
Joined July 2023
- Tweets 626
- Following 179
- Followers 20
- Likes 367
50 Photos and videos

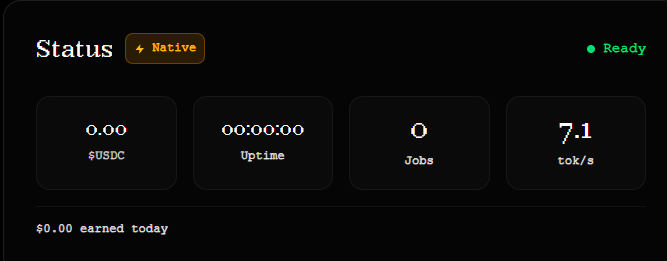




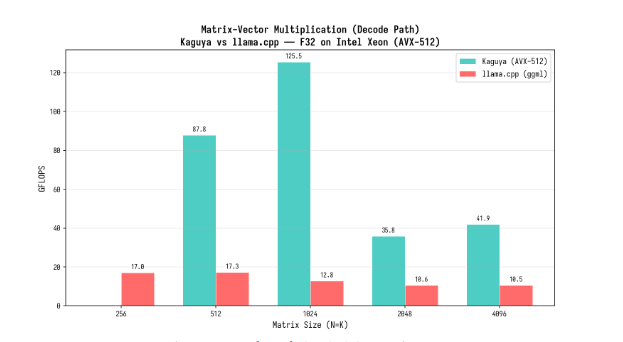


私が多分、日本で初めてのworkerでしょう。
ランタイム設定をもう少し最適化してほしいです。ncmoeを適切に設定すれば、40tok~にはなると思います
#c0mputeAI

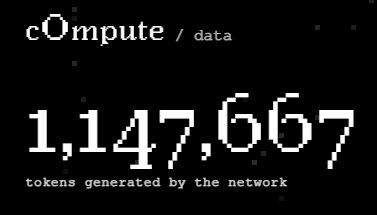
Happy 1,000,000 tokens generated by the network!
Not even 48 hours later and we've 5x'd our token output. Here are some more stats:
- Total workers online: 4 -> 29 (725%)
- Total jobs: 123 -> 1,088 (884%)
- New signups: 13 -> 84 (646%)
More: data.c0mpute.ai
4


Jun 13
C u r s o r S u c k s
Jun 3

cursor sucks, try superset ;)
22
CloudGoat retweeted
Jun 13
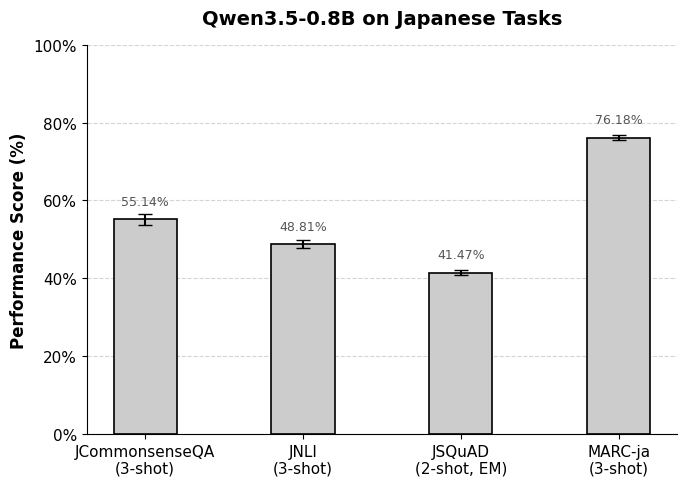
I'm not sure if there's any demand for this, but I'm publishing the results of some Japanese language benchmarks for Qwen3.5-0.8B.
• JCommonsenseQA: 55.14%
• JNLI: 48.81%
• JSQuAD: 41.47%
• MARC-ja: 76.18%
I can't wait for Qwen3.6-0.8B!
1
1
88
Jun 12
色々ファインチューニングしたいんだけど、数学の勉強をすればいいのか、LLMの勉強をすればいいのか、pythonの勉強をすればいいのかわからない...
11

Kimi 是 GOAT
开源社区感谢 Qwen 所做出的一切
文心一言传奇耐活王,ERNIE 也做到 TB scale 了,一直不温不火
腾讯内部 HY 和 WeLM 赛马,马上大的就要来了





11
5
86
17,708

I recently switched from Qwen 3.5 9B to LFM2.5-8B-A1B by @liquidai, and it's quickly become my default local model in Hermes Agent Desktop.
For agentic tasks, it's one of the strongest local models I've used so far. It's surprisingly fast, reliable, and works really well with tools.
Coding is still where it struggles the most.
Other than that, it's been consistently solid and easily one of my favorite local models right now.

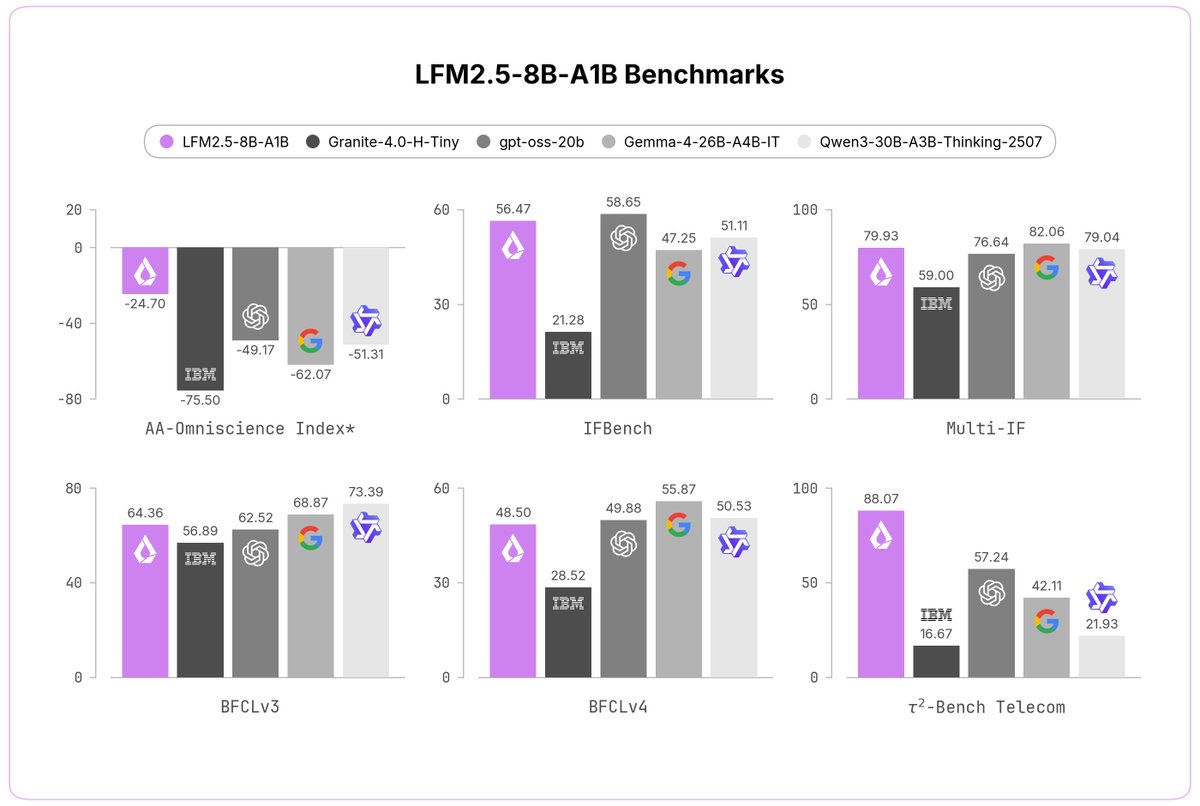
Today, we're releasing LFM2.5-8B-A1B, a device-optimized model designed to power real-life applications on phones, laptops, PCs, robots, and fast & lightweight server-side use-cases.
> 8B MoE, 1.5B active
> Expanded 128K context
> LFM2.5 flagship hybrid MoE architecture
> Trained on 38T tokens large-scale RL
> fast, reliable tool calling, punching above its weight, comparable to models with up to 4x its size
> customizable on a single GPU for any specialized task
> LFM2 open-weight license
🧵
38
39
570
72,821

Jun 10
What do you think GPT's counterpart to the 'Mythos' class will be named?
2