
Distributed query engine providing simple and reliable data processing for any modality and scale (github.com/Eventual-Inc/Daft)
Joined September 2022
- Tweets 656
- Following 47
- Followers 846
- Likes 418
212 Photos and videos








Pinned Tweet

11 Dec 2025
.@SourcetableApp CTO @andrewgrosser shares his recommended tech stack for serious startups - a "wicked combination" that includes:
- S3 Cassandra for data
- Daft for processing
- Python, WASM, Ray
Learn how they built the first AI-powered spreadsheet:
daft.ai/blog/how-sourcetable…
2
1
11
1,425
Daft retweeted

Jun 9
🚢 Daft v0.7.15 just shipped.
try_cast() converts types without crashing your pipeline — invalid values become null instead of throwing a runtime error.
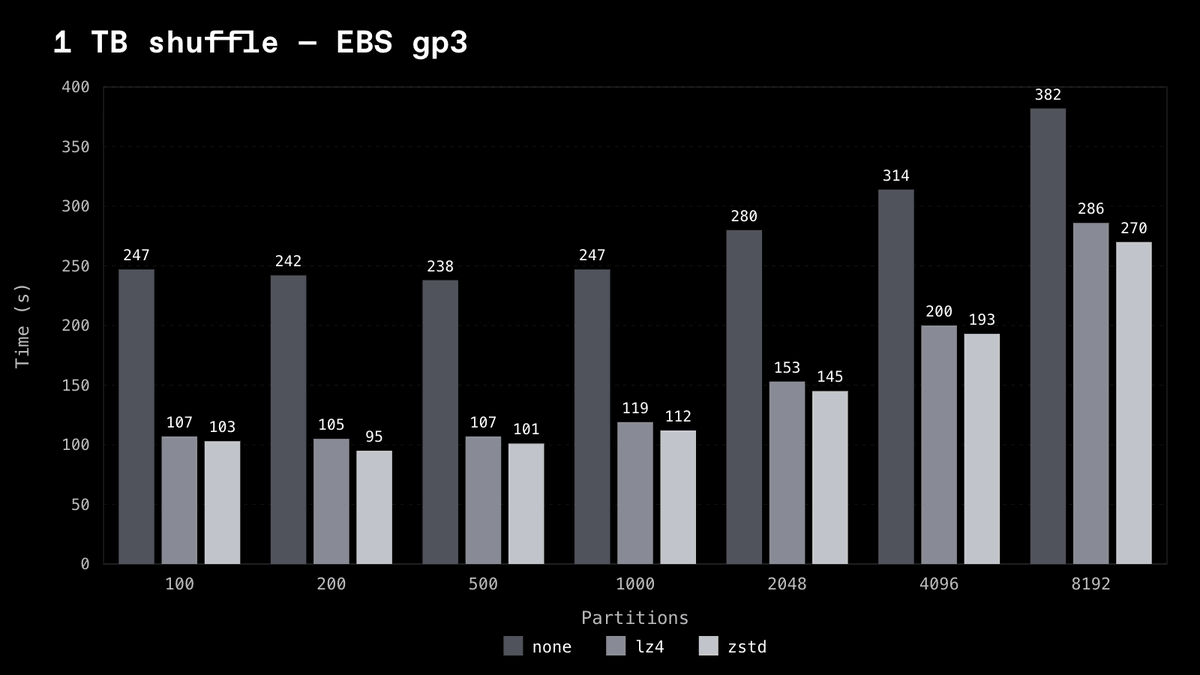
Also in this release: LZ4 flight shuffle compression, UUIDv7 partition transforms, PostgreSQL source.
daft.ai/blog/daft-v0-7-15
1
4
4
130
Jun 8
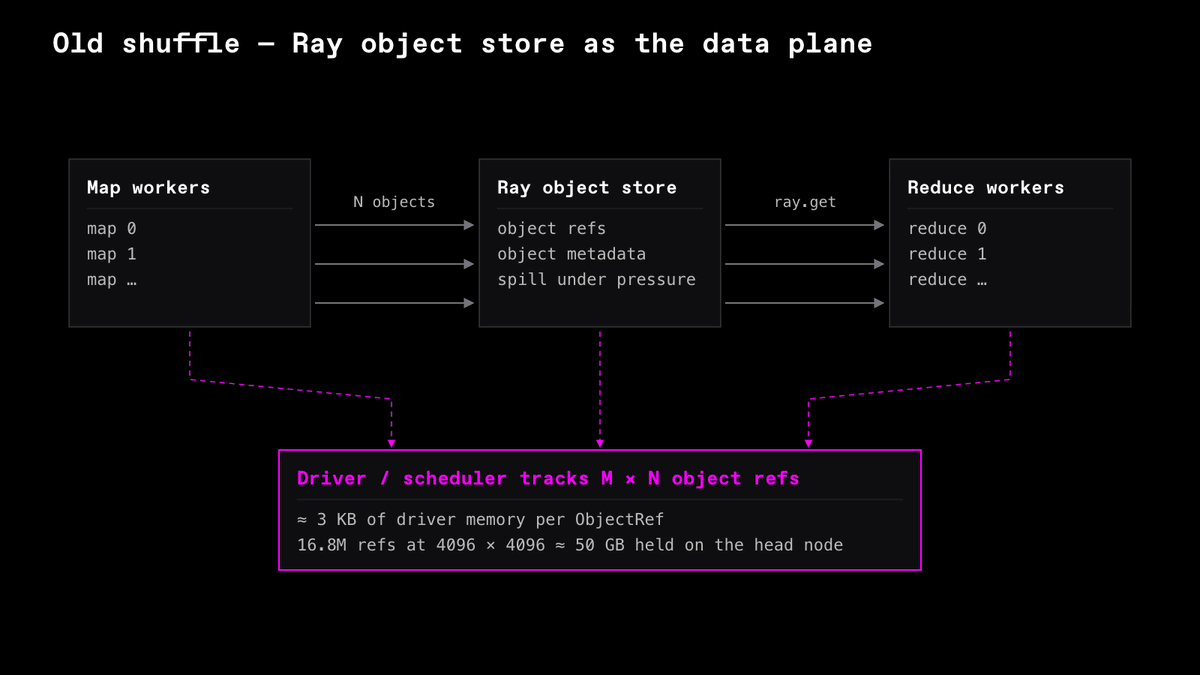
If a distributed query has to materialize more than a few terabytes of data, there's one operation that will dominate: the shuffle.
Shuffling data at scale has been a real bottleneck for Daft users, so we took the time to fix the root cause and rebuild the shuffle from scratch.
1
5
17
2,274
Jun 8
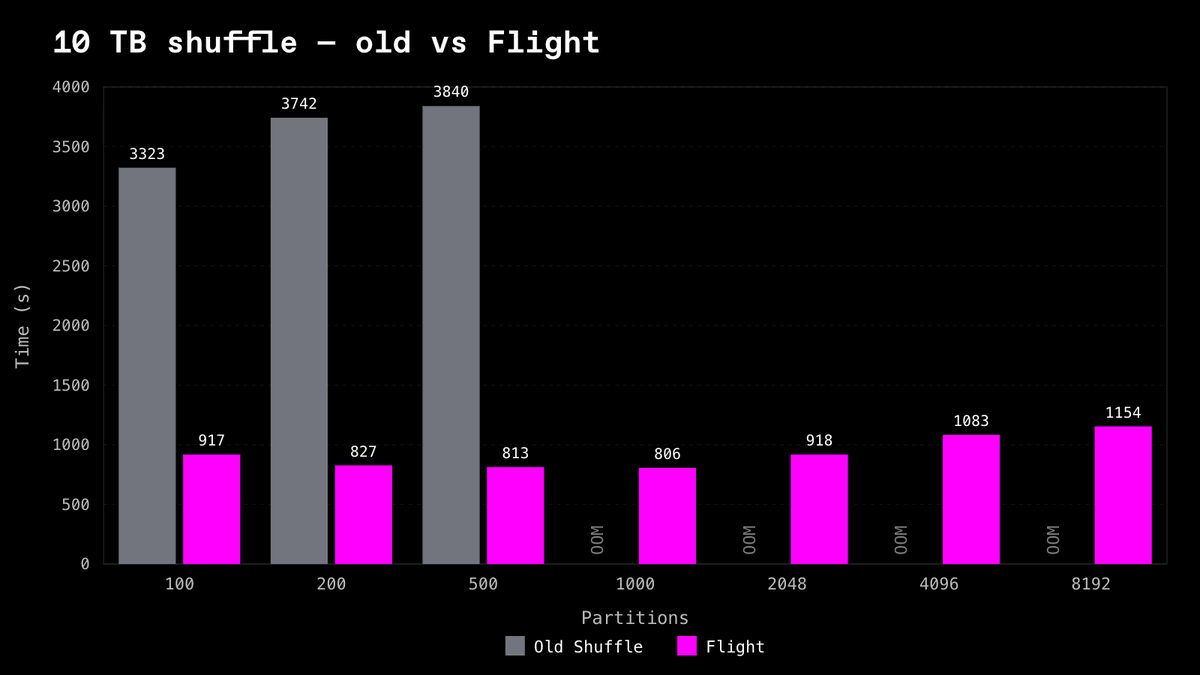
On a TPC-H repartition across 32 workers: at 10 TB the object-store shuffle runs the head node out of memory past 1,000 partitions, while Flight Shuffle completes every partition count and runs 3.6 to 4.7x faster where both finish.
1
1
1
94
Daft retweeted

VLA submissions at ICLR grew 18x in a single year, but World Action Models are showing more promising results when it comes to inference speed and adaptability.
ICLR is the premier gathering of professionals dedicated to the advancement of the branch of artificial intelligence called representation learning.
As Physical AI has gone mainstream, a ton of research has focused on leveraging VLAs to translate the intelligence of LLMs into robotics tasks.
But VLAs are slow, and WAM like Shengshu's MotuBrain achieved 96% on RoboTwin 2.0 with an architecture that supports policy learning, world modeling, video generation, inverse dynamics, and joint video-action prediction in a single model.
"These results show that unified world action models can scale in generality, predictive accuracy, and real-world deployability."
It's crazy that MotuBrain runs at 11 hz and adapts to new humanoid embodiments with only 50--100 trajectories!
Link in the comments

4
13
74
4,609
Daft retweeted
May 27
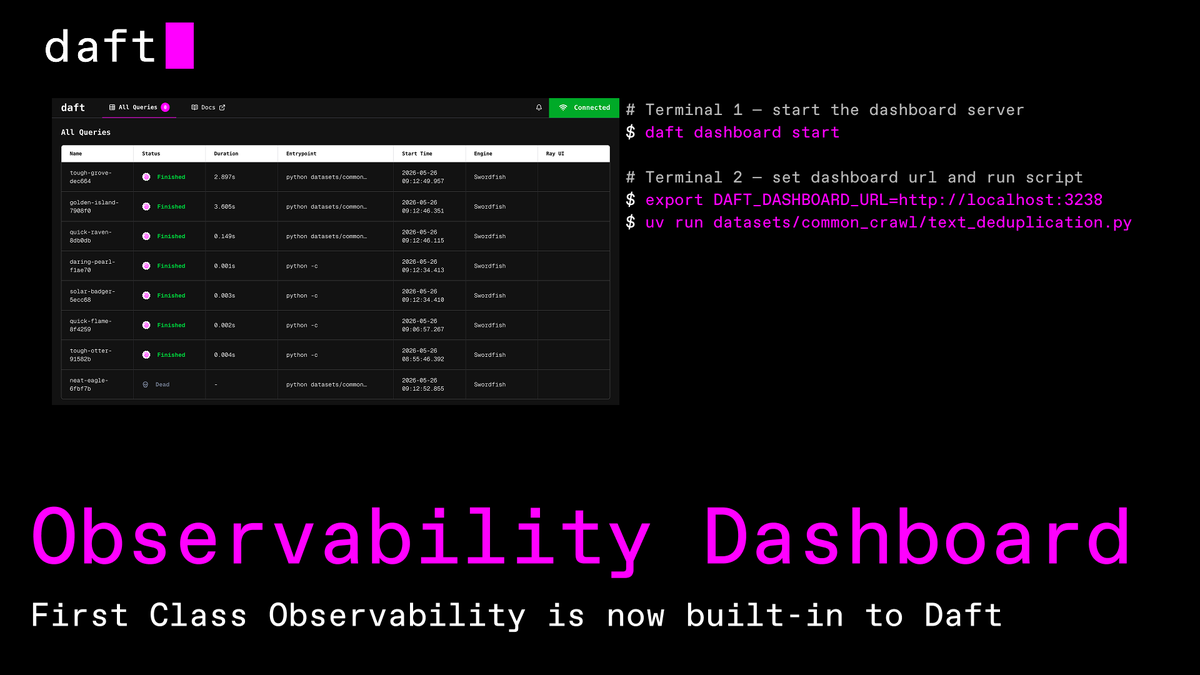
First-class observability in Daft.
Operators, Tasks, Rows, Memory are all surfaced in a dashboard that ships with the install.
OTel endpoints for your existing collector.
Stuck detection.
DAFT_TRACE for console debugging.
~45 PRs across the observability stack.
daft.ai/blog/first-class-obs…
1
4
11
685
Daft retweeted
May 20
🚢 Daft v0.7.14 has shipped
Parquet reader rewrite — up to 17x faster remote reads
Streaming distributed limits
Native UUIDv7 generation
JSON array/object functions
daft.ai/blog/daft-v0-7-14
1
3
9
435
Daft retweeted
May 19
Three Daft releases in four days.
v0.7.11 — Arrow PyCapsule, streaming ASOF joins, Iceberg idempotent commits.
v0.7.12 — Iceberg table properties extension macro revert.
v0.7.13 — Forward ASOF joins.
Upgrade straight to v0.7.13.
daft.ai/blog/daft-v0-7-11-th…
1
3
5
265
Daft retweeted
May 14
Daft now has native distributed ASOF joins.
And it scales horizontally without data skew.
daft.ai/blog/scaling-asof-jo…
1
4
8
361
Daft retweeted
May 13
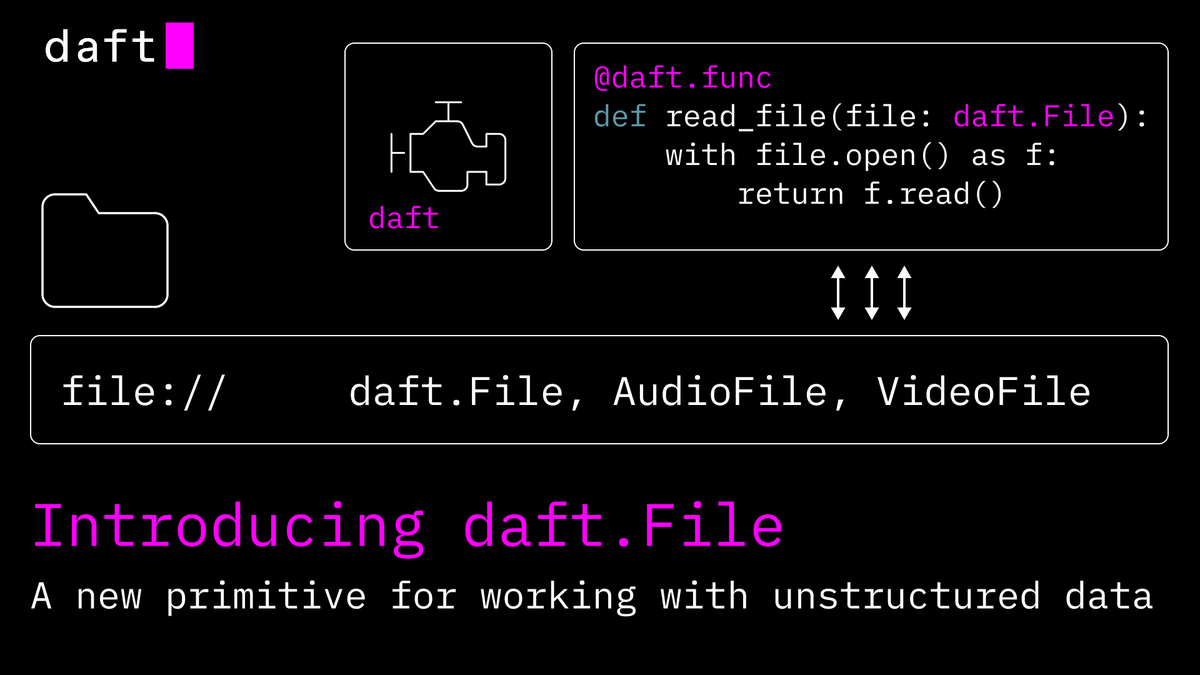
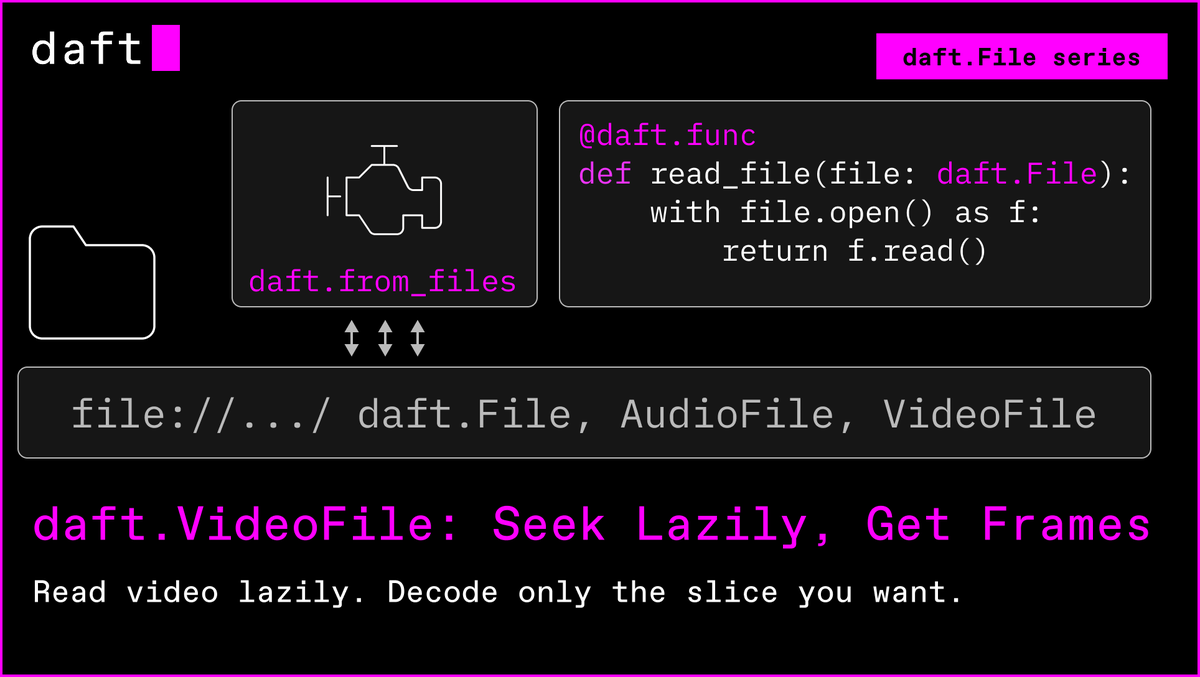
daft.VideoFile is perfect for Physical AI.
Open X-Embodiment aggregates over a million episodes. DROID alone runs 350 hours of multi-camera 60fps footage. That's hundreds of millions of frames across a single dataset, and most action-model training doesn't need them all.
- read_video_frames — filter on keyframes; supports S3, GCS, & YouTube URLs.
- video_metadata — resolution, fps, duration, frame count from file headers.
- video_frames(start_time, end_time) — decode a 10-second window from a 90-minute file.
Frames land as Image columns in the same DataFrame.
Feed them to a vision model, compute embeddings, and write to Iceberg.
Check out the blog
daft.ai/blog/daft-videofile-…
3
5
168
May 8
WAM!!!
May 8

VLAs are dead, long live World Action Models
So declares @DrJimFan, the most credible researcher in robotics today.
daft.ai/blog/vlas-are-dead-l…
👆We just published a short blog where @ykdojo breaks down the video. It certainly helped me correct my mental model.
2
216
Daft retweeted
May 7
So turns out I'm not the only one who builds on @daftengine 😆
In fact, theres a TON of projects that leverage daft natively to power their AI & data processing.
Daft is the Data Engine for AI.
> I say it because its true.
> I keep saying it because the Daft community keeps giving back!
Check out all these projects! (link in the comments)

1
1
6
560
Daft retweeted
Probably my favorite episode yet!
Just finished filming our latest episode of Zero Shot Espresso with @danimberman who is an @ApacheAirflow PMC, developed the @kubernetesio executor, and now helps technical teams ship production AI as a consultant.



1
2
3
145
Daft retweeted
May 5
🚢 Daft v0.7.10
30 contributors (a release record!)
41 new features and functions.
Distributed as_of joins, SimHash dedupe, temporal arithmetic, C extensions.
daft.ai/blog/daft-v0710-30-c…

2
3
4
200
Daft retweeted

May 4
The fastest H3 geospatial indexing in Daft wasn't written by the Daft team.
Developed by Garrett Weaver, daft-h3 runs 3–16x faster than simply wrapping h3-py in a Python UDF. That speed up is thanks to Daft's Native Extensions powered by Apache Arrow's C Data Interface.

1
3
5
231
Daft retweeted
Apr 28
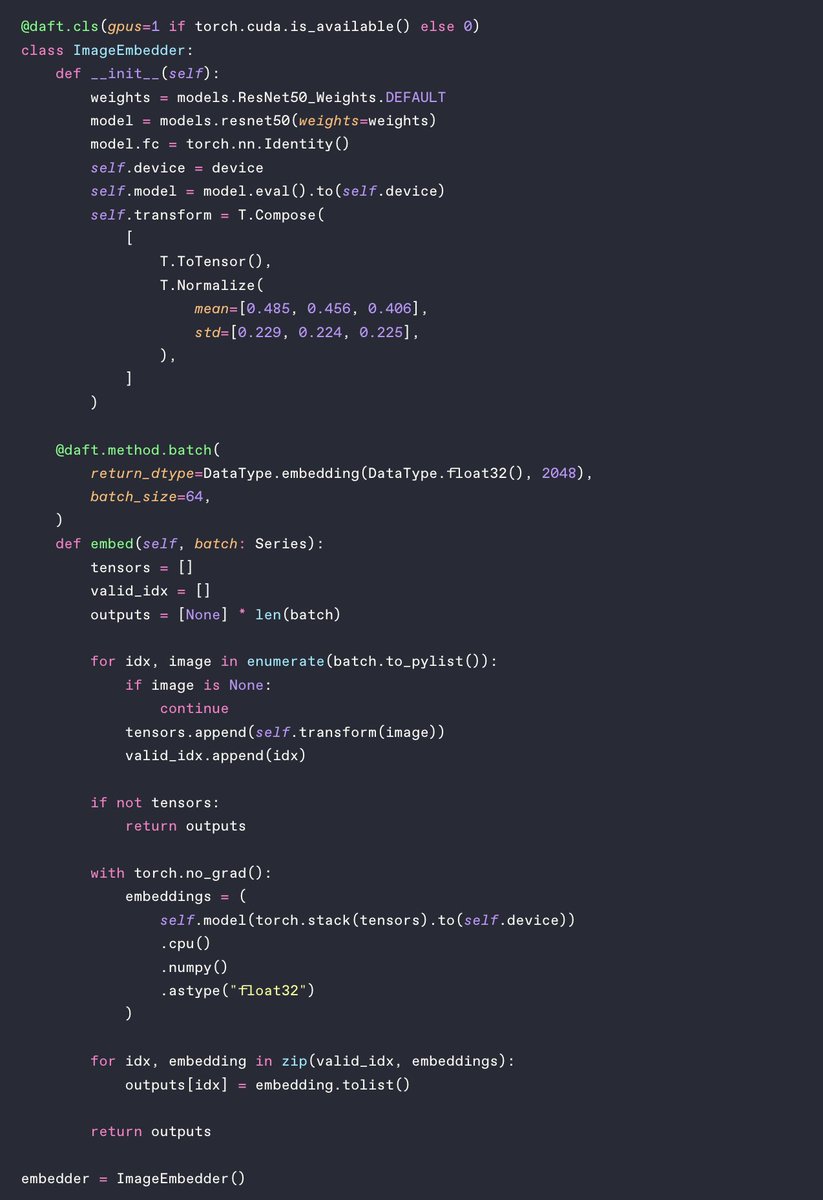
Most image embedding pipelines are actually two pipelines stitched together.
Script one: PySpark reads images from S3, resizes them, joins with metadata, writes to Delta Lake.
Script two: PyTorch loads ResNet, generates embeddings on GPU, writes back to Delta Lake.
Two frameworks. Two sets of dependencies. Two GPU configs. Serialization overhead at every boundary.
With Daft, it's one script. download → resize → join → embed → write. daft.cls handles GPU placement and batching. No handoff.
1
3
5
177
Daft retweeted

Apr 23
Proud but not surprised to see @CRV portco @daftengine punching above their weight 🤗paraform.com/talent-density-…
2
2
20
1,815
Daft retweeted
Apr 23
Eventual was ranked #47 globally on Paraform’s Talent Density Index.
What I liked most about this wasn’t the ranking itself, but how they define it: not by who looks impressive on paper, but by who’s actually developing people the market is fighting for.
A friend put it better than I could:
“Honestly, it’s a testament to the talent you’re recruiting and fostering.”
Feels right.
Grateful to be building alongside this team.
paraform.com/talent-density-…

1
5
8
267