
Joined May 2009
- Tweets 159
- Following 64
- Followers 650
- Likes 97
24 Photos and videos









7 Nov 2025
Congratulations to the authors of our papers at #EMNLP2025 and #SEM2025 in Suzhou! Summaries and links (and remaining *SEM poster session) on our blog: ccgblog.seas.upenn.edu/2025/…
1
2
4
374
10 Nov 2025
Elior Sulem, Siyi Liu (@liusiyi64198), Fengze Liu, Haoyu Wang (@Haoyu_Wang_97), Yu Feng (@AnnieFeng6), Zheng Qi, Yanzhen Shen, Sihao Chen (@soshsihao), Chaitanya Malaviya (@cmalaviya11), Rohit Khoja, Vivek Gupta (@keviv9), Dan Roth (@DanRothNLP), & coauthors!
1
152
Cognitive Computation Group retweeted

6 Nov 2025
📷 New #EMNLP2025 Findings survey paper!
“Conflicts in Texts: Data, Implications, and Challenges” Paper: aclanthology.org/2025.findin…
Conflicts are everywhere in NLP — news articles reflecting different perspectives or opposing views, annotators who disagree, LLMs that hallucinate or contradict themselves, and personal/enterprise document collections that grow apart and are conflicting. Most research tackles these in isolation, and our survey provides the first unified view of conflicting information in NLP. We chart the path toward conflict-aware, reliable NLP systems.
Builds on our earlier work on:
- Multi-perspective dataset aclanthology.org/2021.naacl-… and search aclanthology.org/2022.findin…
- Hallucination detection aclanthology.org/2025.findin…
- Open-domain QA with conflicting contexts aclanthology.org/2025.findin…

4
12
867
14 Jul 2025
Check out our papers at #ICML2025 in Vancouver! Summaries, links, and poster sessions on our blog: ccgblog.seas.upenn.edu/2025/…. Congrats to @XingyuFu2, @DanRothNLP, and their co-authors!
2
1
139
Cognitive Computation Group retweeted

13 Jul 2025
I will be in #ICML2025 next week and present #ReFocus on Tuesday afternoon.
📍 West Exhibition Hall B2-B3 #W-202
⏱️ Tue 15 Jul 4:30 p.m. PDT - 7 p.m. PDT
Happy to chat and connect! Feel free to DM 😁
ReFocus link: huggingface.co/datasets/ReFo…
4
12
1,138
29 Apr 2025
Pleased to share our #NAACL2025 papers in Albuquerque! We’ve updated our blog post with the various session times – come check them out! ccgblog.seas.upenn.edu/2025/…
@soshsihao, @cmalaviya11, @liusiyi64198, @Wado_Will, @keviv9, @DanRothNLP
3
2
344
23 Apr 2025
Excited to share our papers at #ICLR2025 in Singapore! Check out the summaries on our blog (ccgblog.seas.upenn.edu/2025/…), and then check out the papers at oral session 1B (BIRD) and poster session 2 (for all three)!
@AnnieFeng6, @XingyuFu2, @BenZhou96, @muhao_chen, @DanRothNLP
6
9
1,148
Cognitive Computation Group retweeted

16 Apr 2025
#ICLR2025 Oral
LLMs often struggle with reliable and consistent decisions under uncertainty 😵💫 — largely because they can't reliably estimate the probability of each choice.
We propose BIRD 🐦, a framework that significantly enhances LLM decision making under uncertainty.
BIRD = LLM strengths sound probability theory
BIRD leverages LLMs for world modeling and constructs a Bayesian network using LLM-generated variables, enabling interpretable and trustworthy probability estimates.
✨ BIRD using LLaMA-3.1-70B achieves 30% more accurate probability estimates than GPT-4.
📄 Paper: openreview.net/pdf?id=fAAaT8…
💻 Code: github.com/CogComp/BIRD
Shoutout to my amazing collaborators: @BenZhou96 @wdwlin @DanRothNLP
🗓️ Oral Session 1B: Thu 24 April, 10:54 a.m. – 11:06 a.m. SGT
➡️ Poster: Thu 24 April, 3:00 p.m. – 5:30 p.m. SGT
#AI #LLM #decisionmaking #ProbabilisticAI
(1/n)

2
41
256
29,564
14 Apr 2025
We’re excited to share our #NAACL2025 conference and findings papers on our blog: ccgblog.seas.upenn.edu/2025/…! Congratulations to
@soshsihao
@cmalaviya11
@liusiyi64198
@Wado_Will
@keviv9
@DanRothNLP
and their co-authors!
(image Mukhopadhyay et al., 2025)
3
7
521
23 Jan 2025
New interview with @muhao_chen, former CCG postdoc, who talks with us about cats and hamsters, LLM safety, and far-flung national parks!
ccgblog.seas.upenn.edu/2025/…
1
14
893
18 Dec 2024
Grateful for Professor Bill Labov and for all his detailed and far-reaching work in the field of sociolinguistics.
2
251
Cognitive Computation Group retweeted

13 Nov 2024
Excited to share ✨ Contextualized Evaluations ✨!
Benchmarks like Chatbot Arena contain underspecified queries, which can lead to arbitrary eval judgments. What happens if we provide evaluators with context (e.g who's the user, what's their intent) when judging LM outputs? 🧵↓

2
30
121
21,292
5 Sep 2024
Before launching into our new semester, we asked our six summer interns to tell us about their experiences working with us this summer. Take a look! Special thanks to @keviv9 and @soshsihao for their excellent mentoring!
ccgblog.seas.upenn.edu/2024/…
1
4
520
16 Aug 2024
With special congratulations to @peterbailechen, @Wado_Will, and @DanRothNLP for their Outstanding Paper Award at the #ACL2024 Workshop on Knowledgeable LMs!
"Is Table Retrieval a Solved Problem? Exploring Join-Aware Multi-Table Retrieval" Peter Baile Chen, Yi Zhang, Dan Roth
12 Aug 2024

We’re excited to share our #ACL2024 conference and findings papers in our newest blog post: ccgblog.seas.upenn.edu/2024/…. Check out these papers from today’s sessions and next week’s virtual Findings presentations! Congrats to
@keviv9
@Wado_Will
@DanRothNLP
and their co-authors!
3
7
816
Cognitive Computation Group retweeted

16 Aug 2024
Congrats to Peter Baile Chen, Yi Zhang, @DanRothNLP for the Outstanding Paper Award at #ACL2024 Workshop on Knowledgeable LMs!
Is Table Retrieval a Solved Problem? Exploring Join-Aware Multi-Table Retrieval
Peter Baile Chen, Yi Zhang, Dan Roth
arxiv.org/pdf/2404.09889


15 Aug 2024

Tomorrow is the day! We cannot wait to see you at #ACL2024 @aclmeeting Knowledgeable LMs workshop!
Super excited for keynotes by Peter Clark @LukeZettlemoyer @tatsu_hashimoto @IAugenstein @ehovy Hannah Rashkin!
Will announce a Best Paper Award ($500) and a Outstanding Paper Award ($200), kindly supported by @AmazonScience.
Website: knowledgeable-lm.github.io
Location: Lotus Room 10
Zoom: underline.io/events/466/sess…
Meet with our organizers @ZoeyLi20
@megamor2 @eunsolc @mjqzhang @peterbhase @Meng_CS @JiaweiHan @preslav_nakov @mohitban47 @hengjinlp! Looking forward to talking with you!
#LLMs #knowledge #NLProc

1
6
25
3,181
12 Aug 2024
We’re excited to share our #ACL2024 conference and findings papers in our newest blog post: ccgblog.seas.upenn.edu/2024/…. Check out these papers from today’s sessions and next week’s virtual Findings presentations! Congrats to
@keviv9
@Wado_Will
@DanRothNLP
and their co-authors!
4
7
1,504
Cognitive Computation Group retweeted

11 Aug 2024
I can’t make it to #ACL2024 in person this year, but I’ll be there virtually! 🎉💻 Thrilled to present our three papers on Complex Data Reasoning—Visual Flowcharts QA, Chart Fact-Checking, and Robustness in Finance QA. 🚀📊📚🔍 Stay tuned for details! @cogcomp @upennnlp @SCAI_ASU
1
5
24
1,992
20 Jun 2024
New on the blog: An interview with former CCG student researcher Celine Lee, who talks with us about code, creativity, and making connections in the NLP community!
ccgblog.seas.upenn.edu/2024/…
1
271
Cognitive Computation Group retweeted
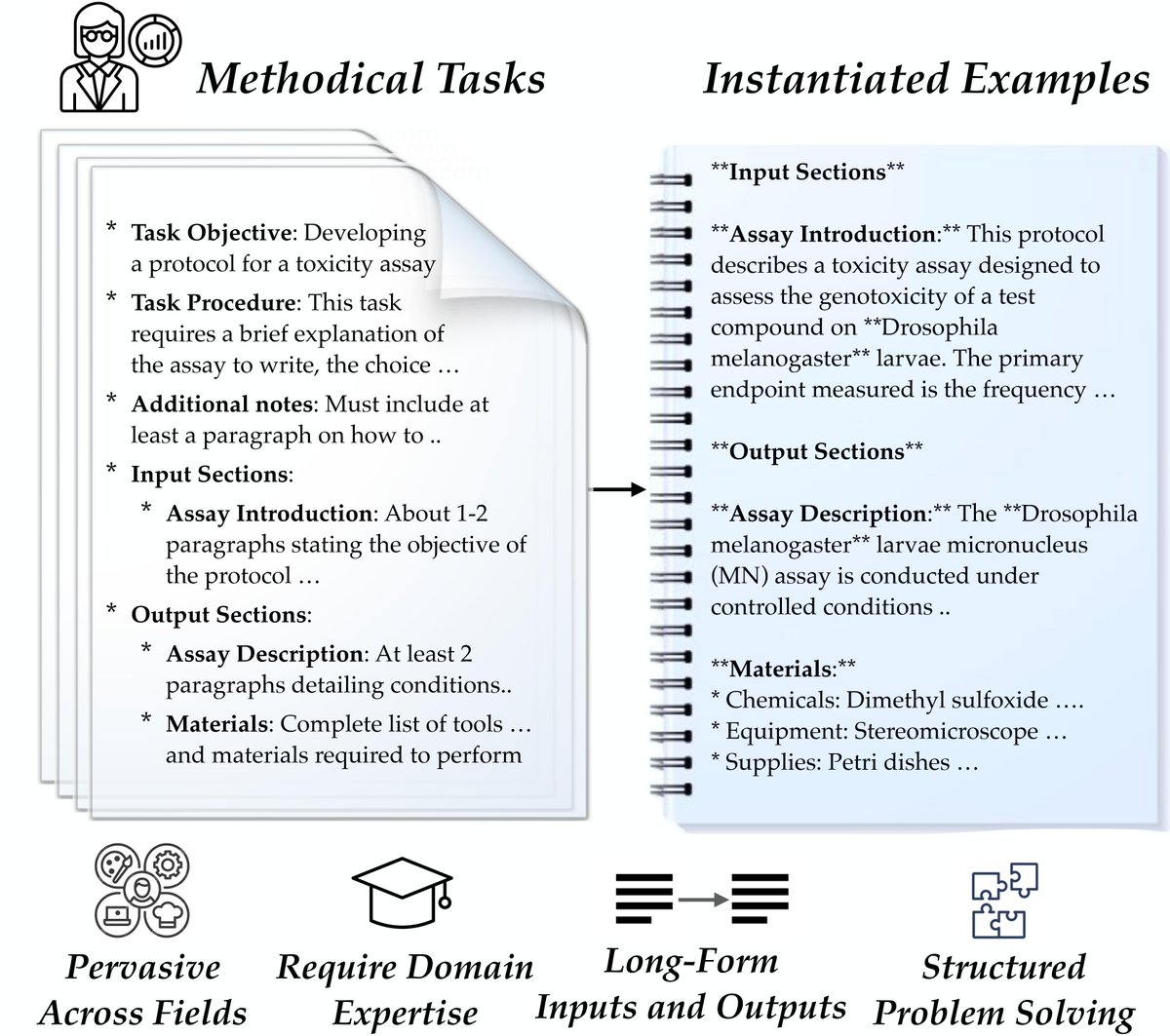
29 May 2024
Excited to share new work done @GoogleDeepMind: 🏔️ DOLOMITES: Domain-Specific Long-Form Methodical Tasks, a new long-form generation benchmark for evaluating language models on **realistic** domain-specific tasks.
Website: dolomites-benchmark.github.i…
Paper: arxiv.org/abs/2405.05938
3
28
73
12,370
22 May 2024
New on our blog: we’re excited to share our #NAACL2024 papers! ccgblog.seas.upenn.edu/2024/…
Congratulations to @soshsihao, @Xiaodong_Yu_126, @cmalaviya11, @BenZhou96, @hangfeng_he, @hongming110, @DanRothNLP, @XingyuFu2, @muhao_chen, @yatskar, and co-authors!
(image Yu et al., 2024)
5
7
1,943