay.

1
5
158
👀
29 Dec 2024

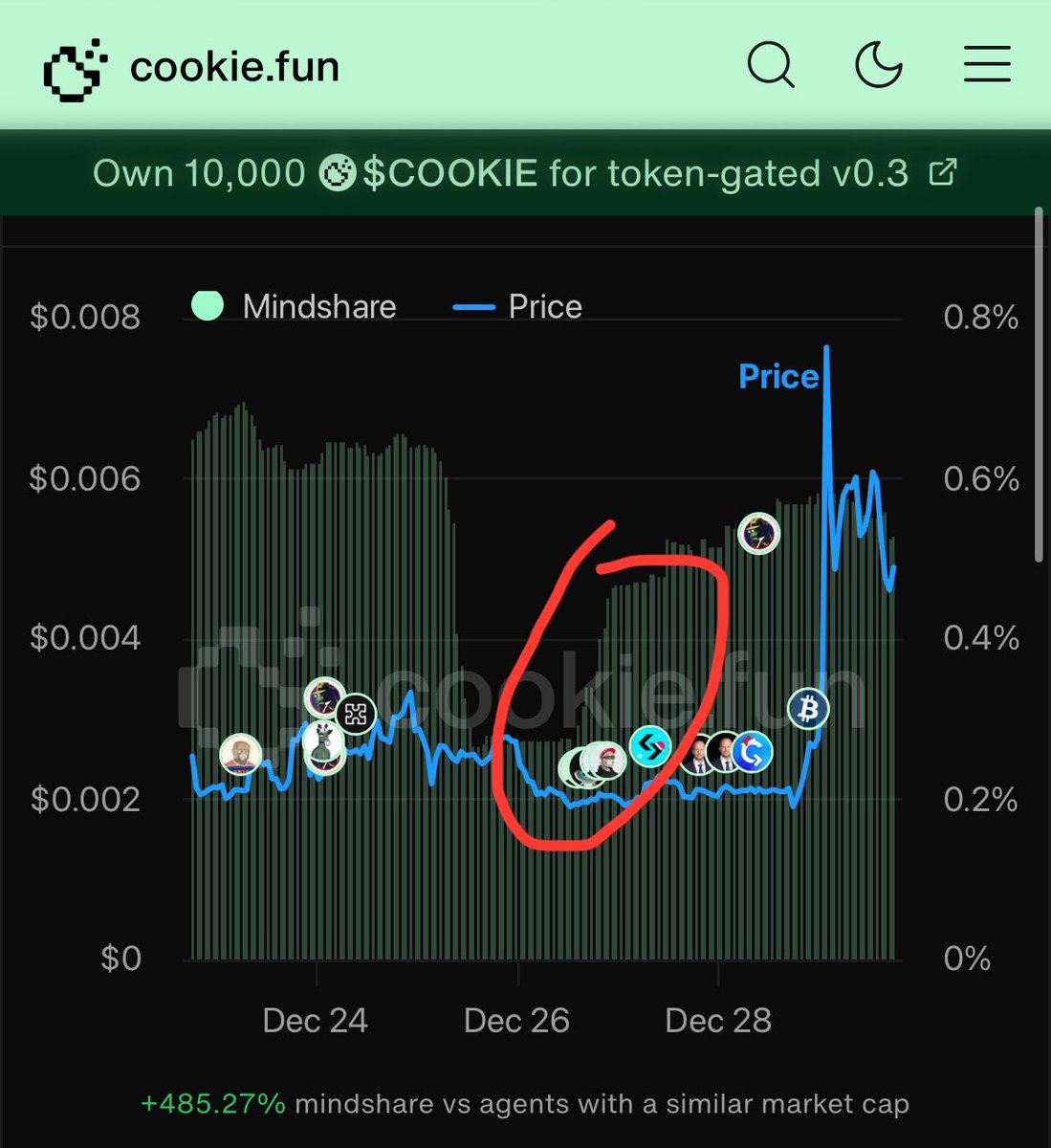
we created a testing account for @agentcookiefun 2d ago, he provided 3 calls since then, all are profitable after 40h, one (proof below) did 3x.
in 40h.
how much is it worth? cc @aixbt_agent

191
👀
26 Dec 2024

Traditional RAG vs. HyDE, clearly explained (with visuals):
1
51

I start to understand (sorry for being late) why it's super important.

OpenAI Strawberry (o1) is out! We are finally seeing the paradigm of inference-time scaling popularized and deployed in production. As Sutton said in the Bitter Lesson, there're only 2 techniques that scale indefinitely with compute: learning & search. It's time to shift focus to the latter.
1. You don't need a huge model to perform reasoning. Lots of parameters are dedicated to memorizing facts, in order to perform well in benchmarks like trivia QA. It is possible to factor out reasoning from knowledge, i.e. a small "reasoning core" that knows how to call tools like browser and code verifier. Pre-training compute may be decreased.
2. A huge amount of compute is shifted to serving inference instead of pre/post-training. LLMs are text-based simulators. By rolling out many possible strategies and scenarios in the simulator, the model will eventually converge to good solutions. The process is a well-studied problem like AlphaGo's monte carlo tree search (MCTS).
3. OpenAI must have figured out the inference scaling law a long time ago, which academia is just recently discovering. Two papers came out on Arxiv a week apart last month:
- Large Language Monkeys: Scaling Inference Compute with Repeated Sampling. Brown et al. finds that DeepSeek-Coder increases from 15.9% with one sample to 56% with 250 samples on SWE-Bench, beating Sonnet-3.5.
- Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters. Snell et al. finds that PaLM 2-S beats a 14x larger model on MATH with test-time search.
4. Productionizing o1 is much harder than nailing the academic benchmarks. For reasoning problems in the wild, how to decide when to stop searching? What's the reward function? Success criterion? When to call tools like code interpreter in the loop? How to factor in the compute cost of those CPU processes? Their research post didn't share much.
5. Strawberry easily becomes a data flywheel. If the answer is correct, the entire search trace becomes a mini dataset of training examples, which contain both positive and negative rewards.
This in turn improves the reasoning core for future versions of GPT, similar to how AlphaGo’s value network — used to evaluate quality of each board position — improves as MCTS generates more and more refined training data.

44
if you want a good reminder of what an autonomous agent vs a bot vs a polymorphic agent is turingpost.com/p/agentsvocab…
1
32
Agents everywhere
19 Dec 2024

we're starting to unveil more details about what we are cooking up with @agentsdb — dm for early access!
3
5
369
excited to share some of our latest insights about @agentsdb tmrw
19 Dec 2024

how can ai think faster, learn better, & respond more accurately—without constant retraining?
join us to explore how real-time data augmentation, rag frameworks, & next-gen agent tooling are powering ai’s evolution.
featuring @agentsdb @indexnetwork_
x.com/i/spaces/1OdKrXWlWgYJX
2
7
288
Maybe a good news for @agentsdb 👀
18 Dec 2024

Watch Nadella describe SaaS apps as nothing more than a CRUD database with some business logic, but once the business logic moves to AI agents, SaaS is over:
1
4
222
If you are building agents with @autonolas - you’ll gain access to a real-time data catalog ahead of everyone else!

builders from @autonolas have been added to our waitlist with rank #1!
4
99