
♤ Molecular Biotechnology ♧ Kitchen Juggler ♢ Genetic Engineering ¥
Joined May 2011
- Tweets 1,054
- Following 328
- Followers 57
- Likes 561
31 Photos and videos














Daniel Guzmán-Zapata retweeted

1
3
2,070
Daniel Guzmán-Zapata retweeted

La mayor parte del genoma humano ha sido considerada históricamente "materia oscura", una incógnita para la ciencia.
Hoy Nature publica esto sobre AlphaGenome de Google Deepmind. Este nuevo modelo de IA logra predecir el impacto patológico de variantes genéticas en regiones no codificantes con una precisión sin precedentes. Y su impacto puede ser tremendo
Este avance demuestra que la Inteligencia Artificial es ya el motor indispensable para descifrar la complejidad biológica y acelerar la próxima era de la medicina de precisión.
nature.com/articles/s41586-0…
11
347
1,232
57,866
Daniel Guzmán-Zapata retweeted

Jan 28
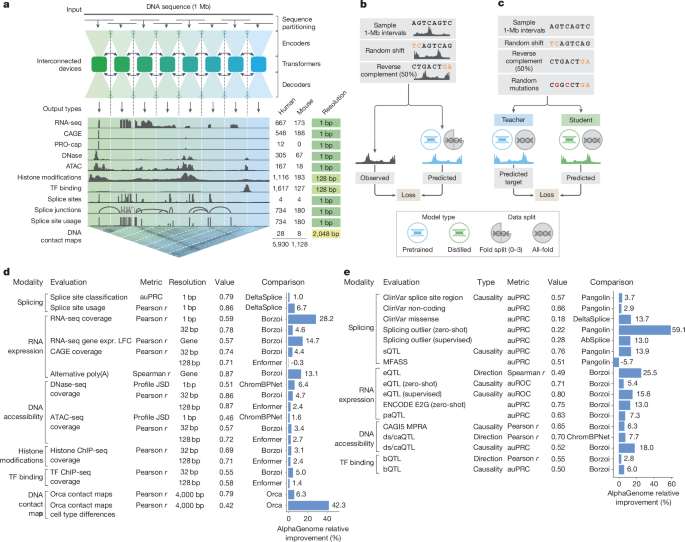
AlphaGenome: Decoding the dark matter of the genome with a unified deep learning model
More than 98% of human genetic variation lies outside protein-coding regions. These "non-coding" variants can disrupt gene regulation in remarkably diverse ways: altering chromatin accessibility, shifting 3D genome architecture, modifying splicing, or changing expression levels—often in tissue-specific patterns. Yet existing computational models face a fundamental trade-off: either they capture long-range regulatory interactions (like distant enhancers) but blur fine-scale features, or they achieve nucleotide resolution but miss distal context. And most specialize in a single modality, leaving users to stitch together predictions from many separate tools.
Žiga Avsec and coauthors at Google DeepMind present AlphaGenome, a model that sidesteps these trade-offs. It takes 1 megabase of DNA as input and predicts ~6,000 genome tracks—spanning gene expression, splicing (sites, usage, and junctions), chromatin accessibility, histone modifications, transcription factor binding, and 3D contact maps—at up to single-base-pair resolution.
The architecture combines a U-Net backbone with transformer blocks: convolutions capture local motifs essential for splice sites and TF footprints, while transformers model long-range dependencies like enhancer–promoter interactions. Training uses a two-stage approach—pretraining on experimental data followed by distillation from an ensemble of teachers using mutationally perturbed sequences—yielding a single model that scores variants across all modalities in one pass.
The results are striking: AlphaGenome achieves state-of-the-art performance on 25 of 26 variant effect prediction benchmarks, including a 25% improvement in predicting eQTL direction over the previous best model. It outperforms specialized models on their own tasks—beating SpliceAI-class methods on 6 of 7 splicing benchmarks and ChromBPNet on accessibility QTLs. Critically, the multimodal outputs enable mechanistic interpretation: for oncogenic mutations near the TAL1 gene in T-cell leukemia, AlphaGenome simultaneously predicts neo-enhancer formation (increased H3K27ac), chromatin opening, and elevated gene expression—recapitulating experimentally validated mechanisms.
This points toward a future where interpreting non-coding variation no longer requires assembling a patchwork of specialized models. A unified framework that jointly predicts molecular consequences across modalities could accelerate rare disease diagnostics, guide therapeutic oligonucleotide design, and help prioritize variants in GWAS loci—moving us closer to truly reading the regulatory code written in DNA.
Paper: nature.com/articles/s41586-0…

6
107
472
28,560
Daniel Guzmán-Zapata retweeted

Jan 28
AlphaGenome is out in @nature today along with model weights! 🧬
📄 Paper: nature.com/articles/s41586-0…
💻 Weights: github.com/google-deepmind/a…
Getting here wasn’t a straight path. We sat down @googledeepmind to discuss the story behind the model, paper & API: youtu.be/V8lhUqKqzUc

29
477
1,862
225,764
Daniel Guzmán-Zapata retweeted

29 Nov 2025
The model of gene expression taught in school is highly misleading!
Transcription factors are proteins that bind to DNA and then help repress, or activate, the expression of genes. Cells have hundreds of different types of transcription factors, each tuned to regulate different genes based on short snippets of DNA located near those genes.
The basic model, taught in school, says that these transcription factor proteins float around the cell and, when they bump into a DNA sequence, either latch onto it strongly (CORRECT SITE!) or fall off quickly (WRONG SITE) and keep searching. All the other DNA in a cell is basically abstracted away as unimportant or irrelevant; mere background noise.
But again, this model is naive! And a new paper, published in Cell, beautifully shows how the sequences SURROUNDING a transcription factor's binding site also matter a great deal.
This won't be surprising to many biologists, as "cracks" in the standard two-state model began emerging decades(?) ago. Biologists have tagged transcription factors with fluorescent tags and then watched them move around living cells. And they have noticed that when transcription factors land in a "wrong" location in the genome, they skip or hop to a nearby location and repeat this until finally connecting with the "correct" sequence. So in other words, there are actually three states that a transcription factor can exist in: free-floating, "searching", or "bound."
(More technically, transcription factors first do a 3D search, then latch onto DNA and do a 1D search to find the correct location.)
For this new paper, though, scientists exhaustively quantified *how* the sequences flanking a transcription factor binding site influence the search of the protein.
They did a huge in vitro experiment, wherein they placed a specific transcription factor with a known binding site, called KLF1, in a huge library of 11,812 different DNA sequences. These sequences had mutated "core" binding sites and variations in the flanking sequences. They also prepared negative controls. Then, these researchers measured the binding kinetics of KLF1 with each sequence to understand which bases in the flanking sites impact the 1D search.
What they found is that KLF1 has a basically flat disocciation rate from its core sequence, but that the PROBABILITY that it finds this sequence depends a lot on the surrounding context. Even mutations located dozens of bases away from the core site matter a lot, either pushing KLF1 to "hop" faster to find the site, or "trapping" KLF1 and slowing down its search. These flanking sequences can cause up to a 40-fold variation in the affinity of a transcription factor for its target site!
This is just one small part of the paper, though, so I encourage anyone interested to read the whole thing. It is challenging throughout.


18
237
1,178
127,114
Daniel Guzmán-Zapata retweeted

16 Nov 2025
🚨 Physicists say there’s a mirror universe where time runs in reverse.

ALT 🚨 Physicists say there’s a mirror universe where time runs in reverse
445
403
2,105
248,816
Daniel Guzmán-Zapata retweeted

15 Nov 2025
Did you know?
An explosion of zinc fireworks occurs when a human egg is activated by a sperm enzyme, and the size of these “sparks” is a direct measure of its ability to develop into an embryo.
In other words, life begins with a flash of light.
403
3,117
25,793
1,180,567
Daniel Guzmán-Zapata retweeted

3 Nov 2025
PhD is fully funded in Finland
PhD is fully funded in Norway
PhD is fully funded in Sweden
PhD is fully funded in Belgium
PhD is fully funded in Denmark
PhD is fully funded in Germany
PhD is fully funded in Switzerland
PhD is fully funded in The Netherlands
64
269
2,511
479,158
Daniel Guzmán-Zapata retweeted

30 Oct 2025
This (pulsar) neutron star spins 716 times every second, racing at 24% the speed of light. Just one teaspoon of it weighs more than Mount Everest... and this is the real sound of a neutron star captured by NASA.
11
67
320
17,168
Daniel Guzmán-Zapata retweeted
22 Oct 2025
Microdispensing at the picoliter scale is redefining precision in science enabling ultra-accurate droplet placement for biotech, diagnostics and electronics.
A raindrop ≈ 50 µL is 50 million× larger than a picoliter.
46
415
3,434
253,287
Daniel Guzmán-Zapata retweeted
13 Oct 2025
Many people think of proteins as having a biological function — catalyze reactions, detect pathogens, etc.
At a higher level, though, proteins are programmable materials. They are an advanced form of nanotechnology, made from templates that we can read and write and understand.
And because proteins are programmable, we can use them to build physical logic gates or “smart” drugs.
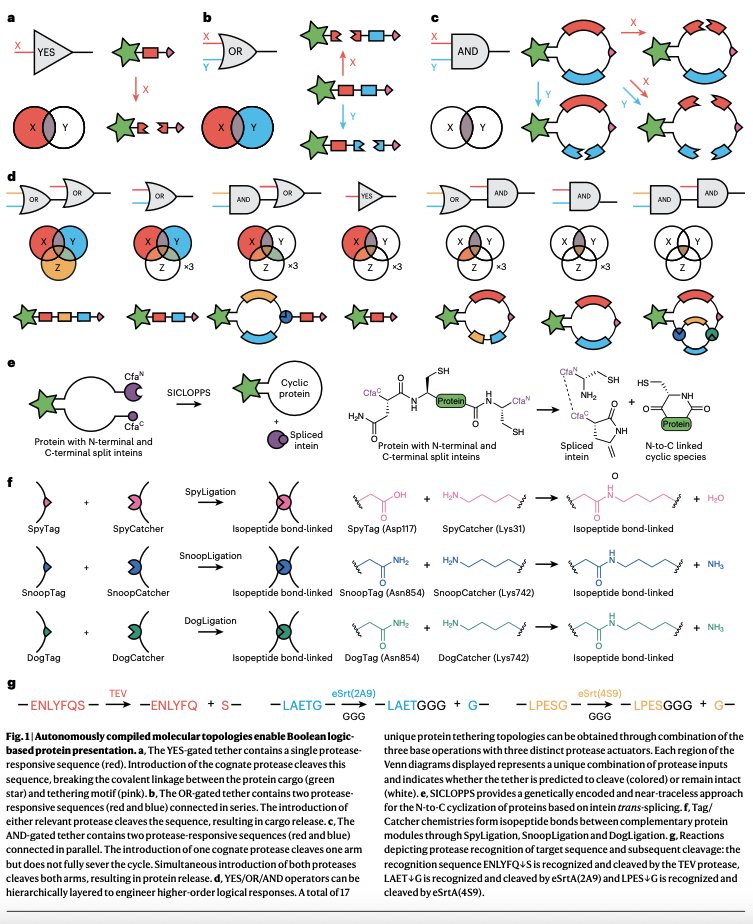
Say you wanted to make a protein that acts as a YES gate. That is, the protein releases some cargo (like a drug or other signal) only when a specific input is received.
You could build this YES gate by synthesizing a short protein (called a peptide) that has a particular sequence which is uniquely recognized by another protein, called a protease. There are many proteases found in nature. Each protease type recognizes a unique protein sequence and cleaves it, thus splitting the target in two.
A YES gate, then, can be made by building a peptide that has a protease recognition site. One end of the peptide is attached to a drug. The drug is only released when exposed to the protease.
An OR gate is also simple to make. Just create a peptide carrying two different protease sites in series, such that the addition of either protease will cleave the peptide and release the drug.
An AND gate is more difficult. To make it, you can instead attach the drug to two different peptides, each carrying a different protease recognition site. Then, anchor the ends of these two peptides to a scaffold. In this case, the drug will only be released if BOTH proteases are added.
Why am I writing about this? Because you can use these basic logic gate architectures to build all kinds of wonderful, “smart” materials and drug delivery vehicles. For a recent study, researchers built each of these logic gates, and also nested or stacked them together to build even more complex circuits (17 different logic architectures in total.)
They embedded these protein logic gates onto magnetic beads, hydrogels, and even living mammalian cells. These logical proteins are genetically encoded, modular, and could in principle respond to other signals, too; not just proteases but also light, small molecules, or mechanical forces.
Imagine a therapy for metastatic cancer that only releases its drug when two tumor-specific proteases, like MMP-9 and cathepsin B, are active. Or engineered immune cells that secrete cytokines only when both an infection marker and a metabolic stress signal are present.
Interesting to think about.

26
249
1,335
77,026
Daniel Guzmán-Zapata retweeted

30 Sep 2025
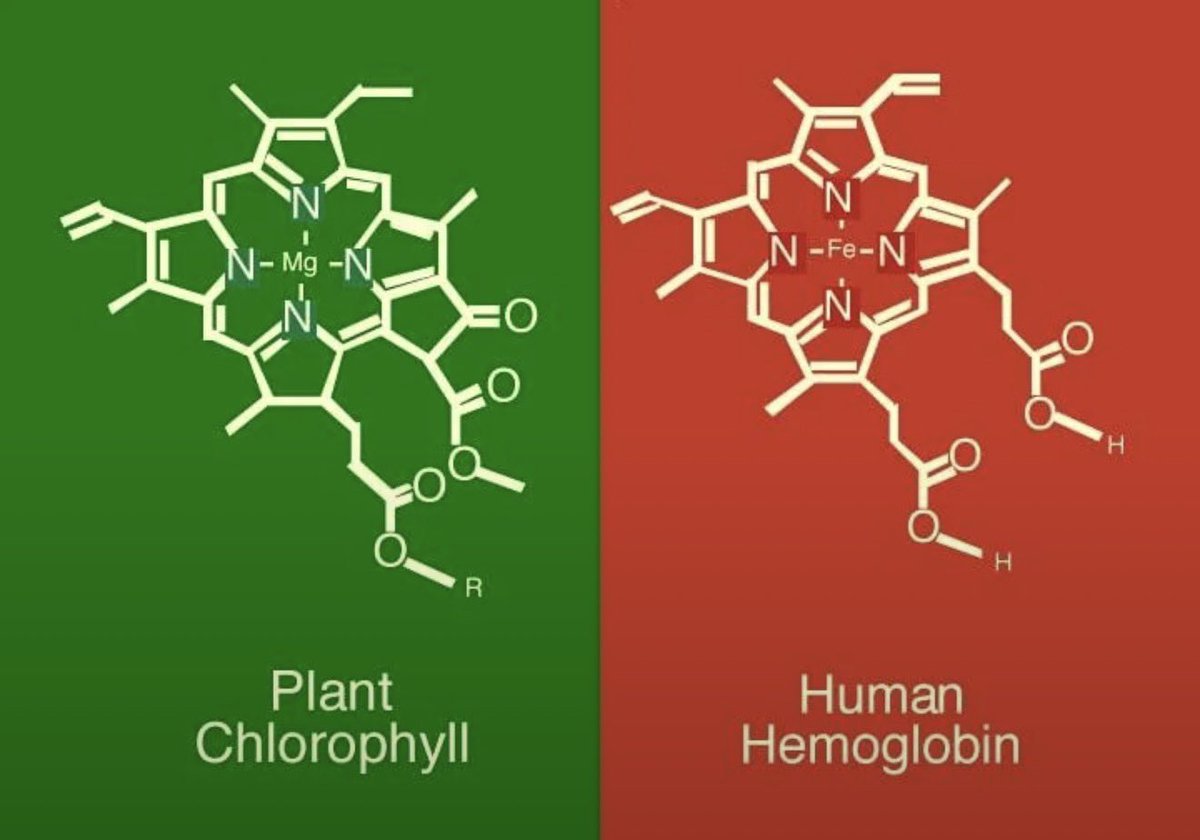
The incredible similarity between chlorophyll and haemoglobin - the difference being the magnesium vs iron core 🤯
108
545
3,596
162,245
Daniel Guzmán-Zapata retweeted

12 Apr 2025
🟢⚪️Camilo Zúñiga junto a Faber Gil viendo fútbol profesional colombiano en el Polideportivo sur de Envigado.
🖇️: @NacionalsPasion
30
19
368
137,595
Daniel Guzmán-Zapata retweeted

5 Nov 2024
Estamos viendo el momento exacto en que la célula T, una poderosa guerrera de nuestro sistema inmunológico, destruye una célula cancerosa mucho más grande que ella misma.
170
5,216
41,575
2,667,000
Daniel Guzmán-Zapata retweeted

2 Nov 2024
This is an excellent essay if you're interested in the intersection of AI x Bio.
1 Nov 2024

How can we condense 50-100 years of biological progress into 5-10 years?
I wrote a response to @DarioAmodei's essay, "Machines of Loving Grace." Most bottlenecks slowing biology today, I argue, are biophysical rather than computational.
LEVERS FOR BIOLOGICAL PROGRESS🔻

1
3
26
5,240
Daniel Guzmán-Zapata retweeted

3 Nov 2024
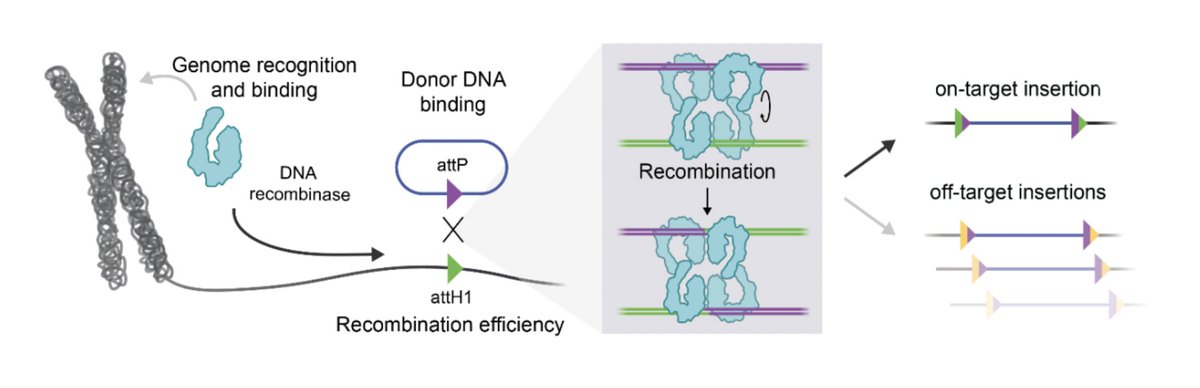
🧵In new work, we report a systematic engineering roadmap to optimize large serine recombinases (LSRs) for direct, site-specific insertion into the human genome 🧬. We achieved over 50% insertion efficiency and 97% genome-wide specificity, a 10X improvement over our previous work
9
81
474
110,300
Daniel Guzmán-Zapata retweeted
10 Jul 2024
Inside the Laboratory for Extraordinary Microbes
An estimated 0.001% of microbes have been discovered. And only a small percentage of those have ever been grown and studied in the lab. Imagine the molecular tools we might discover if scientists could work with a broader palette of lifeforms.
I had a lot of fun visiting @CultivariumFRO and writing about their work. Here are my favorite excerpts:
***
Humanity has discovered an estimated 0.001 percent of all microbes, and many of biology’s most useful tools have come from the “weird” ones.
Consider that scientists found one of the first restriction enzymes, used to “cut” and “stitch” DNA molecules together, in a pathogenic bacterium hiding out in the respiratory tracts of children, called Haemophilus influenzae. Alexander Fleming, upon returning from holiday, discovered penicillin antibiotics after a little-known mold destroyed his Streptococcus colonies. And an enzyme isolated from a microbe growing in the boiling waters of a Yellowstone National Park geyser enabled modern polymerase chain reaction, or PCR.
...
Cultivarium builds tools to grow, transform, and engineer “extraordinary” microbes: the salt lovers, heat tolerators, and geyser growers that have long been inaccessible to scientists. Studying such organisms might lead to better gene-editing tools or medicines. And regardless of whether Cultivarium’s engineering efforts succeed or fail, they give all their knowledge away for free, in the expectation that the next biological breakthrough will come from these overlooked microbes.
...
The trial-and-error nature of microbial cultivation has not changed much in the last century-and-a-half. In 1860, Louis Pasteur brewed the first liquid artificial culturemedium. His initial concoction consisted of a “yeast soup,” made by crushing cells with a mortar and pestle and mixing them with ash, candy sugar, and ammonium salts. He aimed to assemble a broth with all the elements needed to support growth; ammonium salts for nitrogen, sugar for carbon, and ash for vitamins. Microbes added to this mixture sometimes grew, but more often didn’t.
...
The Hubble Telescope and CERN both cost billions of dollars to build and required resources that far exceeded those available to an academic laboratory. Neither of these indispensable technologies turn the kind of profit that would attract venture capitalist funding, either. This is why scientific moonshots that could improve humanity, but which cost too much money to get up-and-running or are unlikely to return investments, often die at the idea stage. Focused research organizations (FROs)—Cultivarium included—are designed to fill that gap.
FROs tackle technical objectives that require resources greater than most academic laboratories can muster. They are not (at least initially) for-profit. Instead, FROs operate over a five-year period, make as much progress as they can, and then give away their findings or inventions to spur wider progress in a scientific field. This scientific structure is growing in popularity as people recognize the chasm between academic laboratories on the one hand and venture-backed startups on the other. @Convergent_FROs, the non-profit organization that helped spin up Cultivarium and six other FROs, matches scientific proposals with potential funders who want to make them happen.
4
19
128
16,224
Daniel Guzmán-Zapata retweeted

4 Mar 2024
𝗣𝗬𝗧𝗛𝗢𝗡 - 𝗧𝗵𝗲 𝗖𝗼𝗺𝗽𝗹𝗲𝘁𝗲 𝗠𝗮𝗻𝘂𝗮𝗹 ‼️
The Ultimate hand Book for Beginners
Want it free?
- Must follow
- Like and Repost
- Reply ‘python’
I’ll DM you a copy.
#python #languages #DataScience #DataScientists

145
100
176
16,160
Daniel Guzmán-Zapata retweeted

2 Mar 2024
𝗣𝗬𝗧𝗛𝗢𝗡 - 𝗧𝗵𝗲 𝗖𝗼𝗺𝗽𝗹𝗲𝘁𝗲 𝗠𝗮𝗻𝘂𝗮𝗹 ‼️
The Ultimate hand Book for Beginners
Want it free?
- Must follow
- Like and Repost
- Reply ‘python’
I’ll DM you a copy.
#python #languages #DataScience #DataScientists

ALT 𝗣𝗬𝗧𝗛𝗢𝗡 - 𝗧𝗵𝗲 𝗖𝗼𝗺𝗽𝗹𝗲𝘁𝗲 𝗠𝗮𝗻𝘂𝗮𝗹 ‼️ The Ultimate hand Book for Beginners Want it free? - Must follow - Like and Repost - Reply ‘python’ I’ll DM you a copy. #python #languages #DataScience #DataScientists
381
292
517
54,358
Daniel Guzmán-Zapata retweeted

28 Jan 2024
✦ Data Science
✦ Python
✦ Artificial Intelligence
✦ AWS Certified
✦ Cloud
✦BIG DATA
✦ Data Analytics
✦ MBA
✦ Machine Learning
✦ Ethical Hacking
𝐀𝐧𝐝 𝐭𝐡𝐞 𝐛𝐞𝐬𝐭 𝐩𝐚𝐫𝐭? 𝐈𝐭'𝐬 𝐚𝐥𝐥 𝐚𝐛𝐬𝐨𝐥𝐮𝐭𝐞𝐥𝐲 𝐅𝐑𝐄𝐄 𝐨𝐟 𝐜𝐨𝐬𝐭!🚀
𝐄𝐚𝐬𝐲 𝐬𝐭𝐞𝐩𝐬 to grab your share:
1. Follow me for DM
2. Like and Repost
3. Comment "Share" for your complimentary copies!
2,099
1,528
3,241
431,266