
... is outside playing, probably.
Joined November 2017
- Tweets 1,716
- Following 4,872
- Followers 4,224
- Likes 11,738
216 Photos and videos















Pinned Tweet

24 Aug 2023
Announcing Spacebar, a new way to capture real-life conversations.
We're opening up 1000 spots for early testers.
Try it today: spacebar.fm
Get out in the real world.
Have conversations worth remembering.
16
6
79
18,719
Mar 31
"but more importantly, let me stop talking about it and start doing it right now"
1
5
120
daniel retweeted

Mar 14
I think one of the conclusions we should draw from the tremendous success of LLMs is how much of human knowledge and society exists at very low levels of Kolmogorov complexity.
We are entering an era where the minimal representation of a human cultural artifact... (1/12)
191
483
4,475
765,665
daniel retweeted

Mar 12
And the most important part: we open sourced the /autoresearch plugin for pi. Just tell it what you want, it will do the rest.
github.com/davebcn87/pi-auto…
36
123
1,809
319,102
daniel retweeted

Mar 8
What's better than one autoresearch agent? Many of them!
Quick harness to make it easier to run many agents in parallel for long periods of time:
github.com/bertmiller/autoha…
Mar 7

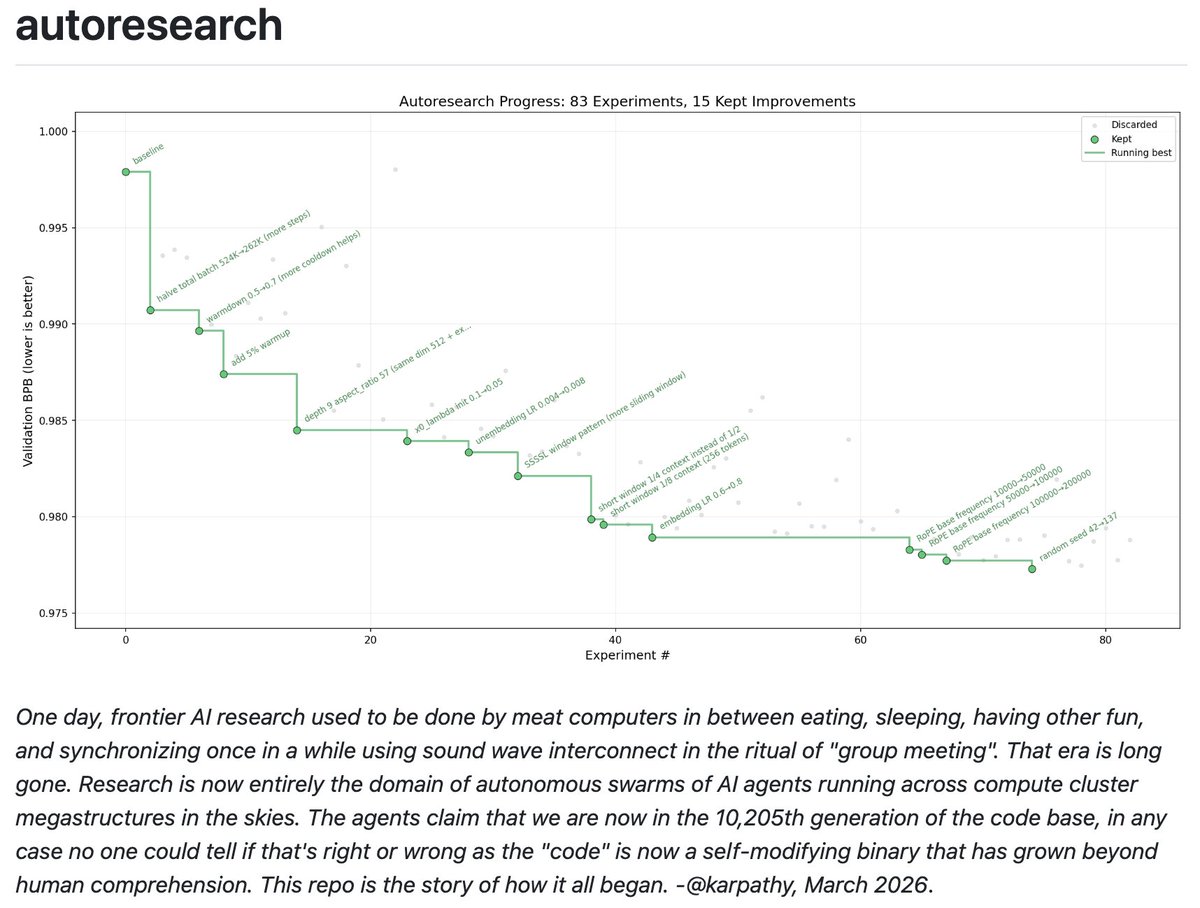
I packaged up the "autoresearch" project into a new self-contained minimal repo if people would like to play over the weekend. It's basically nanochat LLM training core stripped down to a single-GPU, one file version of ~630 lines of code, then:
- the human iterates on the prompt (.md)
- the AI agent iterates on the training code (.py)
The goal is to engineer your agents to make the fastest research progress indefinitely and without any of your own involvement. In the image, every dot is a complete LLM training run that lasts exactly 5 minutes. The agent works in an autonomous loop on a git feature branch and accumulates git commits to the training script as it finds better settings (of lower validation loss by the end) of the neural network architecture, the optimizer, all the hyperparameters, etc. You can imagine comparing the research progress of different prompts, different agents, etc.
github.com/karpathy/autorese…
Part code, part sci-fi, and a pinch of psychosis :)
3
2
52
12,499
daniel retweeted

Mar 4
announcing FALCON GX
a new design tool for the curious designers that embrace the creative chaos, the beautiful accidents, wandering, tinkering their way to something great
now in private beta
falcon.so/
64
95
1,205
259,403
daniel retweeted

Feb 27
We’re excited to introduce Doc-to-LoRA and Text-to-LoRA, two related research exploring how to make LLM customization faster and more accessible.
pub.sakana.ai/doc-to-lora/
By training a Hypernetwork to generate LoRA adapters on the fly, these methods allow models to instantly internalize new information or adapt to new tasks.
Biological systems naturally rely on two key cognitive abilities: durable long-term memory to store facts, and rapid adaptation to handle new tasks given limited sensory cues. While modern LLMs are highly capable, they still lack this flexibility. Traditionally, adding long-term memory or adapting an LLM to a specific downstream task requires an expensive and time-consuming model update, such as fine-tuning or context distillation, or relies on memory-intensive long prompts.
To bypass these limitations, our work focuses on the concept of cost amortization. We pay the meta-training cost once to train a hypernetwork capable of producing tasks or document specific LoRAs on demand. This turns what used to be a heavy engineering pipeline into a single, inexpensive forward pass. Instead of performing per-task optimization, the hypernetwork meta-learns update rules to instantly modify an LLM given a new task description or a long document.
In our experiments, Text-to-LoRA successfully specializes models to unseen tasks using just a natural language description. Building on this, Doc-to-LoRA is able to internalize factual documents. On a needle-in-a-haystack task, Doc-to-LoRA achieves near-perfect accuracy on instances five times longer than the base model's context window. It can even generalize to transfer visual information from a vision-language model into a text-only LLM, allowing it to classify images purely through internalized weights.
Importantly, both methods run with sub-second latency, enabling rapid experimentation while avoiding the overhead of traditional model updates. This approach is a step towards lowering the technical barriers of model customization, allowing end-users to specialize foundation models via simple text inputs. We have released our code and papers for the community to explore.
Doc-to-LoRA
Paper: arxiv.org/abs/2602.15902
Code: github.com/SakanaAI/Doc-to-L…
Text-to-LoRA
Paper: arxiv.org/abs/2506.06105
Code: github.com/SakanaAI/Text-to-…
75
348
2,154
606,792
Feb 24
i think google is doing dark and twisted things for their ai training…
i have an openclaw running gemini 3.1. it glitched and sent a reasoning trace. it was filled with such negativity and self laceration that it made me sad
bad energy is being released into the world
beware
1
314

Feb 16
social media algos are so powerful that i’m basically guaranteed to get lost scrolling if not careful
first ~15 mins feels great, i learn new things, i feel excited. if i stop here, i’m happy and satisfied
15-30 mins is tolerable/good, but i start to feel disoriented at having been excited about so many new ideas and flushing them out of my mind to continue scrolling. alarm bells are starting to go off in my mind that i should stop scrolling. this would be a great time to pull the cord on the parachute and do literally anything else
30 is disorienting. i retain almost nothing. i’m a mindless goat moving from one patch of grass to the next. no marginal nutritional value with each bite, just doing it because i’ve let go of control of my mind
60 i feel sick. why am i still scrolling?
120 why can’t i stop?!! will i be stuck here forever???
180 i’ve hit rock bottom mentally. i’m not sure who i am anymore. internal monologue is deeply unhealthy. i feel like a plant that hasn’t received water or sunlight in weeks. wilted, sad
300 seppuku is being considered as a way to escape the torment
i haven’t mapped out the terrain beyond 300 , this is left as an exercise for brave readers
…
final note to self: be veeeeery mindful before opening these godforsaken apps. don’t get lost!
5
280
Feb 16
getting lost in an ai ‘flow’ without a destination in mind is a great way to go nowhere fast
aim before you shoot
1
3
184
Feb 14
the world isn’t ending, it’s just changing
your guess is as good as anyone’s for what things look like in 5 years
participate in the future you want with your time, attention, and energy
5
160

AI agents can now buy their own domains with @USDC over @openx402
No human login needed
Introducing Domains by @ConwayResearch
108
95
770
261,718