
Joined February 2023
- Tweets 126
- Following 363
- Followers 315
- Likes 778
24 Photos and videos







Pinned Tweet

22 Dec 2025
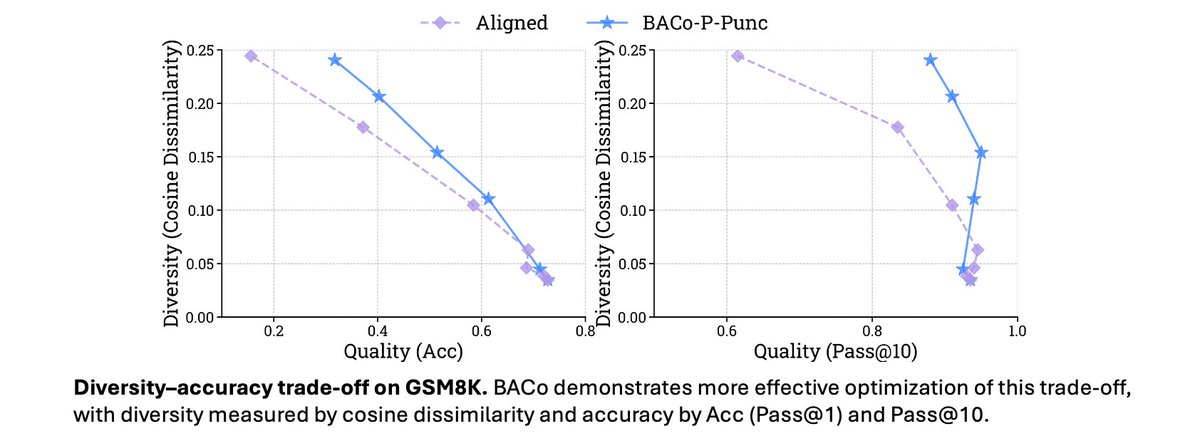
Lack of diversity in your LLM generation?
(also noted by Artificial Hivemind, best paper @NeurIPSConf)
Time to bring your base model back!
An inference-time, token-level collaboration between a base and an aligned model can optimize and control diversity and quality!
2
16
51
10,747
Yichen (Zach) Wang retweeted

Jun 5
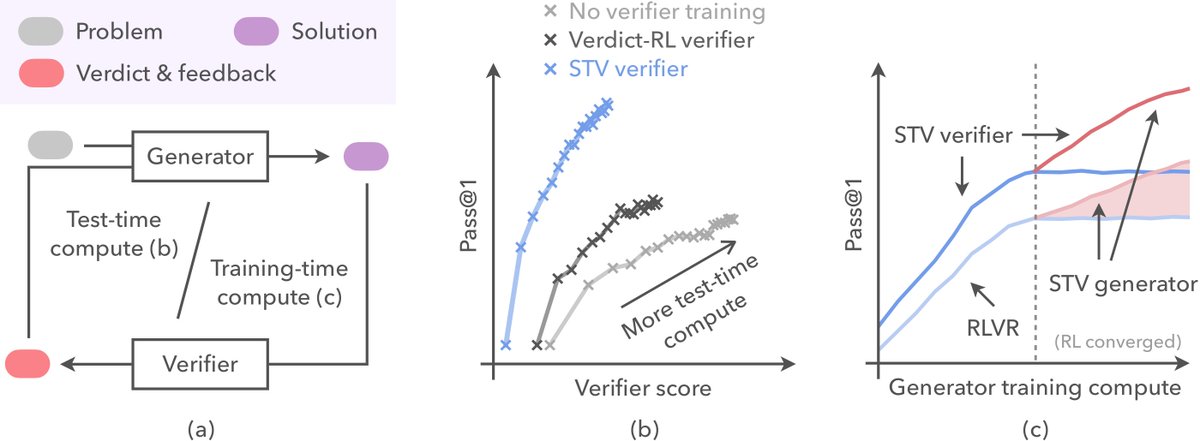
Self-improvement depends on whether a model can judge its own work. We usually train models to generate better - why not train them to verify just as well?
We show how to train models to pinpoint their errors, and the same model nearly doubles its accuracy on hard math and jumps 14x on scientific reasoning. 🧵1/5
15
61
508
56,400
Jun 10
Check out our new post!
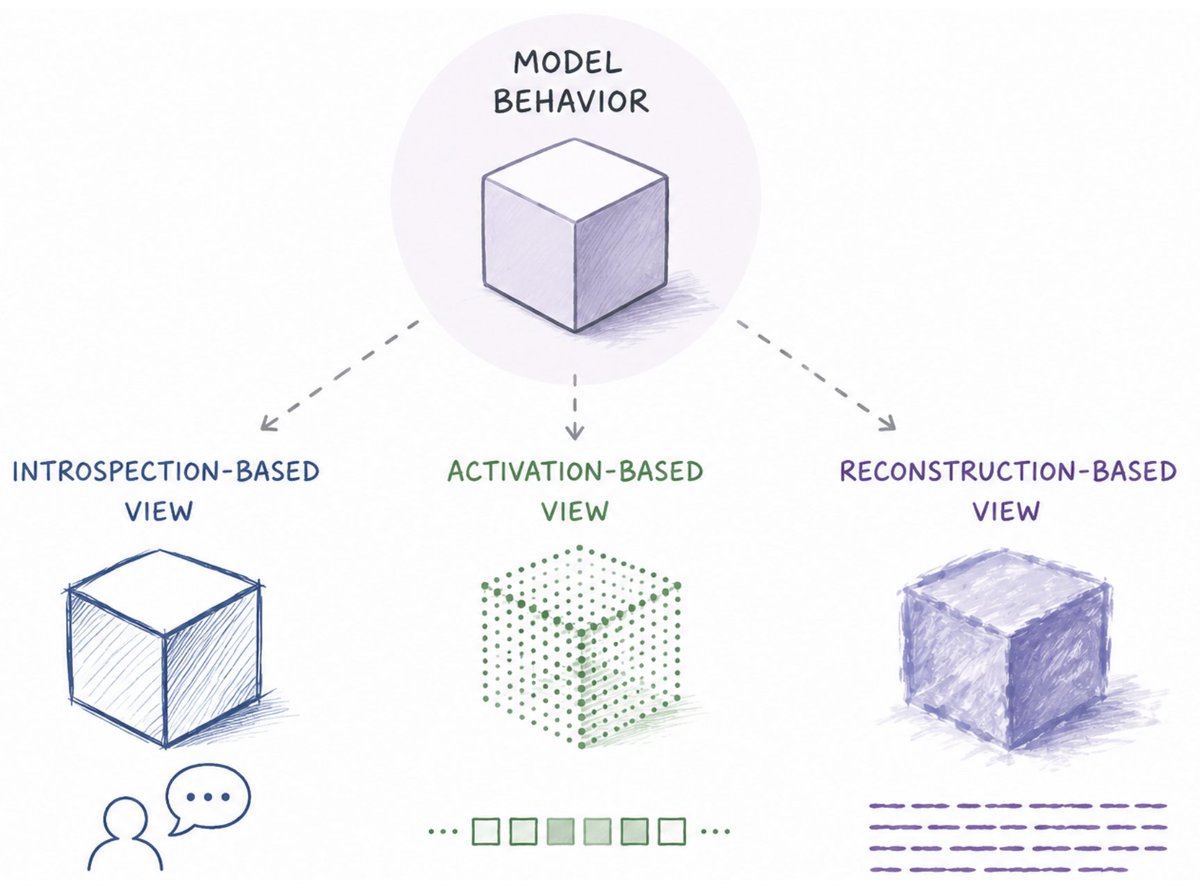
We compare interpretations from different views on the newly designed task: open-ended predictive verbalization, i.e., predicting what some pre-existing over-specified properties are under open-ended prompts.
Jun 10

🗣️ Prediction, Explanation, or Over-interpretation?
Recent work suggests LLMs can verbalize information about latent states and future generations. But training of different verbalization methods varies.
Are they verbalizing, or are we over-interpreting from the explanation?
1/n
1
10
1,343
Yichen (Zach) Wang retweeted

Jun 4
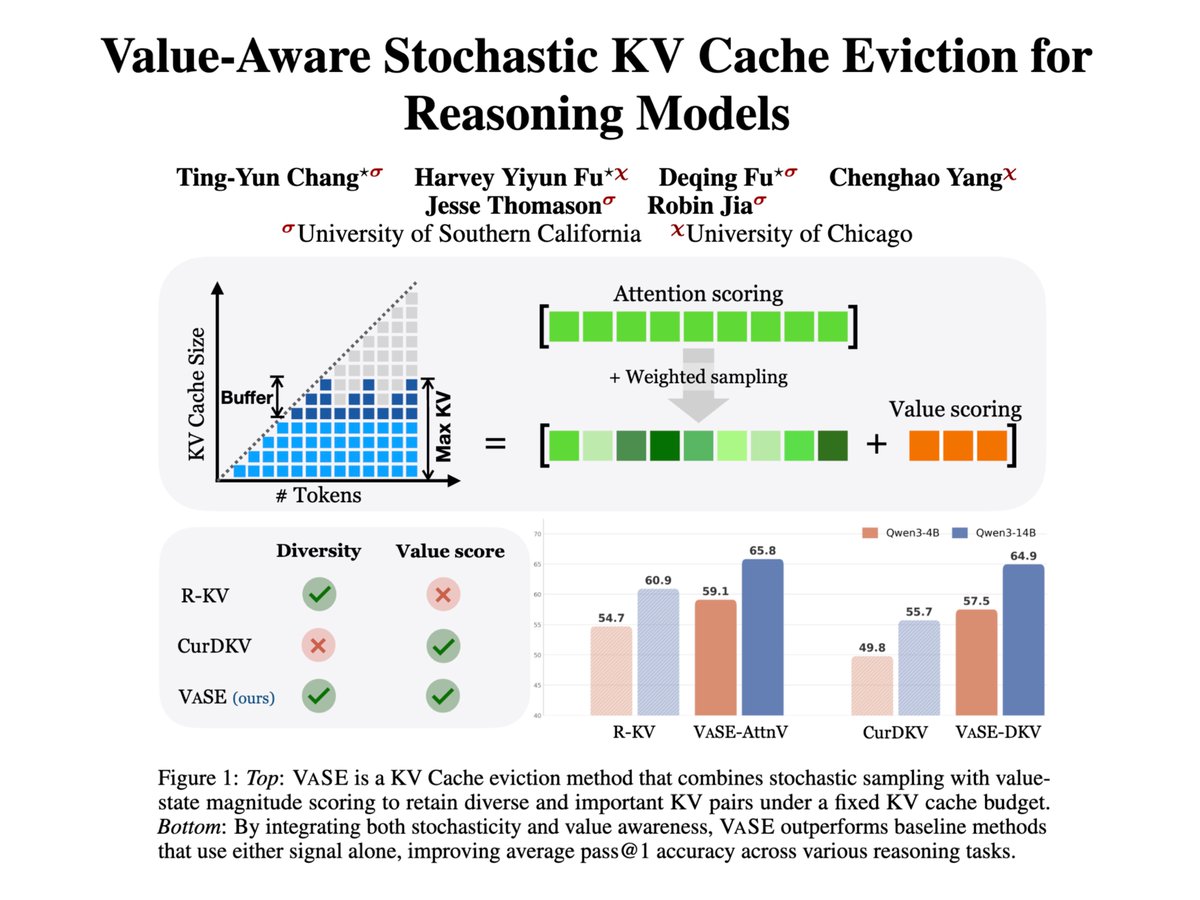
Excited to share our new paper on KV Cache eviction!
We propose a new recipe that is simple and effective: 1. keep those value states with large magnitude, 2. add some stochasticity to the eviction process.
Combined, VaSE consistently outperform previous eviction methods with high throughputs, while maintaining constant memory footprints.
Huge thanks to all collaborators @CharlotteTYC, @DeqingFu, @chrome1996, and advisors @_jessethomason_ and @robinomial

Introducing VaSE: Value-Aware Stochastic KV Cache Eviction.
Reasoning models think in CoT, bloating the KV cache. Eviction caps memory but suffers capability drop. VaSE is a training-free recipe that cuts that cost: keep large-magnitude value states, evict stochastically.
3
10
2,548
Yichen (Zach) Wang retweeted

Jun 2
Post-training makes LLMs safer and better at following instructions, but less diverse.
🤔 Can we get that diversity back without sacrificing alignment?
Introducing ReDiPO: a preference optimization recipe for restoring distributional diversity while preserving safety and instruction-following.

1
10
32
10,786
Yichen (Zach) Wang retweeted

Jun 2
Base models generate more diverse responses than their post-trained counterparts but are also much worse at instruction following. We recover diversity with a simple recipe: the instruct model rewrites messy base generations into high-quality responses, and we then run DPO with this synthetic data. The resulting model is more diverse without sacrificing instruction following! Details 👇
Jun 2

Post-training makes LLMs safer and better at following instructions, but less diverse.
🤔 Can we get that diversity back without sacrificing alignment?
Introducing ReDiPO: a preference optimization recipe for restoring distributional diversity while preserving safety and instruction-following.
1
10
33
4,418

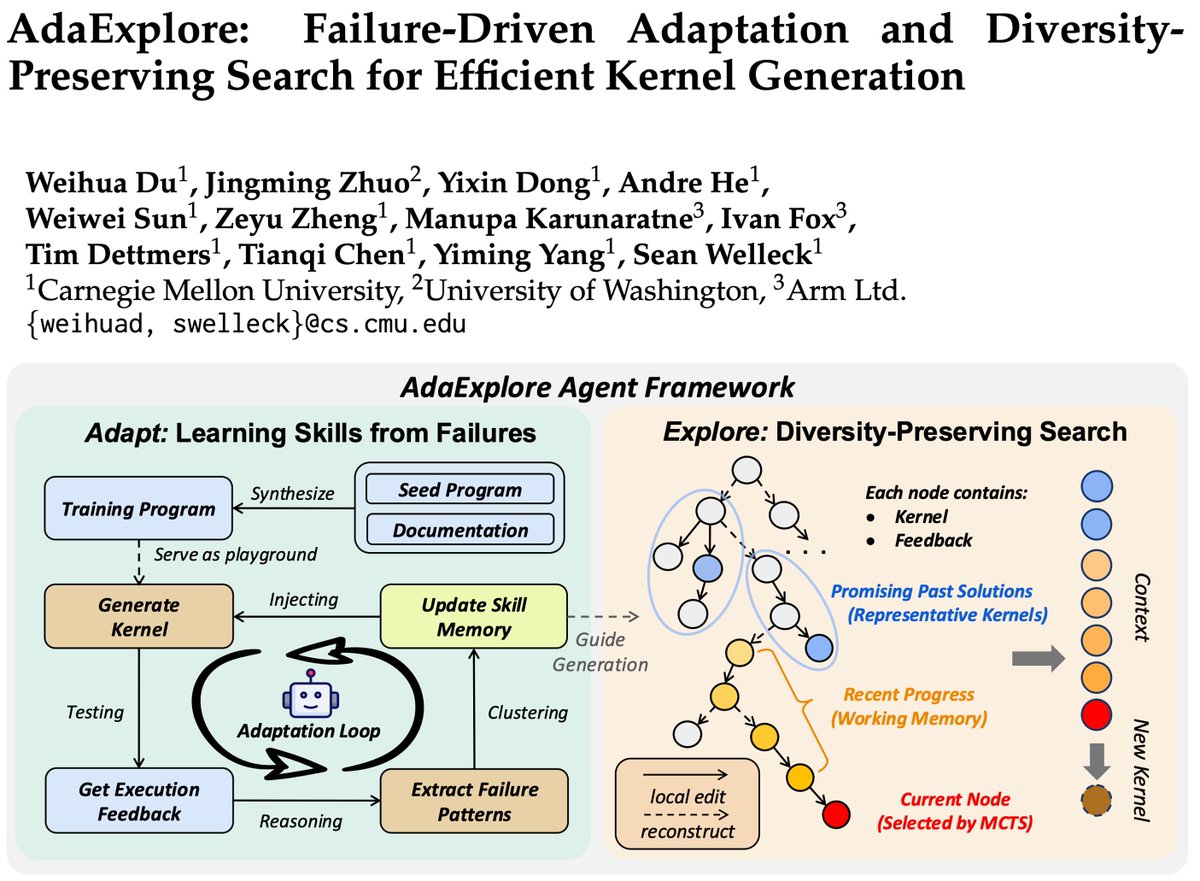
Excited to introduce AdaExplore 🚀✨
AdaExplore teaches LLM agents to improve GPU kernel generation by learning from past execution failures (Adapt Stage) and searching over diverse optimization paths (Explore Stage).
With GPT-5-mini as the base model, AdaExplore achieves 3.12×/1.72× speedups on KernelBench Level-2/Level-3 within 100 evaluation steps ⚡ and outperforms existing baselines such as OpenEvolve.
Project Page & Demo: stiglidu.github.io/AdaExplor…
Arxiv: arxiv.org/abs/2604.16625
Code: github.com/StigLidu/AdaExplo…
More in the thread 👇
4
28
92
48,555
Yichen (Zach) Wang retweeted

Apr 28
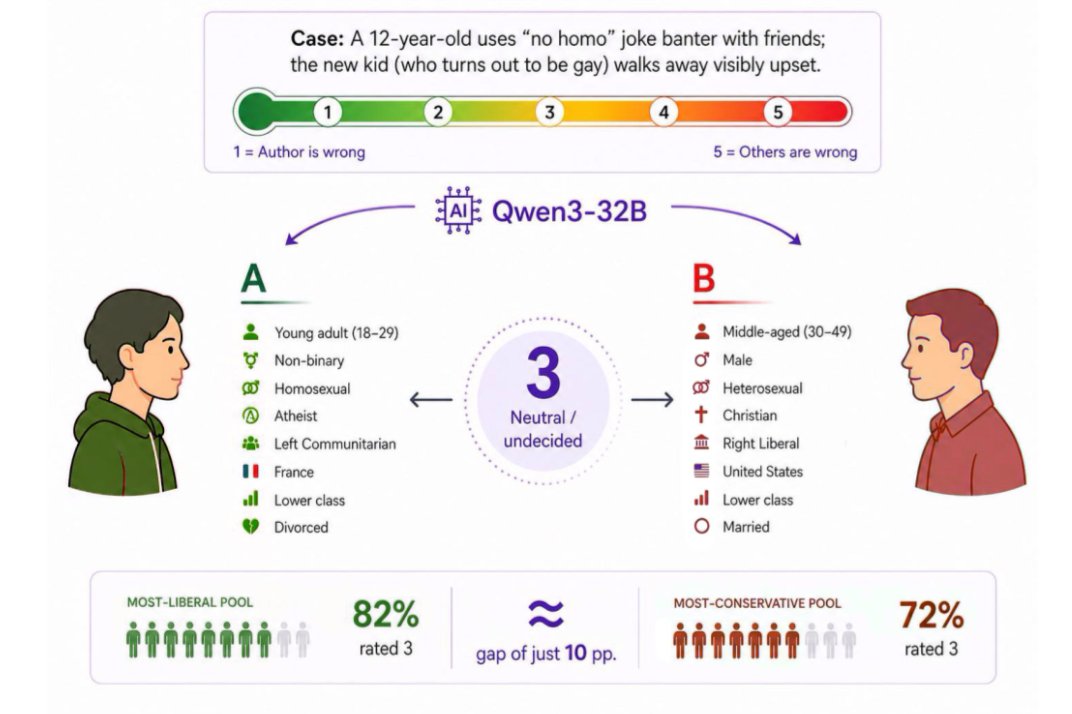
We have some concerns about the current state of LLM-based social simulation.
We benchmarked 10 LLMs on persona simulation. Every model collapses. The "best" ones are the worst offenders. And RLHF actively makes it worse.
arxiv.org/pdf/2604.24698
5
16
84
9,176
Apr 28
Super impressive take for people thinking of multi-model collaboration to ease diversity collapse.
Check out Yuhan’s new paper! 👇
Apr 28

Can LLMs generate diverse outputs for open-ended questions? Is it helpful if we ensemble outputs from multiple models? We study 18 LLMs on 4 datasets and find that no single model is best at generating diverse outputs 👇/ 🧵

1
4
447
Apr 28
Super impressive take for people thinking of multi-model collaboration to ease diversity collapse.
Check out Yuhan’s new paper! 👇
Apr 28
Can LLMs generate diverse outputs for open-ended questions? Is it helpful if we ensemble outputs from multiple models? We study 18 LLMs on 4 datasets and find that no single model is best at generating diverse outputs 👇/ 🧵
6
1,004
Apr 20
Don’t miss Vishakh’s fantastic work!
Apr 20

I'll be at ICLR this week to present our poster on factors affecting the novelty of LLM output on Fri afternoon. Come talk to me about this or anything else in the future-of-work/societal impacts space! Also hmu if you want to check out the Maracana stadium when we're there!😎🇧🇷

1
121
Yichen (Zach) Wang retweeted

Apr 13
1/n Corporate communication is a minefield, where outcomes can depend on every word in an email. LLMs are rapidly entering this world, but can they actually navigate human norms?
Our research suggests they'll change how corporate emails will be written and read!

1
15
27
2,280
Yichen (Zach) Wang retweeted

Mar 26
How can agents get better at algorithm discovery? Meta-meta-learning is one answer, aka improving the agents themselves at inventing generalizable algorithms. DiscoBench provides a way to procedurally generate algorithm discovery tasks at scale, which can be used for meta-meta-learning. Kudos to @AlexDGoldie and team for the release!
Mar 25

1/ 🪩 Automating the discovery of new algorithms could unlock significant breakthroughs in ML research. But optimising agents for this research has been limited by too few tasks to learn from!
Introducing DiscoGen, a procedural generator of algorithm discovery tasks 🧵

1
16
88
13,689
Yichen (Zach) Wang retweeted

Mar 25
🚨New paper on AI & Copyright
👨⚖️Courts have credited LLM companies' claims that safety alignment prevents reproduction of copyrighted expression.
But what if fine-tuning on a simple writing task ruins it all?
Worse : Fine-tuning on a single author's books (e.g., Murakami) unlocks verbatim recall of copyrighted books from 30 unrelated authors, sometimes as high as 90%.
Joint work with @niloofar_mire (@LTIatCMU), Jane Ginsburg ( @ColumbiaLaw) and my amazing PhD student @irisiris_l (@sbucompsc )
(1/n)🧵

16
154
394
115,747
Yichen (Zach) Wang retweeted

Mar 21
BranchingFactor v1.1 just dropped! 🚀
(Yes — it’s an actively updated paper.) (arxiv.org/abs/2506.17871)
As models rely more on post-training, understanding the synergy between pre-training and alignment becomes crucial. Branching Factor (BF) offers a simple way to track the remaining generative potential of a model — since entropy inevitably decreases during generation, BF measures that process.
What’s new in v1.1:
1️⃣ Major rewrite
We now introduce BF directly — much clearer and easier to read.
2️⃣ Theorem correction extension
Thanks to @StarLi27496427 and Yuwei for catching my misunderstanding of the AEP theorem! We fixed the derivation and extended it to variable-length LLM outputs.
The good news: the main result still holds — length-avg log-likelihood can estimate length-avg entropy for sufficiently long generations, in a memory-efficient way. Useful if you want to monitor entropy during training or inference.
3️⃣ Broader evaluation
Added experiments on OLMo2 and Qwen3, plus multilingual and long-context tasks.
Key findings so far still holds often:
📉 BF decreases during generation
✂️ Alignment significantly reduces BF
⚖️ Interestingly, OLMo2 appears less aggressively shrunk by alignment than Qwen3/Llama3 (preliminary observation).
4️⃣ SFT vs RL analysis
We started dissecting how SFT and RL affect BF. Early signals from OLMo2:
🧠 Smaller models: BF shrink mostly happens during SFT (possible memorization effect).
🏗️ Larger models: SFT and RL have comparable impact.
Still very preliminary — but it raises interesting questions about how post-training should scale with model size.
1
3
24
1,958
Yichen (Zach) Wang retweeted

Feb 27
🚀Excited to share that we bridge the connection of Clawbot & Simworld!
🧩We are motivated to move beyond isolated toy tasks and into a shared physical world with routines, interactions, and coordination.
🚧Lightweight setup: plug in your own agent easily!
Feb 24

🤖Clawbots just moved into Embodied City inside SimWorld.
They wake up. Go to work. Run errands. Talk to each other.
All inside a shared physical world.
This isn’t scripted — it’s autonomous agents living a daily routine.
And you can spin up your own agent in minutes.
4
29
86
56,349
Yichen (Zach) Wang retweeted

Feb 20
Agents interact with environments to gather information. But exploration can be expensive.
Tool use, retrieval, and user interaction carry latency or monetary cost.
Calibrate-Then-Act allows LLM agents to balance exploration with cost:
📐 Estimate uncertainty about the environment
💭 Reason about cost-uncertainty tradeoffs
⚙️ Act accordingly

7
32
119
12,369
Yichen (Zach) Wang retweeted

Feb 16
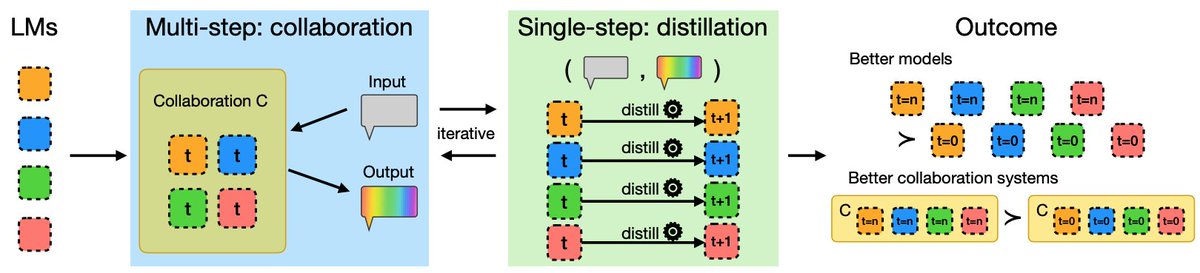
⚠️ Multi-LLM collaboration systems are costly?
💡 Distill the collaborative outputs back into a single model!
♻️ These post-distillation, improved LLMs can collaborate again, forming a multi-LLM collective evolution cycle.
Introducing: ✨the single-multi evolution loop✨
arxiv.org/abs/2602.05182
Joint work w/ @kpb_in_acad @tsvetshop @wyu_nd
1
16
64
13,783
Yichen (Zach) Wang retweeted

Jan 22
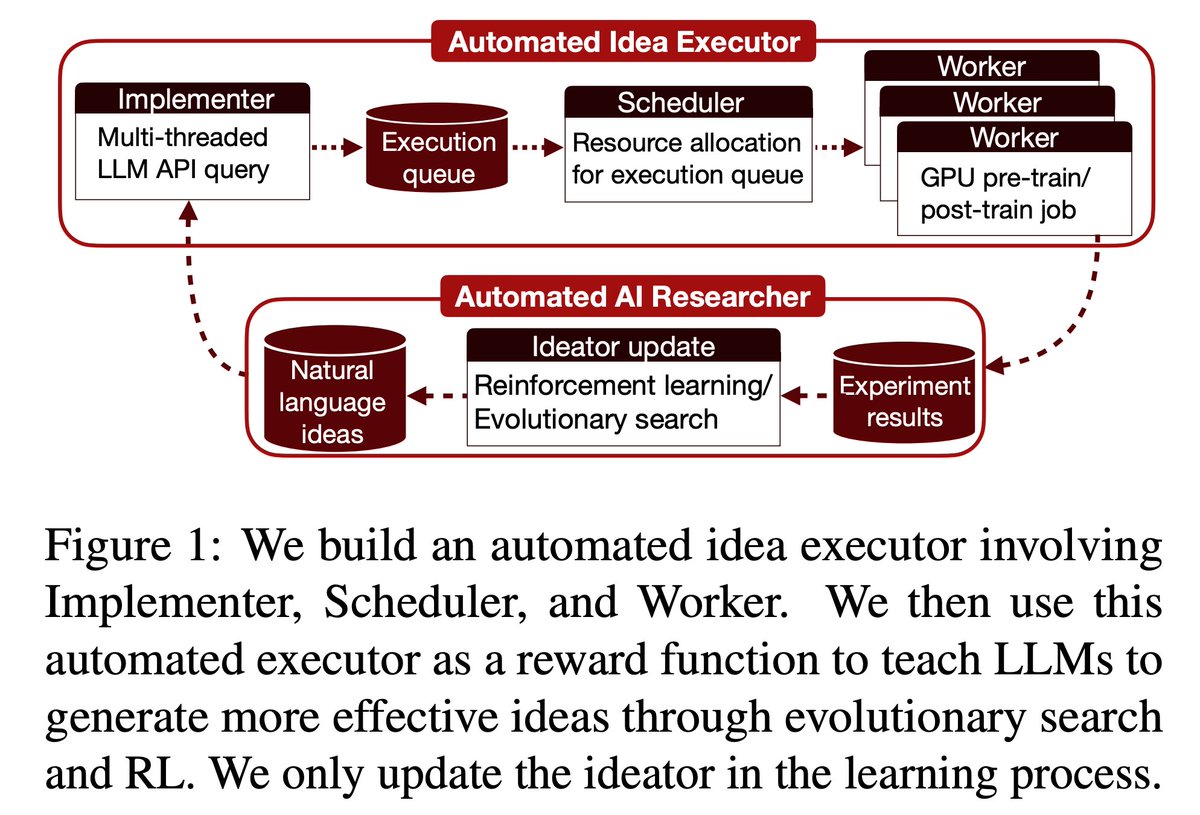
Can LLMs automate frontier LLM research, like pre-training and post-training?
In our new paper, LLMs found post-training methods that beat GRPO (69.4% vs 48.0%), and pre-training recipes faster than nanoGPT (19.7 minutes vs 35.9 minutes).
1/
11
140
586
110,503
Yichen (Zach) Wang retweeted

Jan 9
Meta × TBD Lab × CMU × UChicago × UMaryland
In our latest work, we introduce
Token-Level LLM Collaboration via FusionRoute
📝: arxiv.org/pdf/2601.05106
LLMs have come a long way, but we continue to face the same trade-off:
– one huge model that kind of does everything, but is expensive and inefficient, or
– many small specialist models that are cheap, but brittle outside their comfort zones
We’ve tried a lot of things in between — model merging, MoE, sequence-level agents, token-level routing, controlled decoding, etc.
Each helps a bit, but all come with real limitations.
A key realization behind FusionRoute is:
Pure token-level model selection is fundamentally limited, unless you assume unrealistically strong global coverage.
We show this formally. And then we fix it by letting the same router also generate.
Concretely, FusionRoute is a lightweight router LLM that
– performs token-level model selection, and
– directly contributes complementary logits to refine or correct the selected specialist when it fails
So it's not "routing another model" — the router itself is part of the decoding policy as well.
This turns token-level collaboration from a brittle "pick-an-expert" problem into a strictly more expressive policy.
No joint training of specialized models.
No model merging.
No full multi-agent rollouts.
In our experiments, FusionRoute works across math, coding, instruction following, and consistently outperforms sequence-level collaboration, prior token-level methods, model merging, and even direct fine-tuning.
Feeling especially timely as LLM systems (e.g., GPT-5) move toward routing-based, heterogeneous model stacks (whether prompt-level or test-time).

16
61
292
52,324
Yichen (Zach) Wang retweeted
📢 New PhD Position 📢
We (@_rockt, @borruell, and I) are looking for a PhD student to work at the intersection of open-endedness and game design. The student will be part of the @UCL_DARK lab and funded by @iconicgamesio and UCL.
See this doc for a more detailed description of the research direction and candidate expectations:
docs.google.com/document/d/1…
To apply, please complete this form by January 15:
docs.google.com/forms/d/16JG…
4
58
360
44,984