
PhD in progress
Joined April 2020
- Tweets 43
- Following 489
- Followers 137
- Likes 745
11 Photos and videos





Pinned Tweet

Feb 16
Why repetition works so well is still an open question. There's a lot to uncover about training dynamics of SFT, and we hope this is a useful data point.
Joint work with co-authors @Sagar_Vaze @TiRune @y_m_asano
Paper: arxiv.org/abs/2602.11149
Code: github.com/dkopi/data-repeti…
1
1
19
1,369
Dawid Kopiczko retweeted

Apr 30
🎉[openings] I’m hiring postdoctoral researchers to join our @FunAILab at UTN through the Alexander von Humboldt Research Fellowship (@AvHStiftung), via the Henriette Herz Scouting Programme.
As a Henriette Herz Scout, I can nominate outstanding international researchers for this fellowship route. I’m especially keen to hear from candidates working on multimodal learning, video and image pretraining, and post-training.
Fellows would be hosted in our lab at UTN and work closely with us on these topics.
Key requirements:
* finished your doctoral studies less than 4 years ago or will finish in the next 6 months
* did not live/work in Germany in the last 10 years
* applications from female, trans* and/or non-binary candidates are highly encouraged!
Interested? Please send a short note with your CV, PhD year, current affiliation, 2–3 key publications, and a few lines on how your work connects.
Please share! 🔀

1
23
61
5,763
Feb 16
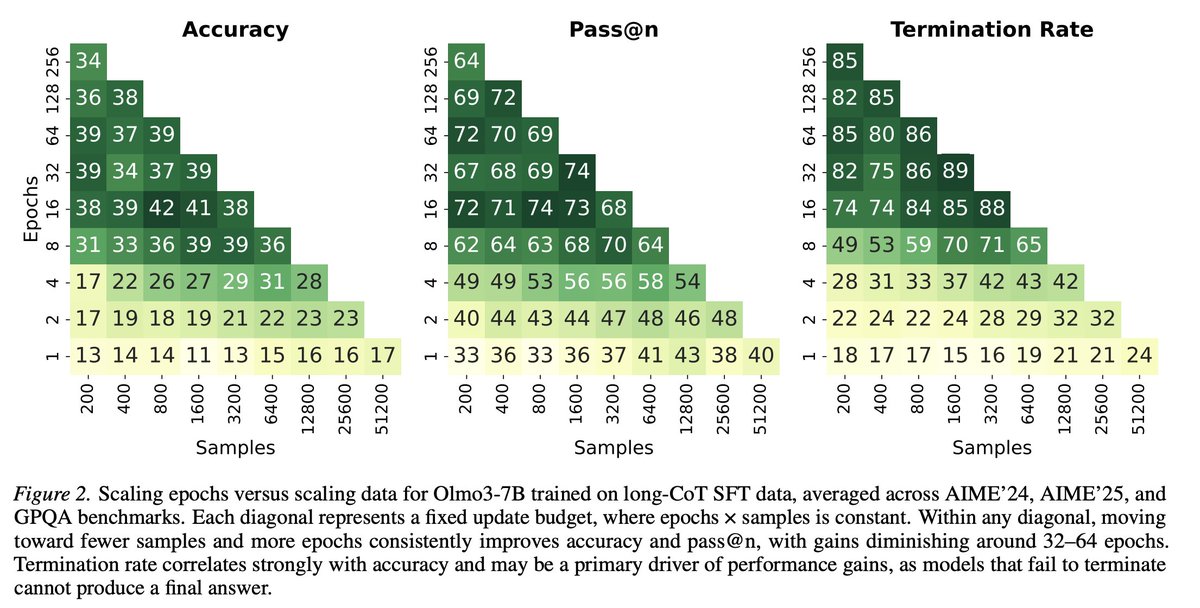
Common knowledge in ML: more unique training data → better generalization. Turns out this doesn't hold for long-CoT SFT.
Under a fixed update budget, repeating a small dataset multiple times beats training on more unique samples. And it's not even close.
3
26
310
20,078
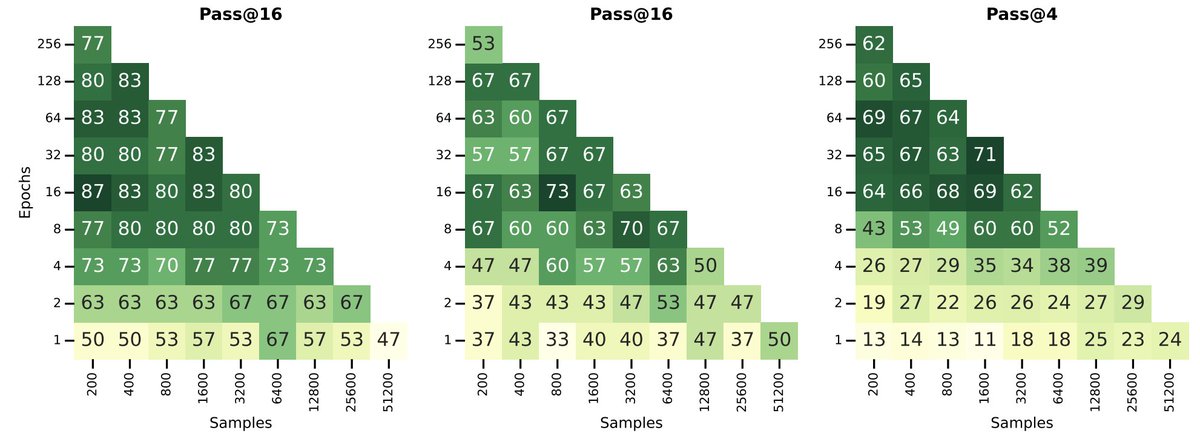
Feb 16
When training Olmo-3 7B on Dolci SFT dataset, 16 epochs on a random subset of 400 samples leads to:
80% (pass@16) on AIME'24,
63% on AIME'25,
62% on GPQA;
while one epoch on over 51K samples yields:
47% -- AIME'24,
50% -- AIME'25,
24% -- GPQA.
2
18
1,294
Feb 16
(too late to edit, config matching mentioned results is: "16 epochs on a random subset of 3.2K* samples")
16 epochs on 400 samples yields:
83% -- AIME'24,
63% -- AIME'25,
66% -- GPQA.
69
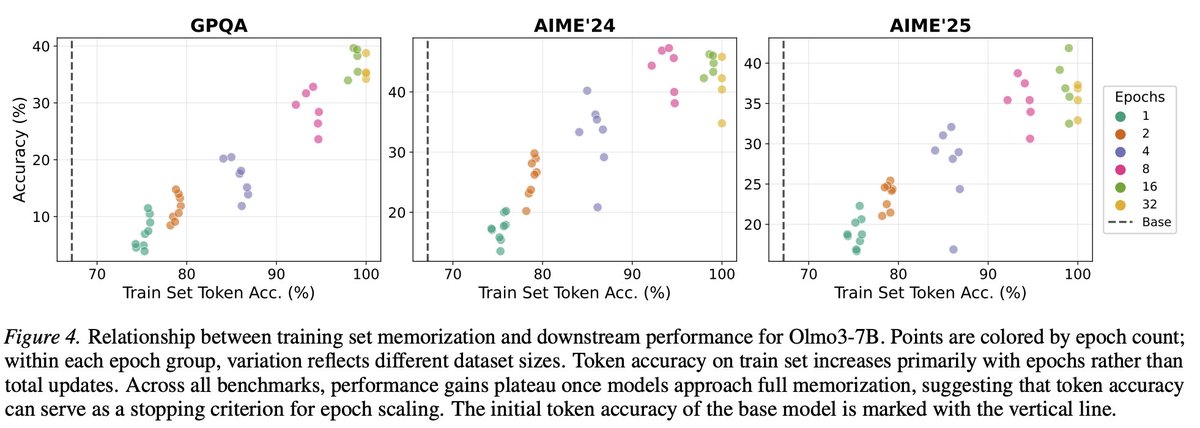
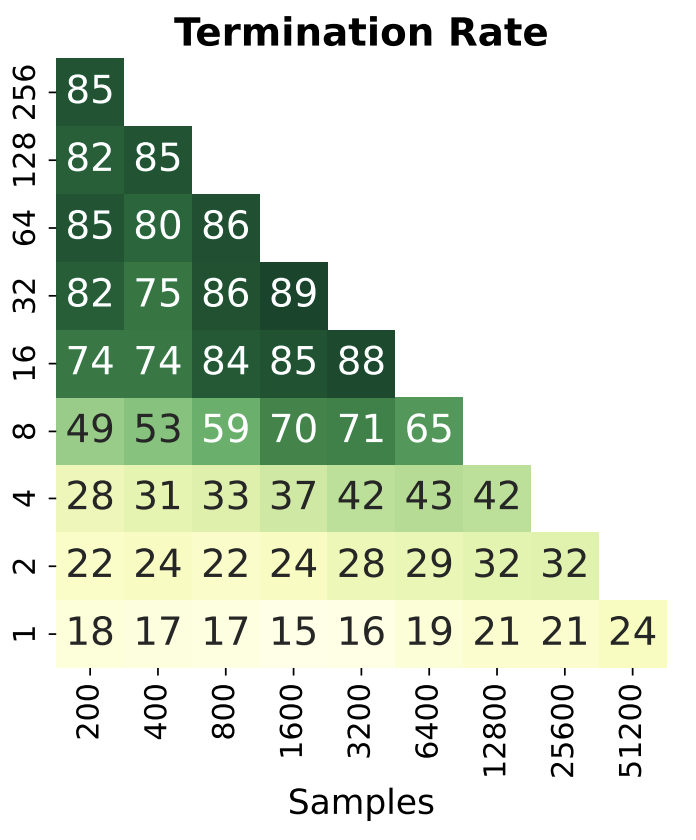
Feb 16
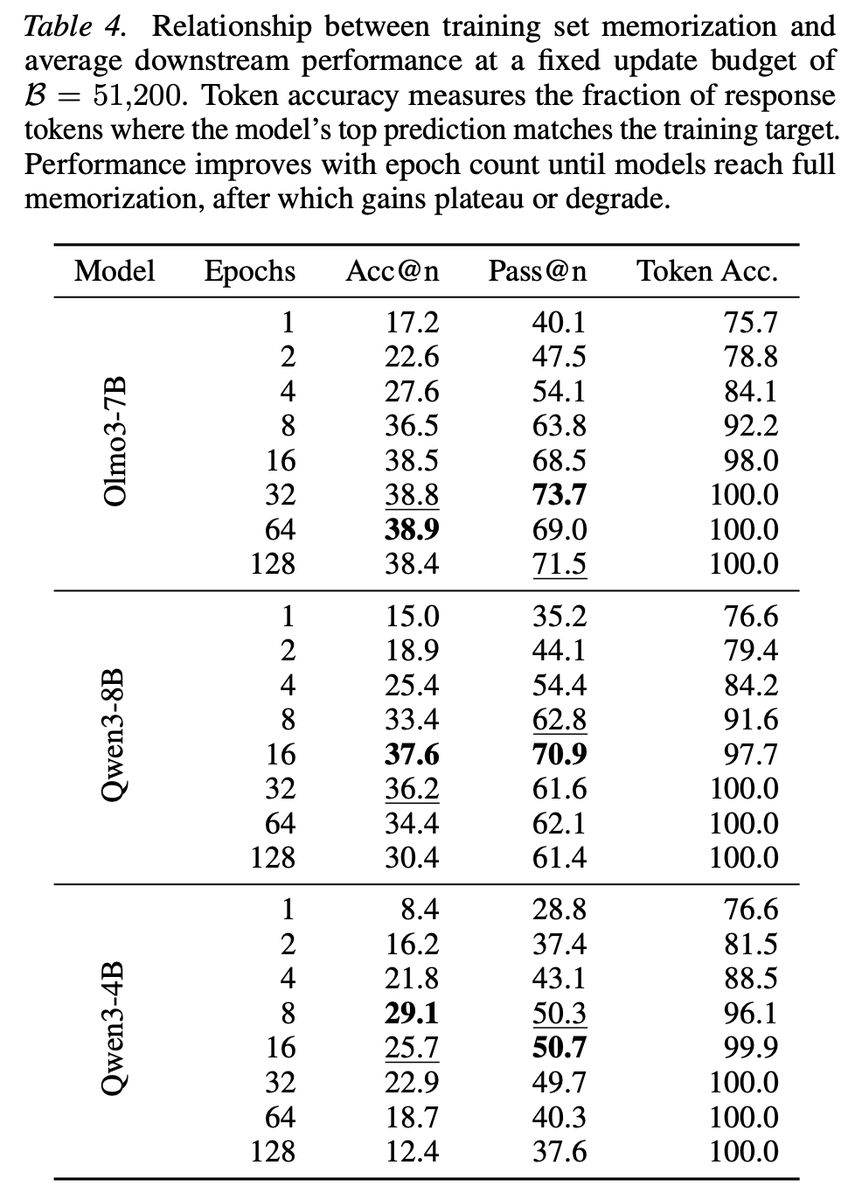
So when does repetition stop helping?
Turns out token accuracy on training dataset is a pretty reliable signal for this. Once the model hits ~100% token accuracy on the training set, additional epochs don't bring further gains, which makes it a nice practical stopping criterion.
1
13
871
Feb 16
Why repetition works so well is still an open question. There's a lot to uncover about training dynamics of SFT, and we hope this is a useful data point.
Joint work with co-authors @Sagar_Vaze @TiRune @y_m_asano
Paper: arxiv.org/abs/2602.11149
Code: github.com/dkopi/data-repeti…
1
1
19
1,369
Dawid Kopiczko retweeted

17 Oct 2025
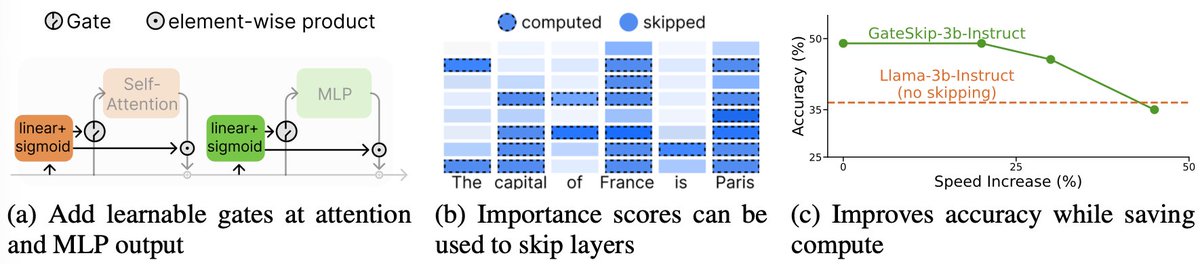
Introducing GateSkip, a new method for skipping layers in LLMs.
GateSkip adds gates at the output of each Attn/MLP module. The gates learn to compress a module’s output to the residual stream. At inference, they estimate layer importance, skipping unneeded layers per token.
5
3
7
830
Dawid Kopiczko retweeted

15 Jul 2025
Introducing cache steering – a new method for implicit behavior steering in LLMs
Cache steering is a lightweight method for guiding the behavior of language models by applying a single intervention to their KV-cache. We show how it can be used to induce reasoning in small LLMs.

1
5
13
3,390
Dawid Kopiczko retweeted
29 May 2024
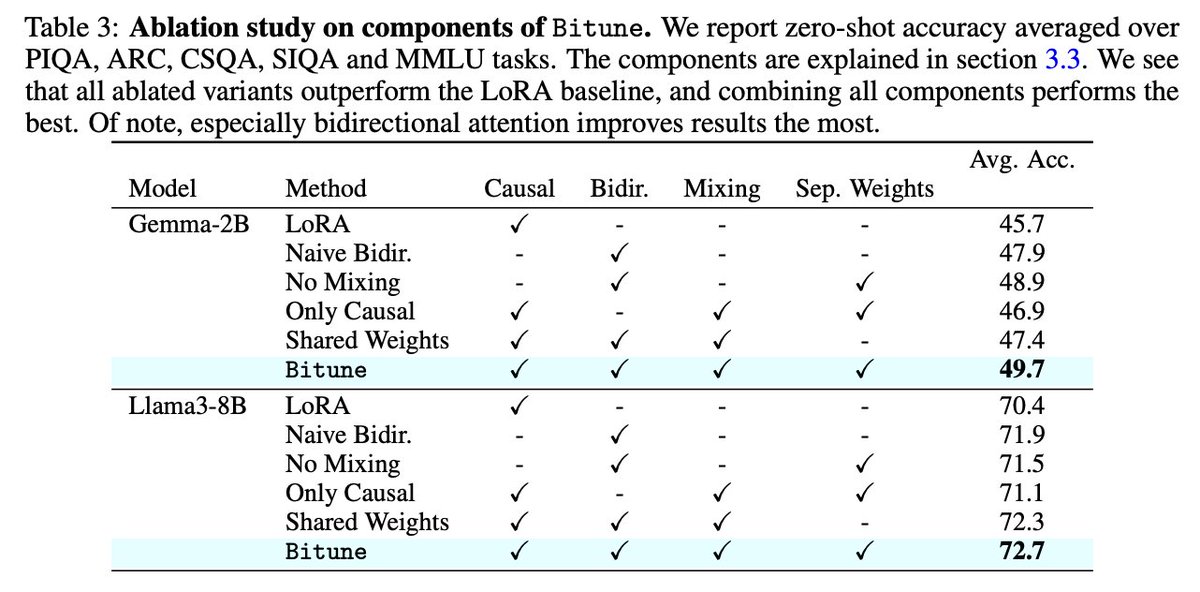
Today we introduce Bidirectional Instruction Tuning (Bitune). It's a new way of adapting LLMs for the instruction->answering stage.
It allows the model to process the instruction/question with bidirectional attention, while the answer generation remains causal.

4
21
152
33,944
Dawid Kopiczko retweeted
17 Jan 2024
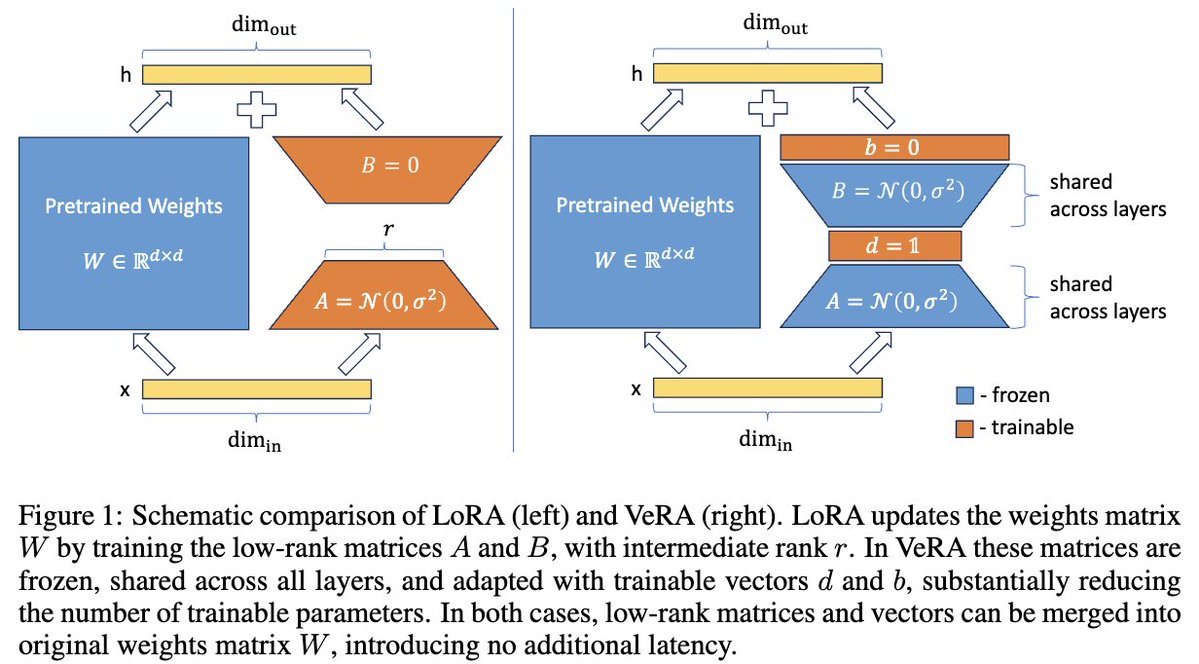
Very happy to announce that VeRA is accepted at @iclr_conf with scores 8,8,8,5!
VeRA makes LoRA ~10x more parameter efficient while retaining the same performance & also works for vision!
Paper: arxiv.org/abs/2310.11454
Our very light-weight webpage😏: dkopi.github.io/vera/

VeRA: Vector-based Random Matrix Adaptation
paper page: huggingface.co/papers/2310.1…
Low-rank adapation (LoRA) is a popular method that reduces the number of trainable parameters when finetuning large language models, but still faces acute storage challenges when scaling to even larger models or deploying numerous per-user or per-task adapted models. In this work, we present Vector-based Random Matrix Adaptation (VeRA), which reduces the number of trainable parameters by 10x compared to LoRA, yet maintains the same performance. It achieves this by using a single pair of low-rank matrices shared across all layers and learning small scaling vectors instead. We demonstrate its effectiveness on the GLUE and E2E benchmarks, and show its application in instruction-following with just 1.4M parameters using the Llama2 7B model.

14
117
636
76,324