
Charles retweeted

12 Apr 2024
🚀Excited to be recognized for a second year by @FortuneMagazine in their Top 50 AI Startups list!
We have come so far in the past year and a huge thank you to the now over 60,000 developers building on the Together API. Thank you!


2
7
20
8,534
Charles retweeted
31 Oct 2023
Great comparison of options for Llama-2 inference, concluding by saying, "Overall, we found Together did best overall across cost, throughput and accuracy followed closely by MosaicML."
This is only going to get better. Stay tuned.
arjunbansal.substack.com/p/w…

10
17
2,184
Charles retweeted

23 Oct 2023
Excited about models that are sub-quadratic in sequence length and model dimension? Our Monarch Mixer paper is now on arXiv -- and super excited to present it as an oral at #NeurIPS2023!
Let's dive in to what's new with the paper and the new goodies from this release:
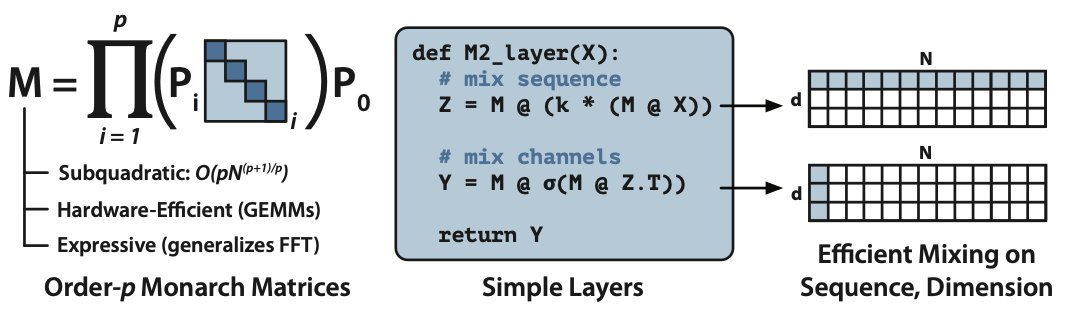
Monarch matrices are an expressive and hardware-efficient set of matrices that generalize the FFT -- and can be used to represent all sorts of fun linear transforms, from Hadamard transforms to Toeplitz matrices and more.
Monarch mixer (M2) uses Monarch matrices to mix information both along the sequence (replacing attention) and along the model dimension.
M2 replaces attention in Transformers with gated convolutions, and replace the linear layers in MLPs with sparse block-diagonal matrices. The result are architectures that scale sub-quadratically in both sequence length and model dimension!
Back in July, we released a short blog post (hazyresearch.stanford.edu/bl…) with @togethercompute about using Monarch matrices to train some more efficient BERT models -- matching BERT-base in quality with 27% fewer parameters, and with long-context inference throughput.
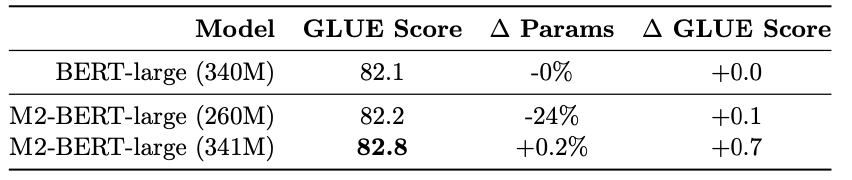
With this release, we're excited to announce two new M2-BERT-large models -- the 260M version matches BERT-large in downstream GLUE score with 24% fewer parameters (and also has much faster long-context throughput).
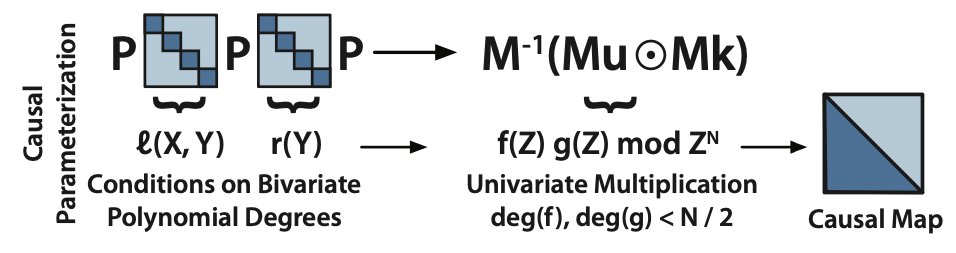
Our paper also has a whole set of theoretical goodness that we didn't get to in our blog post. For causal language modeling -- e.g. GPT-style or decoder-only language modeling -- we need to parameterize the Monarch matrices to make sure that the sequence mixing is causal. This ensures that you can train with next token prediction, GPT-style.
We use a mix of polynomial theory to interpret Monarch matrices as bivariate polynomial evaluation, and then causality is just a matter of keeping the degrees in check. (If you're familiar with the FFT convolution theorem, this is equivalent to the padding trick to turn the circular convolution into a causal convolution).
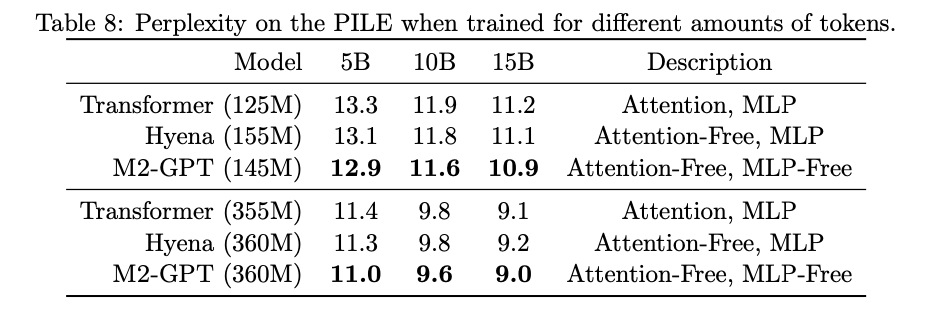
Using this theory, we can train M2-GPT models -- fully sub-quadratic in the sequence length. In a weird twist, we found that we can get rid of the MLP layers entirely, and still match GPT performance... wild!
Check out our paper, code, and blog post for more details:
Paper: arxiv.org/abs/2310.12109
Code: github.com/HazyResearch/m2
Blog: hazyresearch.stanford.edu/bl…
With @simran_s_arora, @Jessica_Grogan_, Isys Johnson, @EyubogluSabri, @ai_with_brains, @bfspector, @MichaelPoli6, Atri Rudra, and @HazyResearch
Building on a lot of great work from great folks, including @tri_dao @_albertgu @davidwromero @srush_nlp @BeidiChen @exnx @BlinkDL_AI @MaxMa1987 @ramin_m_h and many many more!
And of course, couldn't have done this work without support from @StanfordHAI @StanfordAILab @StanfordCRFM. In collaboration with @togethercompute.
Check out our paper for more, and please reach out if you have ideas about usage or questions! arxiv.org/abs/2310.12109
And look forward to more soon ;)
5
59
277
81,032
Charles retweeted

19 May 2023
Today we are excited to introduce and open-source BLOOMChat a multilingual chat LLM. Built on top of the BLOOM model (@BigscienceW), we further train the model on conversational data from @togethercompute @databricks @laion_ai @huggingface. Some interesting observations: (1/6)

4
77
288
112,028
Charles retweeted
5 May 2023
The first RedPajama models are here! The 3B and 7B models are now available under Apache 2.0 license, including instruction-tuned and chat versions!
This project demonstrates the power of the open-source AI community with many contributors ... 🧵 together.xyz/blog/redpajama-…

16
212
836
517,939
Charles retweeted
30 Apr 2023
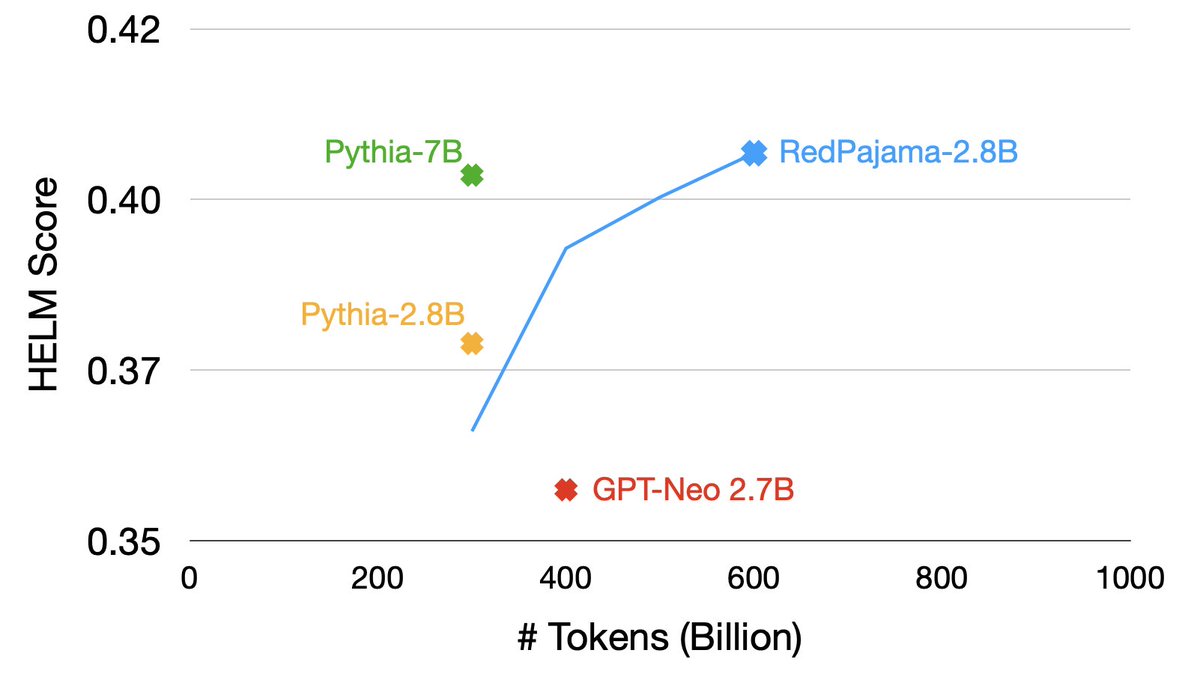
In addition to RedPajama 7B, we’ve also been training a 2.8B model. After 600B tokens it is exciting to see the model has higher HELM scores than the excellent Pythia-2.8B & GPT-Neo 2.7B.
In fact, trained with twice the tokens, RedPajama-2.8B has comparable quality to Pythia-7B!
12
76
501
336,378
Charles retweeted
24 Apr 2023
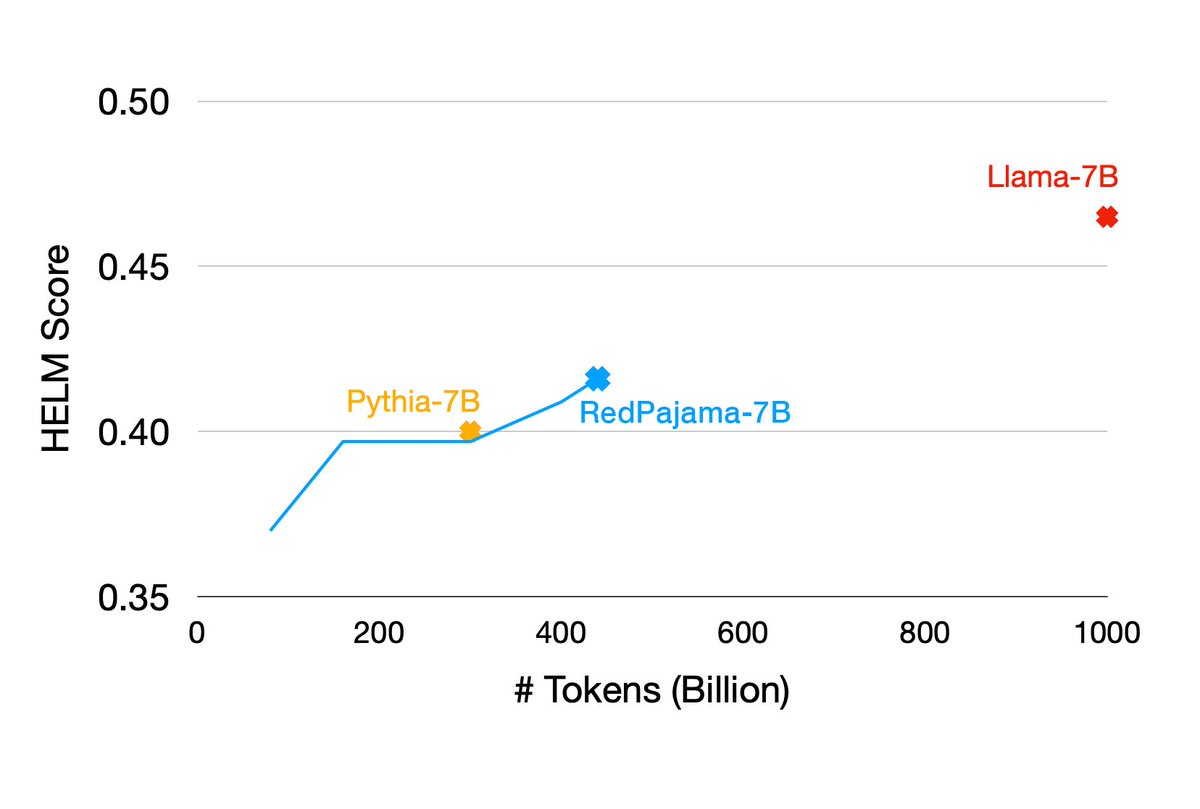
Training our first RedPajama 7B model is going well! Less than half way through training (after 440 billion tokens) the model achieves better results on HELM benchmarks than the well-regarded Pythia-7B trained on the Pile.
Details at together.xyz/blog/redpajama-…
16
88
481
146,691

Facebook is going to put my profile photos and stories in ads and I won't be paid a cent? Brilliant. adage.com/digital/article?ar…
1
Put a pair of iPhone earbuds through the washer today. Seem to still work. #closecall
1
After discussing the Taylor Swift iPhone app @david_goodwin has concluded I need a Charles Srisuwananukorn app.
Got a cool case mod you want to show off? Check out the @exploratorium's rods and mods http://bit.ly/aMK4uq