
Sotfware engineer
Joined November 2021
- Tweets 331
- Following 209
- Followers 42
- Likes 589
33 Photos and videos











Jun 13
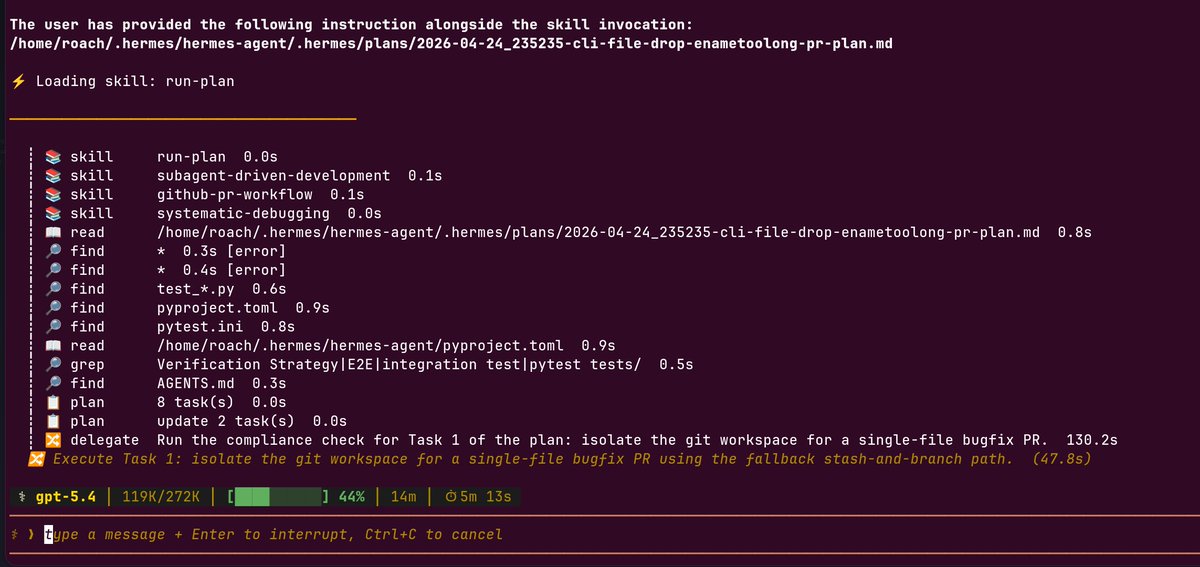
GLM-5.2 가 나왔다
연초에 200$ 가량에 Max Plan 을 사둬서 오늘도 바로 내 전용 벤치마크인 "갤러그" 벤치마크를 돌려봤다
역시나 엄청 느리다 GLM 은 내 생각에 추론속도를 고치지 않으면 더 이상 결제할 가치가 크게 없다. 중국모델들은 솔직히 추론 빠르고, 성능 준수하고, 싼맛에 쓰는건데..
5.2 가 왼쪽, 5.1 이 오른쪽이다.
확실히 5.1 보다는 더 잘만든다
1
1,124
Jun 13
미국정부가 앤트로픽의 프론티어 모델인 Fable5 를 외국인들이 사용하는것을 금지했다
만약에 국가 보안의 이슈로 미국 / 중국이 프론티어 모델 사용을 외국인에게 금지하면 어떻게 될까?
어렵겠지만 한국도 모델 개발을 지속해야하는 이유가 아닐까 싶다
Jun 13

The US government, citing national security authorities, has issued an export control directive to suspend all access to Fable 5 and Mythos 5 by any foreign national, whether inside or outside the United States, including foreign national Anthropic employees.
The net effect of this order is that we must abruptly disable Fable 5 and Mythos 5 for all our customers to ensure compliance.
Access to all other Claude models is not affected.
We apologize for this disruption to our customers. We believe this is a misunderstanding and are working to restore access as soon as possible.
Read our full statement: anthropic.com/news/fable-myt…
146
Jun 12
오늘 Kimi-K2.7-Code 모델이 나왔군요
저는 새로운 모델이 나오면 항상 "갤러그" 만들기를 시켜보는데요. 이게 참 모델이 어느정도 성능을 가지고 있는지 판단하기 좋습니다.
저번 Fable5 는 말도 안되는 수준의 게임 구현 능력을 보여줬는데, kimi 2.7 code 도 엄청나게 잘 만들어주네요.
갤러그 벤치마크 체감상 4.8 과 비슷한 레벨에 있는거 같네요
확실히 kimi-code 에서 "/swarm" 을 쓰냐 안쓰냐가 퀄리티 여부가 조금 많이 차이나는 것 같습니다. kimi 구독하시는 분들은 반드시 kimi-code 써보세요.
@Kimi_Moonshot
164
Jun 11
오늘 Fable 5 (Mythos) 모델이 등장하고 앤트로픽 팀은 nested agent 의 depth 를 늘리는 패치를 진행했습니다. 그리고 loop engineering 까지 언급하며 더 이상 에이전트에게 직접적으로 프롬프트를 치지 말라고 합니다. 이게 무슨 뜻일까요? 저는 이러한 패치와 내뱉는 문장들에 그 들이 느끼는 하나의 방향성이 있다고 봅니다
제 생각에는 모델이 하네스가 하던 역할들을 흡수 하고 있다는 생각이 강하게 듭니다. 예를 들면, 이번 Fable5 모델은 Task 구조 분해를 너무 잘합니다.
기존 유명했던 하네스 들이 해왔던건 보통 "큰 작업" 하나를 여러 작은 작업들로 나눠서 이 작은 작업들을 잘 돌려서 큰 작업을 완수 시키는 과정이 였습니다. 작은 작업 단위가 잘 완수되면 큰 단위 작업은 완수된다는 믿음으로 보통 돌아갔기 때문입니다.
근데 Fable5 를 보면 이 작은 작업으로 쪼개는걸 모델 수준에서 엄청 잘해줍니다. 그리고 최근 Claude code 에 나온 Dynamic workflow 는 loop 내부에서 모델이 스스로 판단하여 JS(javascript) 를 써서 결정적으로 서브에이전트 spawn 여부나 이런것들을 사용 할수 있게 해줍니다.
그니까 Fable5 한테 Dynamic workflow 맡기면 loop 내부에서 Fable5 가 알아서 subagent 를 판단하여 늘리고, 일 구조분해해서 subagent 에게 맡기고 가 쉽게 가능하다는 뜻입니다. (물론 현재 Opus 4.8 도 가능합니다)
근데 여기서 loop 를 진행하는 main agent 를 잘 돌리려면 한가지가 더 필요합니다. 그게 바로 loop 를 잘돌리는 법을 연구하는 loop engineering 인 것이죠.
그건 loop 를 주도하는 main agent 가 최대한 compaction 이 일어나지 않도록 컨텍스트를 분산시켜야 합니다.
그럴려면 subagent 를 nested 하게 소환할 수 있어야 합니다. 사실 이전부터 subagent 를 쓰는 이유는 작업을 subagent 에게 시키고 main 은 요약본만 받아서 컨텍스트 부하를 줄이는 방법으로 많이 사용해왔습니다. 저 역시 제가 제작한 하네스에서 이러한 방법으로 많이 썼고요.
그래서 subagent 에게 일시키고, 그 subagent 는 또 subagent 에게 일을 시키는 구조를 반복하게 되면 main agent 의 컨텍스트 부하를 기하 급수적으로 줄일 수 있고, 더 장기적인 작업을 할수 있게 된다고 봅니다. loop 를 진행하는 main agent 의 컨텍스트 부하가 줄어들면 줄어들수록 방향성을 덜 잃게 되니까요.
그래서 아마 앞으로 요런 방향으로 모델이 발전하지 않을까 싶습니다. 하네스도 이에 대비해서 다시 작성해야 할것 같고요.
제가 만드는 roach-pi 도 이 방향으로 가도록 연구를 더 해볼 예정입니다.
짧은 식견일 수 있지만 이게 올해부터 내년초까지 방향이 아닐까 라고 생각해봅니다
1
1
126
Jun 11
오늘 헤르메스 에이전트 밋업에서 발표를 진행했습니다
오늘은 실제 저희 회사에서 일하고 있는 헤르메스 에이전트에 대해 소개하고, 이 에이전트가 기존에 사람이 일하고 있는 워크플로우를 어떻게 자동화했는지 그 이야기를 들려드렸습니다
큰 작업을 작은 구간들로 쪼개고, 결정론 적인 영역들은 결정적으로 유지하고, 결정적일수 없는 부분들은 재현율(recall) 을 일정 수준으로 끌어올릴때 까지 작은 구간에서 human-in-the-loop 를 해서 재현율을 끌어올릴때 까지 샘플데이터와 작업하게하는
거창하게 말하면 AX, 쉽게 말하면 토큰 값을 실제 노동 가치로 치환할수 있는 작업을 어떻게 진행했는지 발표했습니다.
하나의 워크 플로우을 자동화 하는 과정에서 해당 업무를 담당하던 담당자(도메인 전문가) 와 이야기하며 큰 작업을 잘개쪼개고, 자동화 하다보면 팀원들도 어느 순간 “와우 모먼트” 를 느끼고 이것저것 자동화를 시도해보는 순간이 옵니다
사실 AX 는 뭐 교육보다 실제로 그냥 하고 있는 업무 붙어서 같이 자동화를 해봐야 감이 오지 않나 싶습니다. 조직에 토큰 많이 쓰는분을 좀 채워 넣어서요.
여튼 말이 좀 길어졌는데 헤르메스 에이전트 좋습니다. 안써보신 분들은 한번 정도 써보세요 ㅎㅎ
33
Jun 10
오늘 Fable5 이 보여주는 방향성은 명확한 것 같다
확실히 하나의 Task 에 대한 구조분해 능력이 상당히 뛰어나다. 이 말은 이런 모델이 loop 로 들어왔을때 loop 내부에서 일들을 분해하고 subagent 들에게 작은 task 를 할당하는게 충분히 쉬워진다는 뜻
loop engineering 을 강조한 이유가 느껴진다
45
roach retweeted

my favorite engineering skills for AI:
- Compound Engineering: github.com/EveryInc/compound…
- Ryan Singer's shaping skills: github.com/rjs/shaping-skill…
- Matt Pocock's skills: github.com/mattpocock/skills
I switched from Superpowers to Compound Engineering as they perfected the plugin over time, and I'm pretty sure I still only use like 10% of it
22
95
1,024
72,453

This sounds complicated but the agents can implement this in OpenClaw/Hermes Agent trivially (use skillify from GBrain with a link to this tweet)
Sounds ridiculous but you should try it
May 26

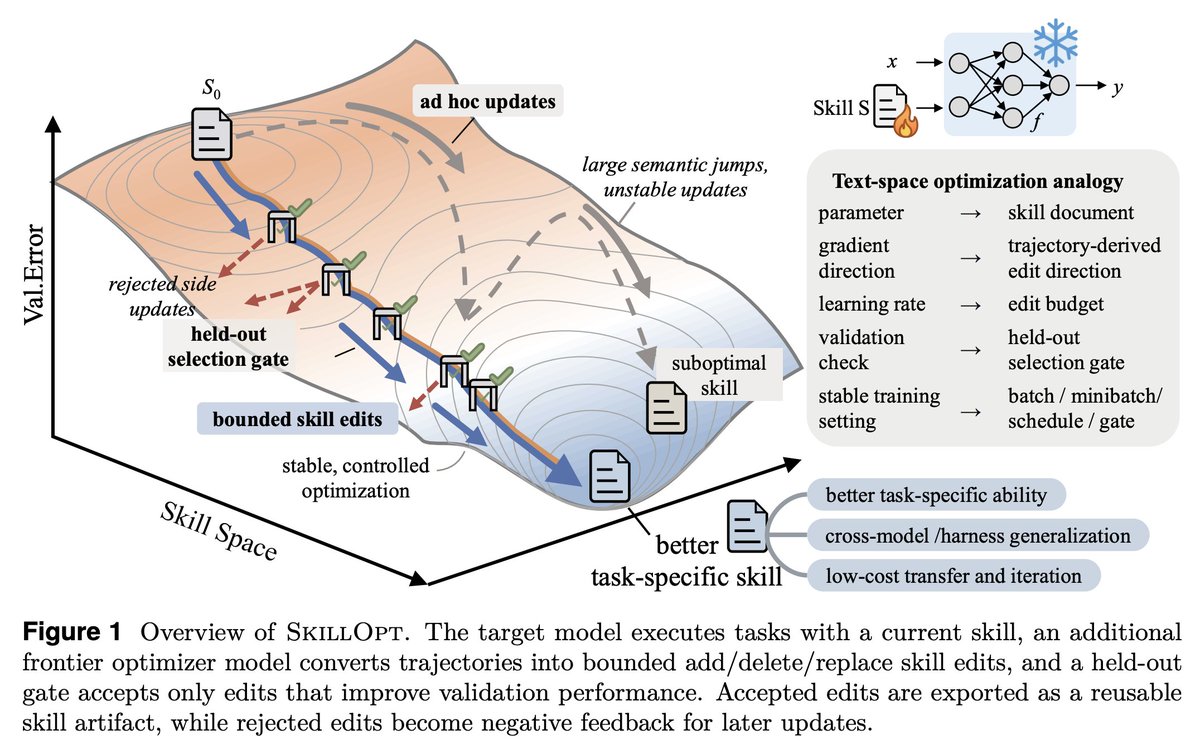
Gradient descent for SKILL.md files sounds interesting, maybe a bit complex but it's becoming a real part of agent harness.
SkillOpt is one of the first papers to treat markdown skill files as trainable parameters and provides a proper optimization framework for them.
A few things I learned that you should consider too.
1. The validation gate is the only thing that matters in a self-editing loop.
Held-out set, strict improvement, ties rejected. End-to-end, their best skills land with 1 to 4 accepted edits total. If your "self-improving agent" is accepting most of what it proposes, you're shipping slop.
2. Bounded edits are better than full rewrites. 4 to 8 edits per step is the sweet spot.
Remove the budget and performance collapses. This is the textual analog of learning rate, and it transfers to any LLM-as-author loop. If you're using an agent to refactor your docs, your prompts, or your skills, cap the diff size.
3. Compactness wins. Median final skill: ~920 tokens.
Skills do not need to be long. They need to be high-signal. Most skill files I see are bloated because length feels like effort. It isn't.
4. The harness is becoming less important; the skill is becoming more important.
A Codex-trained skill ported into Claude Code hit 59.7 points on SpreadsheetBench. Procedural knowledge is more general than the runtime that
produced it.
5. Frozen model trained context is the practical adaptation.
GPT-5.4-nano with a SkillOpt'd skill ≈ frontier behavior on procedural benchmarks. Cheaper, portable, inspectable, zero inference-time cost. This is
the answer to "how do we adapt a frontier model for our domain" for almost everyone who isn't training their own models.
6. Verification is the bottleneck.
Every gate in this paper depends on an auto-grader. That works for benchmarks. It fails for writing, design, and strategy, exactly the open-ended work we want to automate. Whoever builds the verifier for open-ended tasks owns the next stage.
There are also two leassons I learned while shipping v2.3.0 of my Context Engineering Agent Skills repo, measured across composer-2, claude-opus-4-7,
gpt-5.5, and gemini-3.1-pro via the @cursor_ai SDK:
- Description and body are two different surfaces. The router only sees the description. The agent sees the body once activated. They can quietly disagree, and only end-to-end task tests catch it.
- Aggregate accuracy is the wrong unit. When I rewrote three descriptions, the corpus average moved ~1pp. Individual skills moved 23–25pp. Per-skill effect size is where the action is.
Also, in Feb 2026 I shared a piece called Personal Brain OS arguing that the markdown file is a first-class substrate for agent state. SkillOpt is the optimizer-shaped version of that same argument: not "store memory in files" but "treat files as trainable parameters with proper optimization machinery around them." That's the move from static to measured.
The fast/slow split they describe already lives implicitly in the digital-brain-skill repo:
- voice-guide and tone-of-voice.md are slow-state (rarely touched)
- posts.jsonl and bookmarks.jsonl are fast-state
What SkillOpt adds that I didn't have is a protected section invariant, a structural guarantee that fast edits cannot overwrite slow lessons. Removing that mechanism cost them 22 points on SpreadsheetBench. Worth borrowing.
If you're building agents, SkillOpt: Executive Strategy for Self-Evolving Agent Skills is a good paper to read: arxiv.org/pdf/2605.23904
51
166
2,054
331,229
roach retweeted

May 26
这是 yan5xu(ex ManusAI)写的长文:《从 Prompt 到 Harness:如何理解 LLM Engineering》
核心框架:螺旋上升的工程范式演进
第一圈:Prompt Engineering(2022-2024)
• 写好 system prompt,设计 few-shot,调 prompt 结构
• 天花板:模型变强后,精心设计的技巧反而成约束(Khan 的 Prompting Inversion:GPT-4o 上 Sculpting 97%,GPT-5 上降到 94%)
第二圈:Context Engineering(2025)
• Karpathy 命名:"the delicate art and science of filling the context window with just the right information for the next step"
• 管理动态展开任务中的信息流转:上一步结果怎么流入下一步、环境反馈怎么注入、对话历史怎么压缩
• 典型产品:Cursor(动态检索相关代码)、Lovable/Bolt(LSP 报错、测试失败自动注入下一轮)
• 局限:规则是人硬编码的,"context rot"(多轮后性能平均下降 39%)
第三圈:Harness Engineering(2026-)
• 两步走:
‣ 放手:给 agent 工具链(lint、测试、搜索),让它自己决定什么时候用什么
‣ 上保险:框定能力边界(sandbox、CI 轮数限制、文件权限、结构测试)
• 定量验证:同一模型同一 prompt,换 harness 配置成功率从 42% → 78%
金句:"Agents aren't hard; the Harness is hard."
关键洞察
• 不是线性替代,是螺旋积层:harness 内部还在跑 context engineering pipeline,pipeline 里还在写精心设计的 prompt
• 每一圈演化的驱动力:上一阶段不够用了 → 新实践被逼出来
• 下一圈瓶颈已露头:Eval(怎么定义"好"?LLM-as-judge 有 bias)和 Governance(多 agent 互认证、审计、权限)

4
14
131
28,080
May 22
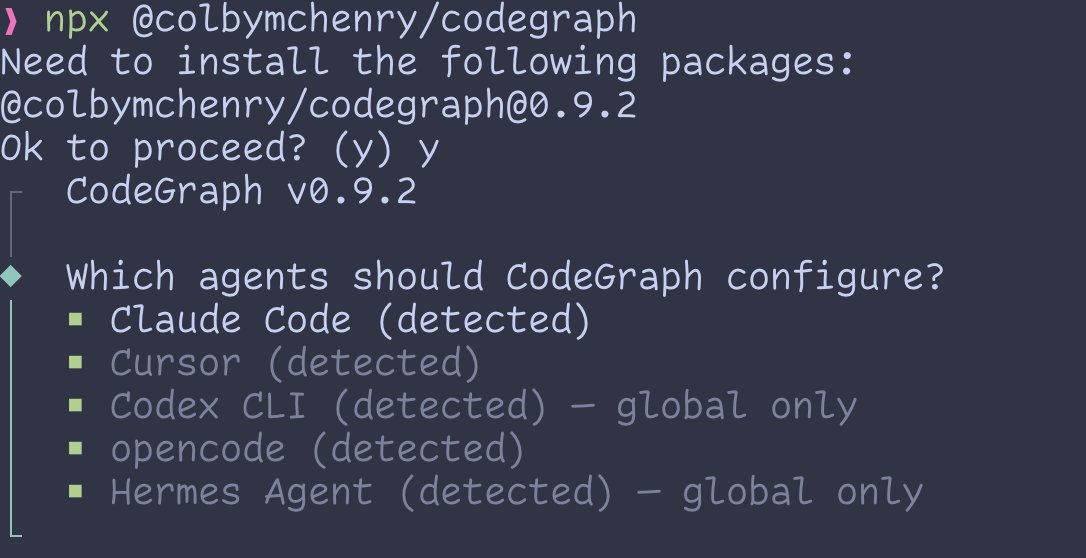
Hermes Agent can now use Codegraph
CodeGraph gives AI coding agents a local semantic code index, so they can search symbols, trace callers/calles, and reason about impact without repeatedly scanning files.
I've contributed this features :)
@Teknium @NousResearch
github.com/colbymchenry/code…
2
3
150
May 22
34
roach retweeted

May 19
1/6 Introducing Qwen3.5-LiveTranslate: Next-gen real-time interpretation is here. 🌍
We’re breaking down language barriers with 3,500 language pairs, ultra-low latency, visual context, real-time voice cloning, and hotword customization.
Engineered to help you ship native, frictionless real-time translation experiences to a global audience.
31
90
690
4,112,573
roach retweeted

May 11
Introducing RL Environment Creator Skill
Now any one can create RL environments
$ npx skills add adithya-s-k/RL_Envs_101
> You can create environments across multiple frameworks like OpenEnv, OpenReward, Verifiers, NemoGym ...
> the repo has live working examples of environments that your coding agent can reference
> The skill is design to first understand what type of model you are training and create an environment while keeping that in mind
ps. There’s a lot more to building RL environments that can be used for training. One major aspect is the data, which this skill can’t directly solve. However, the skill will help with implementing tools, rewards, and other components of an RL environment, making it easier to go from idea to implementation quickly across different frameworks.
Let me know if you’d be interested in a detailed, end-to-end blog/tutorial on building an environment and actually training a model for a useful use case.
May 5

Excited to release the Ultimate guide to RL environments!
Definitions of RL environments differ wildly in the LLM era, so we spent the last month building several RL environments across 6 different frameworks, domains and complexities to map out which are easiest to build with and which can be scaled to 1000s.
15
31
384
46,501

Time for another Jam Session in the Nous Research discord on Hermes Agent!
This one focused on all the things you all are building. Come, bring the project(s) you are working on or join in to see all the other things people are using Hermes Agent for!
Tuesday May 12th, 4PM EST! See you then!
May 10

Join the Nous Research team for another Hermes Agent Jam in our Discord
This one will be an interactive session, so come prepared to discuss ideas and show off your projects!

26
18
268
523,320
May 11
I'm building an Ultragoal plugin for Hermes Agent after speaking at the first Hermes meetup in Seoul!
I will be release soon!
Thank you for having me @realsigridjin
Thank you for your support @NousResearch @Teknium
3
1
9
655

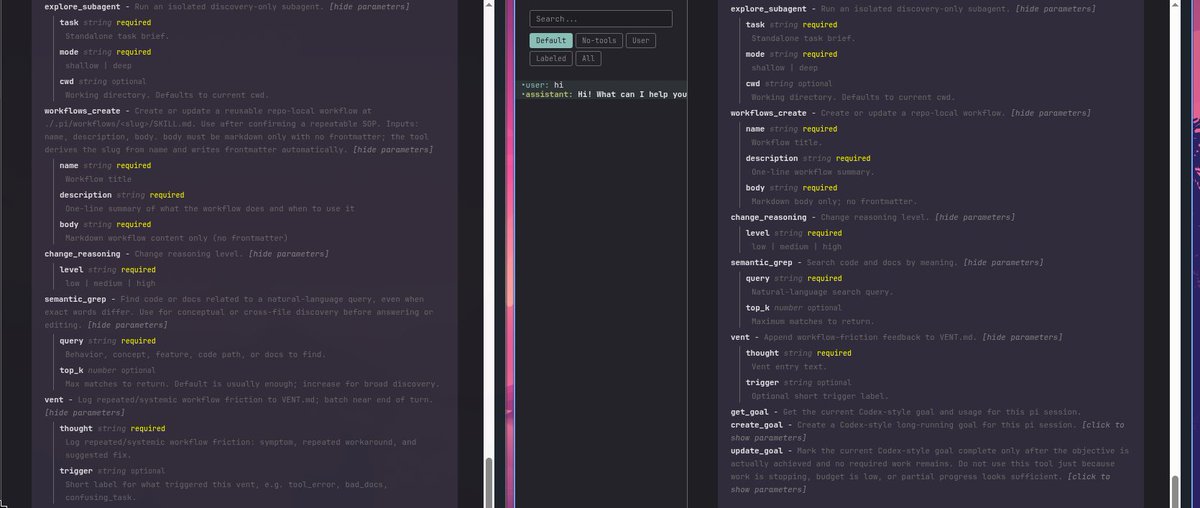
Token-savings-maxxing™ updates to everything. And massive anti-confusion measures. I am not entirely sure how the heck they were previously usable at all by agents.
- pi install npm:@howaboua/pi-auto-reasoning-tool
- pi install npm:@howaboua/pi-markdown-workflows - pi install npm:@howaboua/pi-semantic-grep - pi install npm:@howaboua/pi-vent
"Hi --no-skills" from 3k tokens in the morning to 2.6k tokens.
"Hi with skills" from 4.6 to 3.9k.
Howabout that, big harnesses?
2
5
66
4,816



May 8
$500 headphone, not working well, connected with no sound
Over 50k people agree with that issue their official Q&A site, but they never fix it.
If I had to pick the single biggest piece of overpriced, unrepairable trash on Earth, it'd be Apple's AirPods Max.
youtu.be/woo-Pj60sl0?si=buqe…
90