
Joined July 2012
- Tweets 6
- Following 35
- Followers 17
- Likes 4
1 Photos and videos

Riccardo Del Chiaro retweeted

5 Jul 2024
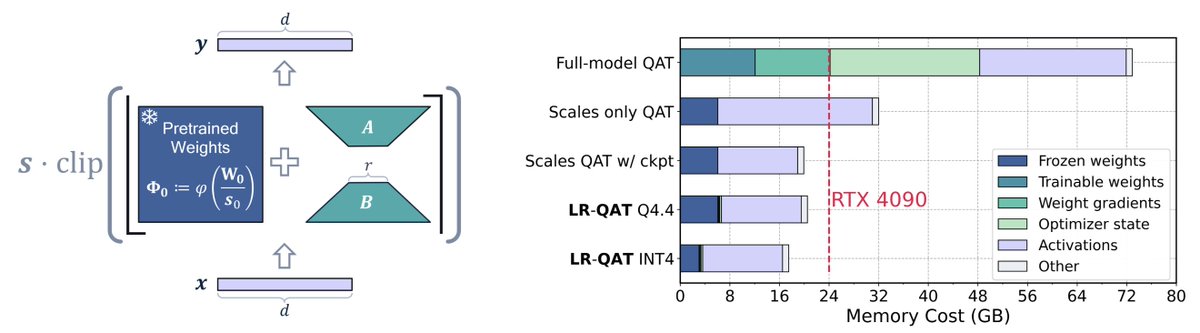
Interested in boosting quantized LLM performance with QAT?
Check out our latest work on Low-Rank Quantization-Aware Training (LR-QAT) which can train 7B LLMs on a single consumer-grade GPU with just 24GB of memory.
New work with @yell1337 and @delchia
arxiv.org/abs/2406.06385
8
31
2,013
Riccardo Del Chiaro retweeted

4 Dec 2019
"Learning Representations Using Causal Invariance"
Leon Bottou. Invited Talk #ICLR2019
videoken.com/embed/8UxS4ls6g…
It describes: "Invariant Risk Minimization" 🔥arxiv.org/pdf/1907.02893.pdf
7
19
