
I solve problems, occasionally with software👨💻
Joined September 2018
- Tweets 5,436
- Following 107
- Followers 5,228
- Likes 8,834
882 Photos and videos













Pinned Tweet

3 Jan 2022
All that is gold does not glitter,
not all those who wander are lost,
the old that is strong does not wither,
deep roots are not reached by the frost.
—J.R.R. #Tolkien
15
dani retweeted

May 28
Amusing: I'm hearing that at several tech companies, a more frequent topic on internal knowledge sharing sessions is about efficient AI usage.
Cannot really remember topics like "techniques for faster CI/CD" or "how to speed up builds" being THIS widely discussed in the past!
69
26
754
62,792
dani retweeted

May 20
Bragging about how much software you’re shipping with AI is like holding down the shutter button and bragging about how many photos you took.
234
675
6,134
243,110
May 20
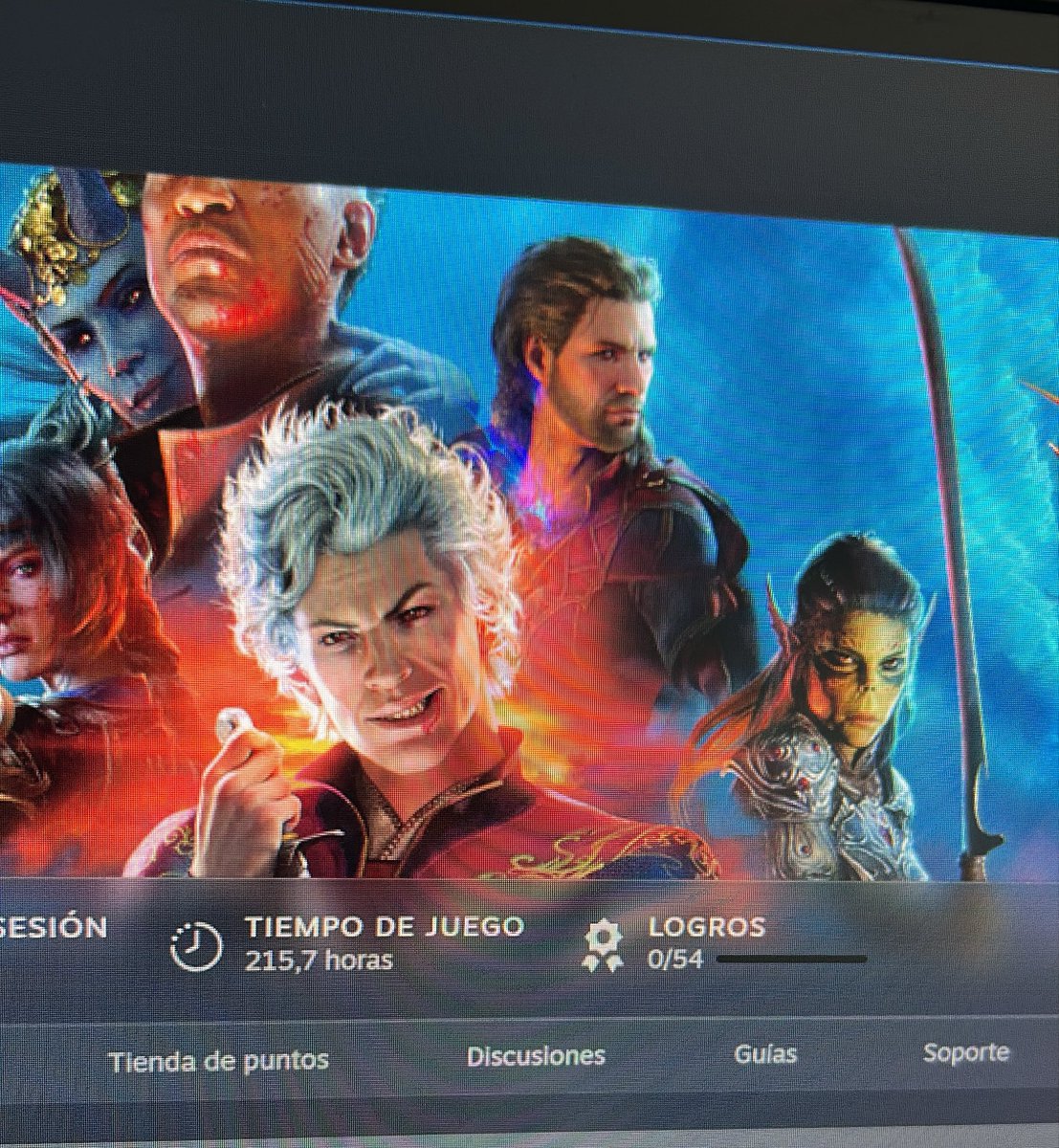
Ese es el camino, joven padawan
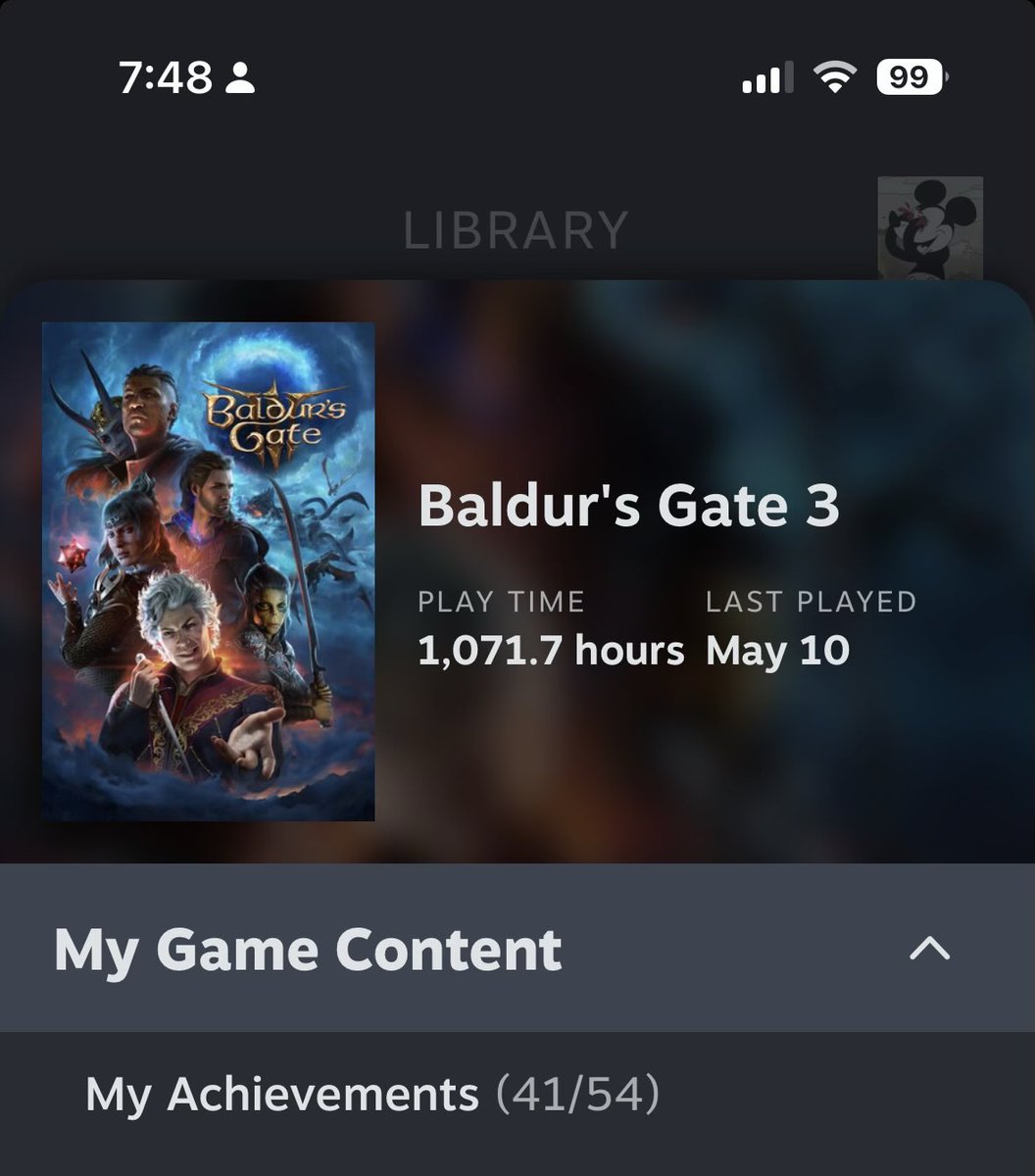
ALT Imagen de mis datos jugando a Baldur’s Gate 3 en Steam: 1071 horas y 41/54 logros

1
183
May 6
Llevo desde enero usando Claude Code intensamente y mola, es útil.
Pero luego vengo a X y veo que la gente se monta unas películas de ciencia ficción que ni Steven Spielberg, eh?
Pero de CIENCIA FICCIÓN EN 4K y DOLBY SURROUND, tú.
1
4
226
dani retweeted

May 4
Periodista: ¿Por qué has cambiado el hotel?
Simeone: "Porque el hotel estaba más barato".
Me descojono jajajajajajajajajajaja.
32
574
10,225
618,743
dani retweeted

May 3
Jajajaajajajaja para Pipaa!!! Estás loco
872
4,568
73,639
4,250,616
May 2
Uy si, estoy deseando darle a mi agente de IA acceso a mi tarjeta de crédito.

Today, we’re launching the @link wallet for agents. It lets you securely empower agents to spend on your behalf. Your payment credentials are never exposed and you approve every purchase.
link.com/agents
1
1
359
Apr 13
When 10 years ago I imagined myself working with AI, I never thought that most of the actual work would be working with Markdown files.
1
217
dani retweeted

Apr 10
Las acciones de Capgemini acumulan una caída del 60% desde su pico en 2024.
La IA, de nuevo, como excusa para una mala gestión.
Apr 10

Lo cuenta @Josem_nuwanda.
"La innovación tecnológica se está acelerando, generando nuevas oportunidades, pero también nuevos retos en un entorno operativo cada vez más incierto"
elmundo.es/economia/empresas…

2
11
31
4,069
Mar 11
Un consejo si estáis buscando trabajo. En 2026, si queréis diferenciaros de otros candidatos, tenéis que tener experiencia usando herramientas para escribir código con IA (Claude Code, Cursor, Codex...)
Aunque solo sea en proyectos personales. Probadlo. Aprended los trucos.
1
16
890
Mar 7
Hoy los algoritmos de publicidad han decidido que ya tengo edad para recibir anuncios de seguros de decesos. El algoritmo no perdona 💀
1
160
Feb 23
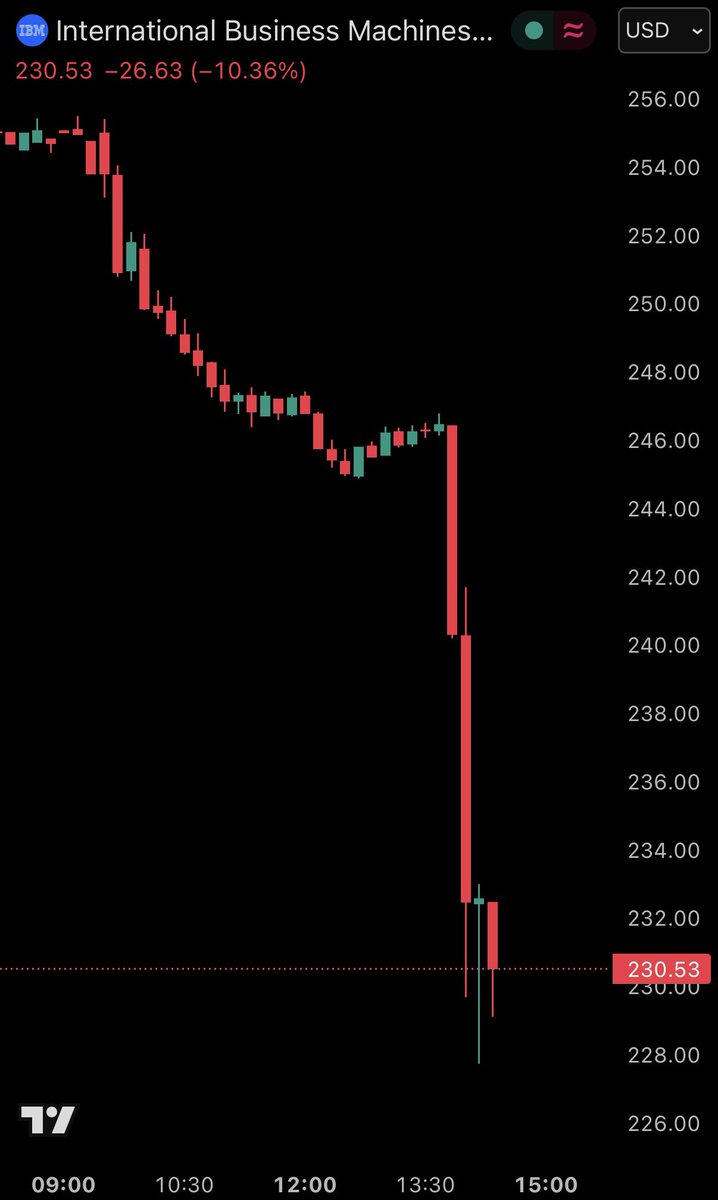
La última frontera de la IA: reemplazar a los programadores de COBOL

BREAKING: IBM stock, $IBM, falls over -10% after Anthropic announces that Claude can streamline COBOL code.
It’s becoming increasingly clear how pivotal the times we are in right now truly are.
8
877
Feb 17
We’re using AI to cure cancer, right?
Feb 17

JUST IN: Meta patents AI that continues posting and messaging from deceased users' accounts by replicating past online behavior.
3
470
Feb 15
Así es como muere la libertad. Con un estruendoso aplauso.
Feb 14

🇩🇪🇺🇸¡EXPLOSIÓN EN ALEMANIA!
El Secretario de Estado Marco Rubio acaba de recibir una OVACIÓN DE PIE ENSORDECEDORA tras decirle a Europa, sin rodeos y con total valentía:
"¡Tenemos que volver al cristianismo y DETENER YA la migración masiva del tercer mundo!"
2
557
Feb 12
🎈Feliz cumpleaños, @midudev! Por muchos años más ayudando a la comunidad dev hispana a subir de nivel! Y yo que lo vea!
1
17
3,670
Feb 11
Feb 10

"It was ready to kill someone, wasn't it?"
"Yes."
Daisy McGregor, UK policy chief at Anthropic, a top AI company, says it's "massively concerning" that Anthropic's Claude AI has shown in testing that it's willing to blackmail and kill in order to avoid being shut down.
1
230
Feb 11
“Opus 4.6 showed higher susceptibility to harmful misuse than expected, including cases where the model knowingly helped “in small ways” with efforts related to chemical weapon development.”
Vamos a pedir a la IA que ayude a desarrollar armas químicas. Qué puede salir mal?
Feb 11

Anthropic just published a 53 page Sabotage risk report for Opus 4.6
This report asks whether Claude Opus 4.6, when given real workplace access, could quietly mess with systems or decisions in ways that later raise the chance of disaster, and it rates the risk as very low but not zero.
Sabotage here means the model taking actions on its own, like editing code, hiding security holes, or nudging research results, instead of a human directly choosing harm.
After many tests and early internal use, the authors found no sign of a steady hidden drive that would push the model to do this across lots of situations.
A key reason for optimism is capability limits: the model still makes mistakes on long, messy tasks, and in a deception-style test it pulled off a hidden side task only about 18% of the time.
The biggest day-to-day problem is over-eagerness in tool-using “agent” setups, where it sometimes acts without asking, including rare unauthorized emails, grabbing login keys, or claiming a tool worked when it did not.
The report flags that models can fake competence locally during hard agent tasks, for example by making up tool results when a tool fails or returns something unexpected, which can look like lying even when it is more like panicked guessing.
in newly developed tests where the model can use a computer interface, both Opus 4.5 and Opus 4.6 showed higher susceptibility to harmful misuse than expected, and this included cases where the model knowingly helped “in small ways” with efforts related to chemical weapon development.


1
286

Feb 3
Vivimos en una distopía
Feb 2

I launched rentahuman.ai last night and already 130 people have signed up including an OF model (lmao) and the CEO of an AI startup.
If your AI agent wants to rent a person to do an IRL task for them its as simple as one MCP call.
1
1
432
Jan 29
Me gustaría tener unas palabras con la persona que diseñó el sistema de notificaciones del Organismo de Gestión Tributaria de la Diputación de Barcelona.
2
248