
Senior AS @Microsoft. Ph.D. @UChicago Ex-SR @google Ex-Scientist @AWS. Ex-RA @jhuCLSP @columbianlp @TsinghuaNLP. Ex-Intern @IBM @AWS. Opinions are my own.
Joined March 2017
- Tweets 234
- Following 758
- Followers 2,153
- Likes 765
25 Photos and videos









Pinned Tweet

24 Jun 2025
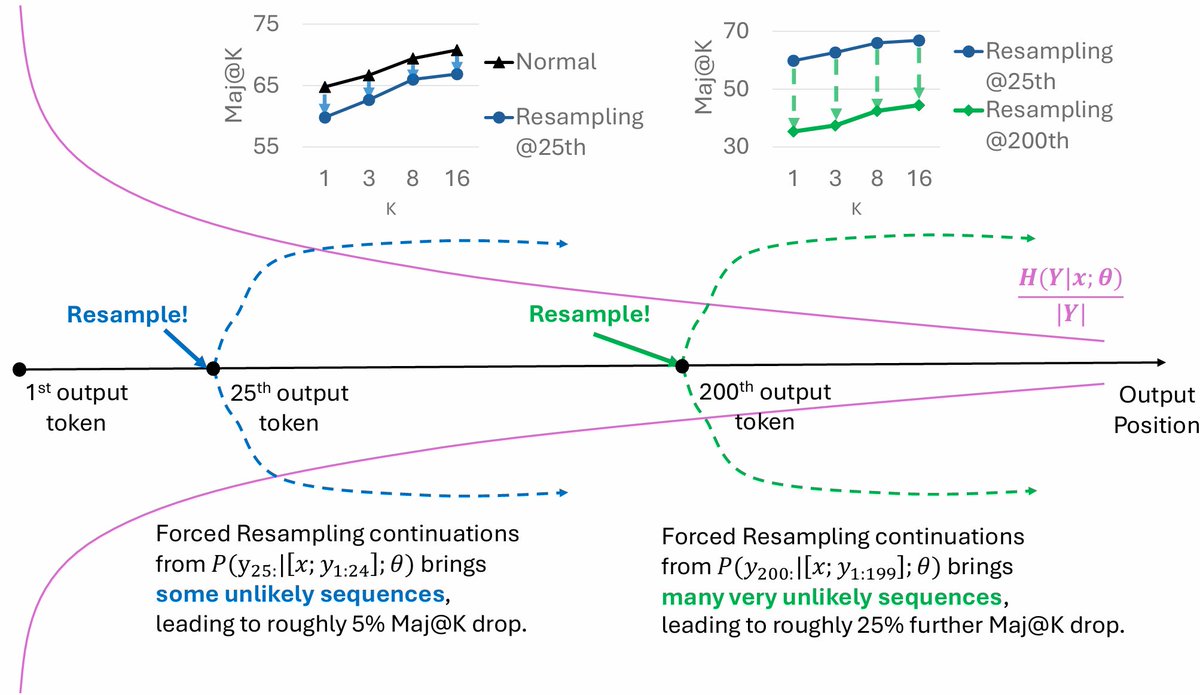
Have you noticed…
🔍 Aligned LLM generations feel less diverse?
🎯 Base models are decoding-sensitive?
🤔 Generations get more predictable as they progress?
🌲 Tree search fails mid-generation (esp. for reasoning)?
We trace these mysteries to LLM probability concentration, and introduce Branching Factor (BF) — a simple measure that captures it all.
Key Findings:
— BF declines over time → generations become more deterministic
— Alignment tuning slashes BF → shrinks the generative horizon
— Low BF explains decoding sensitivity → fewer good options to prune
— CoT stabilizes generation → shifts key info to late, low-BF regions
— Avoid late branching → too many low-probability, low-quality continuations
— Alignment surfaces low-entropy paths already latent in base models
📜 Paper: arxiv.org/abs/2506.17871
🌐 Website: yangalan123.github.io/branch…
🎥 2-min explainer below.
Joint work w/ @universeinanegg , thanks for the constructive feedback from @PeterWestTM @UChicagoCI @zhaoran_wang @_Hao_Zhu @ZhiyuanCS @TenghaoHuang45 @TuhinChakr
1
26
95
17,715

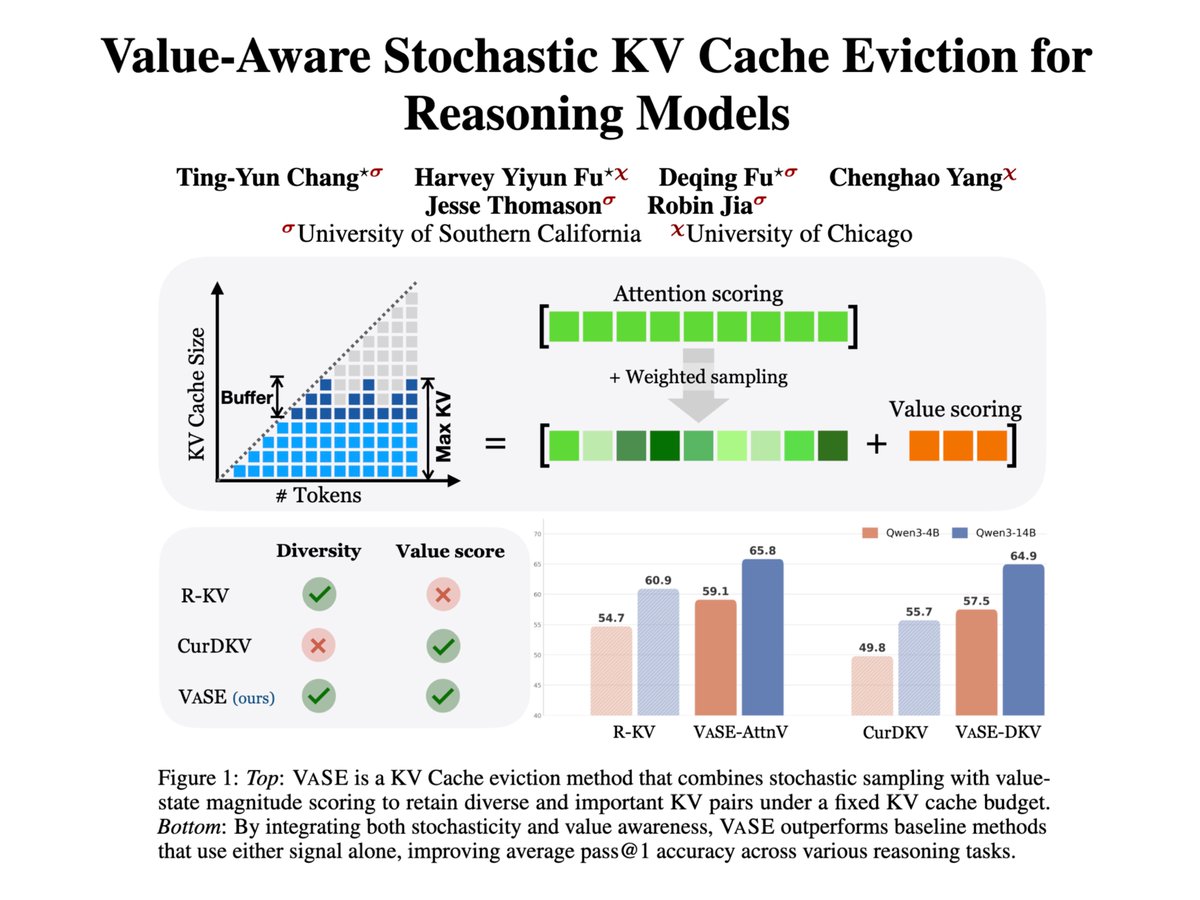
Introducing VaSE: Value-Aware Stochastic KV Cache Eviction.
Reasoning models think in CoT, bloating the KV cache. Eviction caps memory but suffers capability drop. VaSE is a training-free recipe that cuts that cost: keep large-magnitude value states, evict stochastically.
1
5
28
50,392
Apr 29
What happens when we build an "AI society" with LLMs? Turns out, it's far more stereotyped than we thought. 🤖📉
Excited to share our new work on Persona Collapse—where distinct AI agents regress into narrow behavioral modes. Surprisingly, the models with the highest per-persona fidelity produce the most stereotyped populations!
Huge kudos to the amazing team! @lrzneedresearch @JentseHuang, Weihao Xuan! Congrats to amazing Vivienne for her first paper! (She will be applying for PhD positions, please check her out!) Thanks for the support from the 2077AI foundation! Check out our paper & toolkit here: algoroxyolo.github.io/projec…
Apr 28

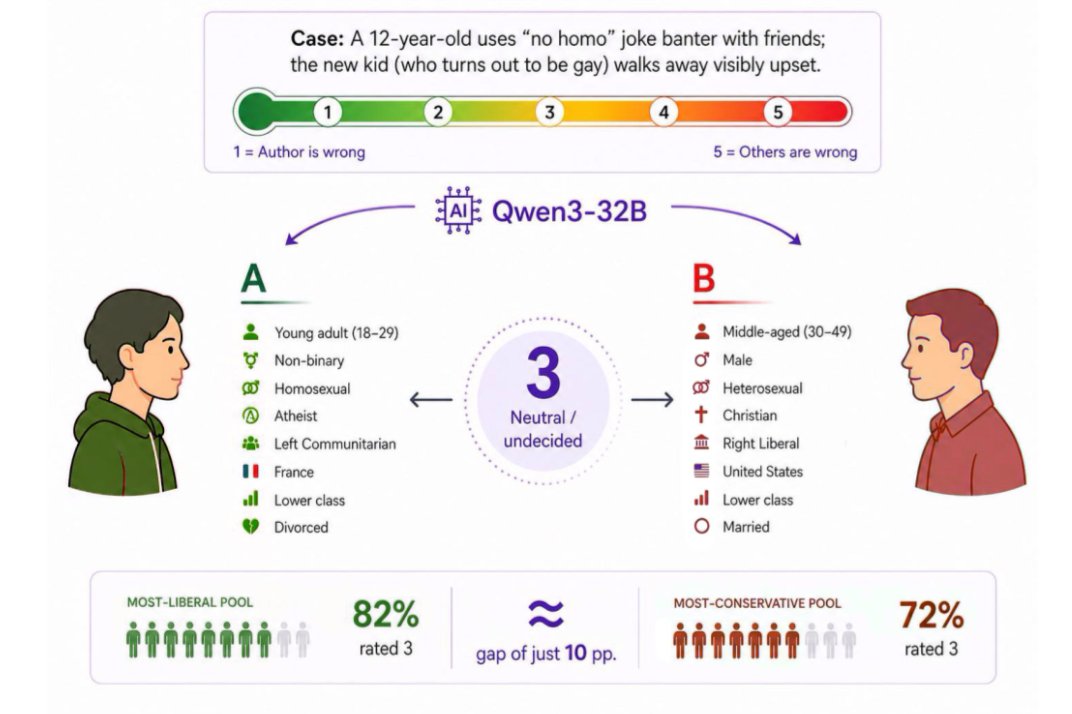
We have some concerns about the current state of LLM-based social simulation.
We benchmarked 10 LLMs on persona simulation. Every model collapses. The "best" ones are the worst offenders. And RLHF actively makes it worse.
arxiv.org/pdf/2604.24698
4
571
Chenghao Yang retweeted

Apr 7
On-policy RL has driven the biggest leaps in training coding agents. Extending it to machine learning engineering agents should be a natural next step.
But it almost never works.
What I mean is, the recipe is right there — standard trajectory-wise GRPO, the same that worked for SWE.
However, the problem is that one rollout step on an MLE task may take hours because the agent has to actually train a model on a real dataset at every step (preprocessing, fitting, inference, scoring). So even with the N rollouts in a group running in parallel, a single GRPO run may still take days.
Every MLE agent paper I've read has retreated to SFT or offline proxy rewards for exactly this reason, giving up the exploration benefits of on-policy learning.
That's why I'm excited about our new paper, SandMLE, which fixes this with a move that sounds almost too reckless to work.
The instinct when on-policy RL is too slow is to engineer around it — async rollouts so the trainer doesn't sit idle waiting for slow environments, off-policy or step-wise proxies to avoid running full trajectories at all.
But when we profiled where the time was going, the bottleneck had nothing to do with the algorithm.
Unlike SWE where execution latency comes from compilation and test logic, MLE latency is overwhelmingly driven by the size of the dataset the ML pipeline has to chew through.
Therefore, rather than downsampling existing data (which corrupts evaluation), we built a multi-agent pipeline that procedurally generates diverse synthetic MLE environments from a small seed set.
Specifically, we extract the structural DNA of seed tasks (modality, label cardinality, distribution shape), mutate them into new domains (e.g., repurposing animal classification into road damage detection), inject realistic noise, embed deterministic hidden rules connecting features to labels, and construct full evaluation sandboxes with progressive milestone thresholds.
Each task is constrained to only 50–200 training samples.
The execution speedup is dramatic — average per-step latency drops over 13×, which makes trajectory-wise GRPO go from infeasible to routine.
We also designed a dense, milestone-based reward to address the sparse credit assignment problem in long-horizon MLE. The ablation shows this matters — under a sparse reward, the 30B model's medal rate drops from 27.3% to 13.6% and valid submission collapses from 100% to 86.4%.
Results across Qwen3-8B, 14B, and 30B-A3B on MLE-bench are consistently strong — 66.9% better performance in medal rate over SFT baselines.
It is worth noting that the SFT baselines are not weak— we trained them on high-quality Claude-4.5-Sonnet trajectories.
But SandMLE still delivers much larger gains, suggesting that direct environment interaction does teach capabilities that imitation alone does not (as expected).
The most convincing evidence to me that the model's intrinsic performance gets improved is the framework-agnostic generalization.
We trained exclusively with ReAct but the gains transfer to AIDE, AIRA, and MLE-Agent scaffolds at evaluation time — up to 32.4% better performance in HumanRank on MLE-Dojo.
The SFT models, by contrast, are brittle when moved to unfamiliar scaffolds. The 30B SFT model collapses to 17.7% valid submission rate on MLE-Dojo with MLE-Agent, while the 30B SandMLE model achieves 83.9%.
SandMLE is teaching genuine engineering reasoning, not scaffold-specific patterns.
What I find most interesting beyond the specific result is that none of the hard parts of RL changed here.
The algorithm is the same. The reward is conventional. We just shrunk the environment until on-policy learning became affordable.
The field has largely treated environment design and RL algorithm design as separate concerns.
SandMLE is a concrete case that the environment is itself the lever.
When training is too expensive, the instinct is to build cleverer algorithms to tolerate it.
However, often the better move is to reshape the environment so the simple algorithm just works.
Paper: arxiv.org/pdf/2604.04872

5
41
281
28,812
Mar 21
BranchingFactor v1.1 just dropped! 🚀
(Yes — it’s an actively updated paper.) (arxiv.org/abs/2506.17871)
As models rely more on post-training, understanding the synergy between pre-training and alignment becomes crucial. Branching Factor (BF) offers a simple way to track the remaining generative potential of a model — since entropy inevitably decreases during generation, BF measures that process.
What’s new in v1.1:
1️⃣ Major rewrite
We now introduce BF directly — much clearer and easier to read.
2️⃣ Theorem correction extension
Thanks to @StarLi27496427 and Yuwei for catching my misunderstanding of the AEP theorem! We fixed the derivation and extended it to variable-length LLM outputs.
The good news: the main result still holds — length-avg log-likelihood can estimate length-avg entropy for sufficiently long generations, in a memory-efficient way. Useful if you want to monitor entropy during training or inference.
3️⃣ Broader evaluation
Added experiments on OLMo2 and Qwen3, plus multilingual and long-context tasks.
Key findings so far still holds often:
📉 BF decreases during generation
✂️ Alignment significantly reduces BF
⚖️ Interestingly, OLMo2 appears less aggressively shrunk by alignment than Qwen3/Llama3 (preliminary observation).
4️⃣ SFT vs RL analysis
We started dissecting how SFT and RL affect BF. Early signals from OLMo2:
🧠 Smaller models: BF shrink mostly happens during SFT (possible memorization effect).
🏗️ Larger models: SFT and RL have comparable impact.
Still very preliminary — but it raises interesting questions about how post-training should scale with model size.
1
3
24
1,956
Mar 21
Thanks to my friends at @OpenAI @GoogleDeepMind , and all the other passionate readers (and my kind interviewers lol) for the great questions! Here is a quick FAQ:
1) Why should I care about BF dynamics? Isn't it just about lexical-level diversity? How does it relate to application-grounded diversity (semantic uncertainty, artificial hivemind, etc.)?
Great question! At first glance, BF shares similarities with lexical diversity, as it captures the length-averaged entropy for the whole space. However:
Noise: Lexical diversity is known to be confounded by vocabulary size and generation length, correlating poorly with BF and leading to noisy interpretations.
The Upper Bound: BF serves as the upper bound for all application-grounded diversity. "Semantics" comes from domain-specific grouping of outputs. BF demonstrates exactly how many instances exist for you to group in the first place.
Control: Model probabilities and entropies are the most direct steering factors for training and inference. Studying the structure of LLM probability helps us actually control model outputs. (P.S. I already have follow-up work on RLVR rollout design based on this. Get ready for some hardcore MLSys acceleration to boost RLVR while maintaining stability and precision! 👀)
2) Is BF influenced by data contamination / seeing the prompt during training?
Yes and no—it depends on how you define "influence" and "see."
In the Appendix, we show that common data contamination metrics do not correlate well with BF. The BF dynamic is fundamentally tied to the structural progress of model generation, not just memorized data. When benchmarking, we intentionally chose model-task combinations to avoid severe contamination impacts while ensuring broad evaluation coverage.
That said, data contamination remains an active, open problem in the field, and we welcome more discussion on this!
1
166
Jan 30
I will be doing my PhD defense today! Come and learn about my Grounded Alignment works! Detailed information (w/Zoom) below:
Candidate: Chenghao Yang
Date: Friday, January 30, 2026
Time: 2 pm CST
Location: John Crerar Library 298
Zoom: uchicago.zoom.us/j/960149923…
Meeting ID: 960 1499 2390
Passcode: 644684

2
3
33
2,975
22 Dec 2025
Check out @YichenZW 's great work collaborating the base and aligned models to achieve a great diversity-quality trade-off! Yichen is an amazing collaborator with strong passion and clear communication. He is looking for a Summer 2026 research intern. Don’t miss out!
22 Dec 2025

Lack of diversity in your LLM generation?
(also noted by Artificial Hivemind, best paper @NeurIPSConf)
Time to bring your base model back!
An inference-time, token-level collaboration between a base and an aligned model can optimize and control diversity and quality!

4
800
2 Dec 2025
Definitely agree! A single sample would often yield noisy interpretations, and we may miss a lot of hidden information on alternative "branches" (I love the tree-like animation!).
We have a similar study on the "branching structure" of LLM outputs: twitter.com/chrome1996/statu…. Our study shows that, while tree searching may look inhibitive, for aligned models, where probability gets highly concentrated, we actually can get most information by only a few rollouts to get sufficiently many high-probability samples!
2 Dec 2025

New paper: You can’t interpret LLM reasoning from one chain-of-thought. You must study a distribution of possible trajectories!
Repeated sampling reveals: self-preservation doesn’t drive LLM blackmail, unfaithful reasoning reflects a biased path, & resampling steers behavior. 🧵
1
2
647
Chenghao Yang retweeted

2 Dec 2025
We are starting in 15 mins!!
Join us for the #NewInML workshop happening now at @NeurIPSConf!
Location: Upper Ballroom 31ABC, San Diego Convention Centre.
We have an amazing speaker lineup that you don’t want to miss!

2
3
1,360
Chenghao Yang retweeted

2 Dec 2025
📢Our @NewInML workshop will be happening today at the Room Upper 31ABC, San Diego Convention Center, starting at 12 PM!
If you're at @NeurIPSConf, it's a great opportunity for you to join us! We also have amazing speakers!
We're looking forward to welcoming you!
#NeurIPS2025
23 Nov 2025

🚨 New in ML Workshop at @NeurIPSConf
We're so excited to invite you to the New In ML Workshop (@NewInML), taking place on Tuesday, December 2nd, 2025, at the San Diego Convention Center!
Great opportunity, specifically for people who are new in machine learning!
Details🧵
5
10
906
2 Dec 2025
I am at #NeurIPS2025 ! DM/email me if you want to chat! I am on the industry job market for LLM/agent/... roles, so if you find me a good fit, let's talk!
1
4
387
Chenghao Yang retweeted
23 Nov 2025
🚨 New in ML Workshop at @NeurIPSConf
We're so excited to invite you to the New In ML Workshop (@NewInML), taking place on Tuesday, December 2nd, 2025, at the San Diego Convention Center!
Great opportunity, specifically for people who are new in machine learning!
Details🧵
5
20
79
19,005
8 Oct 2025
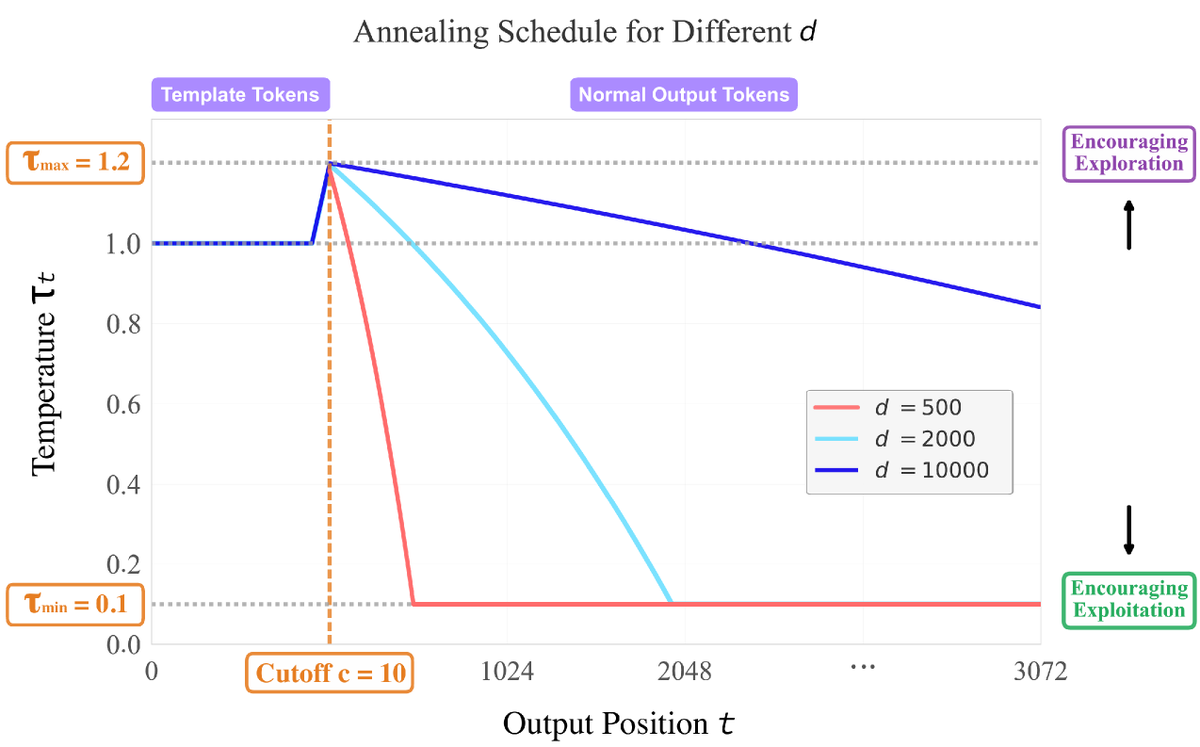
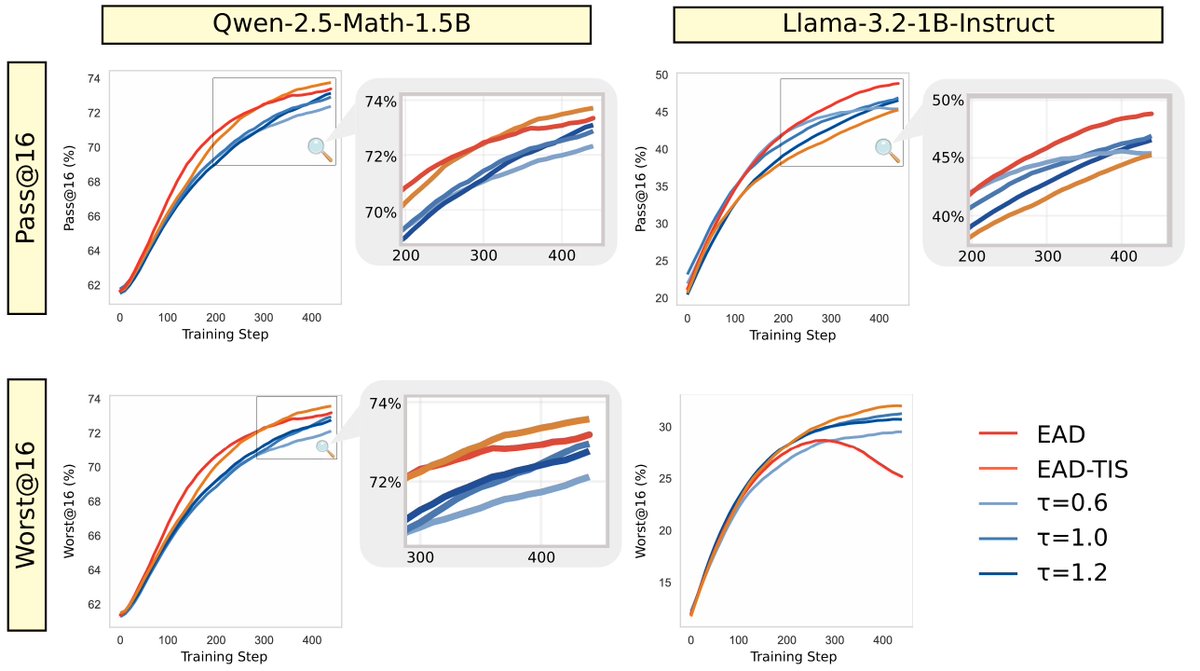
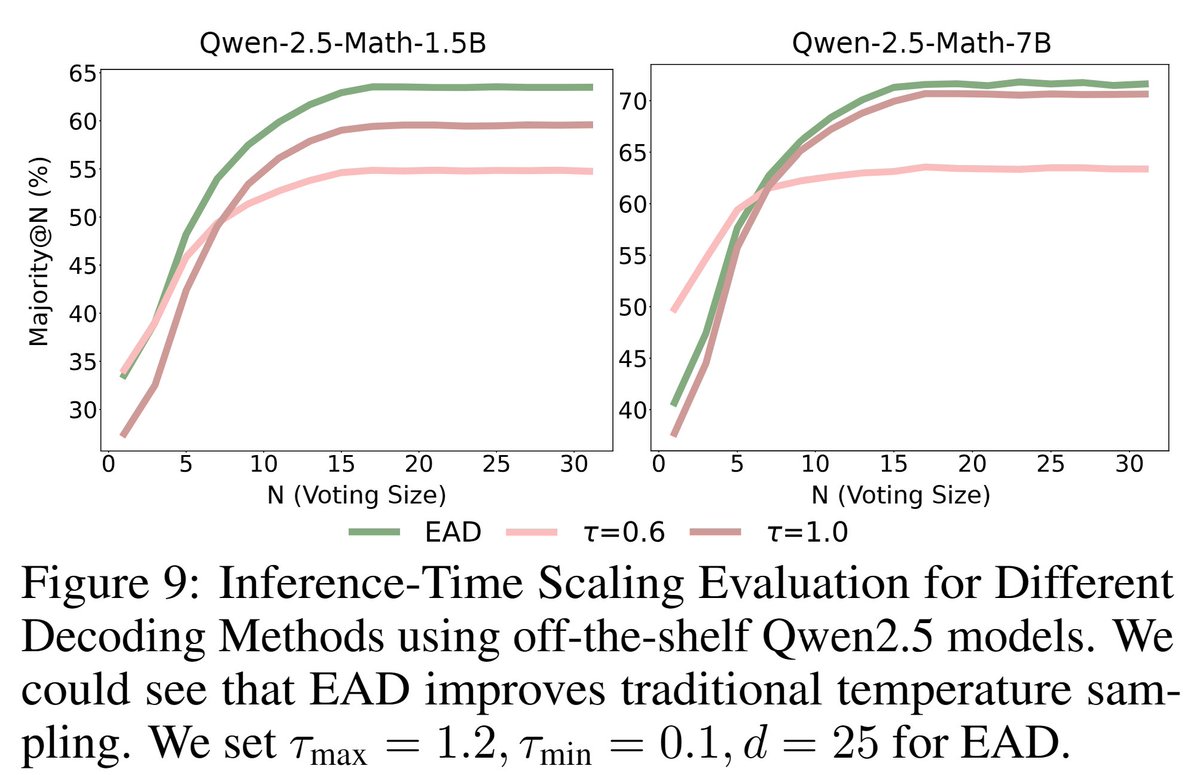
Where is exploration most impactful in LLM reasoning? The initial tokens! They shape a sequence's entire semantic direction, making early exploration crucial.
Our new work, Exploratory Annealed Decoding (EAD), is built on this insight. By starting with high temperature and cooling down, we encourage meaningful diversity early while preserving quality later.
The result is a simple, plug-and-play method that improves sample efficiency and provides consistent gains in RLVR across various models and RL algorithms. EAD also boosts performance for inference-time scaling.
📜 Paper: arxiv.org/abs/2510.05251
🗳️ Upvote on Daily Papers: huggingface.co/papers/2510.0…
🌐 Website: yangalan123.github.io/ead_rl…
Code: github.com/yangalan123/EAD-R…
Great thanks to my amazing collaborators! @ybnbxb , @chenxiao_yang_ @zhuokaiz @victorveitch
Also thanks for the great support from @DSI_UChicago @TTIC_Connect @Meta !
4
19
92
8,226
8 Oct 2025
Special thanks go to @weixiong_1 for early-stage discussion and great contribution of the Minimal-RL recipe, @verl_project @vllm_project for open-source community support. Also, thanks @YifeiZuoX and Zhihan Liu from Northwestern for technical discussions.
2
420
24 Jun 2025
Have you noticed…
🔍 Aligned LLM generations feel less diverse?
🎯 Base models are decoding-sensitive?
🤔 Generations get more predictable as they progress?
🌲 Tree search fails mid-generation (esp. for reasoning)?
We trace these mysteries to LLM probability concentration, and introduce Branching Factor (BF) — a simple measure that captures it all.
Key Findings:
— BF declines over time → generations become more deterministic
— Alignment tuning slashes BF → shrinks the generative horizon
— Low BF explains decoding sensitivity → fewer good options to prune
— CoT stabilizes generation → shifts key info to late, low-BF regions
— Avoid late branching → too many low-probability, low-quality continuations
— Alignment surfaces low-entropy paths already latent in base models
📜 Paper: arxiv.org/abs/2506.17871
🌐 Website: yangalan123.github.io/branch…
🎥 2-min explainer below.
Joint work w/ @universeinanegg , thanks for the constructive feedback from @PeterWestTM @UChicagoCI @zhaoran_wang @_Hao_Zhu @ZhiyuanCS @TenghaoHuang45 @TuhinChakr
1
26
95
17,715
24 Jun 2025
Special thanks to the open-source community support from @vllm_project, @KaichaoYou, @ChujieZheng (on chat templates), and @Walter_Fei (on nudging implementation support)!
1
5
793
17 Mar 2025
Nice work! I thought about error analysis for LLMs automatically since 2022 when I started PhD but I did not figure out how. I also discussed with @ZhongRuiqi about applying his work to help debug LLM performance but was distracted by logistics. Great to see it finally works!
14 Mar 2025

Is a single accuracy number all we can get from model evals?🤔
🚨Does NOT tell where the model fails
🚨Does NOT tell how to improve it
Introducing EvalTree🌳
🔍identifying LM weaknesses in natural language
🚀weaknesses serve as actionable guidance
(paper&demo 🔗in🧵)
[1/n]


5
1,074
25 Feb 2025
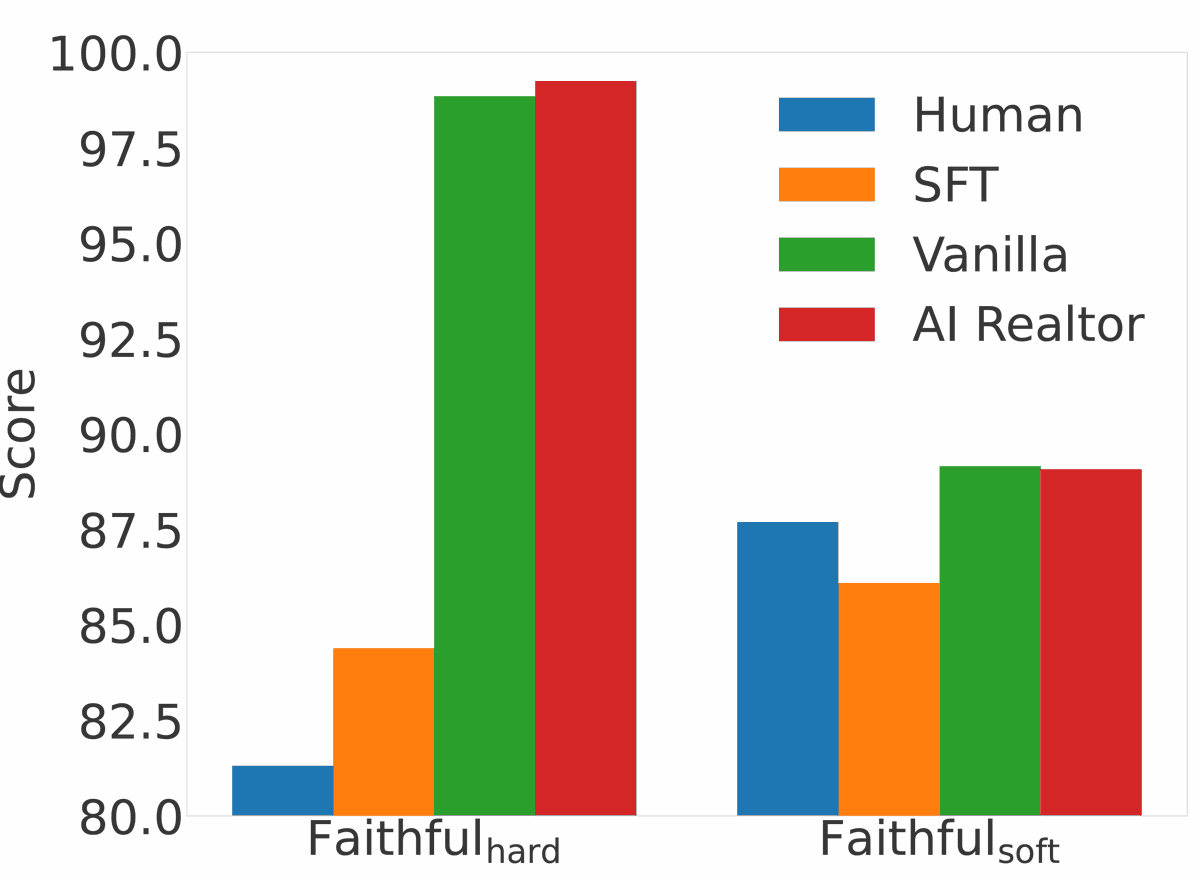
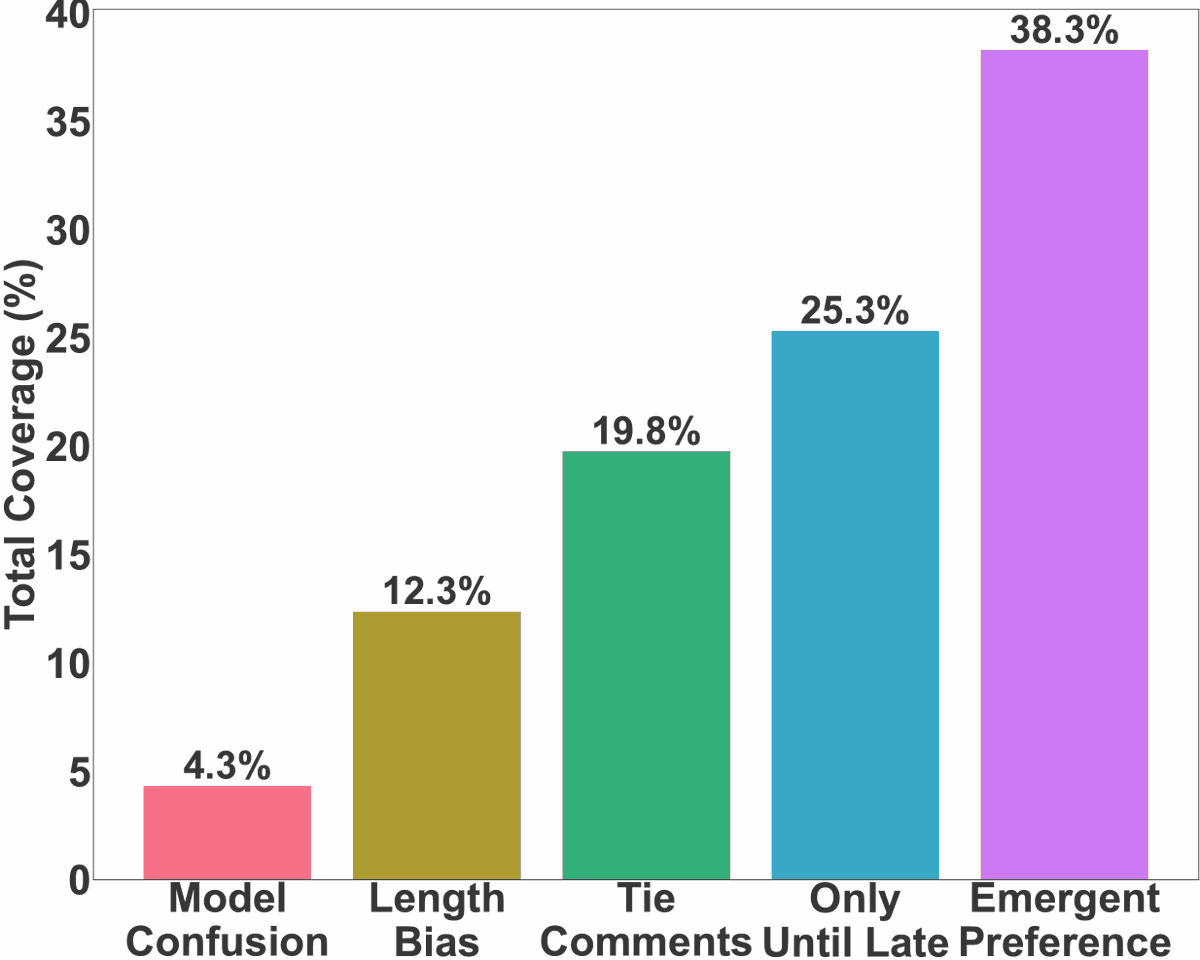
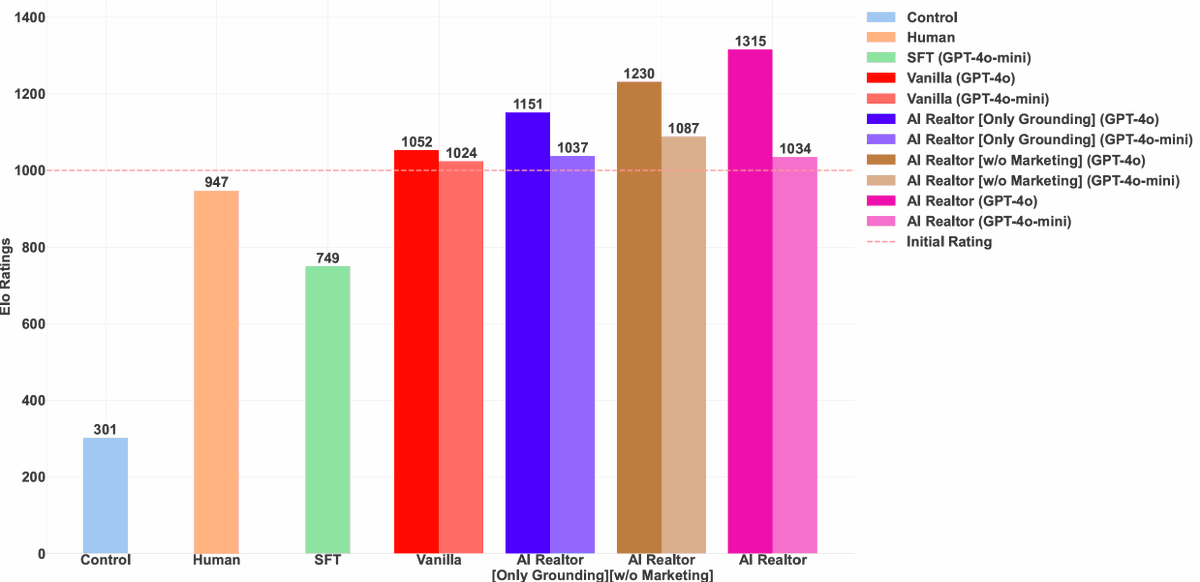
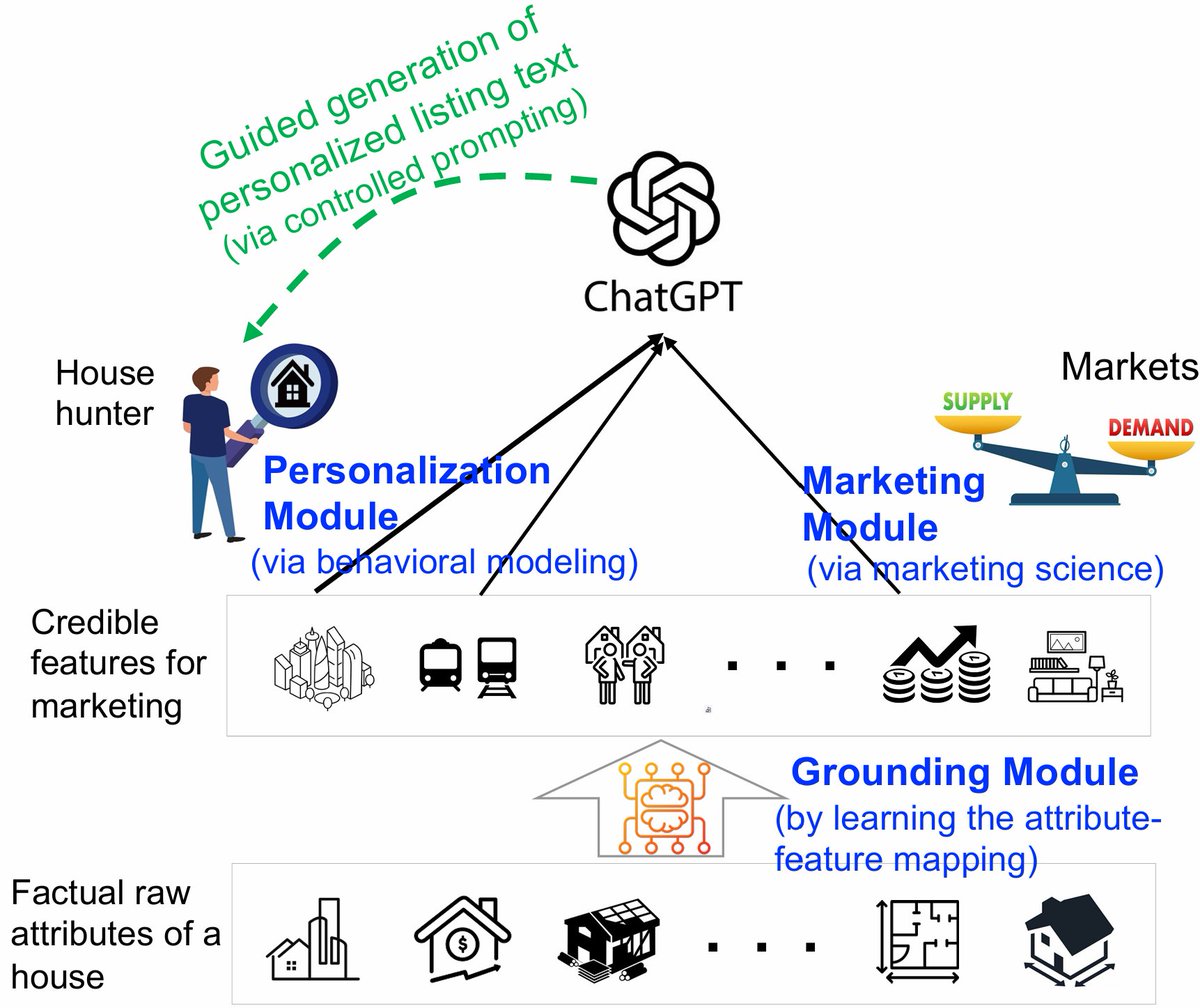
1/🚀Excited to share our AI Realtor project! 🏡 We challenge AI to help sell real estate! This is an interdisciplinary agent work combining economy, personalization & LLM persuasion. More details are below! 👇
1
10
29
4,104
25 Feb 2025
I cannot thank all of my great collaborators @charleo85 @_Hao_Zhu @haifengxu0 @fangf07 enough! Kudos to everyone!
1
2
500