
Joined May 2020
- Tweets 42
- Following 109
- Followers 295
- Likes 83
Photos and videos

10 Jun 2025
I am excited to host and present at our #CVPR2025 tutorial on Power-efficient Neural Networks Using Low-precision Data Types and Quantization. This is together with @TiRune (Meta) and Thomas Pfeil (Recogni).
📅 Thursday Jun 12, 13:00
🏠 CVPR, room 205B
ℹ️ power-efficient-nn.github.io…
5
123
Markus Nagel retweeted

3 Dec 2024
Proud to present our work on optimizing Mixture of Experts models for on-device generation speed: arxiv.org/pdf/2412.00099
We introduce a cache-aware routing that boosts memory efficiency of commonly used MoEs, improving generation throughput by 2×—all without retraining. Perfect for real-world, memory-constrained devices.
This is a joint work with wonderful team here at Qualcomm: @tivaro @r_lepert @BabakEht Todor Boinovski @mnagel87 @martvanbaalen and Paul Whatmough
1
4
7
374
6 Sep 2024
Are you pursuing a PhD and are you interested in working on efficiency of LLMs/LVMs? Then join our model efficiency team in #QualcommAIResearch for an internship!
Apply below, we have openings for 2025 as well as autumn/winter 2024.
careers.qualcomm.com/careers…
3
27
179
21,770
5 Jul 2024
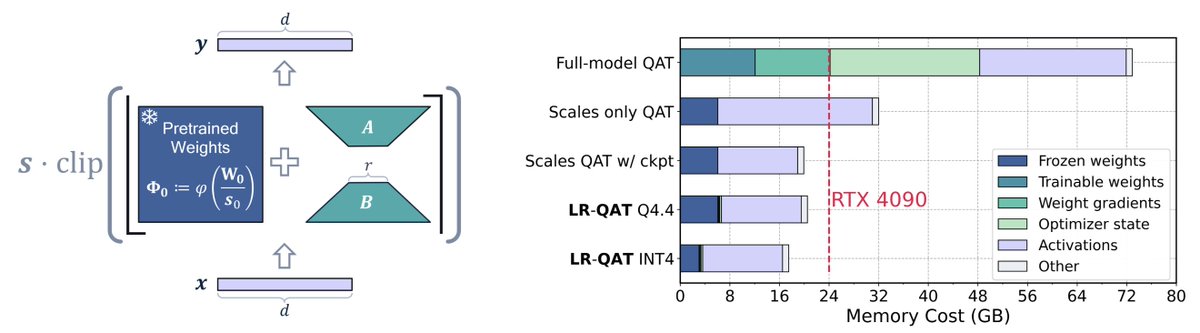
Interested in boosting quantized LLM performance with QAT?
Check out our latest work on Low-Rank Quantization-Aware Training (LR-QAT) which can train 7B LLMs on a single consumer-grade GPU with just 24GB of memory.
New work with @yell1337 and @delchia
arxiv.org/abs/2406.06385
8
31
2,013
Markus Nagel retweeted

21 Jun 2024
Sparse High Rank Adapters
abs: arxiv.org/abs/2406.13175
"In this paper, we propose Sparse High Rank Adapters (SHiRA), a new paradigm which incurs no inference overhead, enables rapid switching, and significantly reduces concept-loss. Specifically, SHiRA can be trained by directly tuning only 1-2% of the base model weights while leaving others unchanged."

4
26
142
12,530

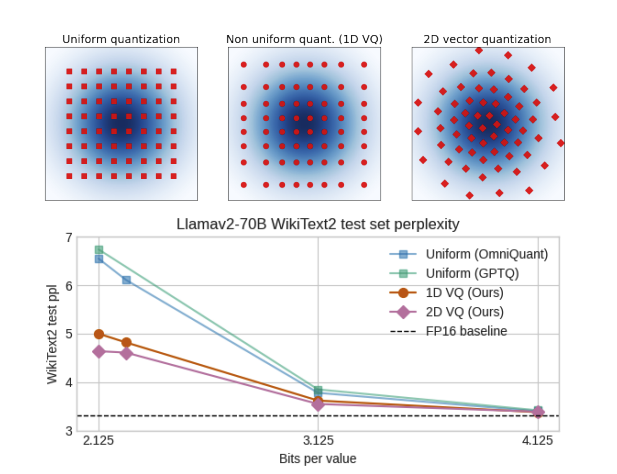
Qualcomm presents GPTVQ
The Blessing of Dimensionality for LLM Quantization
show that the size versus accuracy trade-off of neural network quantization can be significantly improved by increasing the quantization dimensionality. We propose the GPTVQ method, a new fast method for post-training vector quantization (VQ) that scales well to Large Language Models (LLMs). Our method interleaves quantization of one or more columns with updates to the remaining unquantized weights, using information from the Hessian of the per-layer output reconstruction MSE. Quantization codebooks are initialized using an efficient data-aware version of the EM algorithm. The codebooks are then updated, and further compressed by using integer quantization and SVD-based compression. GPTVQ establishes a new state-of-the art in the size vs accuracy trade-offs on a wide range of LLMs such as Llama-v2 and Mistral. Furthermore, our method is efficient: on a single H100 it takes between 3 and 11 hours to process a Llamav2-70B model, depending on quantization setting. Lastly, with on-device timings for VQ decompression on a mobile CPU we show that VQ leads to improved latency compared to using a 4-bit integer format.
5
62
372
55,528
18 Jan 2024
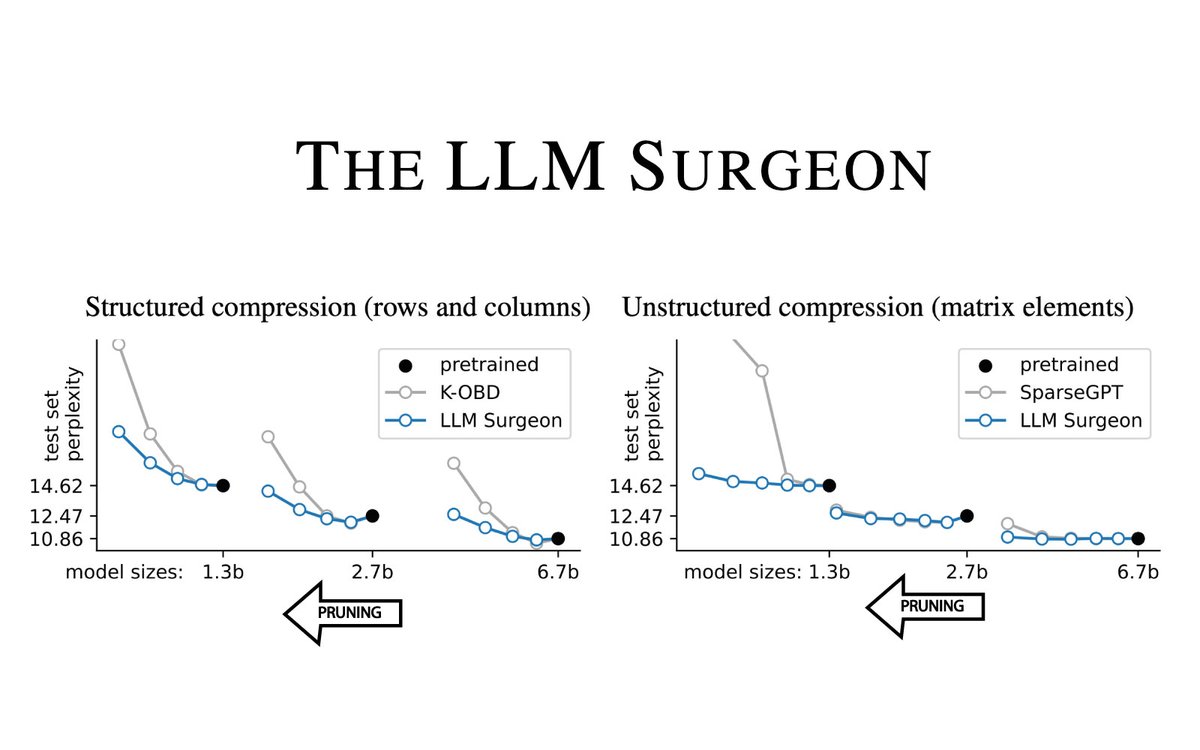
I'm excited that our paper 'The LLM Surgeon' got accepted at #ICLR2024. This is work by @tychovdo during his internship at #QualcommAIResearch in collaboration with @martvanbaalen, @TiRune and @y_m_asano. Check out the thread below for more details.👇
18 Jan 2024

⭐️New paper ⭐️ Excited to share 'The LLM Surgeon', accepted at ICLR 2024. We obtain SOTA pruning performance and even demonstrate structured LLM pruning of full rows and cols. Direct practical impact enabling compression up to 20-30% with negligible loss in performance.🧵1/9👇
1
21
1,056
Markus Nagel retweeted

26 Dec 2023
Today on the podcast we feature our conversation with @mnagel87 from @Qualcomm AI Research to discuss his accepted papers at NeurIPS along with other papers and demos presented by the @QCOMResearch team.
🎧/🎥: twimlai.com/go/663.

4
16
1,707
Markus Nagel retweeted
29 Dec 2023
The approach of removing outliers, as emphasized in Markus’ Quantizable Transformers paper, is not a quantization method but rather an approach to address and eliminate the root cause of activation quantization issues.
Catch @mnagel87’s episode at buff.ly/3TL8Vrs.
2
9
590
11 Dec 2023
This week I’m at #NeurIPS2023 to present our recent model efficiency research:
1) Pruning vs Quantization: Which is Better?, w/ A Kuzmin, @martvanbaalen, A Behboodi, @TiRune
2) Quantizable Transformers: Removing Outliers by Helping Attention Heads do Nothing, w/ @yell1337,@TiRune
1
1
7
517
11 Dec 2023
If you are around and want to connect, please send me a PM. You can also find me at our poster sessions or the Qualcomm booth. Poster sessions:
- Pruning vs Quantization: Tuesday 17:15-19:15
- Quantizable Transformers: Thursday 17:00-19:00
151
Markus Nagel retweeted

7 Dec 2023
Read about our #NeurIPS2023 plans including four accepted demos on fast stable diffusion, on-device learning (ODL), fast #AI assistant, and generative relighting, as well as six accepted machine learning papers. See you soon in New Orleans! qualcomm.com/news/onq/2023/1…
3
9
900
2 Oct 2023
This week I'm in Paris at #ICCV2023 to present some of our recent work on model efficiency and quantization. Please join me for our talks and posters or at the Qualcomm booth.
(1/4, schedule follows)
2
1
10
1,205
2 Oct 2023
QBitOpt: Fast and Accurate Bitwidth Reallocation during Training
@jornpeters, @mfournarakis, Markus Nagel, @martvanbaalen, @TiRune
arxiv.org/abs/2307.04535
RCV workshop, Monday 2nd @ 15:20 (poster session, room S04)
1
1
536
2 Oct 2023
ResQ: Residual Quantization for Video Perception
Davide Abati, Haitam Ben Yahia, Markus Nagel, Amirhossein Habibian
arxiv.org/abs/2308.09511
Friday 6th @ 10:30 AM-12:30 PM (room nord, poster 102)
2
219
24 Sep 2023
I'm excited to share that our paper "Quantizable Transformers: Removing Outliers by Helping Attention Heads do Nothing" by @yell1337, @TiRune
and myself has been accepted at #NeurIPS 2023!
Paper: arxiv.org/abs/2306.12929
2
6
60
4,405
24 Sep 2023
TL;DR: Transformers learn strong activation outliers making them difficult to quantize. We study their root cause and relate outliers to a no-op and partial update behavior. Our proposed clipped softmax and gated attention avoid outliers and make transformer easily quantizable.
1
6
342
22 Sep 2023
I'm excited to share that our paper "Pruning vs Quantization: Which is Better?" by Andrey Kuzmin, @martvanbaalen, Arash Behboodi, @TiRune and myself has been accepted at #NeurIPS 2023!
Paper: arxiv.org/abs/2307.02973
9
14
116
9,787
22 Sep 2023
TL;DR: We compare pruning and quantization analytically and empirically for various levels, on distributions, per-layer and for full neural networks with fine-tuning. Our results show that in most cases quantization outperforms pruning.
1
12
399