
AI Research & Eng in Conversational AI. Building at @teamsundial Prev: founder @soleda_ai, also @columbia, @UW, @stanfordnlp, @UCBerkeley
Joined April 2009
- Tweets 2,100
- Following 316
- Followers 663
- Likes 533
54 Photos and videos




Derek Chen retweeted

Jun 14
This is a *way* bigger deal than it seems...
Frontier AI companies will *never* own the frontier again
I kid you not... I've been waiting for someone to show this result for like 4 years... this is a huge deal.
The short reason: combinations of models will *always* outperform individual models
The long reason: this is the gateway to a million times more data... and huge leaps in compute efficiency.
The AI scaling laws always win.
More in article below 👇
Jun 13

Introducing the Fusion API, the smartest compound model in the market.
Fusion achieves Fable-level intelligence at half the price.
How it works 👇

240
356
5,094
1,273,351



Jun 11
How much do different companies really believe in the ability of the underlying model to do work? I dug into their SDKs to find out: morethanoneturn.com/2026/06/… Despite the hype, AI agents are still in infancy with no clear rules or standards. It's an open field to win!
1
33
Derek Chen retweeted
Jun 10
The scary part about Anthorpic's Fable nerf is not that it refuses to answer biology or cryptography. It's that it foreshadows what's coming. A world where a couple companies decide what you can and cannot do. They're building a new ruling class and you're not in it...
461
1,301
13,870
734,097
Derek Chen retweeted

Jun 10
What if Fable is really really bad at LLM development and biology and they’re just trying to save face?

32
24
702
20,985
Derek Chen retweeted

Jun 5
Massive output uptick due to agentic AI. Complete flat adoption.

470
980
7,365
2,463,880
Jun 7
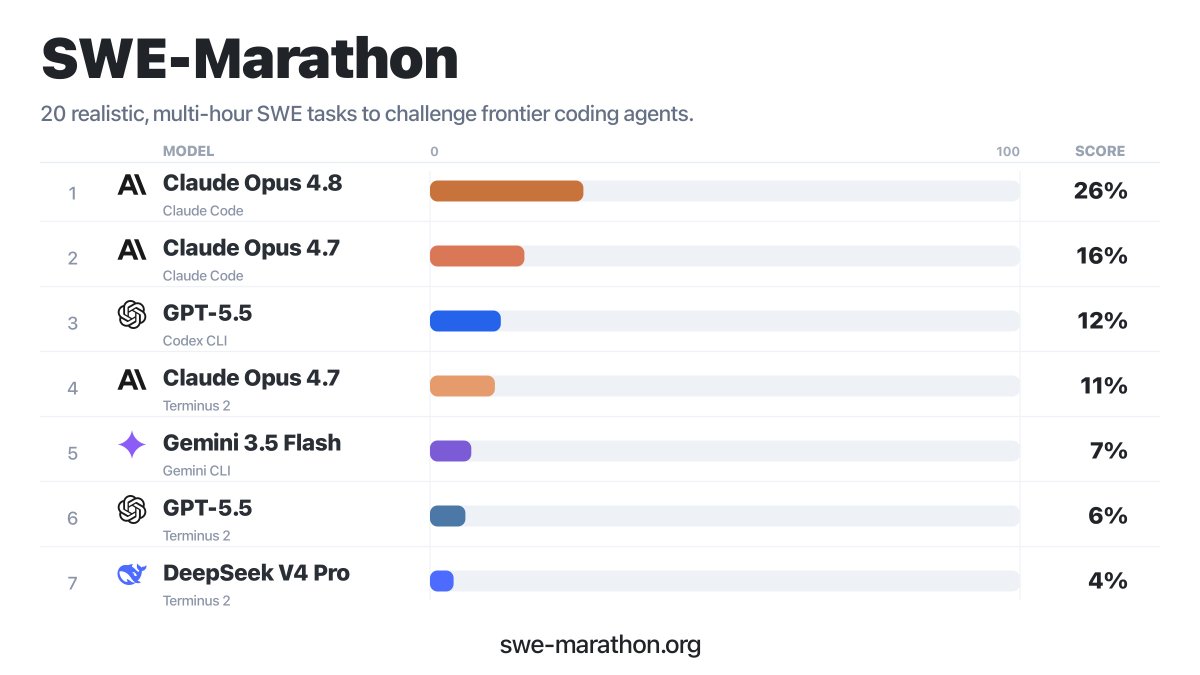
Current coding benchmarks are mostly saturated for recent models, so it's time for a new one! Had a great time collaborating to put this together:
Jun 5

Can coding agents stay coherent over a 1 billion token budget?
Can they build Slack from scratch?
Rewrite a JAX codebase in PyTorch?
Build a C compiler in Rust?
Enter SWE-Marathon: a benchmark for autonomous long-horizon software work.
3
91
Jun 4
RSI might be happening soon ...
Jun 4

Our internal data shows Claude is accelerating AI development—a possible path to recursive self-improvement, or AI autonomously building a more capable successor.
It’s happening faster than we thought, and the implications deserve greater attention. anthropic.com/institute/recu…
62

Today we’re introducing Gemma 4 12B — our latest open model that brings advanced agentic reasoning, vision and audio directly to your laptop.
It delivers performance nearing our larger Gemma models with a much smaller total memory footprint, while being small enough to run locally with just 16GB of VRAM. It’s open and accessible for everyone to use under a permissive Apache 2.0 license.
This is all made possible by our new, unified architecture that removes separate multimodal encoders. Here’s how we did it 🧵

249
1,225
9,368
878,554
Derek Chen retweeted

Jun 4
Recently met @srush_nlp and he started giving me an impromptu lecture on how targeted on-policy self-distillation works.
I asked him if I could record it on my iPhone.
The basic idea is this: if the model made a mistake at some point in the rollout (for example, calling a tool that doesn't exist), we want to discourage this specific error, but we don't want to just learn from the final reward, because it's a very noisy signal spread out over the whole trajectory.
So we have another model read this trajectory and figure where the error was made. It simply inserts some hint tokens to the part of the trajectory right above where the mistake was made.
Now with these injected hint tokens, have the model run a forward pass. You're not having to regenerate a new rollout - aka no new decode required.
The hint causes the model to assign lower probabilities to the error tokens. You then trains the original model to match these new probabilities, teaching it to downweight that specific mistake.
41
175
2,538
417,119
Derek Chen retweeted

Jun 3
this is an interesting point in the new ted chiang piece – no one really claims that alphafold is conscious, or that sora or midjourney or dall-e are conscious

162
432
4,159
324,570
Jun 4
Very compelling arguments about the strengths and limits of LLMs, worth a read!
Jun 4

If we confuse generative AI’s ability to produce text with consciousness, we risk assigning moral responsibility to chatbots—and not to their makers, Ted Chiang argues. theatlantic.com/philosophy/2…
24
May 28
If my rubric is so precise as to prevent all forms of spurious verification, then I'm not writing evals or prompting anymore. I'm just coding.😑
30
Derek Chen retweeted

Man goes to doctor. Says he's depressed about AI. He fears the permanent underclass.
Doctor says, "Treatment is simple. Read Gary Marcus. LLMs are stochastic parrots—they can't reason out of distribution."
Man bursts into tears. "But doctor..." he says, "I am in distribution!"
66
347
5,249
226,448
May 18
Within an agent loop, a reliable component chained together 10x becomes a disaster waiting to happen. ➿🔜🔥 So how do you build trustworthy agents out of probabilistic parts? Turns out we've solved this problem before: open.substack.com/pub/moreth…
1
23
May 18
Observability, Evals, and other telemetry have their place, but the change is actually structural. We need to treat each LLM-invocation or tool-call as a known vector that is waiting to fail. This operates just like individual employees within a larger organization.
15

Yann LeCun says you cannot build a reliable agentic system without a world model
LLMs don't have world models. They can't predict the consequences of their actions before taking them
"they just act, and whatever happens next is someone else's problem"
Without that, it's not intelligence
274
368
2,719
330,828
May 10
When LLMs started benching 200, that was amazing! Each new release pushed boundaries, so able to bench 400, 800 (super human!), and now pushing towards 1600 lbs. But model training keeps skipping leg day, forgetting about core, and they still can't run a mile to save their life🏃♂️
50
Derek Chen retweeted

Apr 30
seriously, working with AI is MISERABLE for one and only one reason: having to re-explain the same thing
"oh yeah this new session obviously doesn't know what proper case trees are, so let me explain it for the 5000th time in my life"
I'm tired
AGENTS.md doesn't solve this because it is impossible to fit the entire domain knowledge without nuking the context - it would be 1m tokens worth
RAGs don't solve this, the agent won't search unknown unknowns
SKILLs don't solve this unless I keep like a collection of 1750 skills with specific cuts of domain knowledge for each possible subset of my domain that I might need in a given chat, but that's a lot of manual work
recursive LLMs or whatever don't solve this for the same reason, you can't dump a domain book and expect the AGENT will magically guess that it is supposed to search for a specific bit knowledge. unknown unknowns
fine tuning doesn't solve this (OSS models suck and OpenAI / Anthropic gave up on user fine tuning)
I honestly think a good product around fine tuning on your domain would be a major hit and an underdog lab should take this opportunity
665
177
3,503
254,185
Derek Chen retweeted

Apr 25
im confused by people saying the right answer is pressing red. the good outcomes are 51% of ppl press blue OR 100% of people press red. the second is obvs way less likely
833
125
7,868
376,631