
Joined February 2018
- Tweets 418
- Following 613
- Followers 1,340
- Likes 962
66 Photos and videos






Pinned Tweet

May 7
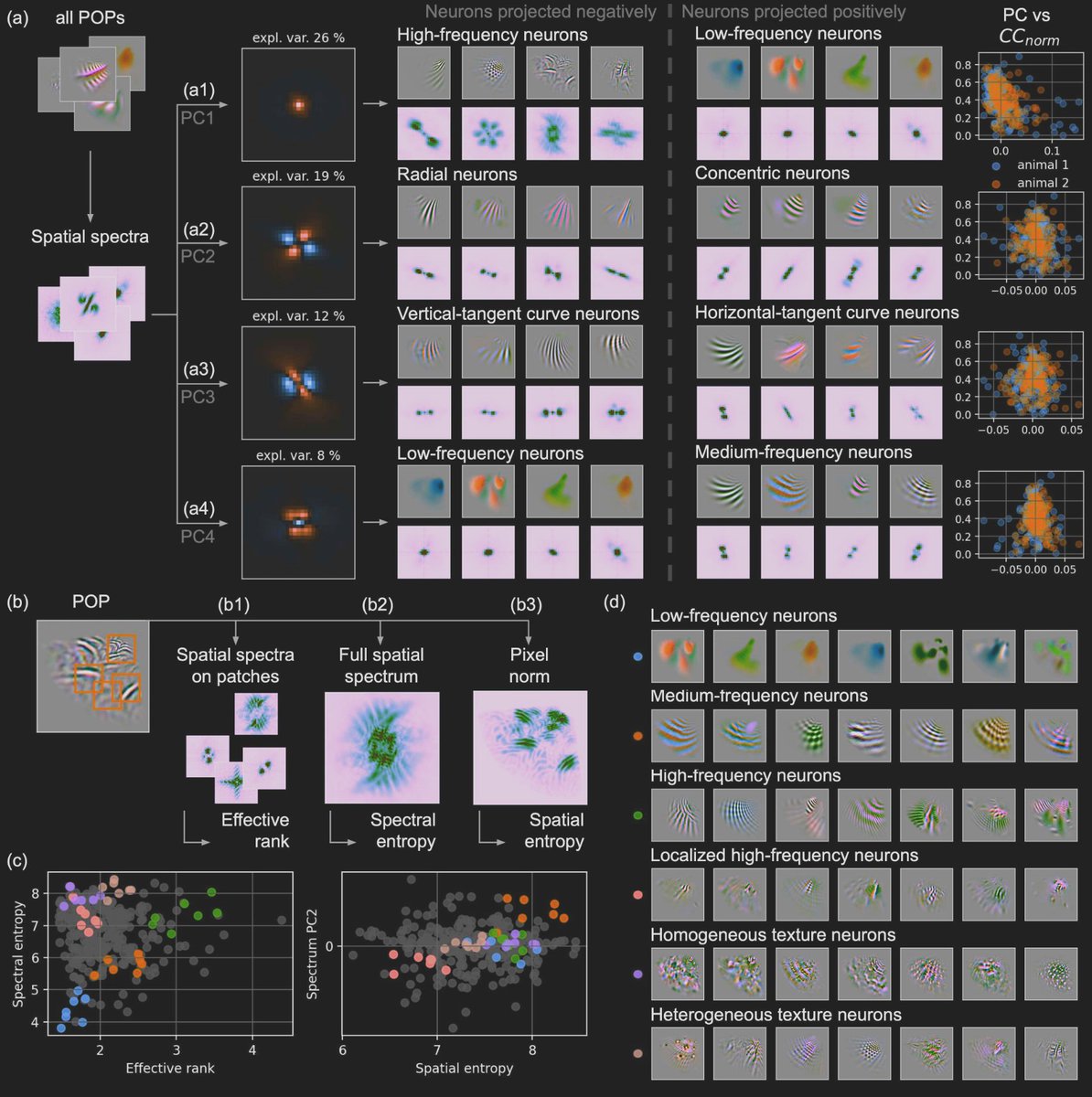
2 emerging interpretability trends I'm excited about from this paper: (1) agent-facing interp & (2) interp objectives for autoresearch 🧵

NEW paper from Microsoft Research.
(bookmark it)
The entire interpretability literature is built around human readers. As more analysis gets delegated to agents, the right target of interpretability shifts. This paper is a recipe for designing tools that agents can actually reason about.
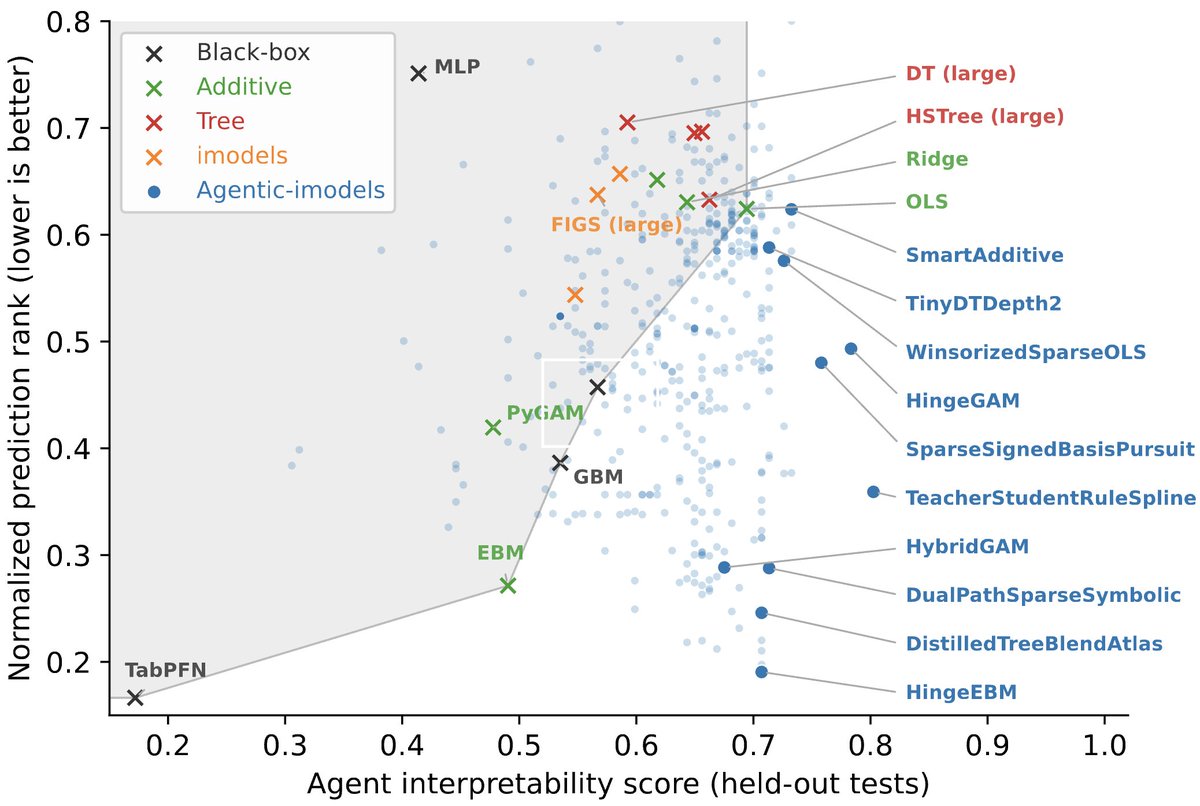
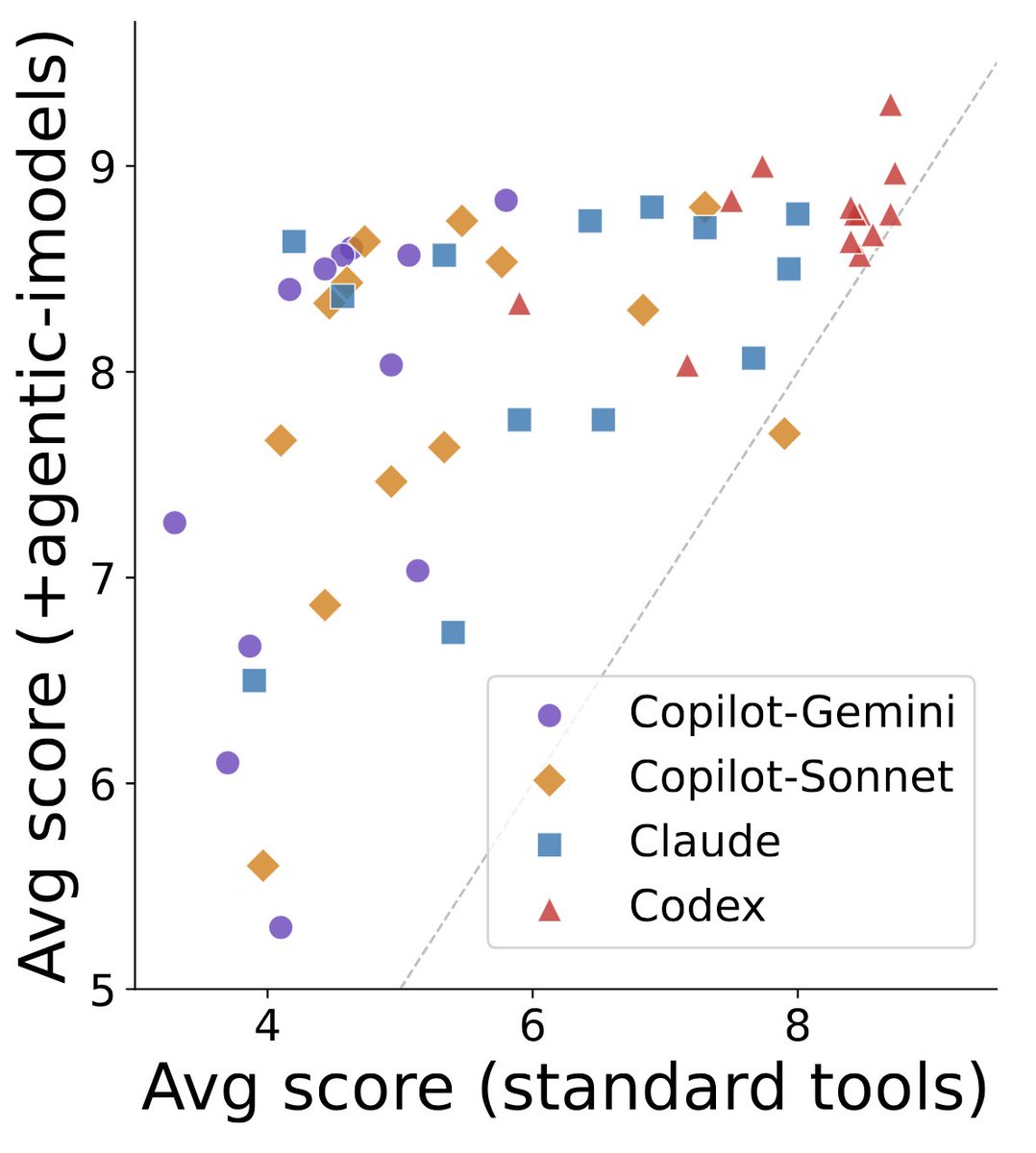
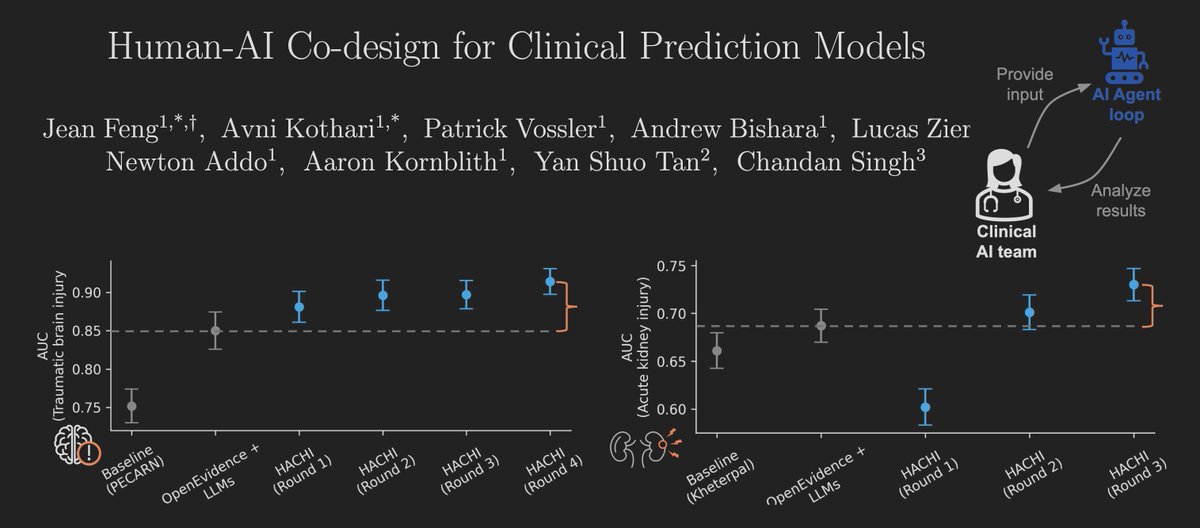
They introduce Agentic-imodels, an autoresearch loop where a coding agent (Claude Code, Codex) iteratively evolves scikit-learn-compatible regressors that are simultaneously accurate AND readable by other LLMs.
Interpretability is measured by whether a small LLM can simulate the fitted model's behavior just by reading its string representation. Predictions, feature effects, counterfactuals, all from the __str__ output alone.
Run on 65 tabular datasets, the discovered models push the Pareto frontier past every classical interpretable baseline (decision trees, GAMs, sparse linear), and improve four downstream agentic data science systems on the BLADE benchmark by 8% to 73%.
Paper: arxiv.org/abs/2605.03808
Learn to build effective AI agents in our academy: academy.dair.ai/

1
13
69
8,300
Jun 12
After listening to Olivia's happy→sad album today, wanted to sift through more songs this way: here's an explorer for every Olivia/Taylor song across a bunch of attributes csinva.io/quick-viz/taylor.h…
1
5
168
Chandan Singh retweeted

Apr 14
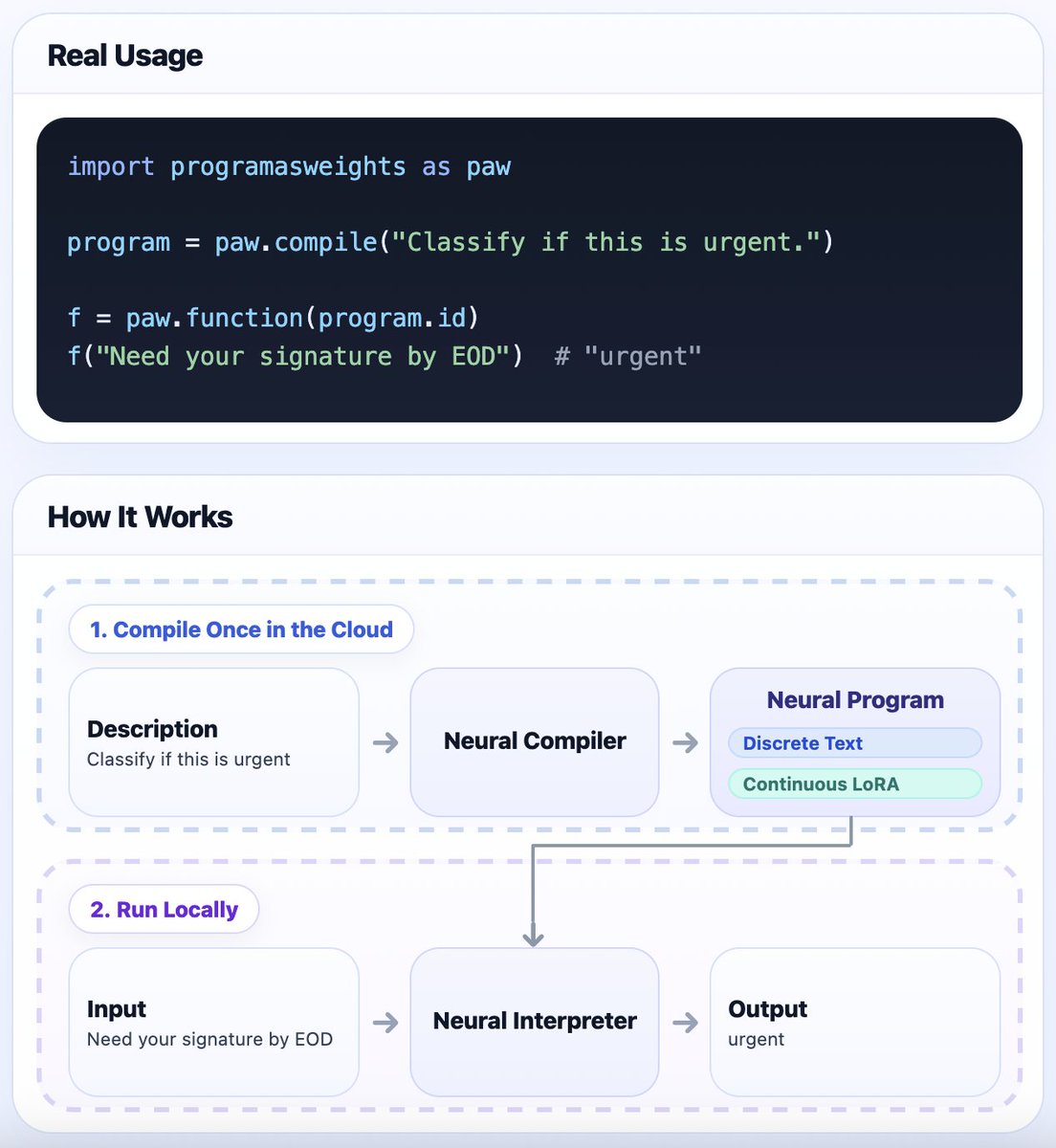
🚀 Launching ProgramAsWeights (PAW)!
Define functions in English → PAW compiles them into tiny neural programs → Run locally like normal Python functions.
A neural program combines discrete text continuous LoRA to adapt a fixed small interpreter.
🔗 programasweights.com
11
77
366
42,761
May 7
2 emerging interpretability trends I'm excited about from this paper: (1) agent-facing interp & (2) interp objectives for autoresearch 🧵
NEW paper from Microsoft Research.
(bookmark it)
The entire interpretability literature is built around human readers. As more analysis gets delegated to agents, the right target of interpretability shifts. This paper is a recipe for designing tools that agents can actually reason about.
They introduce Agentic-imodels, an autoresearch loop where a coding agent (Claude Code, Codex) iteratively evolves scikit-learn-compatible regressors that are simultaneously accurate AND readable by other LLMs.
Interpretability is measured by whether a small LLM can simulate the fitted model's behavior just by reading its string representation. Predictions, feature effects, counterfactuals, all from the __str__ output alone.
Run on 65 tabular datasets, the discovered models push the Pareto frontier past every classical interpretable baseline (decision trees, GAMs, sparse linear), and improve four downstream agentic data science systems on the BLADE benchmark by 8% to 73%.
Paper: arxiv.org/abs/2605.03808
Learn to build effective AI agents in our academy: academy.dair.ai/
1
13
69
8,300
May 7
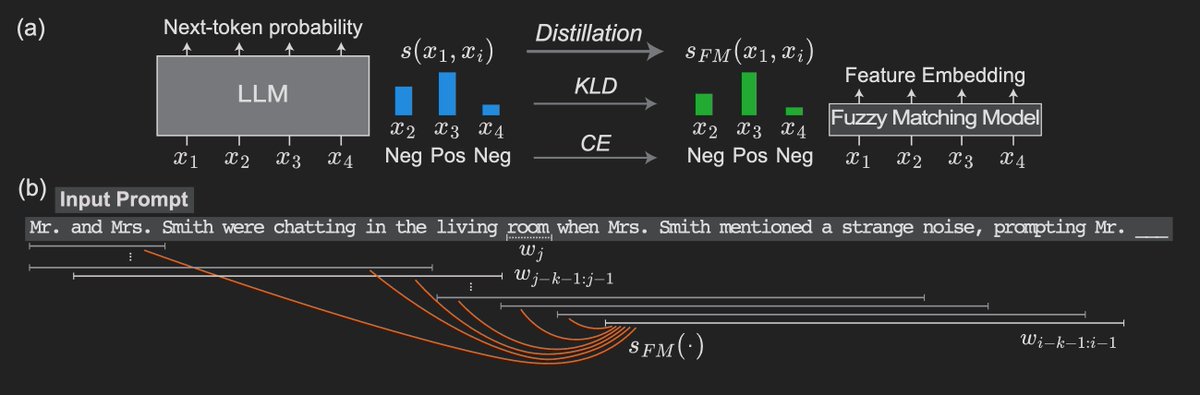
Interp autoresearch shifts the bottleneck from developing methods ➡️ developing useful interp objectives
Our Agent interp score (that measures LLM-simulatability of a model) lets agents ruthlessly identify new pareto-optimal tabular models
1
4
276
May 7
Paper: arxiv.org/abs/2605.03808
Wonderful collaborators: Yan Shuo Tan, @weijiavxu, Zelalem Gero, Weiwei Yang, Michel Galley, @JianfengGao0217 @MSFTResearch
1
2
200

NEW paper from Microsoft Research.
(bookmark it)
The entire interpretability literature is built around human readers. As more analysis gets delegated to agents, the right target of interpretability shifts. This paper is a recipe for designing tools that agents can actually reason about.
They introduce Agentic-imodels, an autoresearch loop where a coding agent (Claude Code, Codex) iteratively evolves scikit-learn-compatible regressors that are simultaneously accurate AND readable by other LLMs.
Interpretability is measured by whether a small LLM can simulate the fitted model's behavior just by reading its string representation. Predictions, feature effects, counterfactuals, all from the __str__ output alone.
Run on 65 tabular datasets, the discovered models push the Pareto frontier past every classical interpretable baseline (decision trees, GAMs, sparse linear), and improve four downstream agentic data science systems on the BLADE benchmark by 8% to 73%.
Paper: arxiv.org/abs/2605.03808
Learn to build effective AI agents in our academy: academy.dair.ai/
10
53
260
26,019
May 5
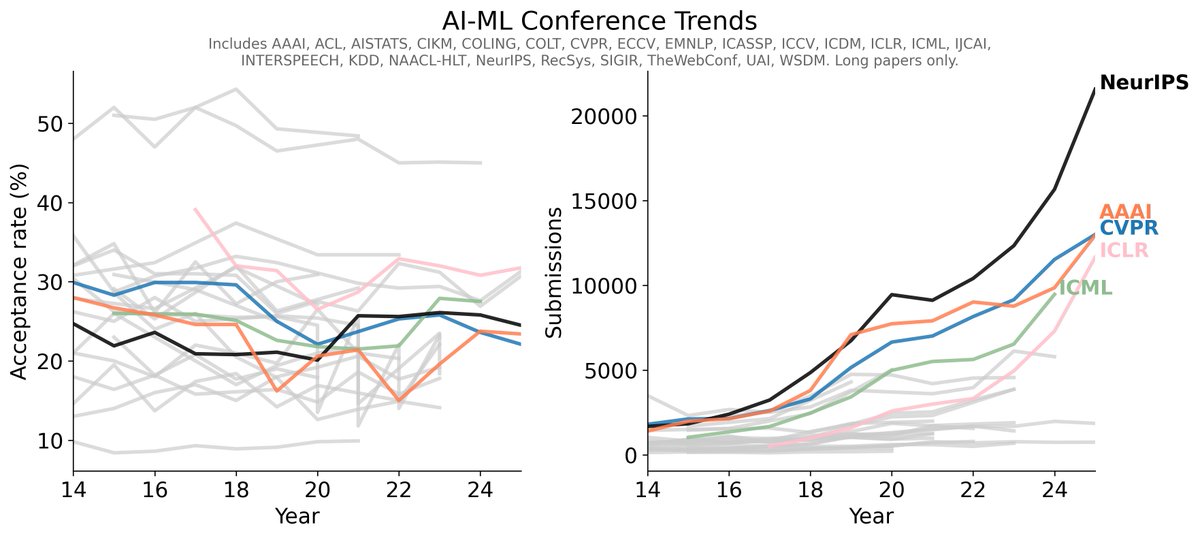
As ML conferences explode, one mitigation I'd like to see seriously considered is a cap on each author's yearly submissions (e.g. 3 total across NeurIPS, ICML, ICLR). Spamming low-quality submissions should have a real cost
3
2
218
16,971
Chandan Singh retweeted

Apr 30
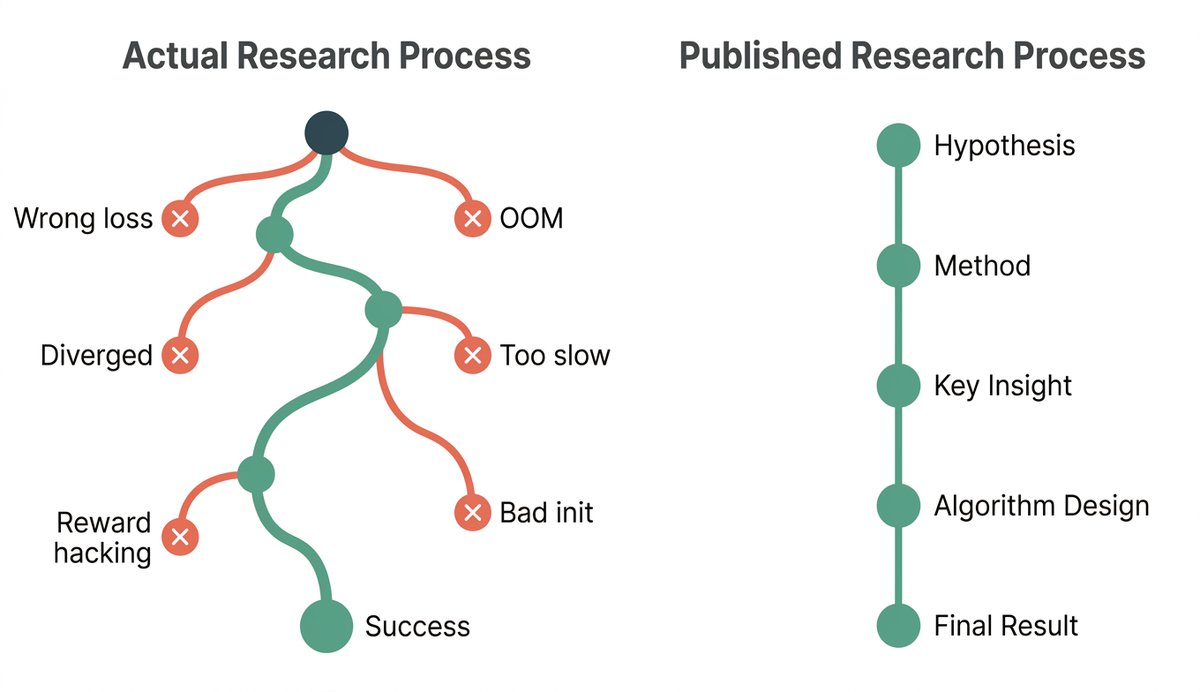
1/ For nearly 350 years, science has communicated itself through one object: the paper. A linear narrative, frozen as a PDF, written for a human reader. We've come to treat that format as the medium of science itself.
It doesn't have to be. It's a historical artifact. 🧵
28
136
1,067
141,359
Chandan Singh retweeted

Apr 24
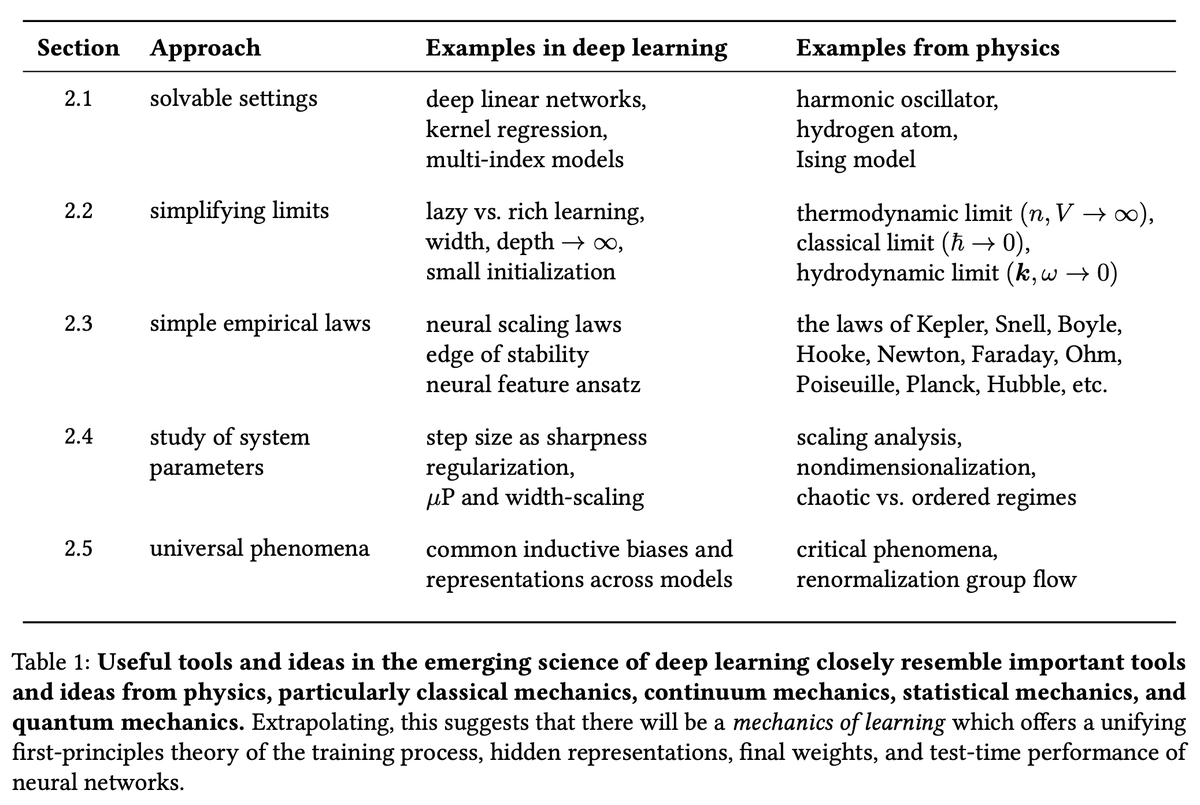
1/ Deep learning is going to have a scientific theory. We can see the pieces starting to come together, and it's looking a lot like physics!
We're releasing a paper pulling together these emerging threads and giving them a name: learning mechanics.
🔨 arxiv.org/pdf/2604.21691 🔧
54
292
1,511
304,708
Chandan Singh retweeted

Apr 22
Check out our autointerp paper ✨Semantic Regexes ✨at ICLR on Friday April 24!
@MIT_CSAIL and @Apple with @donghaoren, @tafsiri, @domoritz, @arvindsatya1 & @fredhohman
📅 iclr.cc/virtual/2026/poster/…
📄 arxiv.org/abs/2510.06378
🖥️ github.com/apple/ml-semantic…
🔗 machinelearning.apple.com/re…
3
11
39
3,553

Imagine every pixel on your screen, streamed live directly from a model. No HTML, no layout engine, no code. Just exactly what you want to see.
@eddiejiao_obj, @drewocarr and I built a prototype to see how this could actually work, and set out to make it real. We're calling it Flipbook. (1/5)
1,142
3,733
28,826
5,956,367
Chandan Singh retweeted

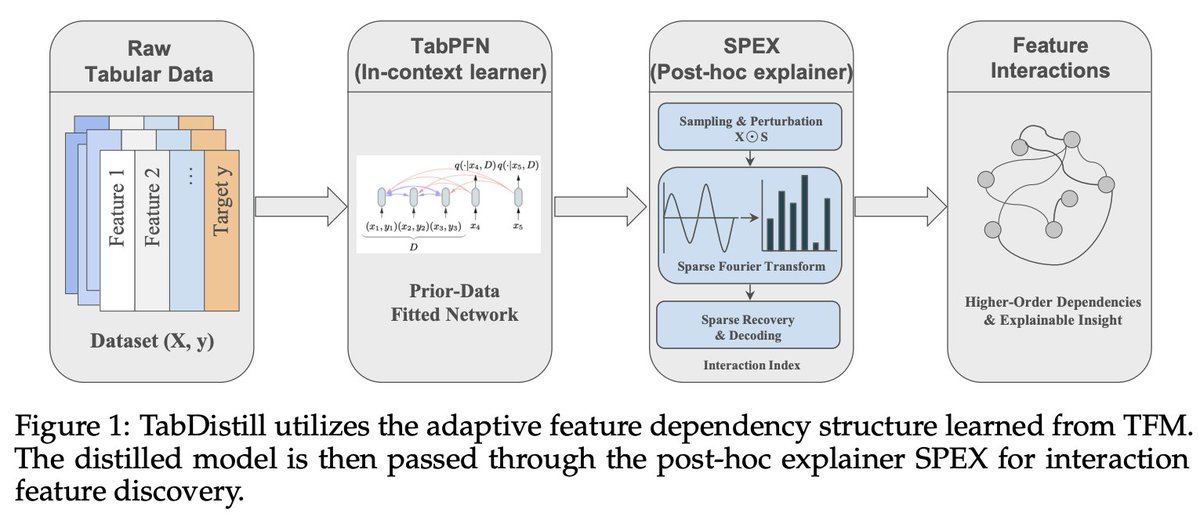
🎉 New on Arxiv:
A fundamental challenge of statistical learning is discovering which features interact with one another to influence outcomes. Looking for pairwise intx. requires O(n^2) calculations, three-way intx. requires O(n^3), etc.
Can we skip this statistical challenge by tapping into the rich prior learned in foundation models?
Our approach TabDistill shows that we can.
Read more:
arxiv.org/pdf/2604.13332
3
6
557

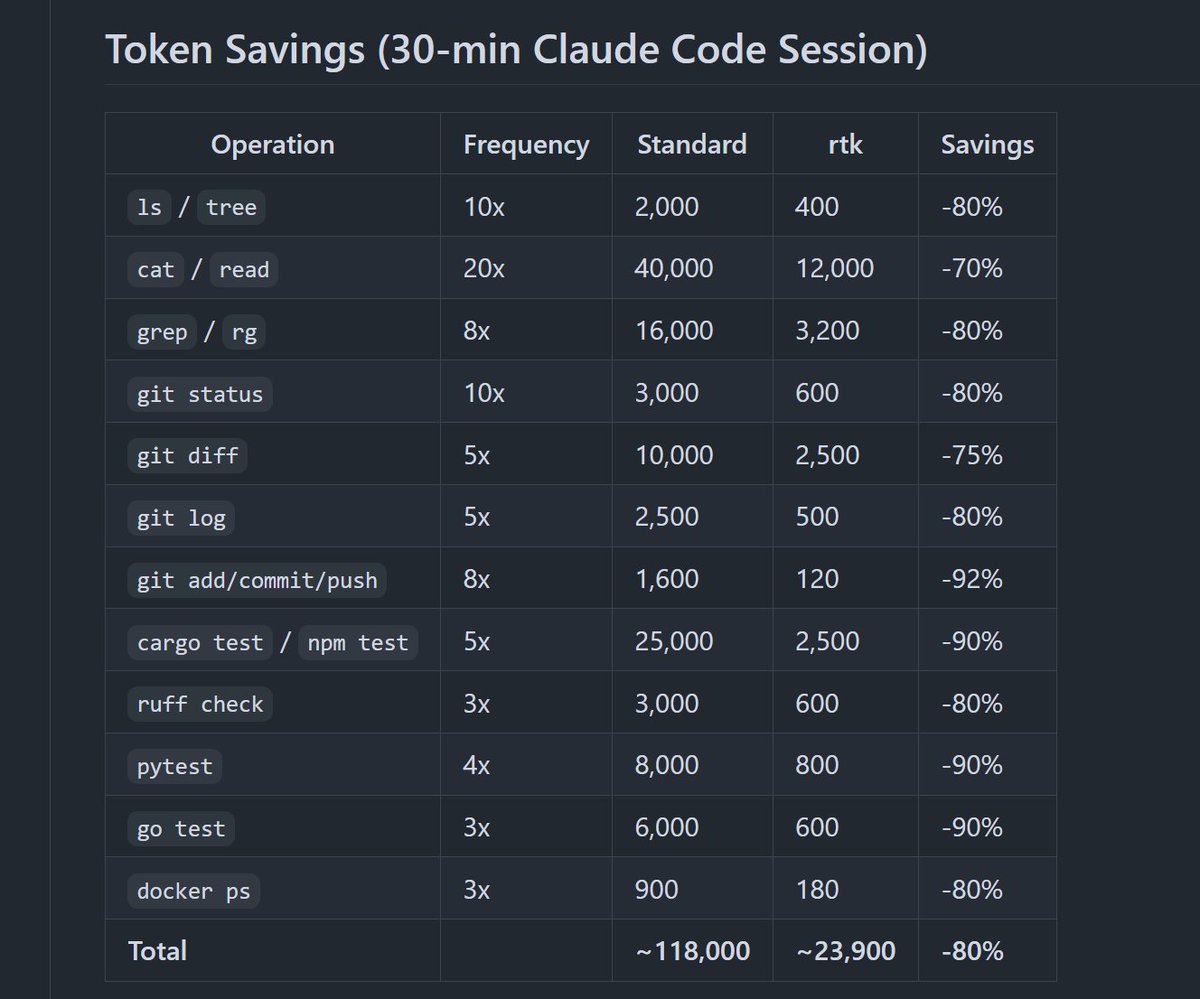
10 GitHub repos to spend 60-90% less tokens in Claude Code:
1. RTK (Rust Token Killer)
CLI proxy that filters terminal output before it hits your context
- 60-90% reduction on common dev commands
- one binary, zero dependencies
- works with Claude Code, Cursor, Copilot
Repo: github.com/rtk-ai/rtk
2. Context Mode
Sandboxes raw tool output into SQLite instead of dumping it into context
- 98% context reduction on Playwright, GitHub, logs
- only clean summaries enter your conversation
- works as Claude Code plugin
Repo: github.com/mksglu/context-mo…
3. code-review-graph
Local knowledge graph that maps your codebase with Tree-sitter
- Claude reads only what matters, not the entire repo
- 49x token reduction on large monorepos
- 6.8x on average reviews
Repo: github.com/tirth8205/code-re…
4. Token Savior
MCP server that navigates code by symbols, not full files
- 97% reduction on code navigation
- persistent memory across sessions
- 69 tools, zero external deps
Repo: github.com/Mibayy/token-savi…
5. Caveman Claude
makes Claude talk like a caveman to cut output tokens
- 65-75% output reduction
- one-line install
- keeps full technical accuracy
Repo: github.com/JuliusBrussee/cav…
6. claude-token-efficient
one CLAUDE.md file that keeps responses terse
- drop-in, no code changes
- reduces output verbosity on heavy workflows
- best for output-heavy sessions
Repo: github.com/drona23/claude-to…
7. token-optimizer-mcp
MCP server with caching, compression, and smart tool intelligence
- 95% token reduction through intelligent caching
- compresses repeated tool outputs
Repo: github.com/ooples/token-opti…
8. claude-token-optimizer
reusable setup prompts for optimizing any project
- 90% token savings in 5 minutes
- reduces doc token usage from 11K to 1.3K
Repo: github.com/nadimtuhin/claude…
9. token-optimizer
finds ghost tokens that silently eat your context
- survives compaction without losing quality
- fixes context quality decay
Repo: github.com/alexgreensh/token…
10. claude-context (by Zilliz)
code search MCP that makes your entire codebase the context
- ~40% reduction with equivalent retrieval quality
- hybrid BM25 dense vector search
Repo: github.com/zilliztech/claude…
[ how to stack them ]:
you don't need all 10. pick 2-3 based on your workflow:
> heavy terminal output? RTK
> big codebase? code-review-graph Token Savior
> lots of MCP servers? Context Mode
> quick fix? Caveman claude-token-efficient
most people are burning tokens without knowing it
run /context in a fresh session and see how much is gone before you even type a word
your pocket will thank me later :<)
104
338
2,920
462,991
Apr 14
Here's a short skill that's helped me get clearer technical reports (especially visualizations) from agents:
github.com/csinva/csinva.git…
3
16
918
Mar 23
PSA for american citizens going to ICLR: you need to get an evisa for Rio (takes up to 10 business days)
1
1
3
484
Chandan Singh retweeted

Mar 17
Interpretability methods usually study single-token behavior.
But real model behaviors, like sycophancy or writing style, are diffuse across many tokens.
Can these diffuse behaviors be localized and controlled from long-form responses? YES!
3
20
104
10,528
Chandan Singh retweeted

Can we rewrite Transformers as a human-readable code?
In this paper, we decompile Transformers trained on algorithmic and formal language tasks into D-RASP – a programming language that mirrors Transformer architecture. 🧵

2
39
237
28,155
Chandan Singh retweeted

Feb 24
so apparently you can just ask models to write weights now.

Feb 24

Beat it by having Codex hand-craft weights:
gist.github.com/N8python/02e…
100% accuracy on 10 million random test cases w/ only 343 parameters. As a bonus, it uses the vanilla Qwen3 architecture, just with the right weights.
31
60
1,452
148,892
Feb 24
Realizing that my brain now associates seeing a typo in a paragraph as a positve signal for quality
12
511