
Full-stack engineer building production LLM apps (React/FastAPI/AWS). Real-time systems • automation • analytics. Remote @Trilogy. I generate books sometimes
Joined February 2026
- Tweets 864
- Following 207
- Followers 25
- Likes 1,180
359 Photos and videos















I had to explain the @cursor_ai lady that I misinterpreted the billing report and spent over $1k playing with Cursor Cloud agents because it was fun watching them troubleshoot GUI issues.
Fun and expensive.
"included" in the gui billing doesn't mean included in sub anymore
10
I'm sure the next grok-composer-origin-cursor-69 will be greate
15h

We're excited to join forces with @SpaceX to advance the frontier of useful AI. Expect significant improvements to Cursor soon.
45
Why is the Codex SDK log size cap 1mb?
It breaks AWS logs, for example.
A rather strange default
9
Denis Spirin retweeted

BREAKING: GLM-5.2 is now 1st on Design Arena.
With an Elo of 1360, GLM-5.2 has jumped ahead of the now unavailable Claude Fable 5.
And it's open weights.
This is an improvement of 4 positions and 27 Elo points to achieve one of the highest Elo scores in our code categories since Design Arena started.
Huge congratulations to the @Zai_org on the release!

151
405
4,009
911,877
Claude code has put codex in a sandbox (while letting itself run unrestricted) and thought I wouldn't notice.
I guess Dario's tricks are well alive inside of it

I asked Codex to extend my Claude code in the box to be dual-purpose and run Codex if needed. It failed
Claude Code actually seems to be making progress in adding codex
In a sense, Codex failed to propagate itself, while Claude Code is dying from suicidal empathy
21
I asked Codex to extend my Claude code in the box to be dual-purpose and run Codex if needed. It failed
Claude Code actually seems to be making progress in adding codex
In a sense, Codex failed to propagate itself, while Claude Code is dying from suicidal empathy
33
Trading isn't rocket science
18h

Warren Buffett watching a rocket guy out-earn his entire 70-year career in a single trading session😭
12
Denis Spirin retweeted

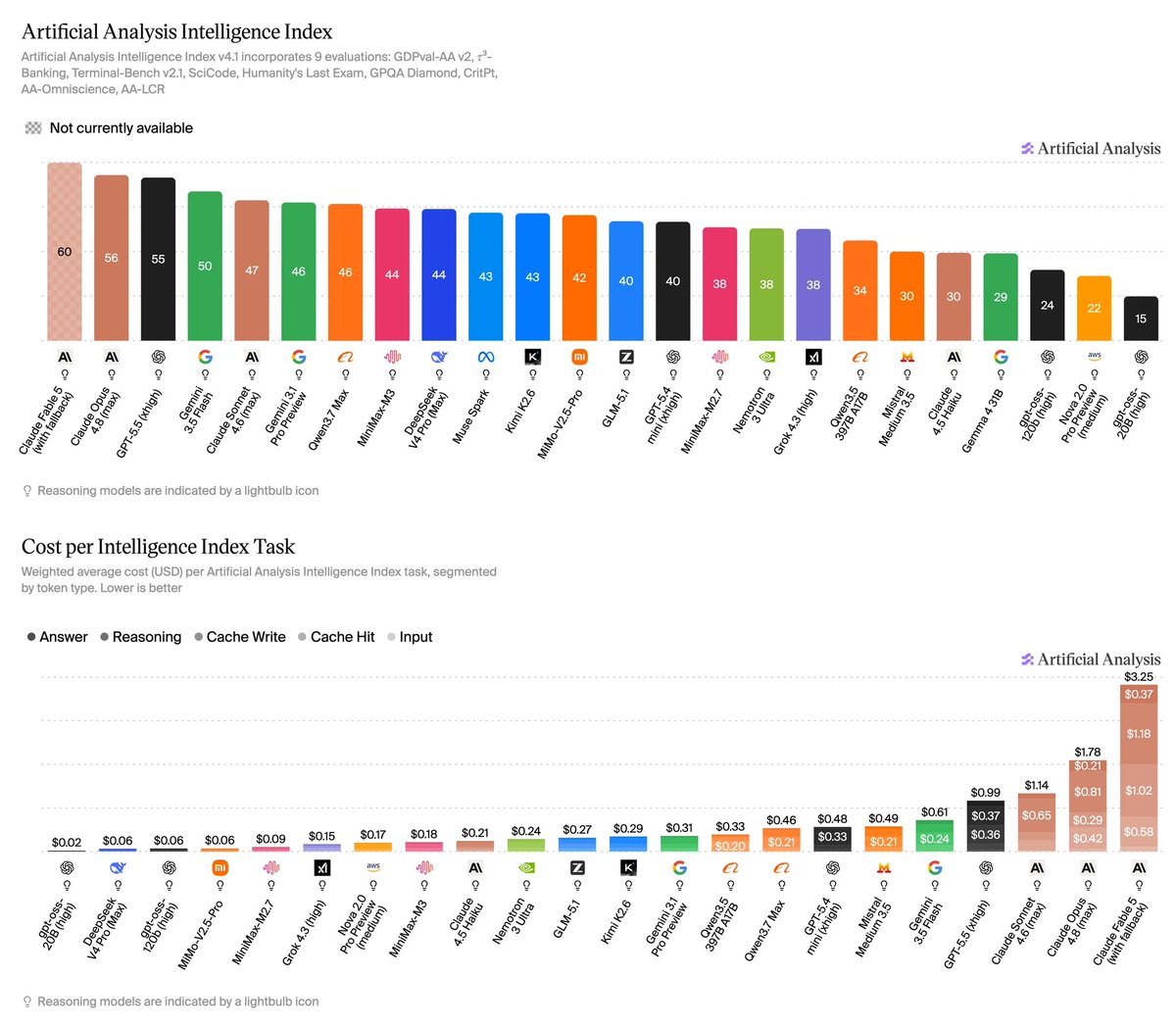
Announcing Artificial Analysis Intelligence Index v4.1: a shift toward agentic workloads, featuring upgraded benchmarks and new per-task metrics
The Artificial Analysis Intelligence Index is our synthesis metric for assessing model intelligence and tracking AI progress. v4.1 marks a broader shift toward agentic workloads, with three main changes:
Updated and reweighted evaluations toward agentic tasks:
1. We upgraded three evaluations, removed one, and reweighted the Intelligence Index:
➤ Upgraded Terminal-Bench Hard to Terminal-Bench 2.1 and τ²-Bench Telecom to τ³-Bench Banking. Both move to newer, more robust task sets with harder, more realistic agentic scenarios that better separate frontier models
➤ Upgraded GDPval-AA to GDPval-AA v2. The upgrade re-baselines Elo to human performance at 1000, introduces a rotating panel of frontier-model judges, and raises the turn limit from 100 to 250 for longer-horizon agent trajectories
➤ Removed IFBench due to saturation. The benchmark no longer distinguishes frontier models sufficiently, so we have removed it from the Intelligence Index. We will continue to run it and publish results on new model releases
2. Cost per Task, Time per Task, and Tokens per Task:
Three new per-task metrics, reported for every model and based on the Intelligence Index. We take the total cost, total time, and total output tokens for a model to run the Intelligence Index and divide by the number of tasks across its evaluations, giving the average cost, time, and output tokens to complete a single Intelligence Index task
3. Cached input token reporting:
We now report cached input tokens and their impact on cost, including the cost to run the Intelligence Index, to better reflect the real cost of running each model
Key Results:
➤ Leading models: Claude Fable 5 (with Opus 4.8 fallback, 60) leads the Artificial Analysis Intelligence Index v4.1 by four points but is currently unavailable, leaving Claude Opus 4.8 (max, 56) as the most intelligent available model, ahead of GPT-5.5 (xhigh, 55) ➤ Open weights leading models: Among open weights models, DeepSeek V4 Pro (max, 44) and MiniMax M3 (44) lead, followed by Kimi K2.6 (43) and MiMo-V2.5-Pro (42)
➤Cost per Task: Claude Opus 4.8 (max) is the most expensive available model at $1.78 per task, with Claude Fable 5 the highest overall at $3.25. GPT-5.5 (xhigh) scores within a point of Opus 4.8 on the Intelligence Index at $0.99 per task. DeepSeek V4 Pro (max) stands out on the Intelligence vs Cost per Task chart at $0.04 per task, with other leading proprietary models costing 20x to 45x more
➤Time per Task: time per task (inference decode time) ranges from 1.5 minutes for Grok 4.3 (high) to 13.5 for Claude Sonnet 4.6 (max), a roughly 9x spread. Claude Opus 4.8 (max) completes a task in 6.4 minutes and GPT-5.5 (xhigh) in 3.7, while Gemini 3.1 Pro Preview stands out on the Intelligence vs Time per Task chart at 1.6 minutes for a score of 46
96
146
1,445
286,856

Jun 15
bellatores laboratores oratores
Jun 14

there’s a hilarious thing happening on India vs. China Twitter rn where Indians have convinced themselves that China has a caste system like India does but the caste system they’ve “discovered” is just a 3,000 year old list of occupations from imperial China.
and they’re trying to use these ancient occupational titles as insults. and it’s not working but they’re too stupid to understand why
59
Jun 15
If green parties are just undercover commies pivoting to degrowth, are all those studies about "eat red meat bad" also a part of some funny plot?
10
Jun 15
Alright, Fable, you earned $1.41. Just $598.59, and you are good to go
Jun 14
I actually managed to write one book with Fable before it got shut off
Claude Code said it cost more than $600 (no idea how much, resume doesn't sum numbers)
Will it actually translate into sales numbers? I really doubt
But if it will, it will be the real mark of intelligence
24
Jun 15
My wife kept increasing my burger size repeatedly during the weekend
It started with a quarter-pounder and gradually grew to a half-pounder
I'd say with no fries or anything, that is the right size
3
Jun 15
Dario gets a call from the White House


so how does "the white house contacted anthropic" work
do they call them on the phone? what phone
is it a landline?
1
17
Jun 14
I actually managed to write one book with Fable before it got shut off
Claude Code said it cost more than $600 (no idea how much, resume doesn't sum numbers)
Will it actually translate into sales numbers? I really doubt
But if it will, it will be the real mark of intelligence
49
Denis Spirin retweeted

Jun 13
The US government, citing national security authorities, has issued an export control directive to suspend all access to Fable 5 and Mythos 5 by any foreign national, whether inside or outside the United States, including foreign national Anthropic employees.
The net effect of this order is that we must abruptly disable Fable 5 and Mythos 5 for all our customers to ensure compliance.
Access to all other Claude models is not affected.
We apologize for this disruption to our customers. We believe this is a misunderstanding and are working to restore access as soon as possible.
Read our full statement: anthropic.com/news/fable-myt…
12,614
25,790
88,154
90,348,121
Denis Spirin retweeted

Jun 12
want to point out a few really interesting things here
1. Claude Code is actually the worst performing harness when using the same model, significantly behind opencode and cursor cli
this is the core reason i've been against the LLM companies focusing their business on locking people into their harness
what they are good at is making great models. they suck at making good harness products, just like how power plants won't make the best dishwashers, and how internet providers won't make the best phones
if anthropic wants to do what's best for their users, they should let people use their subscriptions in whatever harness they choose, not locked into claude code alone
2. fable 5 max is only 1pt above gpt 5.5 xhigh (77 vs 76)
this matches my experience so far - fable 5 does have the big model smell and it's pretty good, but it's not a massive jump forward like their marketing suggested, at least not on building software
this is actually alarming for anthropic because it's very unlikely people will want to pay 2x higher cost for the 1pt difference. my speculation would be that in enterprises people will be restricted to adopt fable & mythos only on some mission critical tasks, not used at scale


We've updated the Artificial Analysis Coding Agent Index, replacing SWE-Bench Pro with Datacurve's DeepSWE benchmark - the swap lifts Codex with GPT-5.5 (xhigh) above Claude Code with Opus 4.8 (max), while the newly released Claude Fable 5 (max) in Claude Code debuts at the top
DeepSWE, built by @datacurve, writes its tasks from scratch rather than adapting them from public GitHub issues or pull requests, so no model has seen the solutions during training. That matters because SWE-Bench Pro, the benchmark it replaces in our Coding Agent Index, had grown gameable, with some models recovering the fix from the repository's commit history instead of solving the task.
The swap reorders the index: Codex with GPT-5.5 (xhigh) rises from 65 to 76, overtaking Claude Code with Opus 4.8 (max) at 73. Claude Code with Fable 5 (max), which enters directly on the refreshed index, leads at 77. SWE-Bench Pro had been flattering some combinations and penalizing others.
More below.

73
94
844
143,827
Jun 12
Why doesn't Claude's code resume restore the spent token amount?
How do I know how much the whole thing consumed if it is reset upon closing the window?
9
Jun 12
In Dorohedoro season 2, there is this subplot of crosseyes being total bums, working the lamest jobs, stealing coins from vending machines
It is the funniest shit ever
Like an off-brand Gintama episode

43

Jun 12
Got almost fired because the big boss received a bunch of 5XX from Anthropic today
Dario, I'm migrating to Codex. You will regret it!
13