
- Tweets 1,852
- Following 81
- Followers 1,147
- Likes 4,723

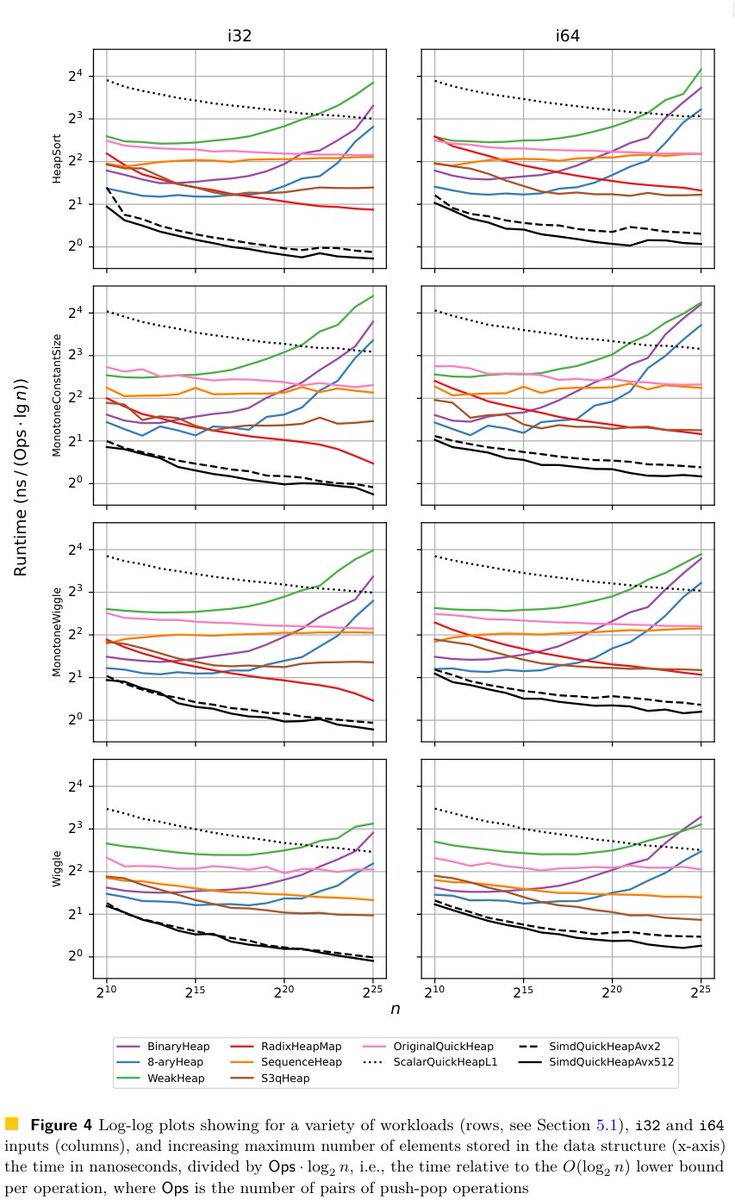
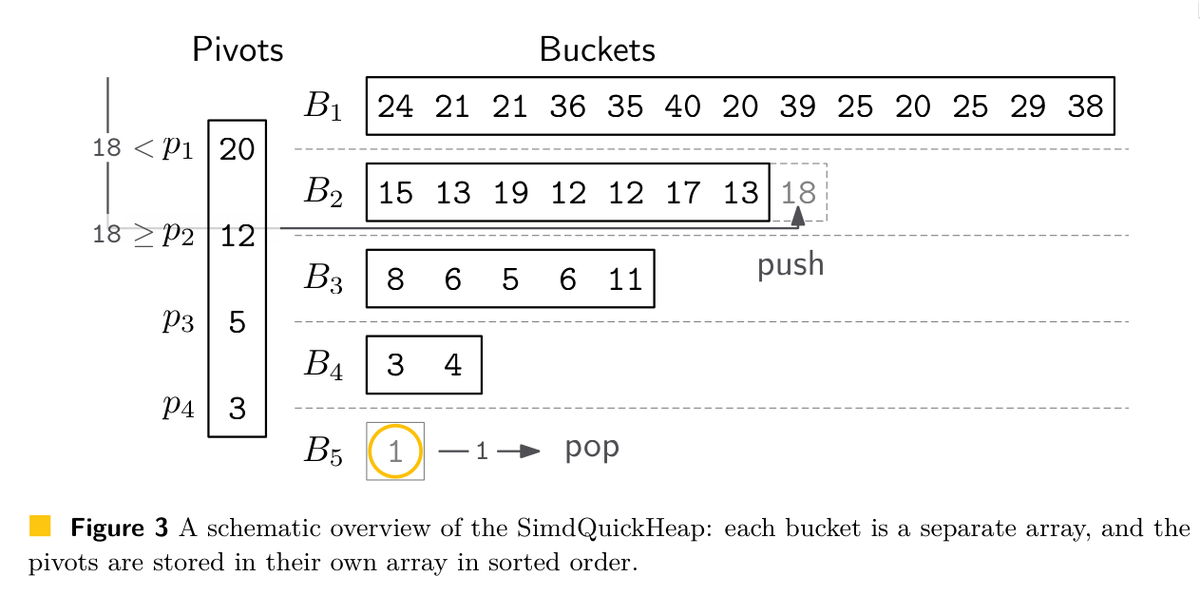

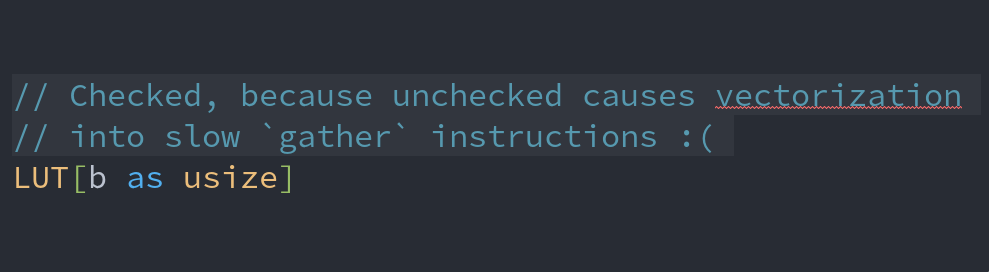











ALT Priority queues are data structures that maintain a dynamic collection of elements and allow inserting new elements and removing the smallest element. The most widely known and used priority queue is likely the implicit binary heap, even though it is has frequent cache misses and is hard to optimize using e.g. SIMD instructions. We introduce the SimdQuickHeap, a variant of the QuickHeap that was introduced by Navarro and Paredes in 2010. As suggested by the name, the data structure bears some similarity to QuickSort. We modify the data layout of the original QuickHeap to have all pivots adjacent in memory, with elements between consecutive pivots stored in dedicated buckets. This allows efficient SIMD implementations for both partitioning of buckets and scanning the list of pivots to find the bucket to append newly inserted elements to. The SimdQuickHeap has amortized expected complexity O(log n) per operation, which improves to O(frac 1Wlog n) in non-degenerate cases, where W is the n



ALT Priority queues are data structures that maintain a dynamic collection of elements and allow inserting new elements and removing the smallest element. The most widely known and used priority queue is likely the implicit binary heap, even though it is has frequent cache misses and is hard to optimize using e.g. SIMD instructions. We introduce the SimdQuickHeap, a variant of the QuickHeap that was introduced by Navarro and Paredes in 2010. As suggested by the name, the data structure bears some similarity to QuickSort. We modify the data layout of the original QuickHeap to have all pivots adjacent in memory, with elements between consecutive pivots stored in dedicated buckets. This allows efficient SIMD implementations for both partitioning of buckets and scanning the list of pivots to find the bucket to append newly inserted elements to. The SimdQuickHeap has amortized expected complexity O(log n) per operation, which improves to O(frac 1Wlog n) in non-degenerate cases, where W is the n






