
Founder. Generalist.
Joined March 2012
- Tweets 3,173
- Following 2,073
- Followers 622
- Likes 3,765
390 Photos and videos




Db retweeted

Jun 13
white pill for my nerds:
60fps e-ink display
a random guy outperformed entire eng teams by developing a pixel by pixel driver for e-ink displays that makes it 60fps.
he did that after work for months, launched it yesterday.
the future is bright


152
427
8,662
530,310
Db retweeted

Jun 11
Julia sets revealed by Lagrangian Descriptors: iterate z² c on the Riemann sphere, accumulate the orbit's step increments and the obtained field loses smoothness right along the Julia set. @marimo_io on #molab GPU. Link 👇👇👇
13
72
392
18,948
Db retweeted

The Sun’s diameter is ~100 times Earth’s.
Sun’s volume is therefore 100 x 100 x 100 times bigger than Earth’s. One million times.
If the Sun was the size of Earth (~8,000 miles in diameter), then Earth would be 80 miles in diameter, the distance from Austin to San Antonio.

1
6
572
Db retweeted

Jun 8
🚨 ANOTHER MASTERCLASS FROM @3BLUE1BROWN
The compressibility of language isn’t just a math curiosity, it’s the hidden engine behind every LLM you use.
Grant’s new video reframes Shannon’s entropy through one elegant lens:
Prediction IS compression.
→ The better you predict the next word, the fewer bits you need to store it
→ Shannon measured English at ~1 bit per character: astonishingly compressible
→ This is exactly what GPT-style models optimize
→ Intelligence, in this framing, is compression
FUN FACT: Von Neumann told Shannon to name it “entropy” because nobody truly understands it anyway 😄
Decades later, that same concept became the bedrock of modern AI.
Deep-dive resources in the 🧵 ↓
79
570
4,816
312,207
Db retweeted

May 28
After AlphaGo, the skill of human Go players noticeably improved. I suspect we will see a similar pattern in math.


Another major problem, this time in additive combinatorics, has fallen, this time to humans rather than AI, but using methods related to the AI solution to the unit distance conjecture.
187
974
9,045
785,339
Db retweeted

90% the tube parts we laser cut are simple cut to length with a few holes.
This technology is extremely unexplored and while this is an extreme example I think more engineers need tube laser tech in their toolbox.

25
41
691
64,813
Db retweeted

Vitamin C shrinks arterial plaques in clinical trial.
The picture below shows improvements in under 4 months.
500 mg 3 times daily in people with heart disease - 6/10 people had reduced plaques, while none in control did.
Vitamin C has several cardioprotective effects:
➞ Antioxidant
➞ Anti-inflammatory
➞ Collagen supporting
➞ Cholesterol lowering
1954. The old forgotten studies often have the best gems.
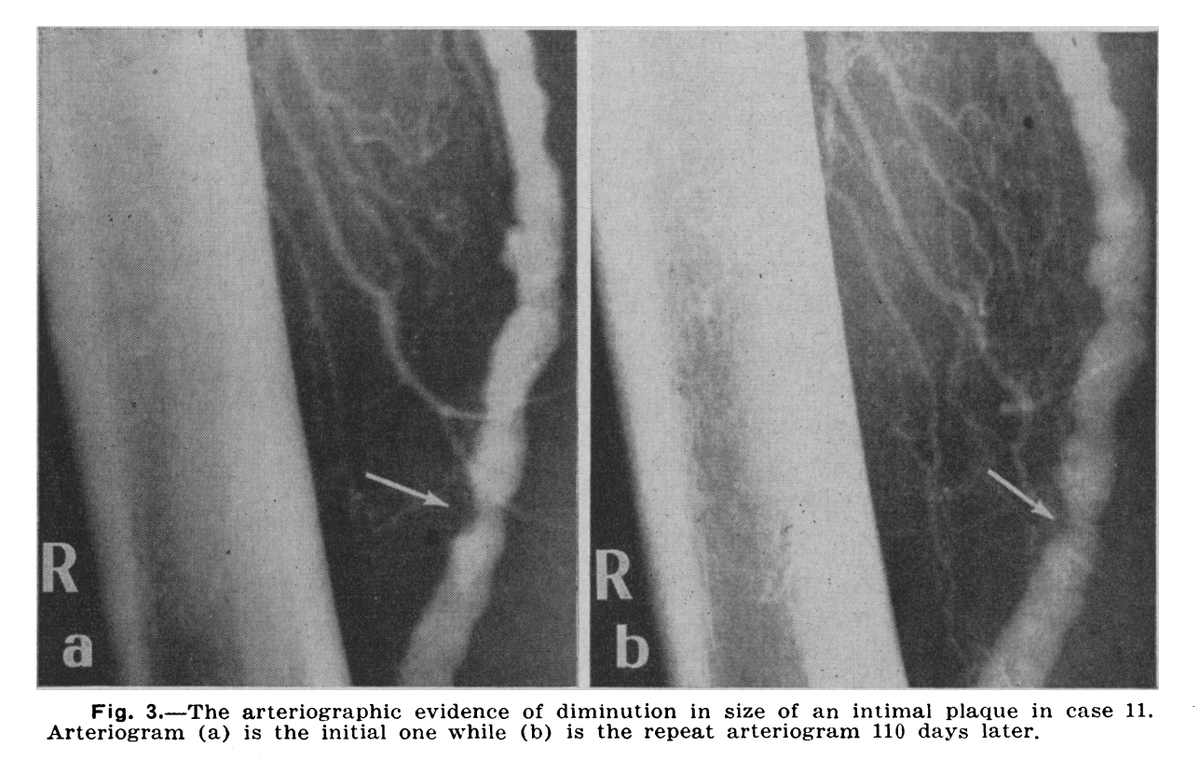

An incredible study showed major reductions in arterial plaques simply by shining a form of red light onto the body, more so than even statins.
(🧵1/7)

32
414
2,021
219,379
Db retweeted

May 9
we ACTUALLY got the oppressor mk2 before GTA 6.
Polish engineer Tomasz Patan built the Volonaut Airbike.
it hits 124 mph, runs on jet propulsion, has no propellers, and weighs less than your dog.
pretty fucking sick.
545
3,740
47,405
1,826,992
Db retweeted

May 7
Chinese researchers have developed the best shortest-path algorithm in 41 years!
Dijkstra’s Algorithm has been the undefeated king of the shortest path for over 40 years.
Whether you’re using Google Maps, booking a flight, or routing internet packets, Dijkstra is the engine running in the background.
Since 1984, textbooks have taught that its efficiency was hit by a "sorting barrier."
To find the shortest path, you have to sort the points by distance. And sorting has a mathematical floor you can’t cross.
Until now.
A research team from Tsinghua University just published a paper that shatters the 41-year-old record.
They proved that Dijkstra is not optimal.
By combining the logic of the Bellman-Ford algorithm with a revolutionary "recursive partial ordering" method, they figured out how to find the path without fully sorting the nodes.
The results are a massive shift in theoretical computer science:
- The first deterministic improvement to the Single-Source Shortest Path (SSSP) problem since 1984.
- A new time complexity of $ O(m \log^{2/3} n)$, officially beating the long-standing $ O(m n \log n)$ limit.
- On massive sparse graphs (like the web or global logistics), this means finding the best route significantly faster than previously thought possible.
For four decades, the greatest minds in algorithms believed this limit was absolute.
Last year, even the legendary Robert Tarjan won an award proving Dijkstra was "optimally efficient" at sorting distances.
Tsinghua’s answer? Stop sorting.
The world’s most settled problem is suddenly wide open again.
If we can break a 40-year-old law in basic graph theory, what other "impossible" speed limits are waiting to be crushed?
92
594
4,057
825,185

Db retweeted

Apr 27
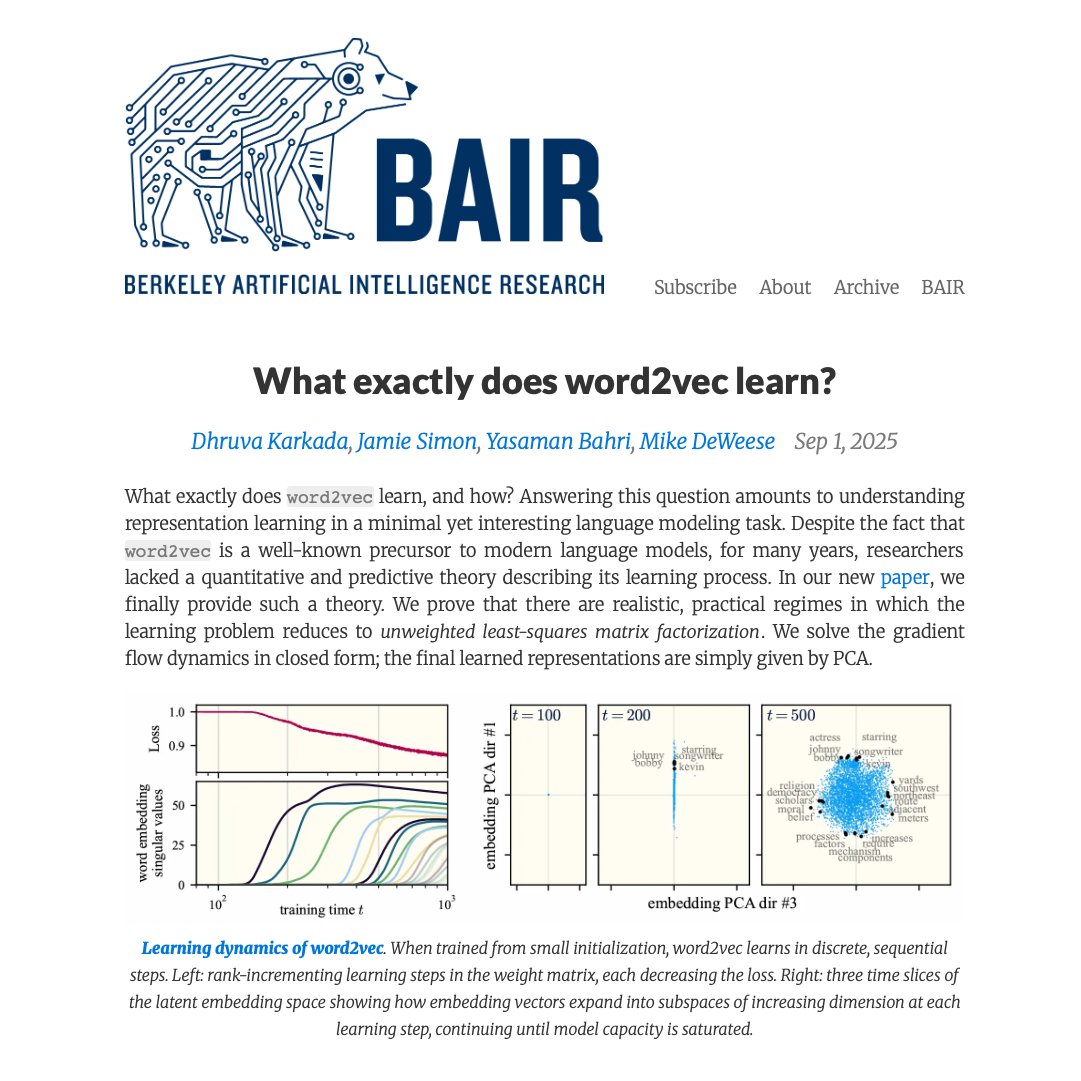
Embeddings power every modern LLM. But what do they actually learn?
This Berkeley (BAIR) paper is one of the clearest reads on how AI systems learn and why embeddings really work.
bair.berkeley.edu/blog/2025/…
6
149
889
46,303
Db retweeted

Continual Learning remains one of the most challenging “holy grails” of AI.
Most discussions focus on catastrophic forgetting: models lose what they previously learned. But there is another equally important failure mode: over long continual training, neural networks can also lose their plasticity, ie, their ability to learn new things is weakened over time.
In our ICLR 2026 work with colleagues at @Apple and @ETH, we study this phenomenon, known as Loss of Plasticity (LoP), from a geometric perspective.
We show that LoP can arise when gradient dynamics become trapped in invariant manifolds of parameter space. In particular, we analyze two types of traps:
🔴 Frozen units: units saturate, gradients vanish, and they become effectively silent to backpropagation.
🔵 Cloned units: units become redundant, receive matching forward and backward signals, and move together.
For these structures, the gradient is tangent to the trap. Once standard GD/SGD enters these affine subspaces, it cannot leave them on its own. This means the dynamics can remain sticky even when the data distribution or task changes.
What we find especially interesting is that these traps are not merely optimization bugs. The same feature-learning pressures that help networks learn useful representations for the current task can also push them toward states with less future adaptability.
This raises a difficult open question for future work: are neural networks trained with SGD and cross-entropy loss fundamentally the right framework for continual learning?
Please read the full paper for more details: arxiv.org/pdf/2510.00304
Apr 25

Neural nets don’t just forget. Sometimes, after long training, they lose the ability to learn at all.
In our #ICLR2026 poster, we model Loss of Plasticity as gradient dynamics trapped in invariant manifolds: 🔴 frozen units, 🔵 cloned units.
The video makes the traps visible.
9
47
359
50,090
Db retweeted

Apr 26
Open-source magnetic tactile sensor for $5! 🧲
Researchers introduced a magnetic tactile sensor that's low-cost, and easy to fabricate, democratizing tactile sensing for robotics.
Operating in unstructured environments like homes and offices requires robots to sense forces during physical interaction. Yet the lack of a versatile, accessible tactile sensor has led to fragmented solutions and often force-unaware, sensorless approaches.
Building an eFlesh sensor requires four components: a hobbyist 3D printer, off-the-shelf magnets (less than $5), a CAD model, and a magnetometer circuit board.
The sensor is 3D printed with magnets embedded in the middle layer. Based on chosen mechanical properties, magnets displace in response to contact forces, measured by a magnetometer underneath.
An open-source design tool converts simple OBJ/STL files into 3D-printable STLs. This enables application-specific sensors for robot hands, grippers, quadruped feet, and more.
Slip detection generalizes to unseen objects with 95% accuracy. Visual-tactile control policies improve manipulation by 40% over vision-only baselines, achieving 90% success on precise tasks like plug insertion and credit card swiping.
All design files, code, trained models, and conversion tools are openly available.
Project page: e-flesh.com/
~~
♻️ Join the weekly robotics newsletter, and never miss any news → ziegler.substack.com
24
335
2,577
287,802
Db retweeted

Apr 24
RoPE is proof that sometimes the right mathematical abstraction can solve an engineering problem more elegantly than any learned parameter can.
No training needed. No lookup tables. Just rotation matrices and the dot product takes care of the rest.

12
74
4,979
Db retweeted

Apr 24
now That's a Mind Palace

trying to use topological data analysis to map the shape of my x bookmarks through mapper embedding extraction and generated 3 views:
- density: where attention keeps gravitating
- pca: the dominant axes of variation
- centroid: center vs edge (typical -> outlier)
4
19
206
11,558
Db retweeted

Apr 24
You can make your own silicon with wafer.space too! Our second shuttle run is open at buy.wafer.space with a new $4 USD per die option!
Apr 23

First silicon just arrived.
These dies are from the first wafer of my GF180MCU based Linux SoC KianV, built with a fully open source ASIC flow.
This chip was part of the wafer.space GF180MCU run and hardware validation comes next.
Big thanks to Leo Moser for help with the ASIC flow and to @mithro and @evezor for their guidance along the way.
The picture shows the first dies. More bring up updates soon.

3
12
93
8,437
I built a machine-vision tool to help you learn to use your fingers like an abacus using the "Chisanbop" technique after discovering it a while back. Recently discovered a great documentary on the history of this technique youtube.com/watch?v=Rsaf4ncx…
1
82


Nice paper combining the strength of Skills and RAG.
Most RAG systems retrieve on every query, whether the model needs help or not. This is wasteful when the model already knows the answer, and often too late when it does not.
New research introduces Skill-RAG, a failure-state-aware retrieval system. It uses hidden-state probing to detect when an LLM is approaching a knowledge failure, then routes the query to a specialized retrieval strategy matched to the gap.
Evaluated on HotpotQA, Natural Questions, and TriviaQA, the approach improves over uniform RAG baselines on both efficiency and accuracy.
Why does it matter?
RAG is moving from a single monolithic pipeline to a suite of skills an agent selects between. Knowing when to retrieve and what kind of retrieval to run will matter more than raw retriever quality as agents take on multi-step reasoning, where a single bad lookup derails the whole chain.
Paper: arxiv.org/abs/2604.15771
Learn to build effective AI agents in our academy: academy.dair.ai/

22
135
741
53,067