
stanford cs phd student. i make ml go brr.
Joined October 2020
- Tweets 157
- Following 301
- Followers 10,713
- Likes 7,743
24 Photos and videos







May 27
All reliable clusters are alike; each unreliable cluster is unreliable in its own way.
30
1,719

Benjamin F Spector retweeted

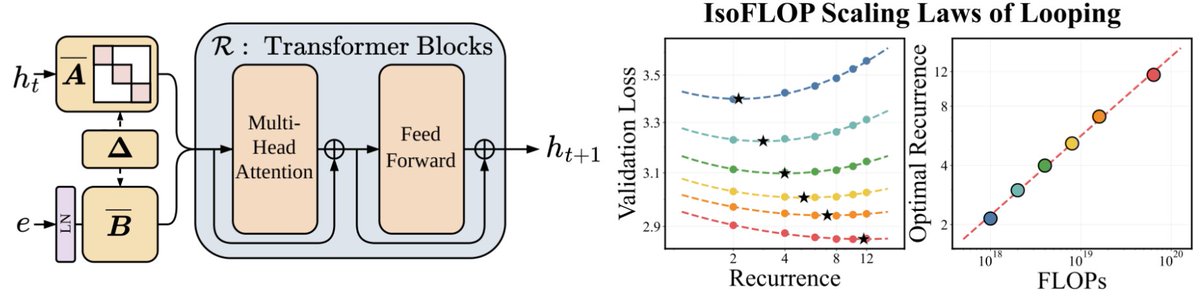
We’ve been thinking a lot about scaling laws, wondering if there is a more effective way to scale FLOPs without increasing parameters.
Turns out the answer is YES – by looping blocks of layers during training. We find that predictable scaling laws exist for layer looping, allowing us to use looping to achieve the quality of a Transformer twice the size.
Our scaling laws suggest that for a fixed parameter budget, data and looping should be increased in tandem!
🧵👇
41
179
1,278
294,819
Jan 28
Very grateful and excited to be working together every week!

The best part of my job is the privilege to partner with extraordinary founders. It’s especially rewarding when those founders are people you’ve long admired and respected.
I’ve known @amspector100 since our college days, and I’ve gotten to know his brother, @bfspector, through the Prod community, where Ben helped shape a generation of founders and young talent.
So when Asher mentioned to me on a walk that he and Ben were thinking about starting something together, I could barely contain my excitement. It felt like a moment that had been building for an eternity.
Today, that conviction has taken shape as Flapping Airplanes, a new foundational AI research lab led by Ben, Asher, and @aidanmantine, exploring radically more data-efficient approaches to learning.
We’re thrilled to co-lead this investment alongside @GVteam and @sequoia, and to partner with my dear friends Ben, Asher, Aidan and the rest of their all-star team.
3
3
72
41,648
Jan 28
agreed

2
66
38,437
Benjamin F Spector retweeted

Jan 28
The new guard in AI has emerged: next generation of top tier AI founders just started a new kind of frontier lab. Good luck!
Announcing Flapping Airplanes!
We’ve raised $180M from GV, Sequoia, and Index to assemble a new guard in AI: one that imagines a world where models can think at human level without ingesting half the internet.
4
7
84
26,699
Jan 28
Very proud of the team we've assembled! Back to work!
Announcing Flapping Airplanes!
We’ve raised $180M from GV, Sequoia, and Index to assemble a new guard in AI: one that imagines a world where models can think at human level without ingesting half the internet.
22
15
259
46,264
Benjamin F Spector retweeted

2 Dec 2025
Introducing Ricursive Intelligence, a frontier AI lab enabling a recursive self-improvement loop between AI and the chips that fuel it.
Learn more at ricursive.com
50
151
1,102
494,407
Benjamin F Spector retweeted

2 Dec 2025
Thrilled to share that @annadgoldie and I are launching @RicursiveAI, a frontier lab enabling recursive self-improvement through AIs that design their own chips.
Our vision for transforming chip design began with AlphaChip, an AI for layout optimization used to design four generations of TPUs, data center CPUs, and smartphones. AlphaChip offered a glimpse into a future where AI designs the silicon that fuels it. Ricursive extends this vision to the entire chip stack, building AI that architects, verifies, and implements silicon, enabling models and chips to co-evolve in a tight loop.
We sat down with WSJ’s @berber_jin1 to discuss Ricursive: wsj.com/tech/this-ai-startup…
2 Dec 2025

Introducing Ricursive Intelligence, a frontier AI lab enabling a recursive self-improvement loop between AI and the chips that fuel it.
Learn more at ricursive.com
124
135
1,512
234,910
Benjamin F Spector retweeted

1 Dec 2025
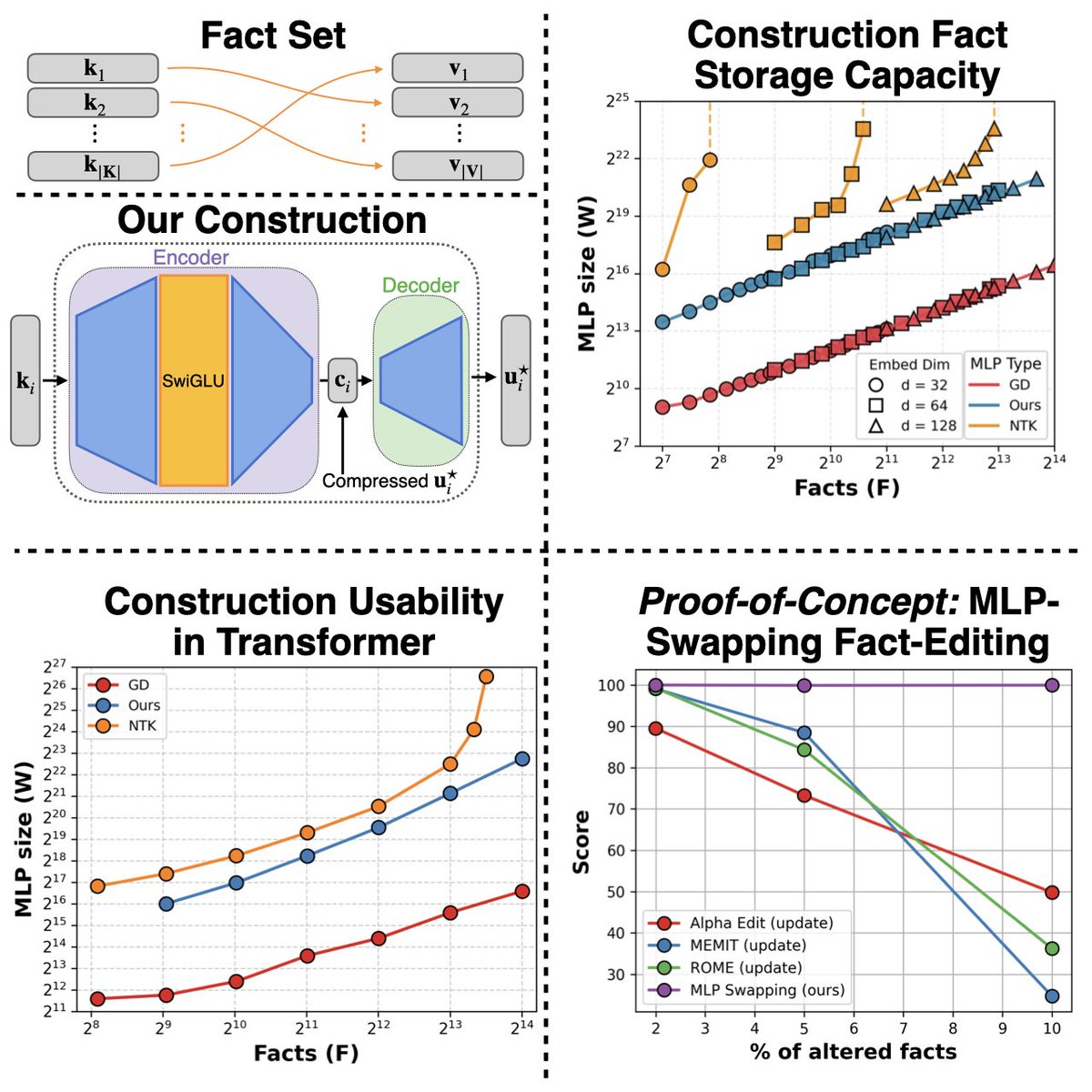
Part 2 of our MLPs blog post is out! 👀
This time, we’re here to tell you the story 📖 of our quest for a construction that:
✅ Handles general embeddings 🌐
✅ Asymptotically matches the information-theoretic limit 📊📈
✅ Is usable within transformers 🤖✨

28 Nov 2025

Happy 🦃 Thanksgiving weekend! 🍂 This year, we cooked up a new recipe for juicy fact-storing MLPs. Instead of picking apart trained models, we asked: Can we construct fact-storing MLPs from scratch? 🤔
Spoiler: we can & we figured out how to slot these hand-crafted MLPs into Transformer blocks as modular fact stores! 🧩
New work with @garctrob @ronnygjunkins @jerrywliu @dylan_zinsley @EyubogluSabri Atri Rudra @HazyResearch!
🧵👇
1
11
31
8,921
Benjamin F Spector retweeted

28 Nov 2025
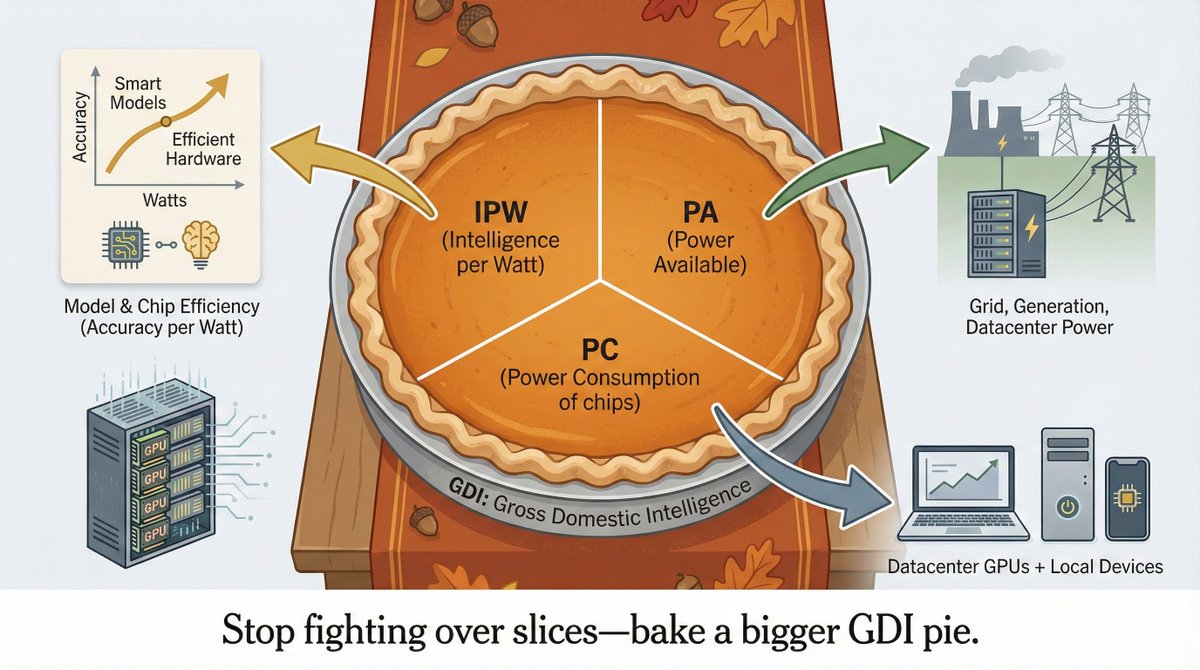
The U.S.–China AI race won’t be decided by who builds the most datacenters, but by who deploys the most intelligence.
We call this Gross Domestic Intelligence (GDI): intelligence per watt × usable power.
If the U.S. activates its dense installed base of local AI accelerators in a hybrid local–cloud system, it could add ~30–40% inference capacity and ≈2-4× GDI for single-turn chat and reasoning queries without building any new datacenters or grid infrastructure.
Winning the GDI race means treating local compute as critical infrastructure and making hybrid inference the default.
(1/N)
9
41
136
68,790
Benjamin F Spector retweeted
28 Nov 2025
Happy 🦃 Thanksgiving weekend! 🍂 This year, we cooked up a new recipe for juicy fact-storing MLPs. Instead of picking apart trained models, we asked: Can we construct fact-storing MLPs from scratch? 🤔
Spoiler: we can & we figured out how to slot these hand-crafted MLPs into Transformer blocks as modular fact stores! 🧩
New work with @garctrob @ronnygjunkins @jerrywliu @dylan_zinsley @EyubogluSabri Atri Rudra @HazyResearch!
🧵👇
8
47
337
64,863
Benjamin F Spector retweeted

17 Nov 2025
(1/6) GPU networking is the remaining AI efficiency bottleneck, and the underlying hardware is changing fast! We’re happy to release ParallelKittens, an update to ThunderKittens that lets you easily write fast computation-communication overlapped multi-GPU kernels, along with new kernels for data, tensor, sequence, and expert parallelism!
Here’s a photo of overlapped kittens, along with things you should care about when optimizing multi-GPU kernels.
(With @simran_s_arora, @bfspector, and @hazyresearch. Generously supported by @cursor_ai and @togethercompute)

9
59
512
156,002
Benjamin F Spector retweeted

12 Nov 2025
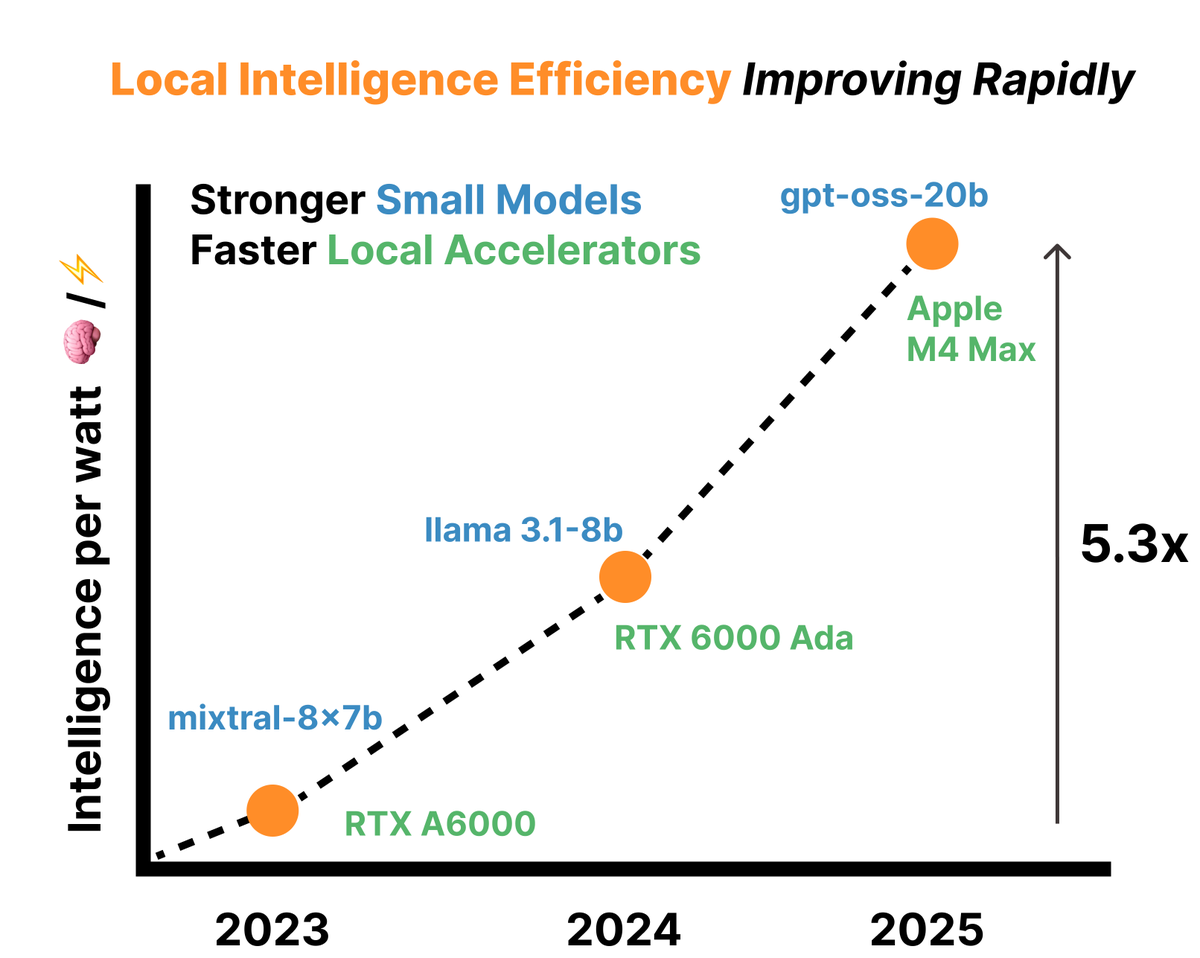
Data centers dominate AI, but they're hitting physical limits. What if the future of AI isn't just bigger data centers, but local intelligence in our hands?
The viability of local AI depends on intelligence efficiency. To measure this, we propose intelligence per watt (IPW): intelligence delivered (capabilities) per unit of power consumed (efficiency).
Today’s Local LMs already handle 88.7% of single-turn chat and reasoning queries, with local IPW improving 5.3× in 2 years—driven by better models (3.2×) and better accelerators (1.7×).
As local IPW improves, a meaningful fraction of workloads can shift from centralized infrastructure to local compute, with IPW serving as the critical metric for tracking this transition.
(1/N)
56
142
463
229,374
Benjamin F Spector retweeted

11 Nov 2025
AI has been built on one vendor’s stack for too long.
AMD’s GPUs now offer state-of-the-art peak compute and memory bandwidth — but the lack of mature software / the “CUDA moat” keeps that power locked away. Time to break it and ride into our multi-silicon future. 🌊
It's been a blast working with the amazing @_williamhu, @Drewwad and team; we present HipKittens!

13
95
581
223,664
Benjamin F Spector retweeted

11 Nov 2025
AI is compute-hungry. While it has generally relied on a single hardware vendor in the past, AMD GPUs now offer competitive memory and compute throughput. Yet, the software stack is brittle.
So we ask: can the same DSL principles that simplified NVIDIA kernel dev translate to AMD? We’re excited to introduce the newest addition to the ThunderKittens cinematic universe of kernel DSLs: HipKittens (HK) 🚀for Fast and Furious AMD kernels.

7
35
156
53,140
Benjamin F Spector retweeted

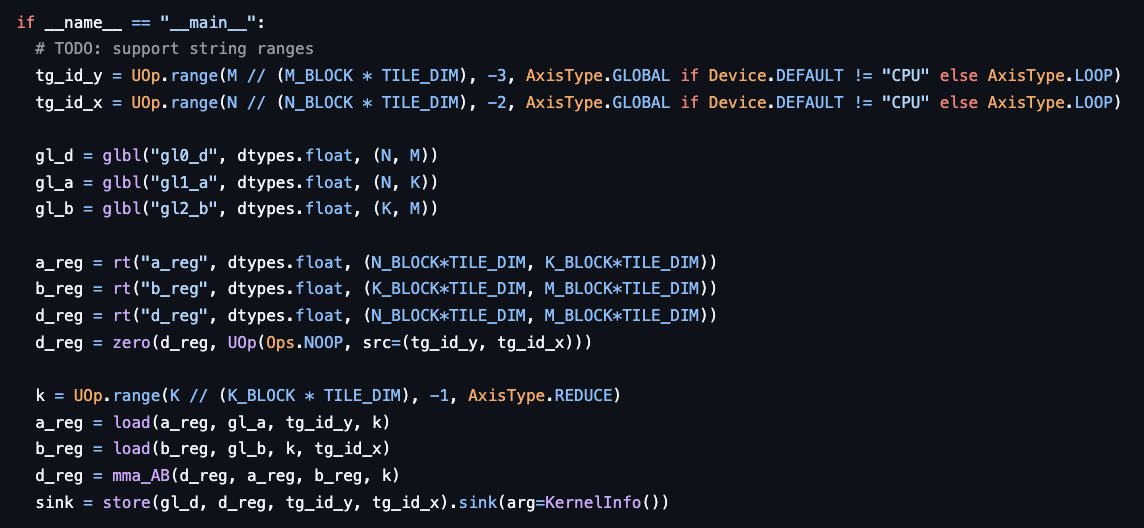
9 Oct 2025
Shout out to ThunderKittens for writing simple yet very performant GPU code. We're working on "tinykittens" which uses the same insight but in tinygrad's language.
The insight is that GPU "registers" are the wrong primitive and TK's "register tile" is a lot more sensible.
10
32
691
97,761
Benjamin F Spector retweeted

29 Sep 2025
@StanfordHAI just ran this story on self-study and cartridges -- it's a really nice overview for those curious about our work

1
19
47
10,349
28 Sep 2025
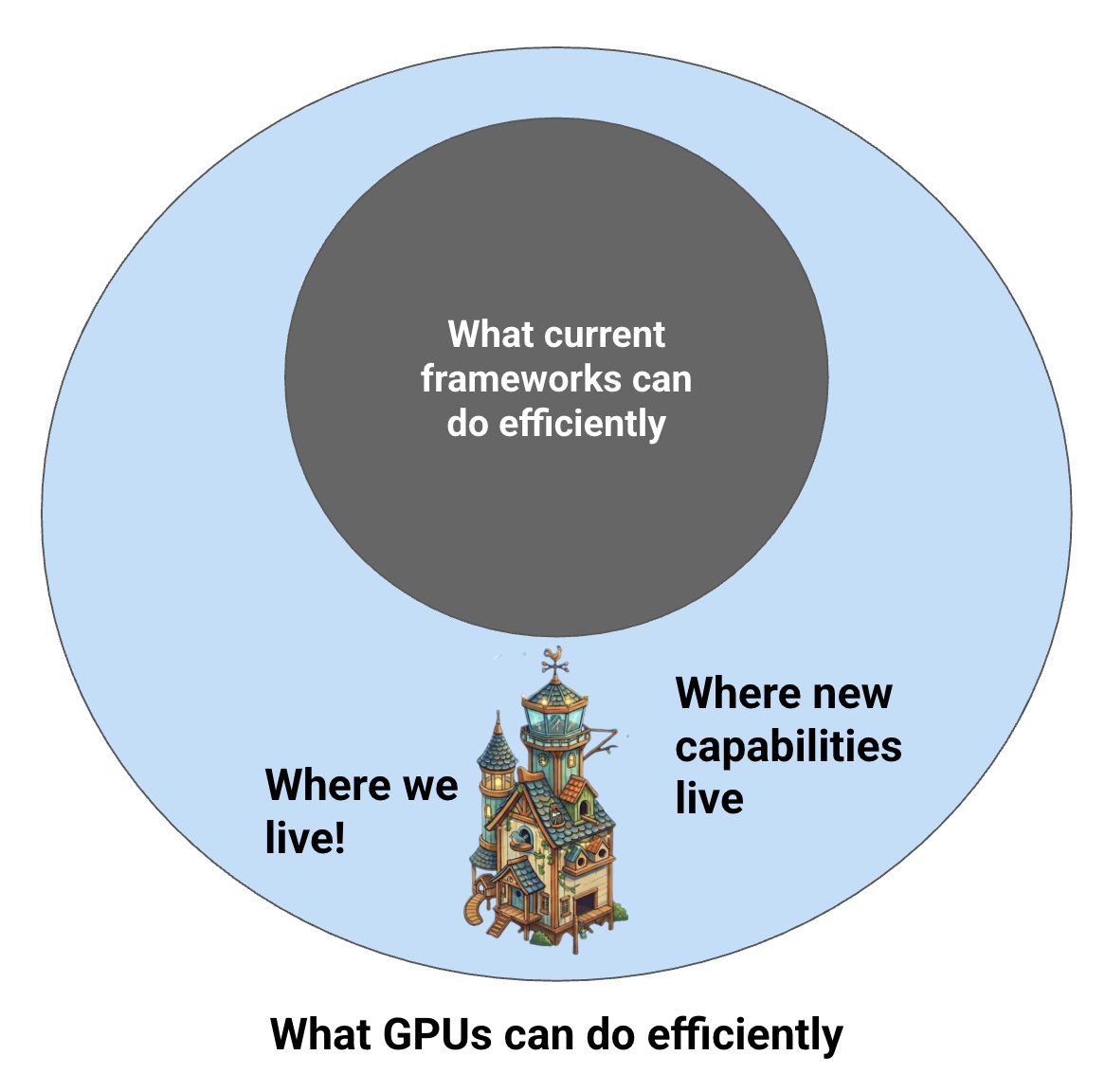
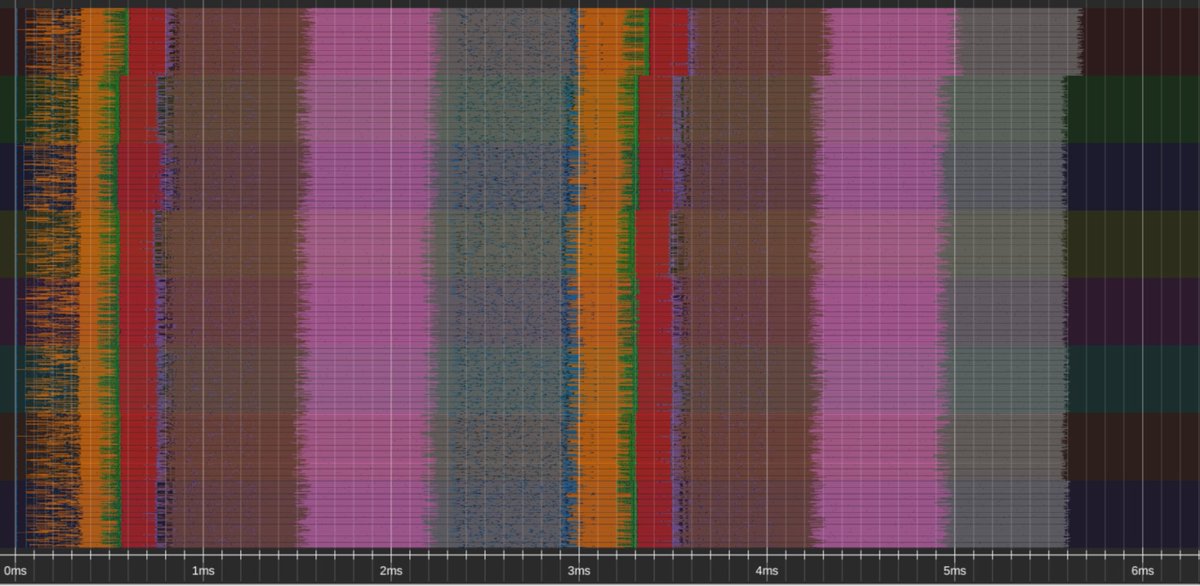
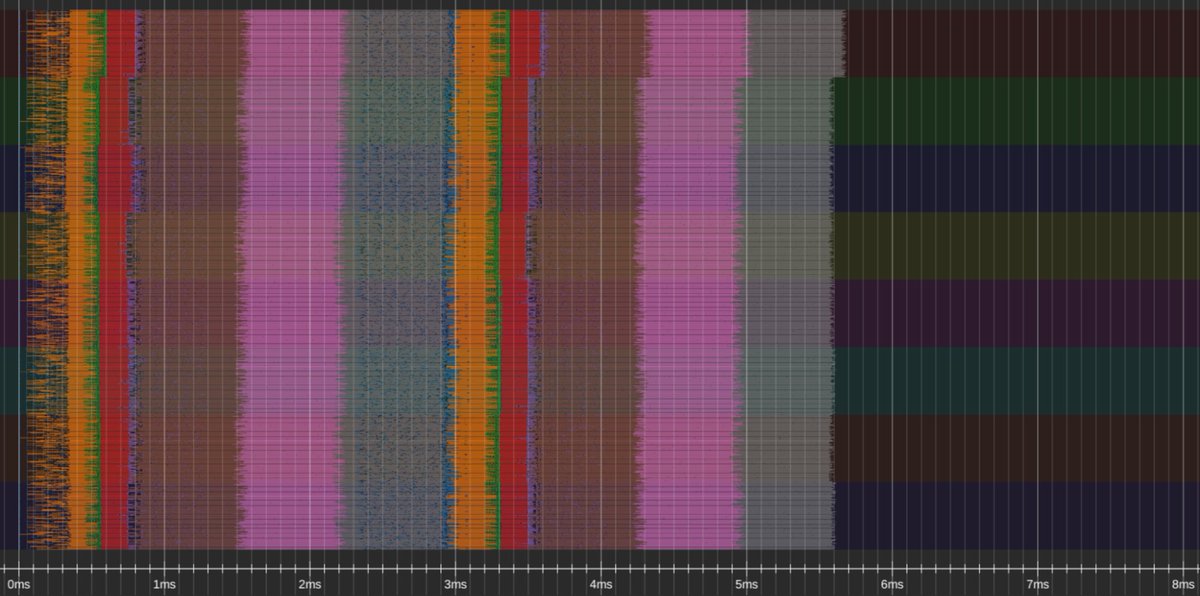
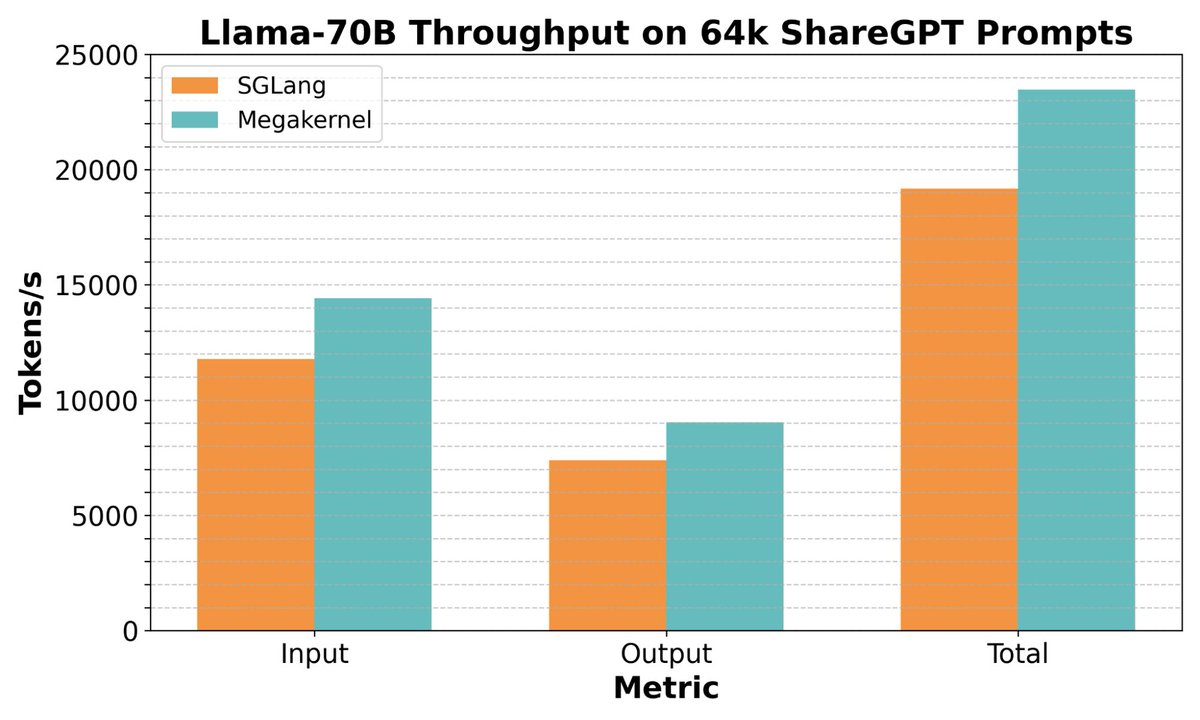
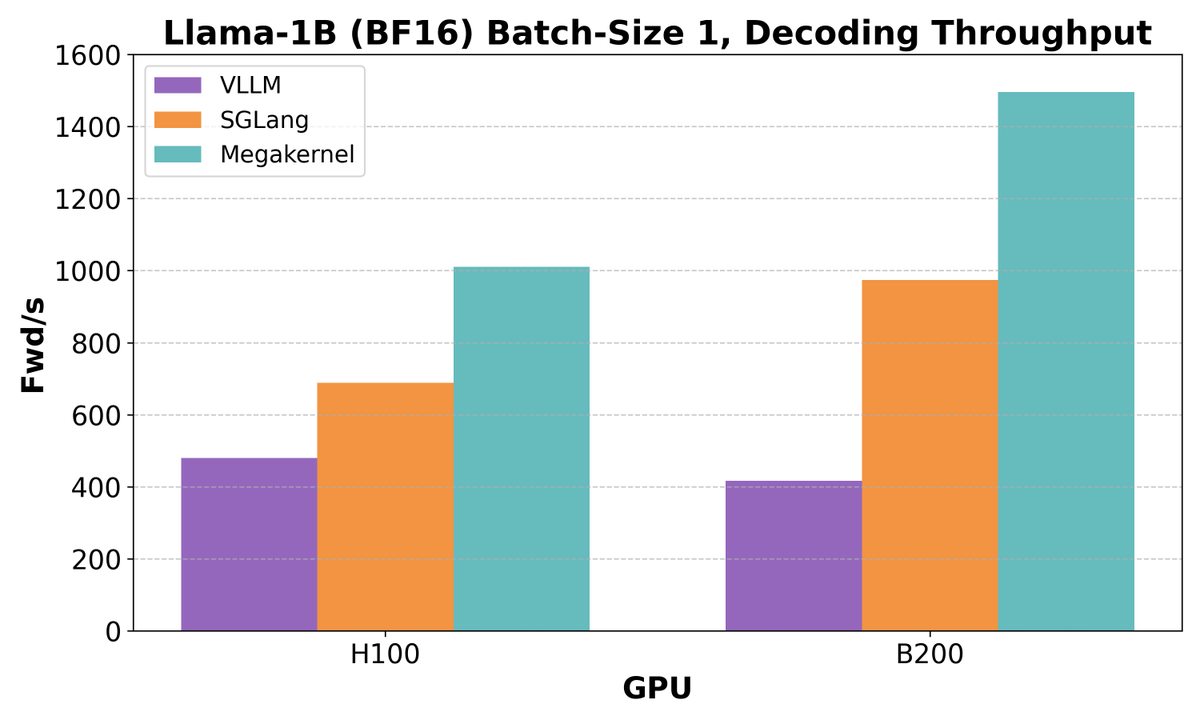
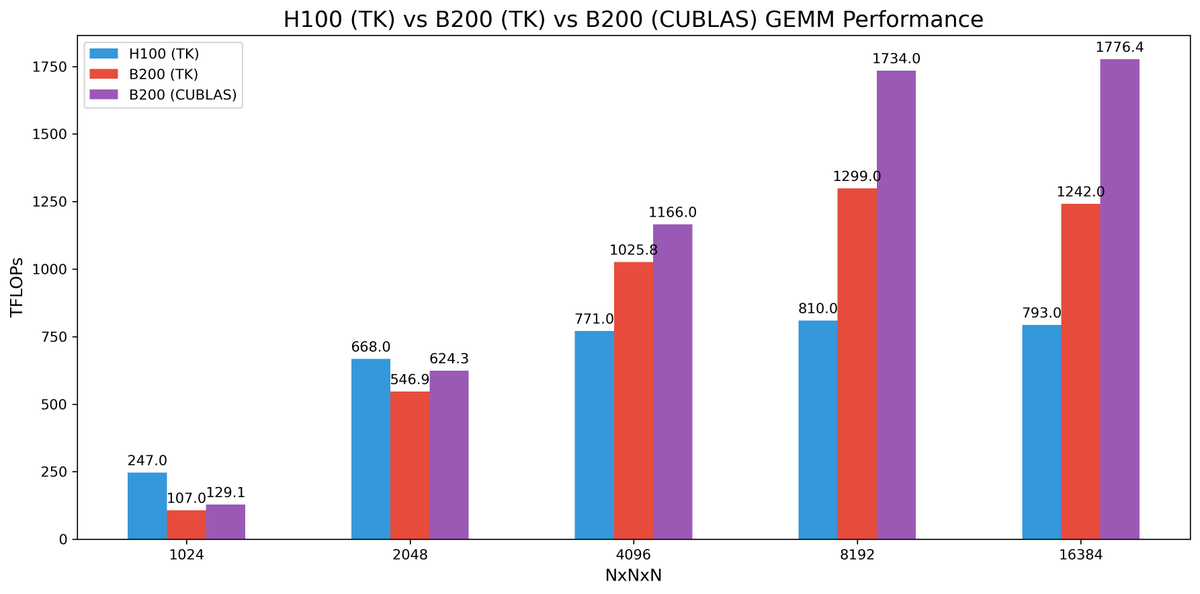
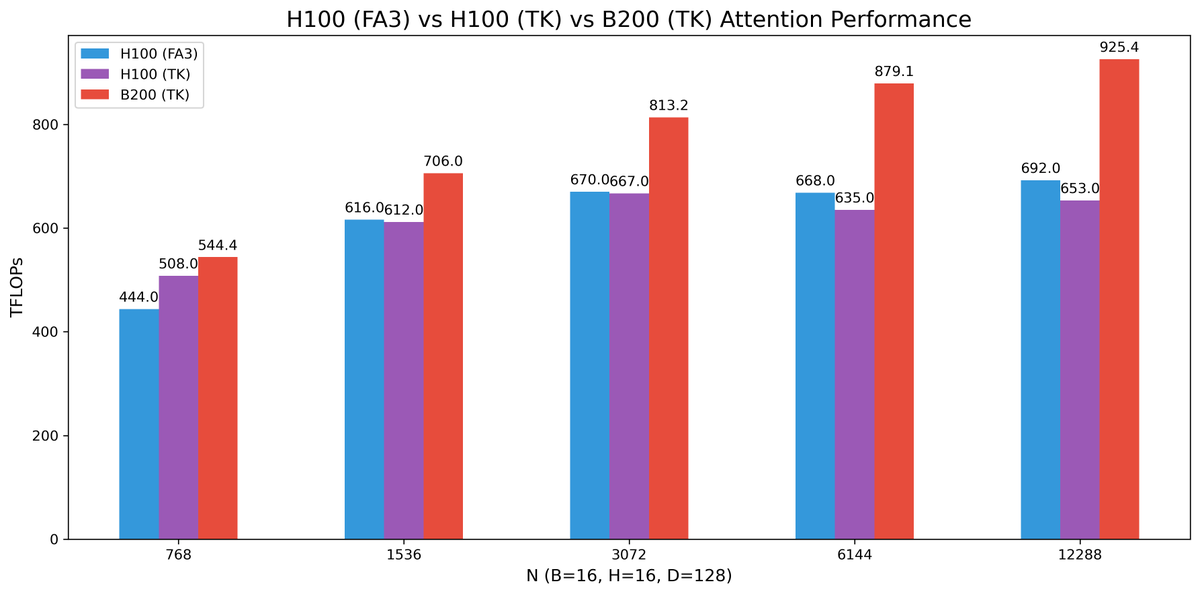
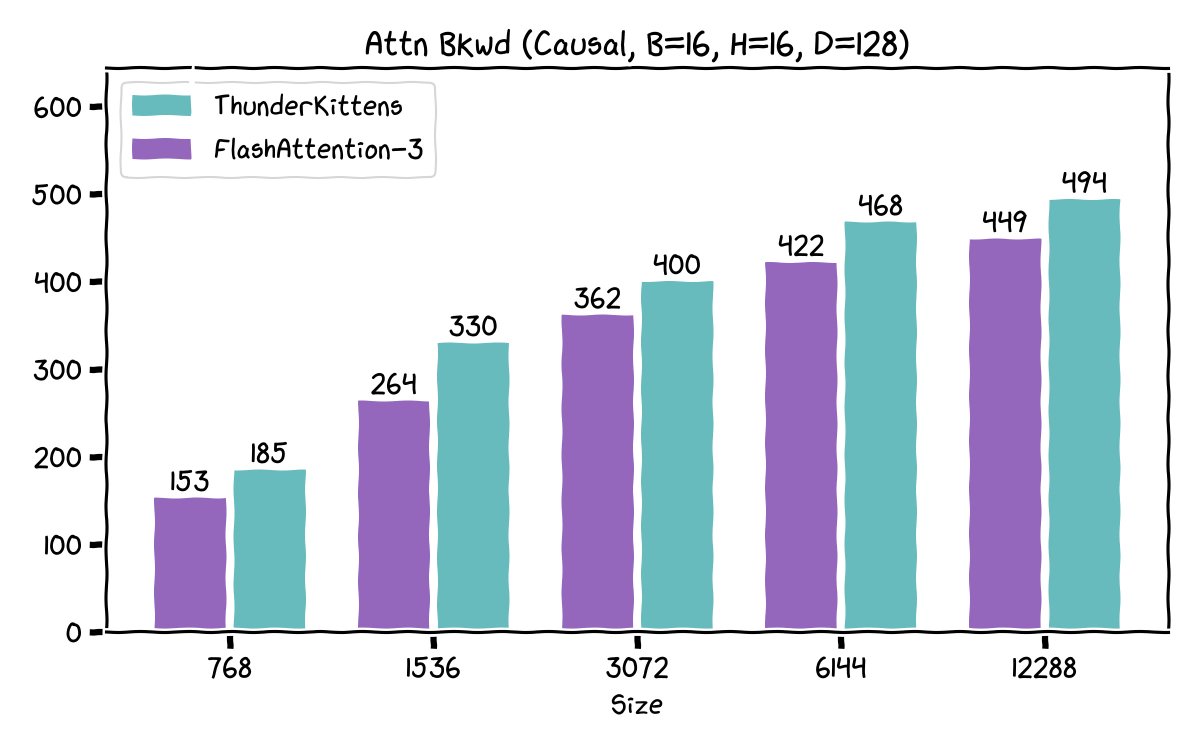
(1/8) We’re releasing an 8-GPU Llama-70B inference engine megakernel! Our megakernel supports arbitrary batch sizes, mixed prefill decode, a paged KV cache, instruction pipelining, dynamic scheduling, interleaved communication, and more! On ShareGPT it’s 22% faster than SGLang.
7
48
321
84,669
28 Sep 2025
(7/8) Code is at bit.ly/tplcode; it is (emphasis) research code. You can also play with our custom profiler at bit.ly/4mDJ0wG! We’ve written up both a brief, introductory post at bit.ly/tplintro and a longer, more technical one: bit.ly/tplmain
1
4
42
4,322
28 Sep 2025
(8/8) This is joint work with my amazing collaborators @jordanjuravsky, @stuart_sul, @dylan__lim, @OwenDugan, @simran_s_arora, and @HazyResearch. And special thanks to @togethercompute for providing the GPUs to make this work possible!
1
31
3,023