
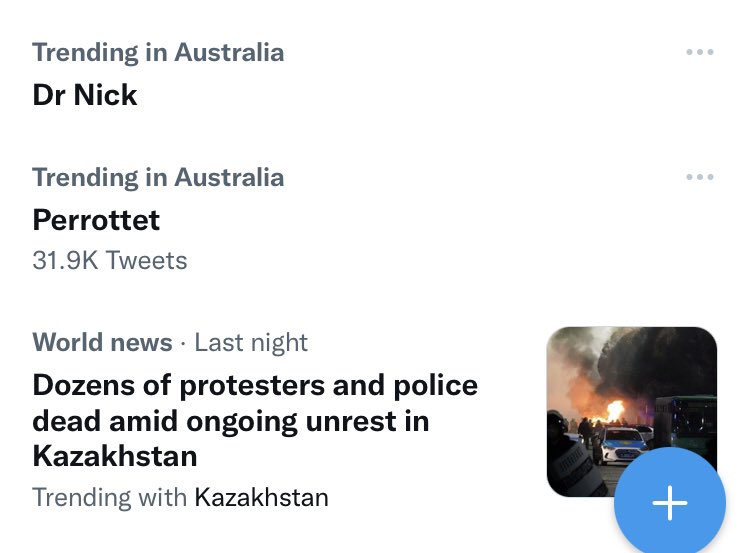
Mostly lurking.
Joined January 2011
- Tweets 2,653
- Following 912
- Followers 411
- Likes 3,205
44 Photos and videos













Marco Fahmi retweeted

26 May 2024
✍️Dorothea Strecker, Heinz Pampel, Rouven Schabinger and Nina Leonie Weisweiler, explore how common data repository shutdowns are and suggest what can be done to ensure data preservation in the long-term.
#OpenData wp.me/p4m9em-cPR
8
4
2,898
Marco Fahmi retweeted

26 May 2024
I am really troubled by the proposal from the Tony Blair Institute for a "National Data Trust" (NDT) for health data, particularly by the idea that the next government might actually go for it.
institute.global/insights/po…
2
17
31
5,242
Marco Fahmi retweeted

16 Apr 2024
“When we have a technology that treats something as simple and fundamental as our name as an error, it robs us of our personhood" theatlantic.com/technology/a…
2
2
333
Marco Fahmi retweeted
26 Dec 2023
Transformative governance of innovation ecosystems sciencedirect.com/science/ar…

2
7
772
Marco Fahmi retweeted

Congratulations team NCYSUR who is being awarded a 1.5 million dollar @nhmrc ideas grant, led by Dr Daniel Stjepanovic, @tianzesun , A/Prof Phong Thai, and Prof. @DavidHammondPhD.

2
5
12
838

15 Dec 2023
RT @CREtobacco: Congratulations 🎉 to CRE researcher Dr Carmen Lim @Cwernlim who has been awarded $660,000 by the @nhmrc to develop a progra…
3



Behind the hype of generative AI, large companies are struggling to deploy the new technology — hitting cost and data management hurdles that are leaving many of their generative AI projects stuck in pilot phase. trib.al/zwRlIVl
2
11
12,077
As adoption of generative AI grows, providers are hoping that greater transparency about how they do and don't use customers' data will increase those clients' trust in the technology. trib.al/tCr3DVd
1
1
7
12,064
Marco Fahmi retweeted

18 Aug 2023
There's a resurgence of interest in fine tuning LLMs
I've yet to see a successful public use case where fine tuning > prompting.
But here's where I see fine tuning *mattering*:
First, fine tuning is for teaching an LLM specific tasks or behaviors
Not teaching an LLM new knowledge. For new knowledge, use Retrieval (store your data in an outside database and strategically pull the right chunks in to give the LLM context to your question)
But even in teaching LLMs specific tasks or behaviors - here's the catch...
LLMs are remarkably good at picking up tasks and behaviors from just a good prompt
THIS is what makes LLMs mind blowing after all
So that begs the question.
Where is fine tuning actually helpful?
Some use cases I could see developing are teaching LLMs tasks that are exceptionally difficult to describe, or fit into ~10 examples you can add to a prompt.
One way to think about this: if it would take someone a few weeks doing a task to 'master it' instead of being able to read training materials and get the picture...
That *may* be a use case for fine tuning
But proceed with caution
To truly teach an LLM a new behavior or task, you'll need to treat this like a machine learning project, not just throwing examples in and getting magic in return (which it still blows my mind that ChatGPT does this so well for us).
Things like:
- Dataset design
- Training and test data
- Overfitting
more as the tooling around fine tuning gets more sophisticated
The other obvious use case is cost.
If you can get a super small language model to do a task instead of GPT-4, there's meaningful cost savings there.
And if you're using a language model to do large scale tasks like triaging your customer support inbox, or analyzing public data for insights
The costs can add up.
But if you're wondering where the heck to invest in fine tuning...
My answer at the moment for most businesses is still:
Make sure you can't do it with prompts.
38
56
451
164,113
Marco Fahmi retweeted

17 Aug 2023
📢NEW PAPER!
Where @davidthewid, @sarahbmyers & I unpack what Open Source AI even is.
We find that the terms ‘open’ & ‘open source’ are often more marketing than technical descriptor, and that even the most 'open' systems don't alone democratize AI 1/
papers.ssrn.com/sol3/papers.…


67
614
1,791
634,910
Marco Fahmi retweeted

7 Aug 2023
New updates on Bellingcat's #github this week. The 'whisperbox' API receives audio or video URLs and returns the video transcripts using OpenAI's Whisper model. Designed by Bellingcat discord member github.com/fspoettel
Find the tool at: github.com/bellingcat/whispe…
3
17
94
67,628
5 Aug 2023
Opinion Paper: “So what if ChatGPT wrote it?” Multidisciplinary perspectives on opportunities, challenges and implications of generative conversational AI for research, practice and policy sciencedirect.com/science/ar…
1
67
Marco Fahmi retweeted

27 Jul 2023
Best poster award

120
3,288
27,965
2,621,491
Marco Fahmi retweeted

26 Jul 2023
🗺️ NEW! Can journalists rely on #AI chatbots to successfully geolocate an image?
Investigative journalism group @bellingcat conducted 3️⃣ tests to examine the geolocation capabilities of #Bing and #Bard.
Reporter @DennisKovtun broke down the findings: ⬇️ buff.ly/3O7PmFu
7
14
2,583
Marco Fahmi retweeted

26 Jul 2023
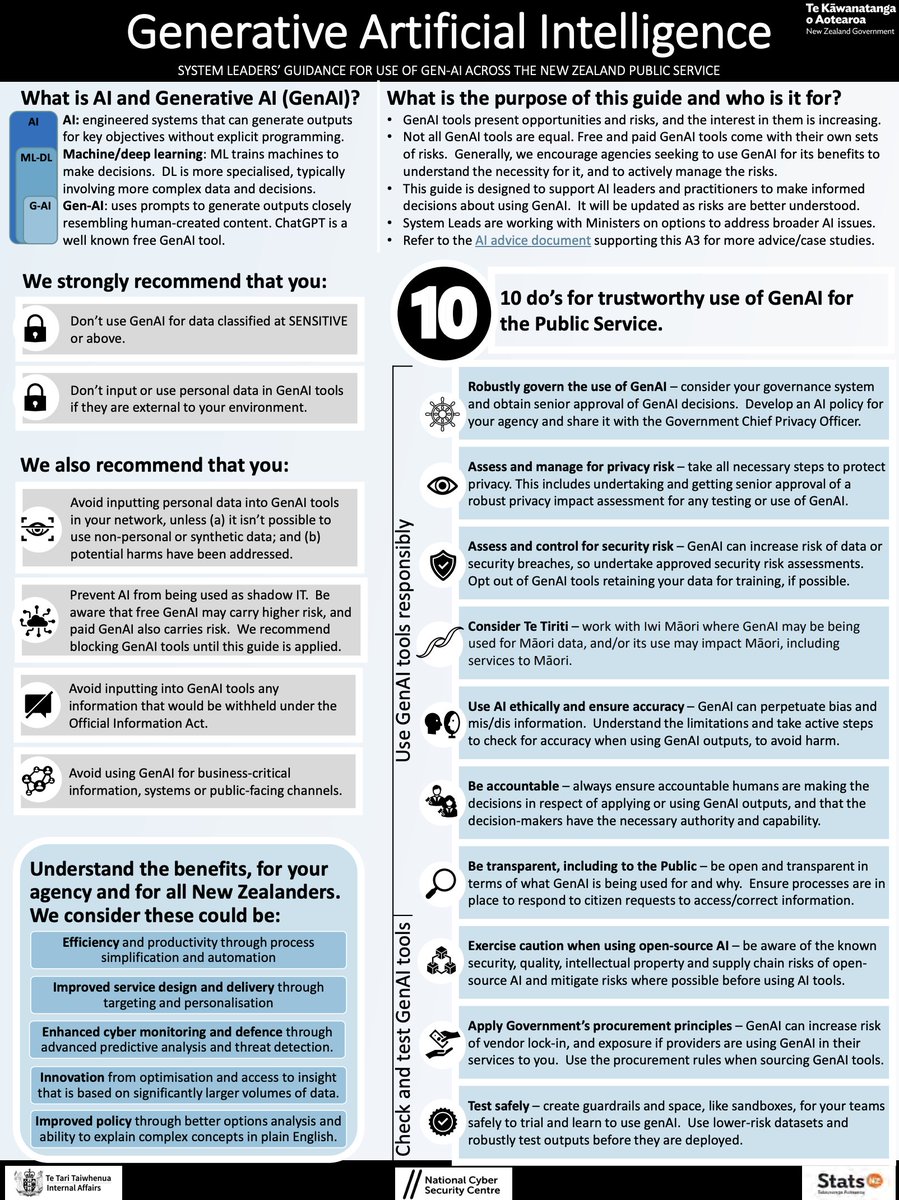
Department of Internal Affairs has put out some guidance today on use of generative AI in the public sector...
5
19
38
8,922
23 Jul 2023
What will the federal government do with generative AI? nextgov.com/artificial-intel… via @Nextgov
3
34
Marco Fahmi retweeted

21 Jul 2023
US judge finds flaws in artists' lawsuit against #AI companies reuters.com/legal/litigation… #StableDiffusion #genAI #AIlaw #IPlaw #webscraping #openweb
Andersen et al v. Stability AI Ltd. et al dockets.justia.com/docket/ca… courtlistener.com/docket/667…

ALT Andersen, Kelly McKernan and Karla Ortiz said in their January complaint that Stability "scraped" billions of images from the internet to teach its Stable Diffusion text-to-image system to create its own images, including some in their styles. They accused the company of infringing their copyrights by using their work without permission. … The judge also said the artists were unlikely to succeed on their claim that images generated by the systems based on text prompts using their names violated their copyrights. "I don't think the claim regarding output images is plausible at the moment, because there's no substantial similarity" between images created by the artists and the AI systems, Orrick said.
2
1
394
Marco Fahmi retweeted

18 Jul 2023
I “jailbroke” a Google Nest Mini so that you can run your own LLM’s, agents and voice models.
Here’s a demo using it to manage all my messages (with help from @onbeeper)
🔊 on, and wait for surprise guest!
I thought hard about how to best tackle this and why, see 🧵
365
2,451
13,828
1,698,176