
d-Matrix delivers high-performance AI inference with digital in-memory compute and ultra-high-bandwidth architecture for modern data centers.
Joined February 2022
- Tweets 261
- Following 182
- Followers 858
- Likes 342
157 Photos and videos












Jun 9
Corsair™ is now in full production.
Products are beginning to ship in volume to priority hyperscalers, neoclouds, and frontier AI labs.
Thanks to our ecosystem partners TSMC, @AristaNetworks, @Broadcom, @Supermicro, @gimletlabs, and @AlchipTECH for helping make this milestone possible.
Read more:
d-matrix.ai/announcements/d-…
#AIInference #AIInfrastructure #HeterogeneousCompute #DataCenterAI #Corsair
1
2
8
589
Jun 4
The Middle East is emerging as AI's third pole. @CNBC featured @BullhoundC's @Pradey discussing the region's AI infrastructure buildout — and their co-investment in d-Matrix with the Qatar Investment Authority as an example of the public-private partnerships driving it.
🎥 cnbc.com/video/2026/06/02/gl…
#AIInfrastructure #datacenters
3
175
Jun 2
How do you build AI infrastructure when no single accelerator wins every workload?
Join Satyam Srivastava (d-Matrix) and Tom St. John (Gimlet Labs) at TPC26 on June 3 in Baltimore for “Bold New World of Heterogeneous AI Computing.”
tpc26.org/tpc26-sessions/
#TPC26 #AIInfrastructure #dMatrix #AIHardware #AI
1
1
3
320
May 28
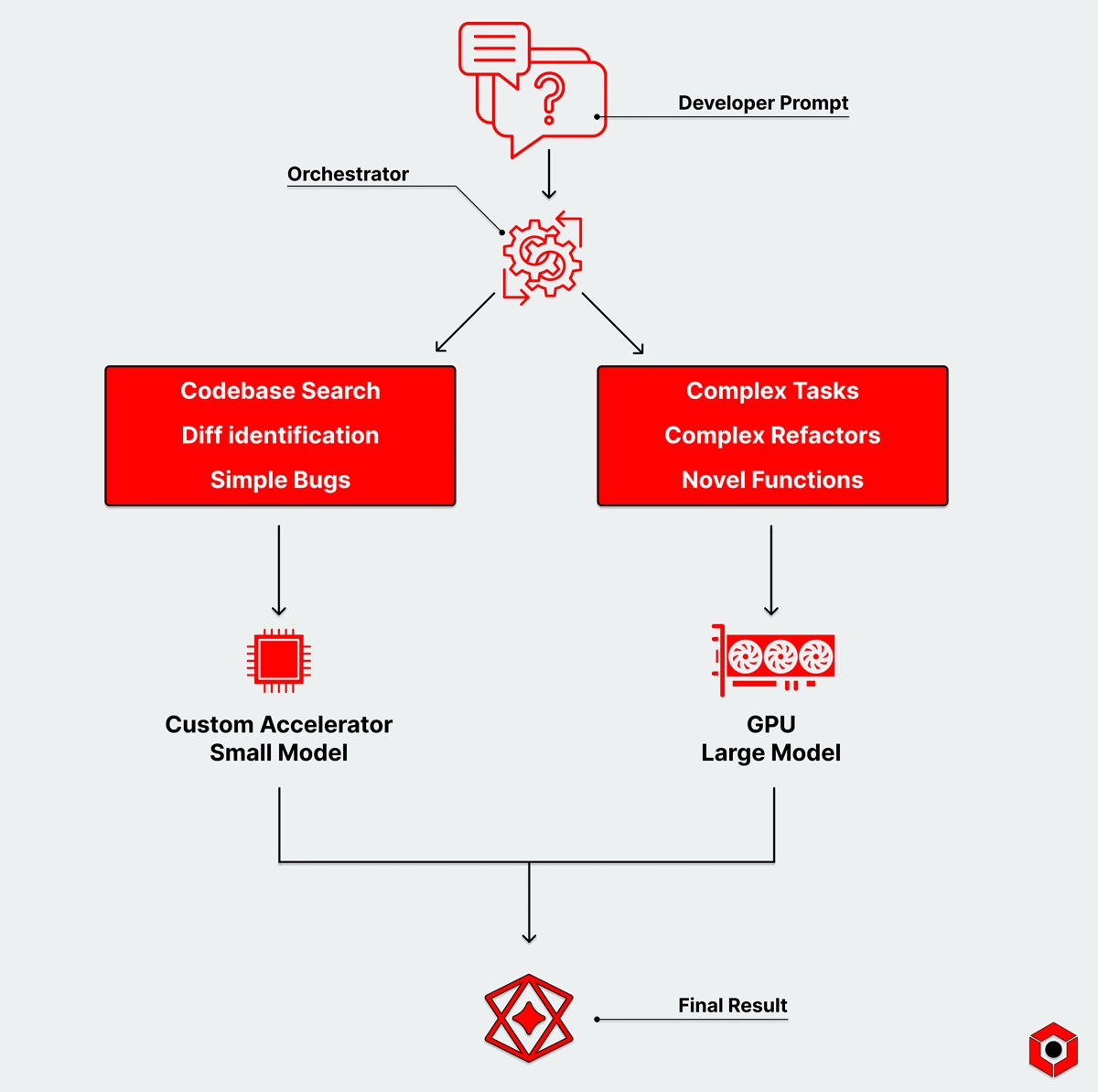
What if your next coding session happened through conversation instead of an IDE?
At d-Matrix, we’re building the infrastructure behind low-latency speech-to-code experiences with heterogeneous AI pipelines and optimized accelerators.
Read what’s next for multimodal AI: d-matrix.ai/building-apps-on…
1
3
269
May 26
Our CEO @sidsheth joined @GregShove on the Supercompanies podcast to talk about how we're not just building inference chips — we're using AI to do it.
🎧 youtu.be/o5vVWphzmsw
3
320
May 19
AI coding agents are exploding in capability.
The infrastructure behind them needs to evolve just as fast.
GPU-only systems are increasingly hitting latency, efficiency, and scaling walls for agentic coding workloads.
Heterogeneous and disaggregated inference pipelines change the equation:
• Lower latency
• Better efficiency
• Speculative decoding acceleration
• Scalable infrastructure for AI coding agents
The future of AI coding requires purpose-built inference architectures.
d-matrix.ai/where-heterogene…
#AI #Inference #AgenticAI #LLM #AIInfrastructure #SpeculativeDecoding
2
208
May 13
Tomorrow at #IMAPSMemorySummit, Max (Sunghwan) Min from d-Matrix presents:
“Low-Latency Digital In-Memory Compute Packaging for LLM AI Inference: SRAM, DRAM and Beyond”
🗓 May 14 | 4:35 PM
📍 Hyatt Regency, Santa Clara
Come see how DIMC architecture is reshaping AI inference hardware. ⚡️
imaps.org/page/MemorySummitS…
#AIInference #DIMC #dMatrix #Semiconductor
1
2
352
May 12
Building the future of AI inference takes a village. Fortunate to have @Infineon as a key partner on this journey.
Together, we’re advancing low-latency, power-efficient AI inference infrastructure for the next generation of interactive AI.
Read more: infineon.com/market-news/202…
#AI #AIInference #GenerativeAI #LLM #DataCenter #Semiconductors #Inference #MachineLearning #PowerEfficiency #AIInfrastructure
4
210
May 4
May the throughput be with you.
AI doesn’t win at training. It wins at inference.
Every prompt. Every response. Every real-time decision.
That’s where latency matters. That’s where efficiency matters.
We’re building systems designed for this moment—high throughput, low latency, and power efficiency at scale.
Built for inference. Ready for production.
#AI #Inference #AIInfrastructure #MayThe4th
1
1
3
314
Apr 29
Join us at TiEcon 2026 this Thursday as our Founder & CEO, Sid Sheth, joins the Unicorn Panel to discuss what truly scales in AI today.
From inference to infrastructure, the conversation is shifting from hype to real-world execution.
📍 Santa Clara Convention Center
📅 April 30, 2026
⏰ 1:30–2:00 PM PST
Register here: tiecon.org/speakers-2026/
#TiEcon2026 #AIInfrastructure #Inference #dMatrix
1
2
289
Apr 28
@dmatrixai's Chris Nicol joins the panel on what composable infrastructure really means for AI at scale.
CCIB | April 29–30 ⤵️ See you there.
#AI #AIInfrastructure #Composable #GenAI
3
193
Apr 27
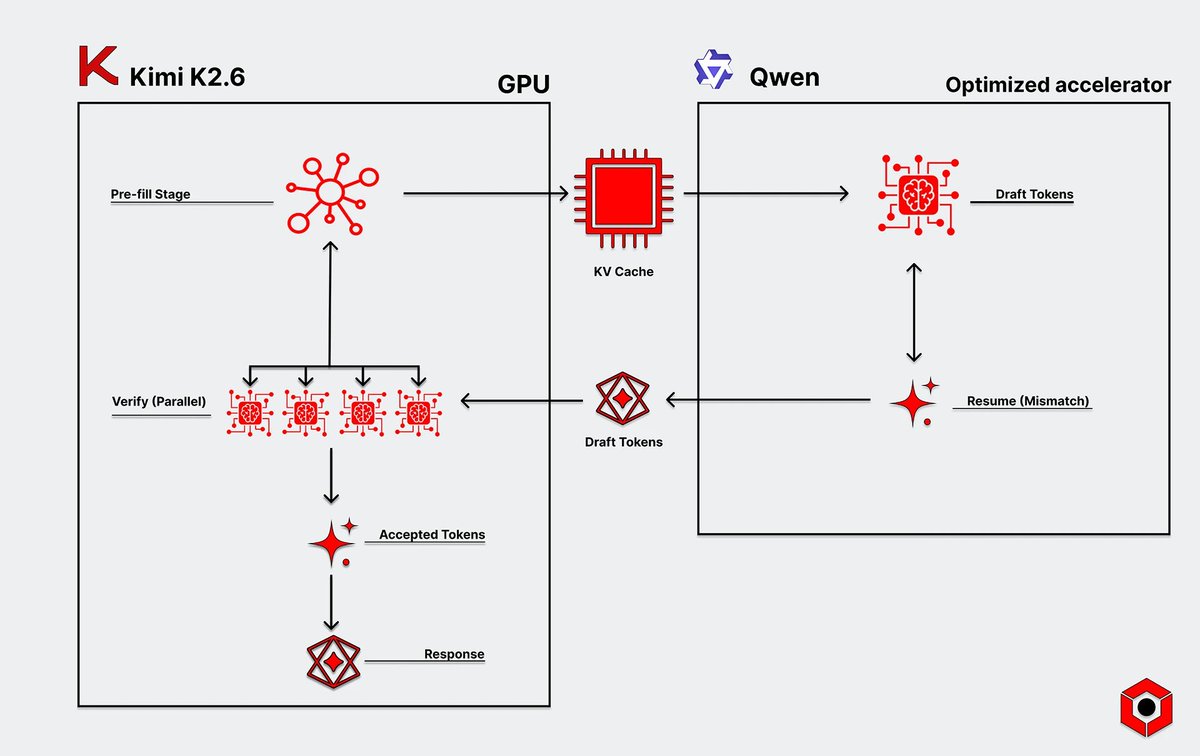
AI inference is a pipeline, not a single workload.
Speculative decoding paired with memory-centric architecture delivers lower latency, better GPU utilization, and faster responses at scale.
The future of AI infrastructure is built by matching the right hardware to the right phase of inference.
Read more: d-matrix.ai/how-speculative-…
#AIInference #SpeculativeDecoding #GenAI #dMatrix
4
14
775
Apr 21
Proud to receive Andes Technology's Most Valuable Customer award at the RISC-V Now! conference today.
The RISC-V ecosystem is a core part of how d-Matrix is building the fastest, most efficient inference accelerator for the Age of AI Inference — and Andes has been a key partner in making that possible. Thank you to Frankwell Lin and the entire Andes team.
Photo (left to right): d-Matrix Founder & CEO Sid Sheth, Andes Chairman & CEO Frankwell Lin, and d-Matrix Chief AI SW Architect Satyam Srivastava.
#AIInference #RISCV #LowLatency
4
331
Apr 17
We’re at RISC-V Now.
Join Satyam Srivastava (d-Matrix) on solving low-latency, efficient inferencing in the datacenter.
4/21 | San Jose, CA
Register: eventbrite.com/e/risc-v-now-…
#RISCV #AIInference #AIInfrastructure #Datacenter #ML
1
225
Apr 9
Great to see our CEO Sid Sheth speaking at HumanX.
“It’s not a money problem — it’s an architecture problem.”
Scaling AI requires heterogeneous systems where specialized silicon works together to deliver real-time inference at scale.
The Age of Inference is here.
#AI #Inference #HumanX

1
1
7
418
Apr 9
Today at HumanX, d-Matrix CEO Sid Sheth will share why the GPU-only era is ending and what comes next for AI inference infrastructure.
“The GPU-Only Era Is Over”
April 9 | 2:25–2:40 PM
Grove Theater
humanx.co/speakers/sid-sheth
#HumanX #AIInference
1
1
4
285
Apr 6
“Inference is bigger than any one chip.”
Thanks to @DCKnowledge and @ShaneSnider for the coverage of d-Matrix’s acquisition of GigaIO’s data center business and what it means for rack-scale AI inference infrastructure.
Worth a read ↓

We spoke with Sid Sheth, CEO of d-Matrix, about the company’s acquisition of GigaIO’s data center business – a strategic move that brings PCIe fabric technology and rack-scale system design in-house.
datacenterknowledge.com/data…

8
372
Apr 2
Excited to see GPU Corsair systems running in the @gimletlabs environment.
Heterogeneous AI infrastructure is how agentic workloads will run at scale.
#AIInference #AgenticAI #AIInfrastructure
Apr 2

First view of our GPU @dMatrix_AI Corsair configuration for high-performance agentic workloads. The future of inference is heterogeneous!
Technical writeup here: gimletlabs.ai/blog/low-laten…

1
9
550