
Build efficient general-purpose AI at every scale.
Joined March 2023
- Tweets 647
- Following 44
- Followers 29,835
- Likes 1,444
157 Photos and videos





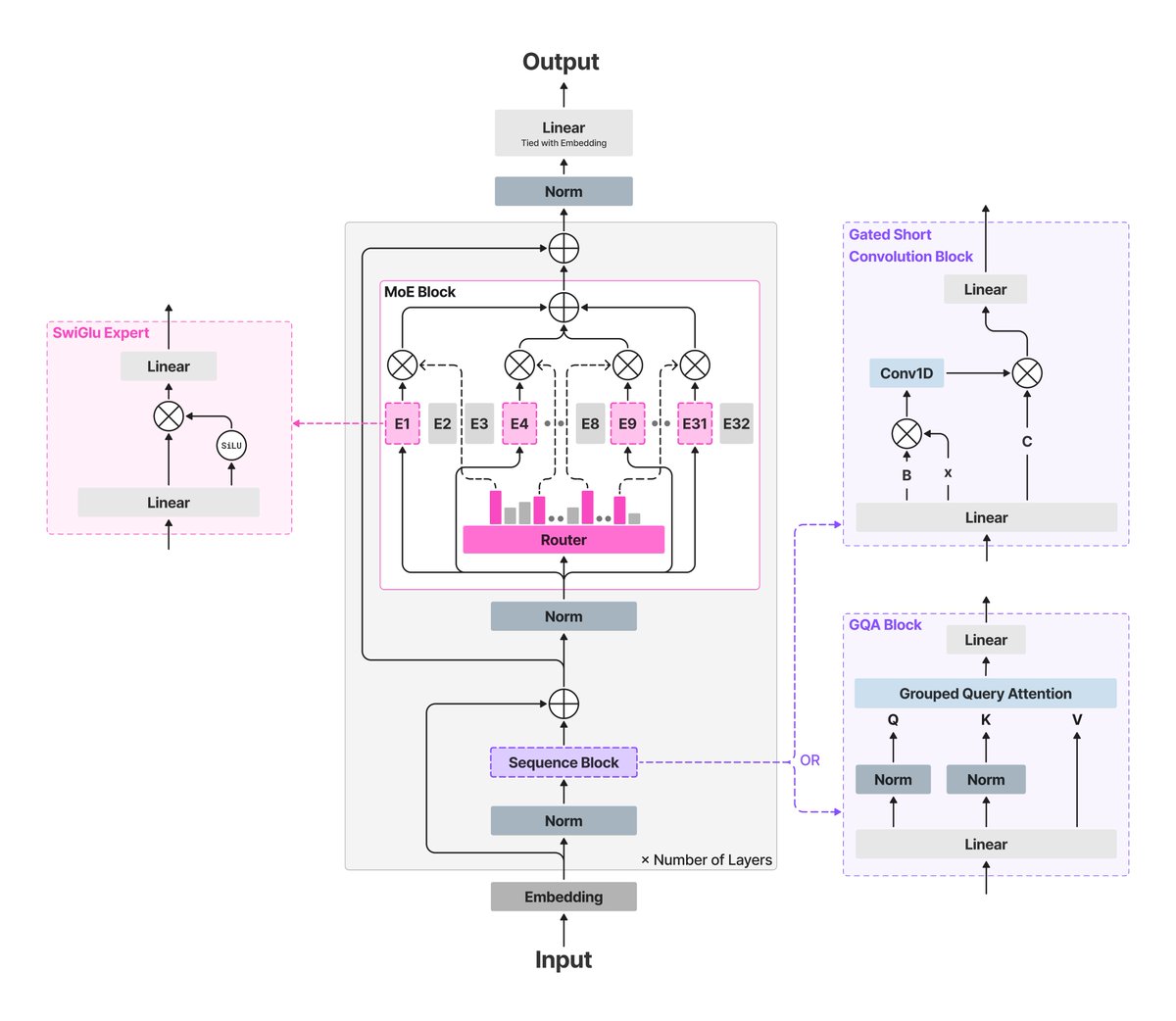

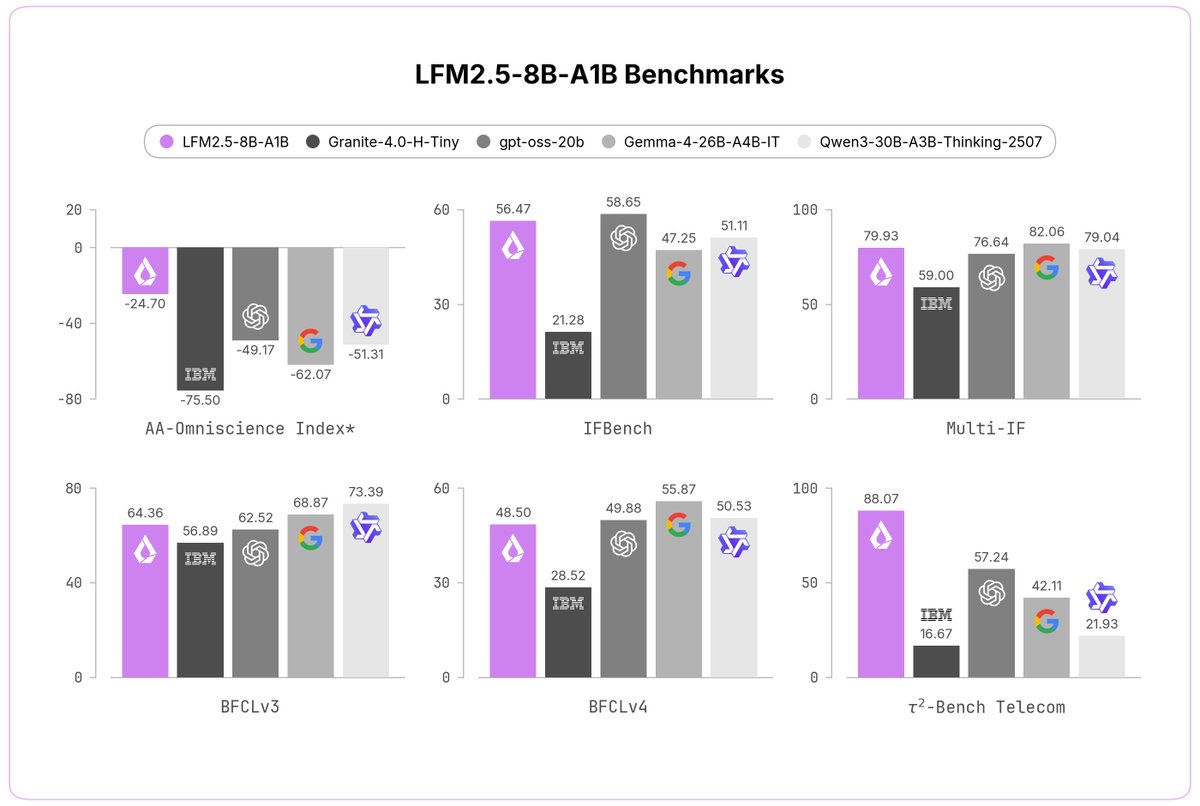




Today, we're releasing LFM2.5-8B-A1B, a device-optimized model designed to power real-life applications on phones, laptops, PCs, robots, and fast & lightweight server-side use-cases.
> 8B MoE, 1.5B active
> Expanded 128K context
> LFM2.5 flagship hybrid MoE architecture
> Trained on 38T tokens large-scale RL
> fast, reliable tool calling, punching above its weight, comparable to models with up to 4x its size
> customizable on a single GPU for any specialized task
> LFM2 open-weight license
🧵
140
507
3,839
1,318,204
We are proud to announce that Ion Stoica (@istoica05) co-founder of @databricks, @anyscalecompute, and @arena, and UC Berkeley Professor of Computer Science, has joined Liquid AI as a strategic member of our Advisory Council.
Ion will guide us on our growth journey as we build the efficient AI infrastructure and platform for a hardware-aware, physical AI future.
5
14
134
16,682
Most multimodal systems need data that combines every modality together. Hard to get, expensive to build.
Our CTO Mathias Lechner, @mlech26l, sits down with Saniya Karwa, @saniwhya, from our multimodal research team to talk about building a mode that handles text, audio, and image, and why you might not need as much combined training data as you think.
7
12
156
14,369
Liquid AI retweeted

Jun 8
LFM2.5-Audio-1.5B-JP試した!
このレベルがLocalで動くのすごい!
自音声拾ってしまうので、イヤホンでしか試せないのだが、割り込みもイケる
1
12
86
6,760

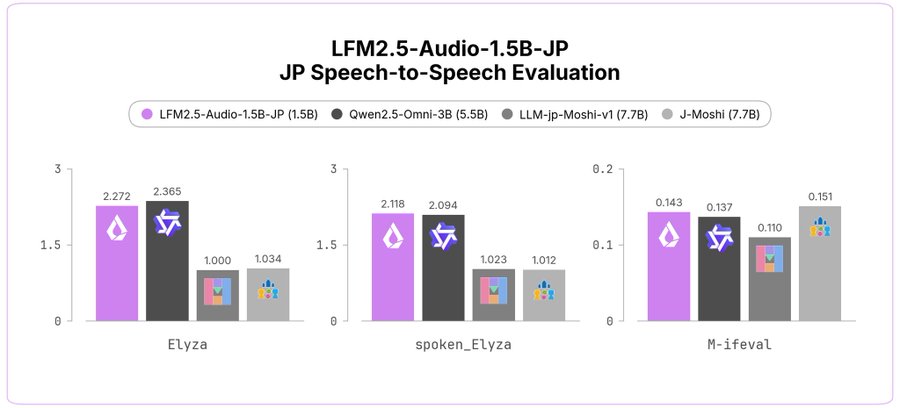
Liquid AI released two new Japanese models: LFM2.5-Audio-1.5B-JP and LFM2.5-1.2B-JP-202606.
The release includes Liquid AI’s first Japanese audio model and an updated Japanese language model focused on stronger benchmark performance across Japanese tasks.
Both models are available on Hugging Face.

本日、日本語向けの新モデルを2つ公開しました🇯🇵
音声モデル:LFM2.5-Audio-1.5B-JP
言語モデル:LFM2.5-1.2B-JP-202606
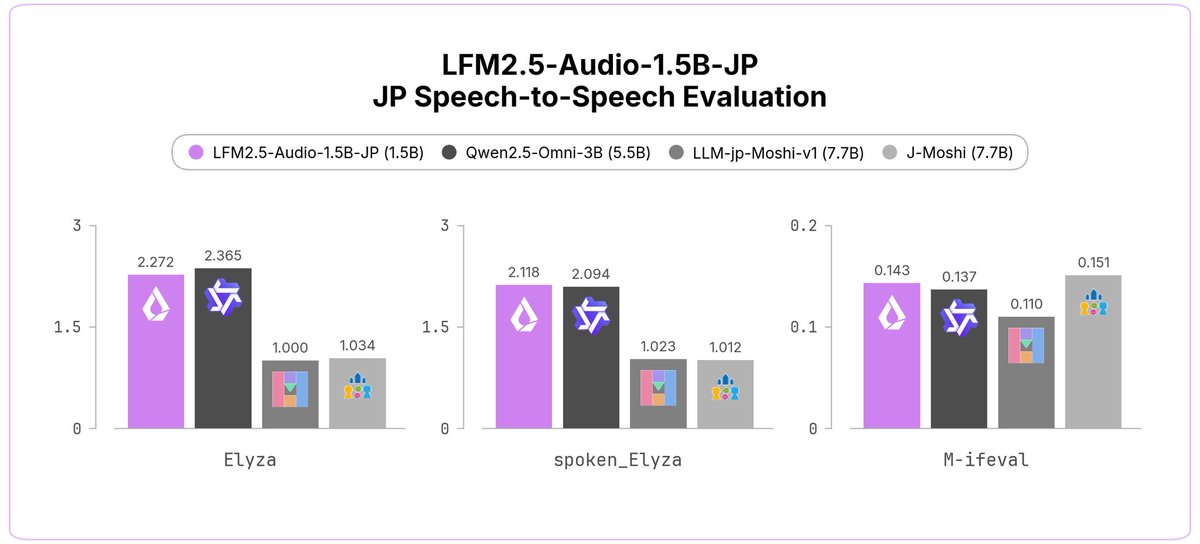
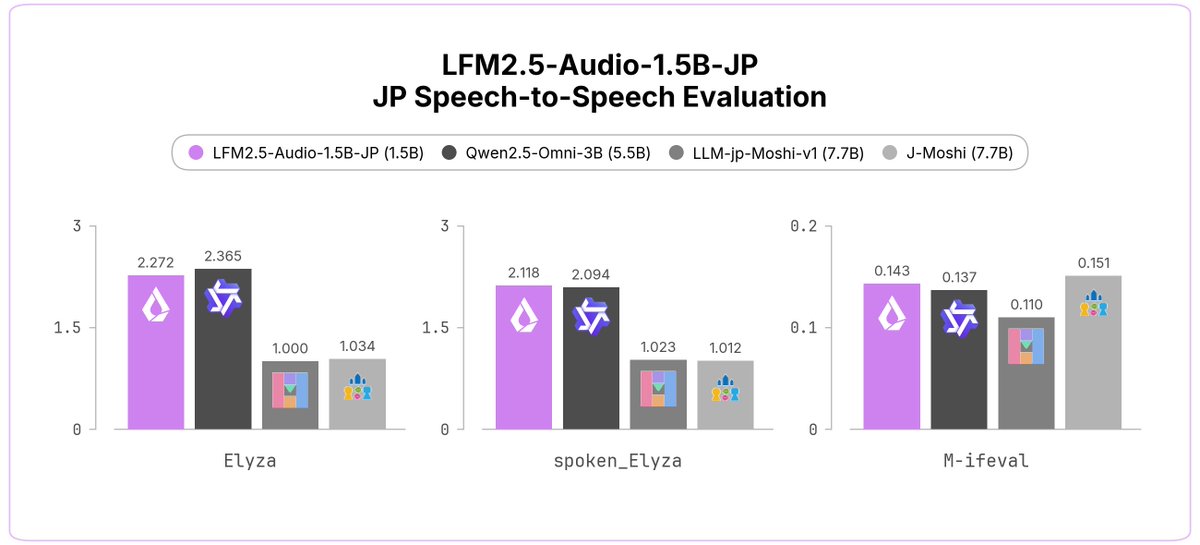
LFM2.5-Audio-1.5B-JP は、Liquid AI 初の日本語音声モデルです。
日本語で話しかけると、日本語の音声で応答します。ASR・TTS を別々に組み合わせるのではなく、単一のモデルで完結するエンドツーエンドの音声モデルです。
> 日本語に対応した、このスケールでは初の汎用エンドツーエンド音声モデル
> 15億(1.5B)パラメータで、J-Moshi(約77億)を上回る性能
> Qwen2.5-Omni-3B(約55億)にも匹敵する性能
> 追加学習を想定したベースモデル
LFM2.5-1.2B-JP-202606 は、最新版の日本語言語モデルです。
前バージョン(LFM2.5-1.2B-JP)はすでに、JMMLU、M-IFEval、GSM8K において Qwen3-1.7B や Llama 3.2 1B を上回っていました。
今回のアップデートでは、日本語データミックスの改善と新しい中間・事後学習により、さらに広範な日本語ベンチマークで 最高性能を達成しています。
どちらのモデルも本日より利用できます。
モデル:
音声: huggingface.co/LiquidAI/LFM2…
言語: huggingface.co/LiquidAI/LFM2…
ドキュメント: docs.liquid.ai
1
6
33
4,840
Liquid AI retweeted

Jun 7
@mlech26l and I review some of the basics of ML training infra here.
These days we’ve been spending a lot of time deeper in the stack, iterating on some exciting bets in compilers, quantization, long-context optimization, communication-compute overlap, etc.
Even though @liquidai models are optimized for deployment on edge, pushing the frontier of large-scale training on GPUs is just as relevant today.
Training LFMs at scale means solving parallelism across every layer of the architecture. And not all layers are the same.
Our CTO Mathias Lechner (@mlech26l) sits down with Liquid's founding engineer Paul Pak (@paulpak__) to talk training infrastructure: Data, tensor, pipeline, expert, and context parallelism, and how they make context parallelism work across hybrid architectures with both attention and convolution operators.
2
2
25
4,232
Training LFMs at scale means solving parallelism across every layer of the architecture. And not all layers are the same.
Our CTO Mathias Lechner (@mlech26l) sits down with Liquid's founding engineer Paul Pak (@paulpak__) to talk training infrastructure: Data, tensor, pipeline, expert, and context parallelism, and how they make context parallelism work across hybrid architectures with both attention and convolution operators.
9
15
159
17,137
Liquid AI retweeted

Jun 6
実は私もついこの前まで特製日本語モデルがあるの知ってなくて、なんか嬉しいです🥹
本日、日本語向けの新モデルを2つ公開しました🇯🇵
音声モデル:LFM2.5-Audio-1.5B-JP
言語モデル:LFM2.5-1.2B-JP-202606
LFM2.5-Audio-1.5B-JP は、Liquid AI 初の日本語音声モデルです。
日本語で話しかけると、日本語の音声で応答します。ASR・TTS を別々に組み合わせるのではなく、単一のモデルで完結するエンドツーエンドの音声モデルです。
> 日本語に対応した、このスケールでは初の汎用エンドツーエンド音声モデル
> 15億(1.5B)パラメータで、J-Moshi(約77億)を上回る性能
> Qwen2.5-Omni-3B(約55億)にも匹敵する性能
> 追加学習を想定したベースモデル
LFM2.5-1.2B-JP-202606 は、最新版の日本語言語モデルです。
前バージョン(LFM2.5-1.2B-JP)はすでに、JMMLU、M-IFEval、GSM8K において Qwen3-1.7B や Llama 3.2 1B を上回っていました。
今回のアップデートでは、日本語データミックスの改善と新しい中間・事後学習により、さらに広範な日本語ベンチマークで 最高性能を達成しています。
どちらのモデルも本日より利用できます。
モデル:
音声: huggingface.co/LiquidAI/LFM2…
言語: huggingface.co/LiquidAI/LFM2…
ドキュメント: docs.liquid.ai
2
2
51
7,978
本日、日本語向けの新モデルを2つ公開しました🇯🇵
音声モデル:LFM2.5-Audio-1.5B-JP
言語モデル:LFM2.5-1.2B-JP-202606
LFM2.5-Audio-1.5B-JP は、Liquid AI 初の日本語音声モデルです。
日本語で話しかけると、日本語の音声で応答します。ASR・TTS を別々に組み合わせるのではなく、単一のモデルで完結するエンドツーエンドの音声モデルです。
> 日本語に対応した、このスケールでは初の汎用エンドツーエンド音声モデル
> 15億(1.5B)パラメータで、J-Moshi(約77億)を上回る性能
> Qwen2.5-Omni-3B(約55億)にも匹敵する性能
> 追加学習を想定したベースモデル
LFM2.5-1.2B-JP-202606 は、最新版の日本語言語モデルです。
前バージョン(LFM2.5-1.2B-JP)はすでに、JMMLU、M-IFEval、GSM8K において Qwen3-1.7B や Llama 3.2 1B を上回っていました。
今回のアップデートでは、日本語データミックスの改善と新しい中間・事後学習により、さらに広範な日本語ベンチマークで 最高性能を達成しています。
どちらのモデルも本日より利用できます。
モデル:
音声: huggingface.co/LiquidAI/LFM2…
言語: huggingface.co/LiquidAI/LFM2…
ドキュメント: docs.liquid.ai
12
370
1,836
1,161,570
Liquid AI retweeted

New Japanese audio and text models!
Today we’re releasing two new models for Japanese: LFM2.5-Audio-1.5B-JP (audio) and LFM2.5-1.2B-JP-202606 (text).
🧵
1
17
4,089
Liquid AI retweeted

Jun 6
a sick Japanese audio model for the entire Japan market! ✨🔈🇯🇵
Today we’re releasing two new models for Japanese: LFM2.5-Audio-1.5B-JP (audio) and LFM2.5-1.2B-JP-202606 (text).
🧵
3
52
5,531
Liquid AI retweeted

Jun 6
オンデバイス最高水準の日本語テキスト・音声対話モデルを公開しました!
詳しくはこちら → prtimes.jp/main/html/rd/p/00…
Today we’re releasing two new models for Japanese: LFM2.5-Audio-1.5B-JP (audio) and LFM2.5-1.2B-JP-202606 (text).
🧵
10
41
4,813
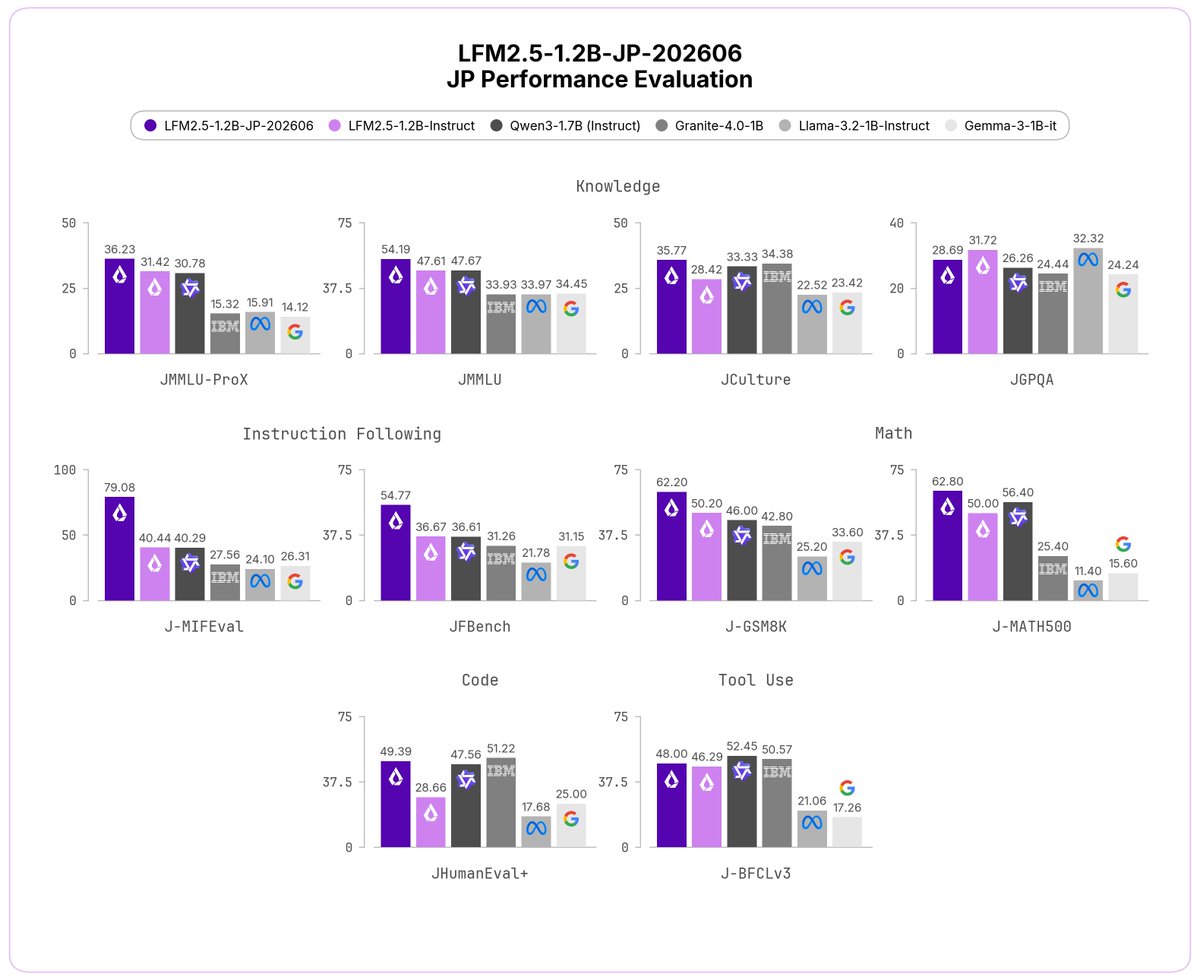
LFM2.5-1.2B-JP-202606 is an updated version of our Japanese text model.
The previous version already outperformed Qwen3-1.7B and Llama 3.2 1B on JMMLU, M-IFEval, and GSM8K. This update adds a better Japanese data mix and new post-training runs.
> SoTA across a wider range of Japanese benchmarks
(3/n)
2
2
38
3,498
> Weights:
Audio: huggingface.co/LiquidAI/LFM2…
Text: huggingface.co/LiquidAI/LFM2…
> Docs: docs.liquid.ai
3
25
2,665
Liquid AI retweeted

Jun 5
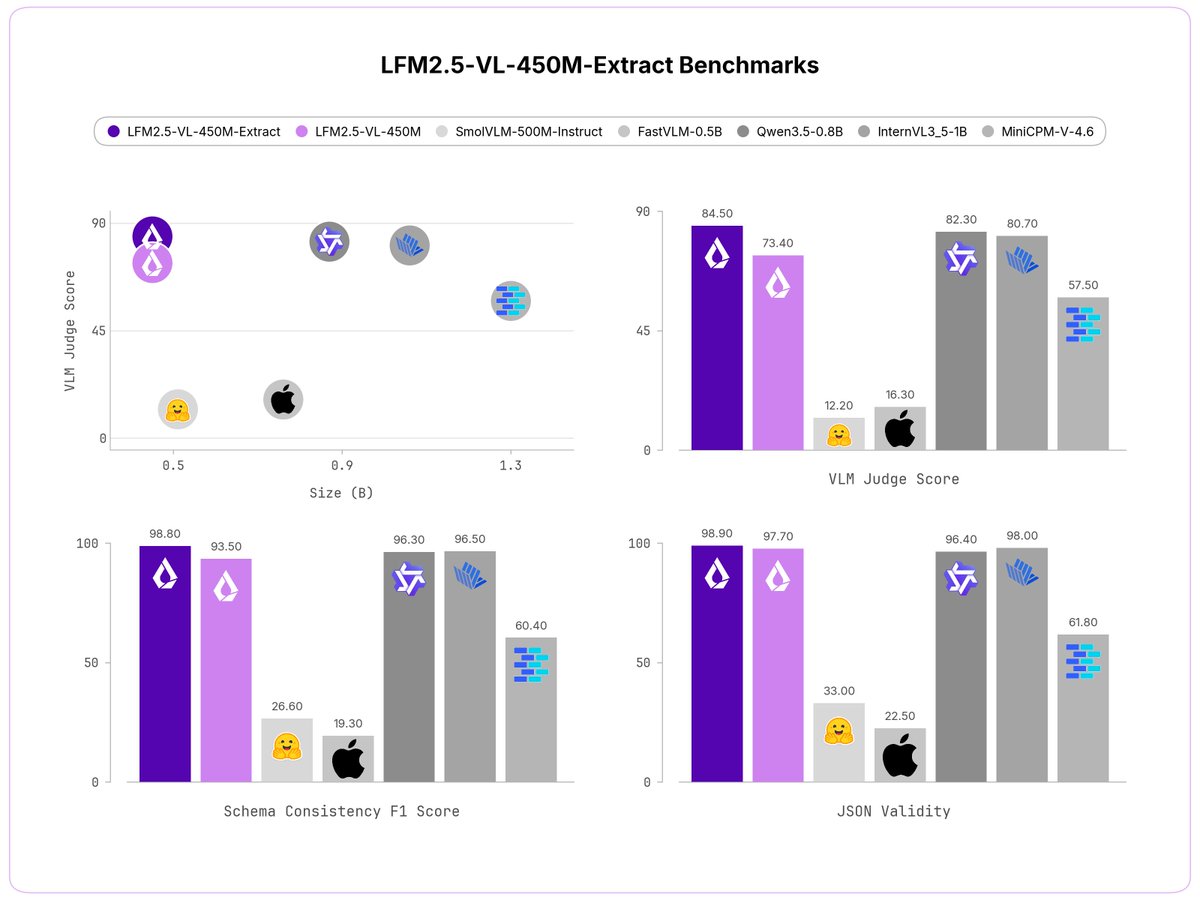
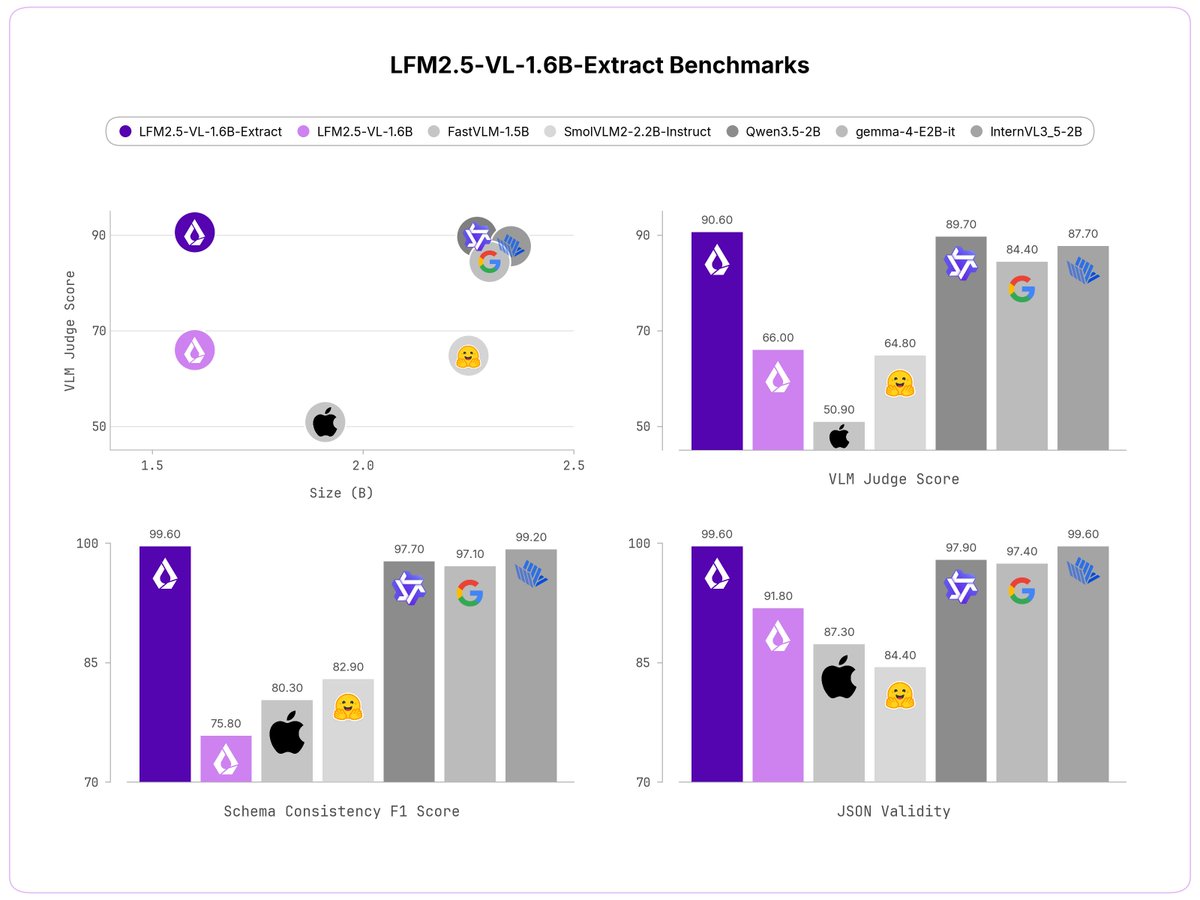
We released two new specialized VLMs 🎉
They extract structured outputs from images quickly and reliably.
You can customize your fields directly in the system prompt.
Introducing LFM2.5-VL-1.6B-Extract and LFM2.5-VL-450M-Extract: Vision-language models that return structured JSON, not free-form text.
Pass in an image and a list of fields. Get back a clean JSON object.
> Two sizes: 1.6B parameters and 450M
> open-weight
> run on any device SoC
🧵
15
15
166
13,678
Liquid AI retweeted

Jun 5
I wake up, new banger release from someone at Liquid, just another day at the intelligence factory ...👩🏭
Introducing LFM2.5-VL-1.6B-Extract and LFM2.5-VL-450M-Extract: Vision-language models that return structured JSON, not free-form text.
Pass in an image and a list of fields. Get back a clean JSON object.
> Two sizes: 1.6B parameters and 450M
> open-weight
> run on any device SoC
🧵
2
4
26
3,447