
Research fellow at Flatiron Institute, working on understanding optimization in deep learning. Previously: PhD in machine learning at Carnegie Mellon.
Joined September 2011
- Tweets 1,231
- Following 998
- Followers 6,278
- Likes 1,455
115 Photos and videos









Pinned Tweet

1 Oct 2025
Part 1: How does gradient descent work?
centralflows.github.io/part1…
Part 2: A simple adaptive optimizer
centralflows.github.io/part2…
Part 3: How does RMSProp work?
centralflows.github.io/part3…
1
11
123
17,542
Jun 12
Did Anthropic get more gains out of model scaling than other labs thought was possible? It reminds me of an interesting recent paper, which showed that deep layers in open LLMs are not doing much, and that this can be fixed by scaling the LayerNorm output.
arxiv.org/abs/2502.05795
9
22
293
24,083
Jun 13
Update: not the secret sauce (definitely known to the other labs)
Jun 13

Thanks for your kind thoughts and support, Jeremy! I do believe this direction could potentially open up a new level of scaling toward deeper models with stronger reasoning capabilities.
To be clear, I was not aware of the Depth-MP work when developing this paper (shamed); the idea grew out of my years of work on model compression and layerwise analysis.
1. arxiv.org/abs/2202.02643
2. arxiv.org/abs/2310.05175
3. arxiv.org/abs/2410.10912
After releasing our paper, we compared our method with Depth-P and found that the two perform similarly. I fully respect prior work, and we will expand the related work discussion and add the appropriate references in the next version.
1
6
1,062
Jun 8
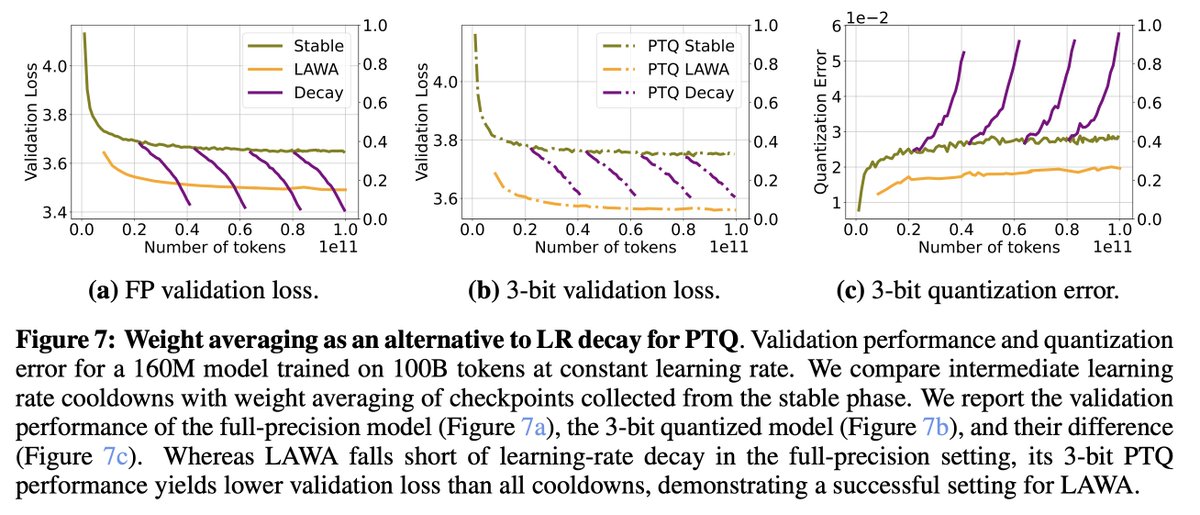
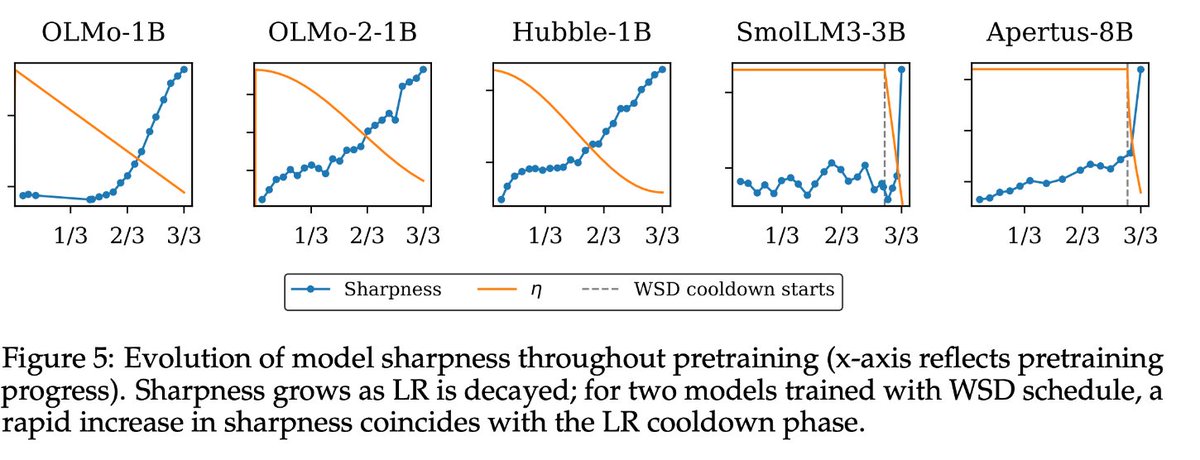
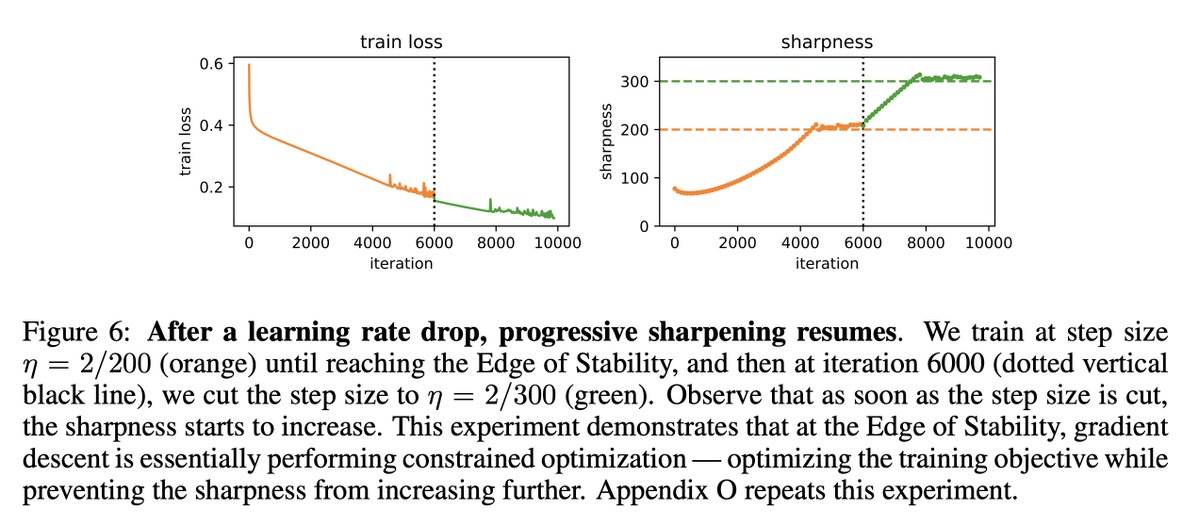
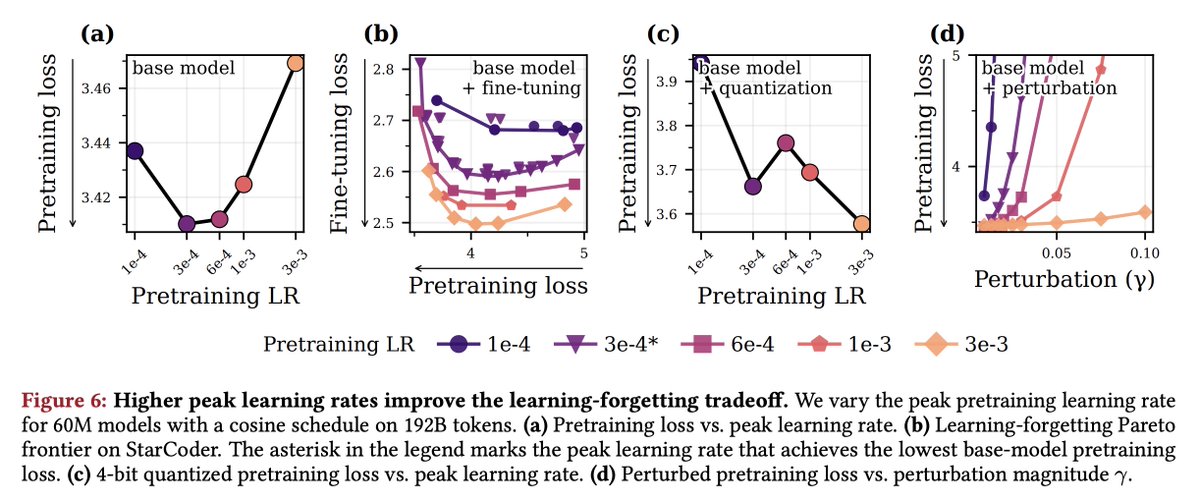
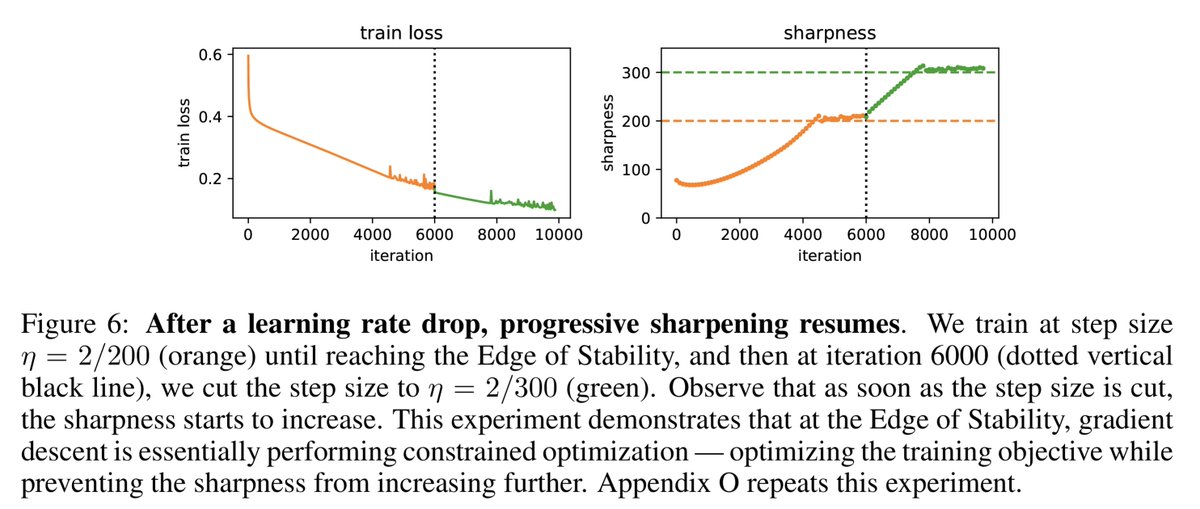
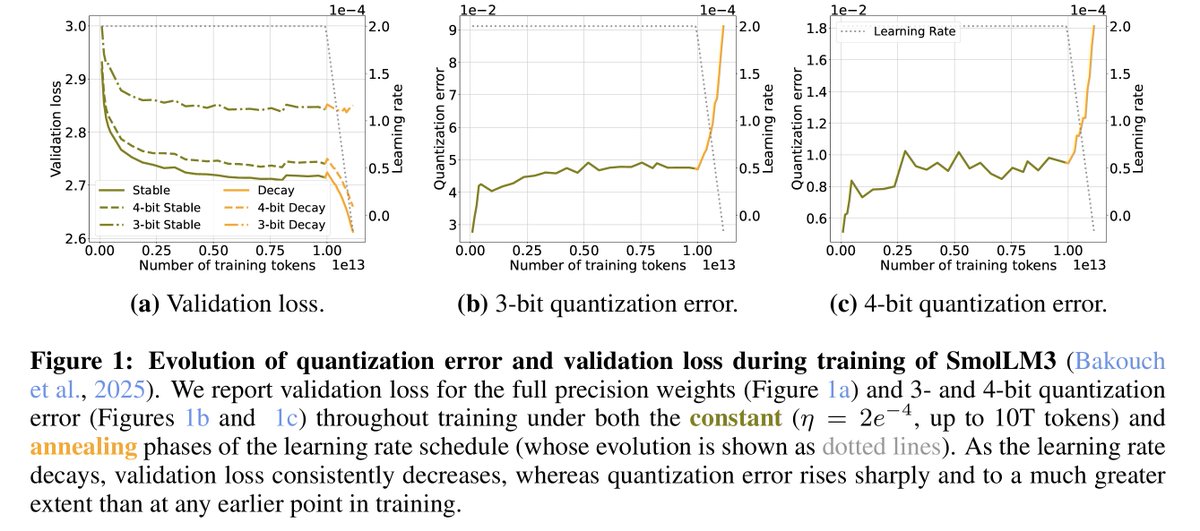
The recent Microsoft AI report noted that too much learning rate decay during pretraining hurts post-RL performance. This is actually just the latest of several papers this year pointing out that small learning rates can be harmful in LLM pretraining. (Thread)
6
23
193
17,410
Jun 8
Nevertheless, hyperparameters matter, and I'm glad we're starting to see good science about LR schedules for LLMs.
PS: as noted by Catalan-Tatjer et al, weight-averaging recovers many benefits of LR decay but without increasing sharpness. More should consider weight-averaging!
1
2
12
829
Jun 8
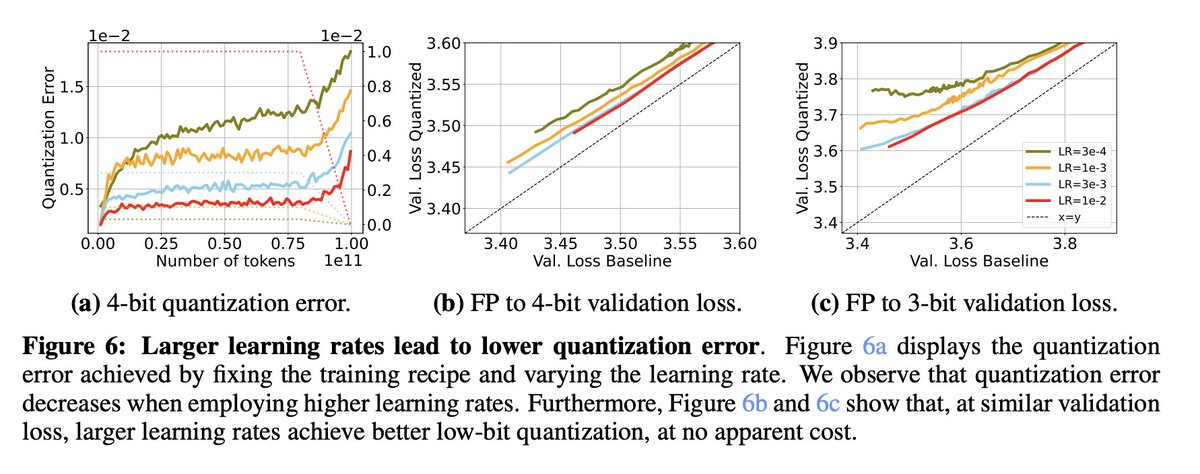
Oh also, in the *multi-epoch* LLM setting, there is evidence that larger LR's yield better population pretraining loss, exactly mirroring what was known in 'classical' image settings (arxiv.org/abs/2306.08590).
(This experiment is with batch size, but LR should be the same)
1
5
514
Jeremy Cohen retweeted

Apr 24
There Will Be a Scientific Theory of Deep Learning ift.tt/FIXLaes
4
49
317
28,383
Jeremy Cohen retweeted

Apr 24
1/ Deep learning is going to have a scientific theory. We can see the pieces starting to come together, and it's looking a lot like physics!
We're releasing a paper pulling together these emerging threads and giving them a name: learning mechanics.
🔨 arxiv.org/pdf/2604.21691 🔧
54
292
1,511
304,585
Apr 22
Looking forward to attending ICLR and giving a talk on Sunday at 9am at the Science of Deep Learning workshop: scienceofdlworkshop.github.i…. Message me if you want to chat about deep learning optimizer dynamics at the conference!
3
6
47
4,091
Jeremy Cohen retweeted

Mar 13
I have spent 4 years making LLMs generalize better without more data or compute. I'm looking for a Research role in industry. Here's what I've built:
1/ Early Weight Averaging → First paper (2023) to apply weight averaging during LM pre-training. Now widely used in many pre-training pipelines. arxiv.org/abs/2306.03241
2/ Attention Collapse → Diagnosed attention collapse in LLMs and proposed a training fix.arxiv.org/abs/2404.08634
3/ Curriculum Finetuning → Upweight easy samples and downweight hard ones during finetuning to reduce forgetting. arxiv.org/abs/2502.02797
I am a PhD student at UT Austin. I have interned at DeepMind, LightningAI, and Amazon Alexa.
If you're hiring or know someone who is, please DM or email (sanyal.sunny@utexas.edu).
Web: sites.google.com/view/sunnys…
#MachineLearning #LLM #NLP #PhD #AIJobs #OpenToWork
3
10
94
21,543