
Co-founder of Vindigo, Mr. Number, and Compound Eye.
Joined July 2007
- Tweets 823
- Following 490
- Followers 756
- Likes 14
31 Photos and videos




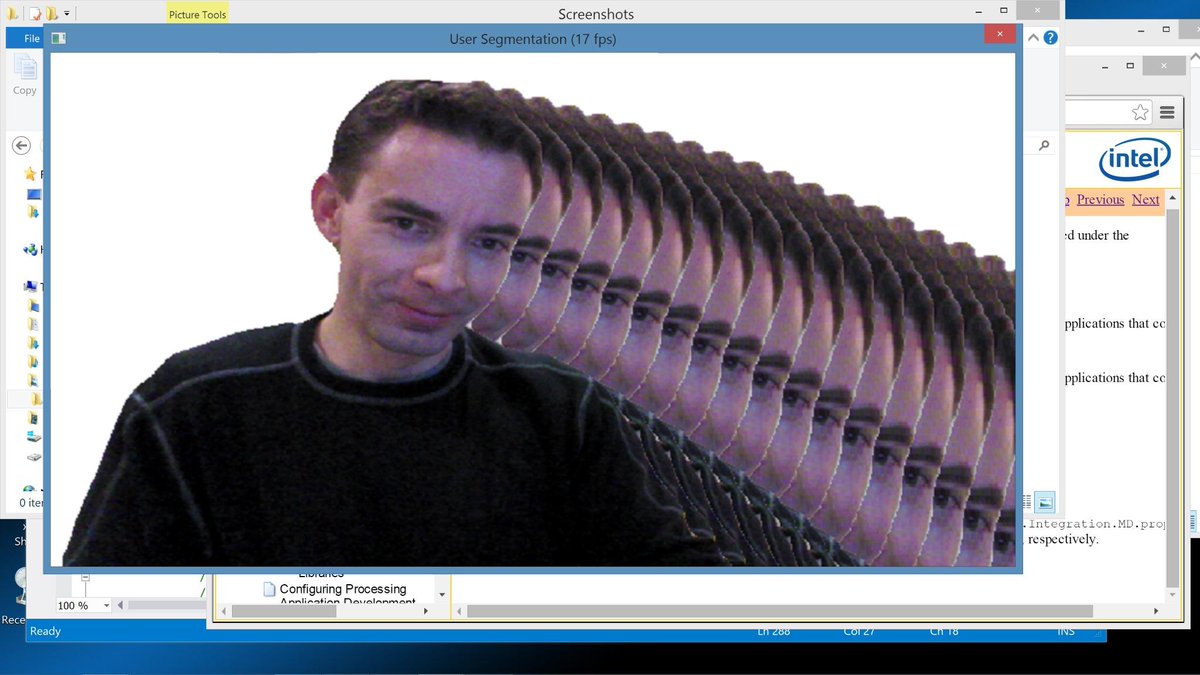


6 Jan 2023
I'm at CES giving demos of
@compoundeyeinc
real-time 3D perception tech. We leverage automotive-grade cameras for on road and off road perception tasks. Find me at booth #61401 in Tech West at the Venetian Hotel Expo January 7th and January 8th. #CES2023 #AutonomousVehicles
2
7
1,290
3 Oct 2022
This beautiful work by @cut_pow suggests diffusion models have at minimum learned to reproduce static monocular depth cues. Not clear if that's the same as learning 3D geometry. But if not, MiDaS has no 3D knowledge either; it uses the same cues. FYI @jon_barron
3 Oct 2022

1.2 It heavily relies on the quality of depth maps, and uses the assumption that SD has implicit knowledge of the scene geometry in an image. So therefore it can plausibly inpaint missing parts without explicitly knowing underneath 3D meshes of the scene
1
2
23 Aug 2022
#stablediffusion is remarkable. The failure cases are as interesting as the successes. Prompt "photograph of a young woman looking through a telescope, professional" @karpathy
21 Feb 2022
The term "self-driving" is problematic but this is a really good summary of what's available today.
21 Feb 2022

Great to see @ConsumerReports' Kelly Funkhouser on @CBSMornings giving an accurate overview of the current state of driver assistance technology. youtube.com/watch?v=W3n6bhl2…
3
18 Feb 2022
Thanks for having us! We really enjoyed the conversation. @TheAutonocast
18 Feb 2022

New episode now live: @devitt and @TaraniDuncan of @compoundeyeinc came by to talk camera-based depth perception with the gang, and in the process blew up all the stale, contrived "camera or lidar" debates. You want to listen to this one! autonocast.com/blog/2022/2/1…
1
3
22 Jul 2021
I am very proud of the team that built this
22 Jul 2021
Our first blog post gives an overview of how our camera-only 3D perception system sees the world
compoundeye.com/post/introdu…
6
Jason Devitt retweeted

19 Feb 2017
@compoundeyeinc wins the first ever autonomous race at @diyrobocars using our open source code github.com/compound-eye/wind…
2
26
70
Jason Devitt retweeted

18 Jun 2015
Irish J1 Berkeley Tragedy Fund gofundme.com/J1tragedyfund?p… via @gofundme
2
4
5 Jul 2014
People prefer electric shocks to time alone with their thoughts bostonglobe.com/news/science…
2
15 May 2014
Tried this brilliant standing desk at the SF Hardware Meetup and decided to back it on @Kickstarter kck.st/1sEnfNk
1
1
13 May 2014
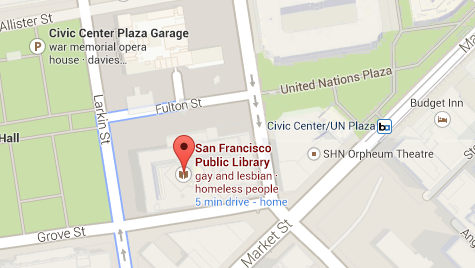
This branch of SF public library is highly specialized according to Google.
1
13 Mar 2014
Eventful week in Mission Bay. A train just hit an unoccupied car at 16th and 7th while I was out for a run.


Jason Devitt retweeted

12 Mar 2014
4 ALARM FIRE (update): Crews taking defensive approach. Per @climbSF "We're about 80% sure it's the Arden condominium building."
3
16
3
14 Sep 2013
Know of a startup looking for office space in the Mission? This space belongs to good a friend of mine. sfbay.craigslist.org/sfc/off…