
Deep Learning Researcher Nvidia - Efficiency/Numerics
Joined May 2009
- Tweets 512
- Following 217
- Followers 680
- Likes 477
21 Photos and videos



Tijmen Blankevoort retweeted

Feb 16
Why repetition works so well is still an open question. There's a lot to uncover about training dynamics of SFT, and we hope this is a useful data point.
Joint work with co-authors @Sagar_Vaze @TiRune @y_m_asano
Paper: arxiv.org/abs/2602.11149
Code: github.com/dkopi/data-repeti…
1
1
19
1,369
Tijmen Blankevoort retweeted

15 Dec 2025
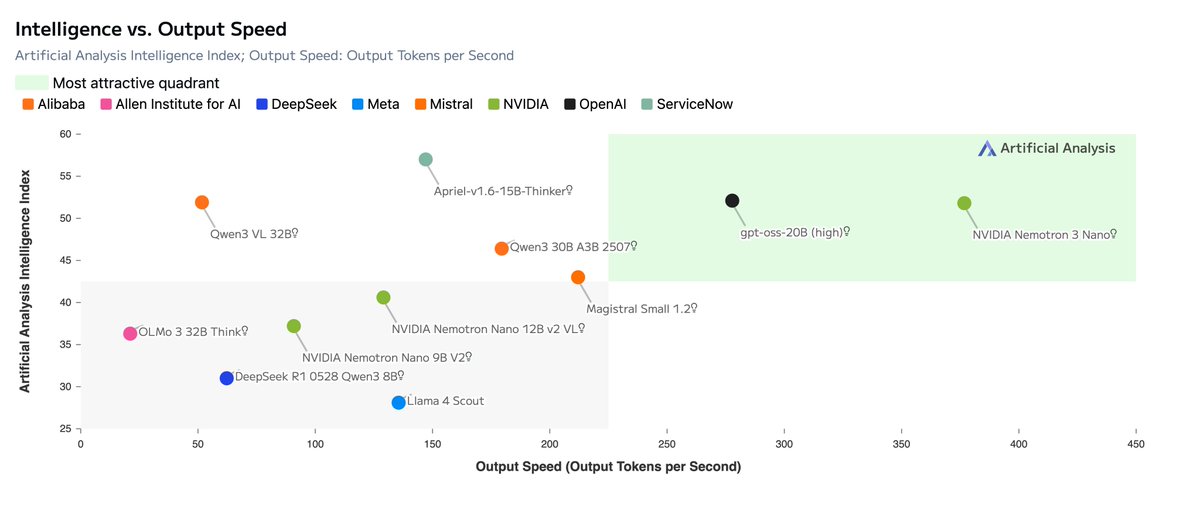
Today, @NVIDIA is launching the open Nemotron 3 model family, starting with Nano (30B-3A), which pushes the frontier of accuracy and inference efficiency with a novel hybrid SSM Mixture of Experts architecture. Super and Ultra are coming in the next few months.
41
221
1,238
505,712

30 Nov 2025
Looking for cracked full-time Deep Learning researchers on Efficiency, Quantization and Sparsity. Join our world-class applied deep learning research team at Nvidia. Team creates the Nemotron models, we influence the hardware with our research. Shoot me a message! Am at Neurips!
2
1
10
1,742
13 Jul 2025
I recently made the news because of a doc I wrote in Meta’s GenAI organization. ‘The Information’ wrote about it as if I did a big raging ‘mic drop’ before leaving the company. Nothing could be further from the truth - so setting the record straight here. open.substack.com/pub/blanke…
2
3
80
18,354
Tijmen Blankevoort retweeted

30 Jan 2025
So You Think your @iclr_conf rejection was surprising?
We nearly fell out of our chairs when our 7.25 avg rating (10,8,6,5 -- i.e. top 4%) Bitune paper got rejected 😅.
It's not like new points or problems surfaced... Just ¯\_(ツ)_/¯ I guess?
Sharing this so that especially younger researchers also see that the review process is somewhat random and can be _very_ frustrating - for all of us :). Oh well! Onwards!

11
26
363
63,363
Tijmen Blankevoort retweeted

10 Oct 2024
🪩The @stateofai 2024 has landed! 🪩
Our seventh installment is our biggest and most comprehensive yet, covering everything you *need* to know about research, industry, safety and politics.
As ever, here's my director’s cut ( video tutorial!) 🧵
31
305
1,136
440,597
3 Jun 2024
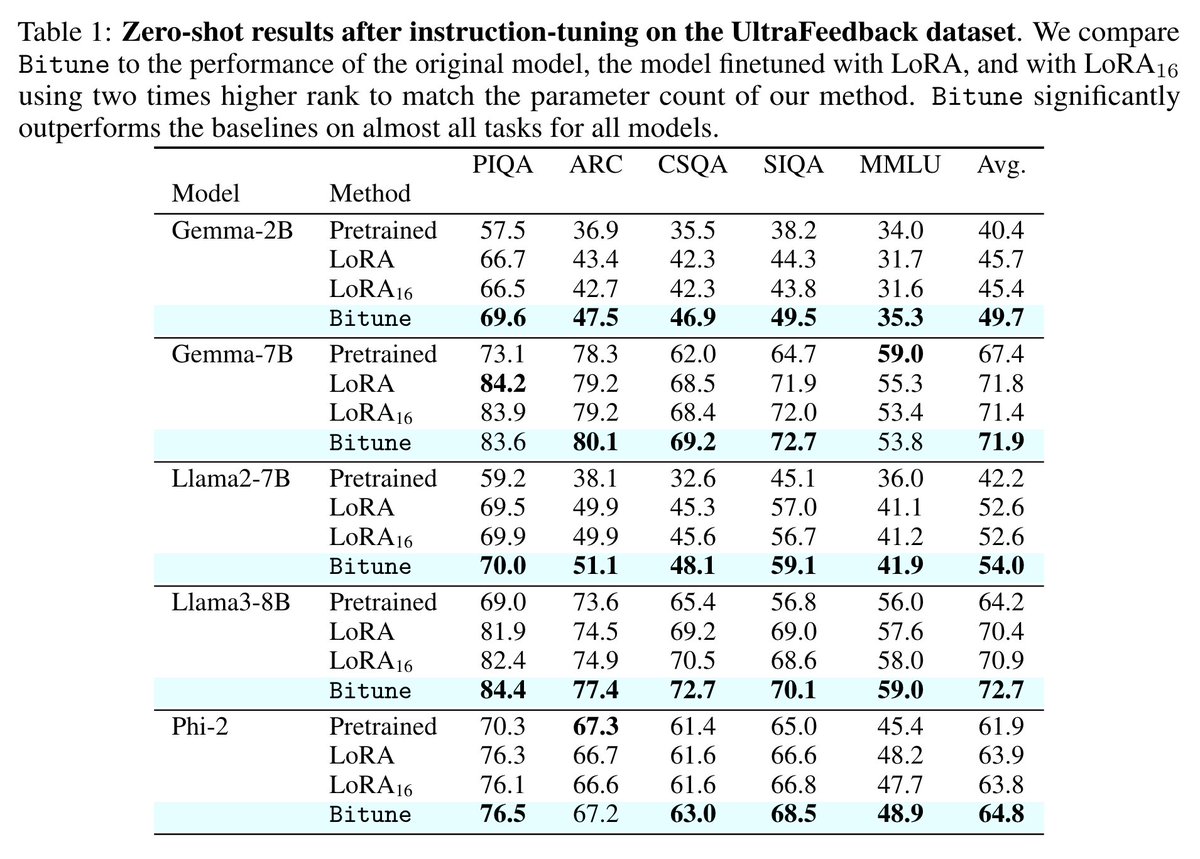
Our new Bitune method is out - improving results on instruction-tuning! We add bidirectional attention to a decoder-only architecture, and concoct an IT-specific PEFT method for Q&A and instruction following settings
1
4
15
2,145
3 Jun 2024
The algorithm is very simple, and provides better results across the boards at very little cost. We see gains of around 1-5% for many common models in zero-shot task eval
1
3
652
3 Jun 2024
Check out our amazing website: dkopi.github.io/bitune/ The paper: arxiv.org/abs/2405.14862 And the code: github.com/dkopi/bitune This is work from the great @dawkopi and @y_m_asano, and yours sincerely
1
466
Tijmen Blankevoort retweeted
29 May 2024
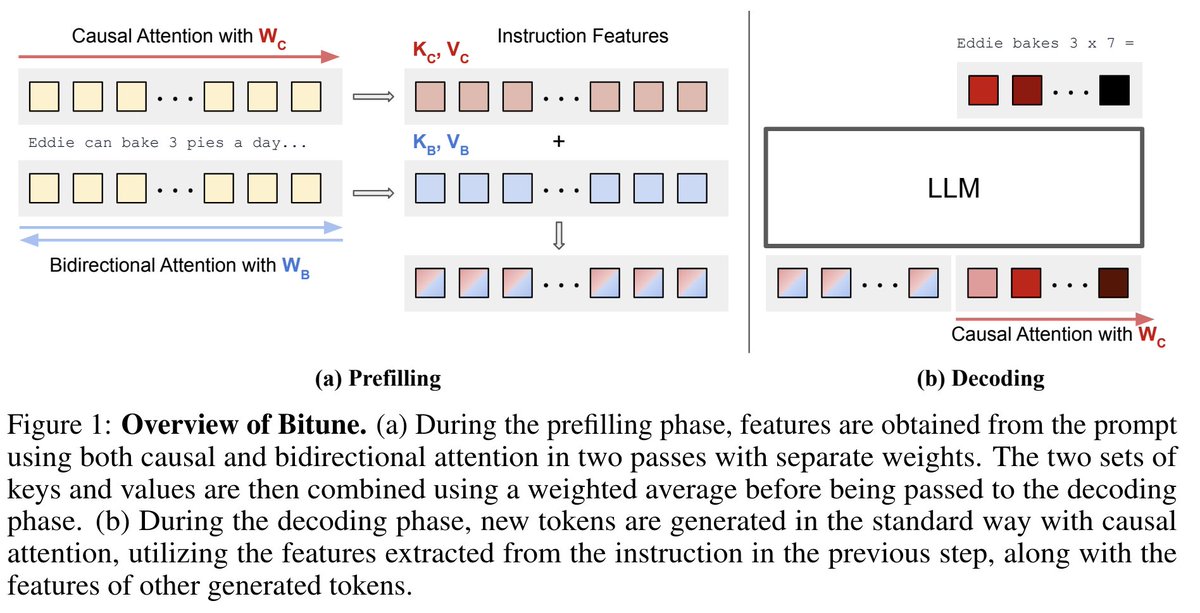
Today we introduce Bidirectional Instruction Tuning (Bitune). It's a new way of adapting LLMs for the instruction->answering stage.
It allows the model to process the instruction/question with bidirectional attention, while the answer generation remains causal.

4
21
152
33,944
Tijmen Blankevoort retweeted
16 May 2024
Another week, another release:
Our PEFT method VeRA (LoRA but 10-100x less parameters thanks to random projections) is now on HF PEFT!
so now's a good time to `pip install peft`
Thx to @alexfmckinney @BenjaminBossan @dkopi @TiRune
huggingface.co/docs/peft/pac…

2
18
66
5,356
Tijmen Blankevoort retweeted

22 Mar 2024
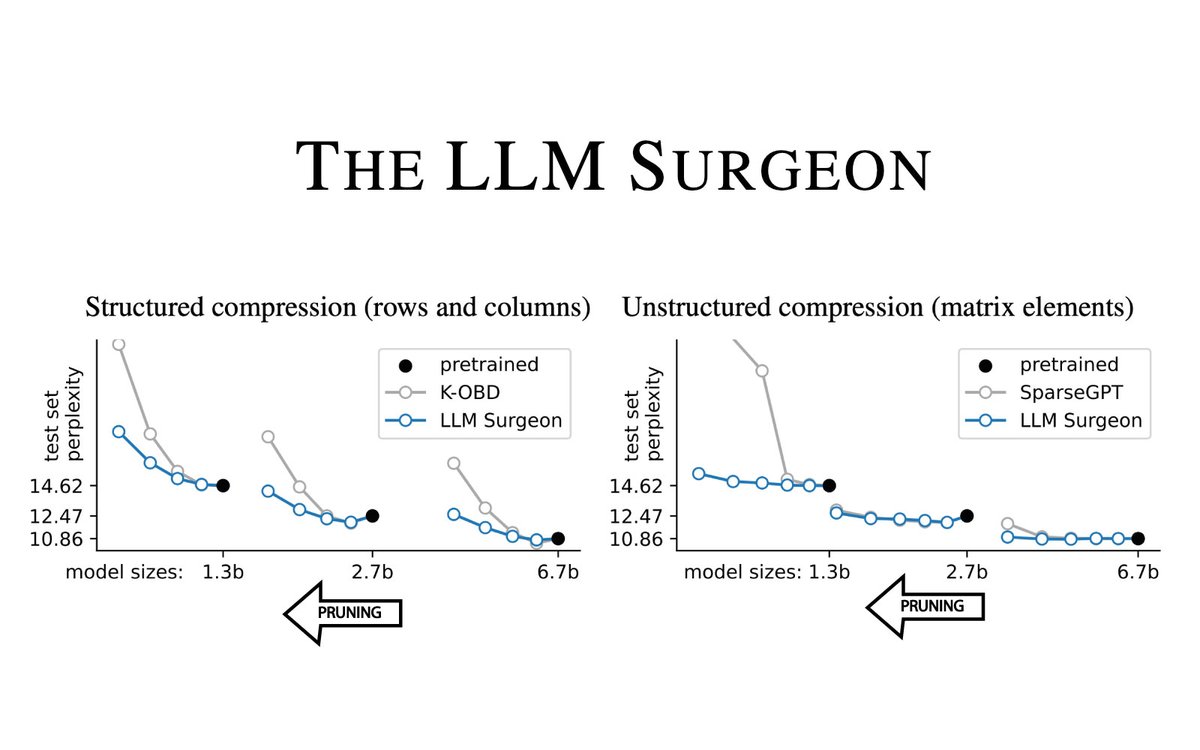
Our paper, "The LLM Surgeon," accepted at ICLR 2024, achieves SOTA in LLM pruning in all unstructured, semi-structured, and the most challenging but most effective structured pruning that removes entire matrix rows/columns.
Happy to share that code is now publicly available.
Code: github.com/Qualcomm-AI-resea…
Thread: twitter.com/tychovdo/status/…
Paper: arxiv.org/abs/2312.17244
w/ @mnagel87, @martvanbaalen, @y_m_asano, @TiRune

The LLM Surgeon
paper page: huggingface.co/papers/2312.1…
State-of-the-art language models are becoming increasingly large in an effort to achieve the highest performance on large corpora of available textual data. However, the sheer size of the Transformer architectures makes it difficult to deploy models within computational, environmental or device-specific constraints. We explore data-driven compression of existing pretrained models as an alternative to training smaller models from scratch. To do so, we scale Kronecker-factored curvature approximations of the target loss landscape to large language models. In doing so, we can compute both the dynamic allocation of structures that can be removed as well as updates of remaining weights that account for the removal. We provide a general framework for unstructured, semi-structured and structured pruning and improve upon weight updates to capture more correlations between weights, while remaining computationally efficient. Experimentally, our method can prune rows and columns from a range of OPT models and Llamav2-7B by 20%-30%, with a negligible loss in performance, and achieve state-of-the-art results in unstructured and semi-structured pruning of large language models.

1
15
97
13,366
Tijmen Blankevoort retweeted

7 Mar 2024
Today, with @Tim_Dettmers, @huggingface, & @mobius_labs, we're releasing FSDP/QLoRA, a new project that lets you efficiently train very large (70b) models on a home computer with consumer gaming GPUs. 1/🧵
answer.ai/posts/2024-03-06-f…
79
630
3,434
444,896
Tijmen Blankevoort retweeted

26 Feb 2024
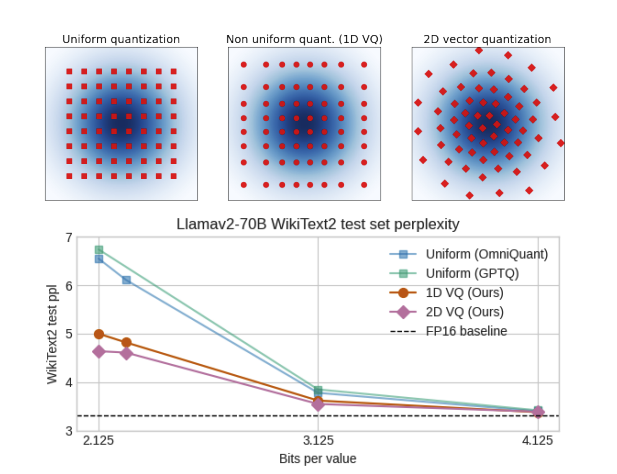
Our work on Vector Quantization for SOTA size vs accuracy trade-offs in LLMs is on Arxiv!
Thanks co-authors Andrey Kuzmin, @mnagel87, @pcoranje, Cedric Bastoul, Eric Mahurin, @TiRune and Paul Whatmough for their hard work
And thanks to @_akhaliq for amplifying!
Qualcomm presents GPTVQ
The Blessing of Dimensionality for LLM Quantization
show that the size versus accuracy trade-off of neural network quantization can be significantly improved by increasing the quantization dimensionality. We propose the GPTVQ method, a new fast method for post-training vector quantization (VQ) that scales well to Large Language Models (LLMs). Our method interleaves quantization of one or more columns with updates to the remaining unquantized weights, using information from the Hessian of the per-layer output reconstruction MSE. Quantization codebooks are initialized using an efficient data-aware version of the EM algorithm. The codebooks are then updated, and further compressed by using integer quantization and SVD-based compression. GPTVQ establishes a new state-of-the art in the size vs accuracy trade-offs on a wide range of LLMs such as Llama-v2 and Mistral. Furthermore, our method is efficient: on a single H100 it takes between 3 and 11 hours to process a Llamav2-70B model, depending on quantization setting. Lastly, with on-device timings for VQ decompression on a mobile CPU we show that VQ leads to improved latency compared to using a 4-bit integer format.
4
21
11,165
Tijmen Blankevoort retweeted
18 Jan 2024
⭐️New paper ⭐️ Excited to share 'The LLM Surgeon', accepted at ICLR 2024. We obtain SOTA pruning performance and even demonstrate structured LLM pruning of full rows and cols. Direct practical impact enabling compression up to 20-30% with negligible loss in performance.🧵1/9👇
3
12
108
18,696
Tijmen Blankevoort retweeted
17 Jan 2024
Very happy to announce that VeRA is accepted at @iclr_conf with scores 8,8,8,5!
VeRA makes LoRA ~10x more parameter efficient while retaining the same performance & also works for vision!
Paper: arxiv.org/abs/2310.11454
Our very light-weight webpage😏: dkopi.github.io/vera/
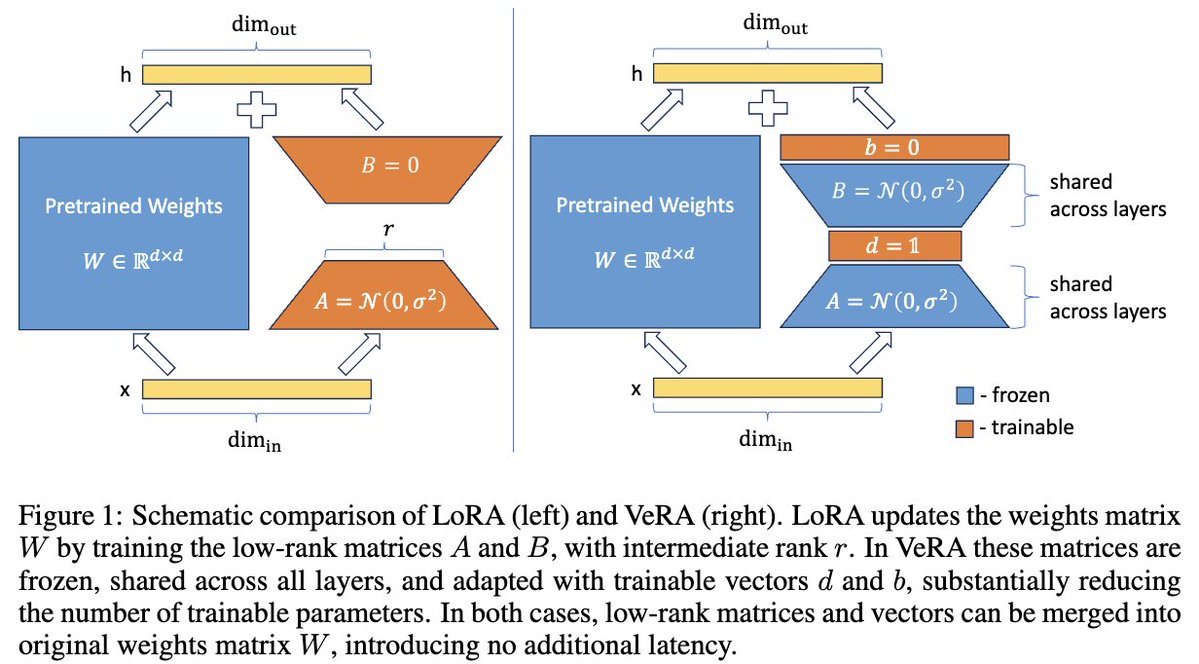
VeRA: Vector-based Random Matrix Adaptation
paper page: huggingface.co/papers/2310.1…
Low-rank adapation (LoRA) is a popular method that reduces the number of trainable parameters when finetuning large language models, but still faces acute storage challenges when scaling to even larger models or deploying numerous per-user or per-task adapted models. In this work, we present Vector-based Random Matrix Adaptation (VeRA), which reduces the number of trainable parameters by 10x compared to LoRA, yet maintains the same performance. It achieves this by using a single pair of low-rank matrices shared across all layers and learning small scaling vectors instead. We demonstrate its effectiveness on the GLUE and E2E benchmarks, and show its application in instruction-following with just 1.4M parameters using the Llama2 7B model.

14
117
636
76,324
5 Dec 2023
Talking in this Dutch podcast, about how a general AI, something that can do many tasks just like a human (and perhaps better) might not be as far away as you might think. 😃
Specifically RL LLMs has the potential ability to supercharge the current model performance.
5 Dec 2023

Na het interne conflict bij OpenAI is het gesprek over ‘artificial general intelligence’ (AGI) relevanter dan ooit. @hmblank en @ikbenechtben zoeken samen met @TiRune uit wat het precies is, en hoe slim AI nu echt kan worden.
bnr.nl/podcast/de-technoloog…
7
442
Tijmen Blankevoort retweeted

6 Jul 2023
We propose a dynamic tokenizer for ViTs, where the scale at which an image is processed varies based on the complexity of the image area. This means less computing for simple areas and more for complex, cluttered areas. Thanks to @royaleerieme, @JakobHavtorn, @TiRune
MSViT: Dynamic Mixed-Scale Tokenization for Vision Transformers
paper page: huggingface.co/papers/2307.0…
The input tokens to Vision Transformers carry little semantic meaning as they are defined as regular equal-sized patches of the input image, regardless of its content. However, processing uniform background areas of an image should not necessitate as much compute as dense, cluttered areas. To address this issue, we propose a dynamic mixed-scale tokenization scheme for ViT, MSViT. Our method introduces a conditional gating mechanism that selects the optimal token scale for every image region, such that the number of tokens is dynamically determined per input. The proposed gating module is lightweight, agnostic to the choice of transformer backbone, and trained within a few epochs (e.g., 20 epochs on ImageNet) with little training overhead. In addition, to enhance the conditional behavior of the gate during training, we introduce a novel generalization of the batch-shaping loss. We show that our gating module is able to learn meaningful semantics despite operating locally at the coarse patch-level. We validate MSViT on the tasks of classification and segmentation where it leads to improved accuracy-complexity trade-off.

8
47
16,745