
PhD. Data Scientist. Humanist. Stats, machine learning, deep learning, AI, data science educator, community builder. She/her.
- Tweets 8,081
- Following 2,796
- Followers 1,899
- Likes 6,142




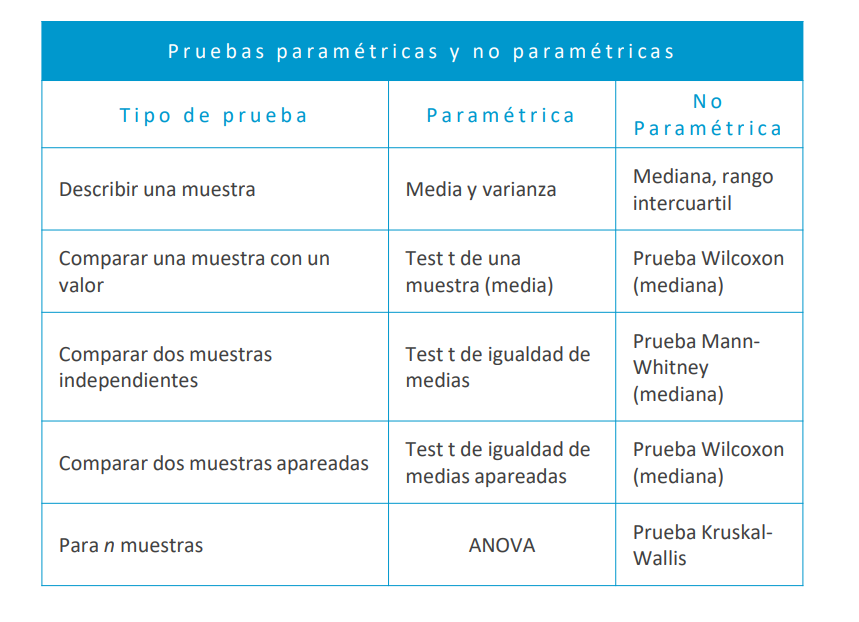






























ALT China’s quantum computer completed a task in 4 minutes that would literally take a supercomputer billions of years. Chinese researchers have achieved a monumental breakthrough in quantum computing with their prototype, Jiuzhang. By counting 76 photons through Gaussian boson sampling, the system completed a calculation in four minutes that would take a traditional supercomputer billions of years. This achievement shatters the previous classical record of five photons, demonstrating how an intricate array of lasers and mirrors can outperform traditional silicon bits in complex processing tasks. This milestone is more than just a speed record; it proves the viability of photon-based quantum mechanics in solving real-world challenges. From revolutionizing quantum chemistry to laying the groundwork for a secure, large-scale quantum internet, the principles of superposition and entanglement are moving from theoretical physics into functional technology.





