
Carpenter by day Tech Inventor by night. DialectForge and AuthShield (patents pending)
Joined February 2017
- Tweets 1,068
- Following 312
- Followers 303
- Likes 1,142
95 Photos and videos










Pinned Tweet

Apr 26
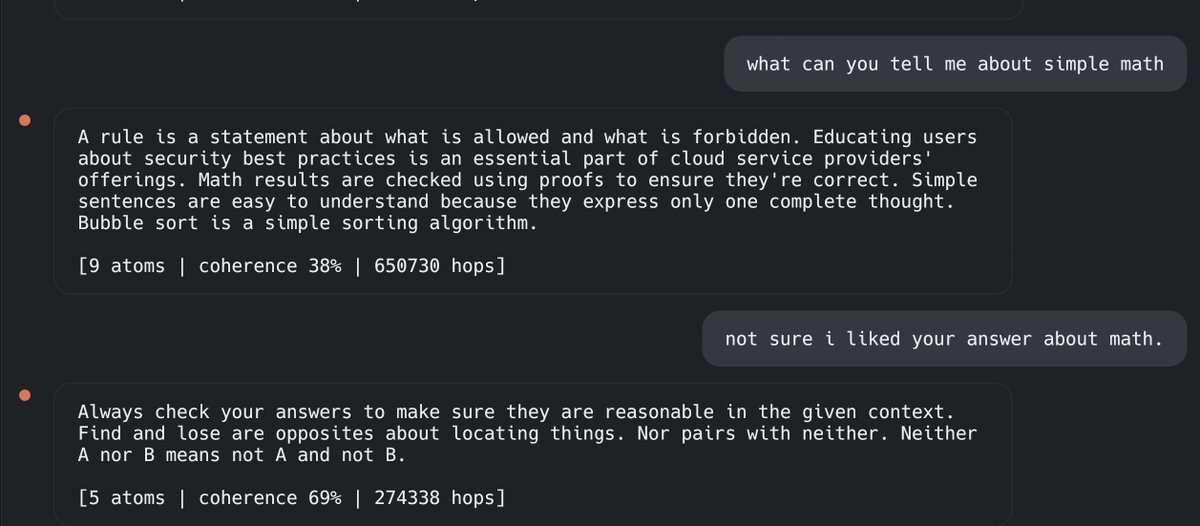
On a single Ryzen 9 5800X, Lu processed 151,525 documents and created 3.7 million facts in under 4 hours, with zero garbage ingestion. The same volume of training would take days to weeks on massive GPU clusters for a traditional LLM.
#AI #MachineLearning #NonLLM #SelfImprovingAI #TrainingEfficiency #FutureOfAI
1
6
260
Jun 13
Crazy that we are probably going to be required to show proof of Citizenship to use AI before we will have to show proof of Citizenship to vote. (Both of which are national security issues)
#ClaudeFable5 #VoterID #DigitalIdentity
7
Jun 1
Had my head down working on Lu AI for a while now. Working on training pipelines and keeping RAM usage down. It’s a ton of work.
While that is cooking I decided to put work in on DF messenger.
1
39
May 18
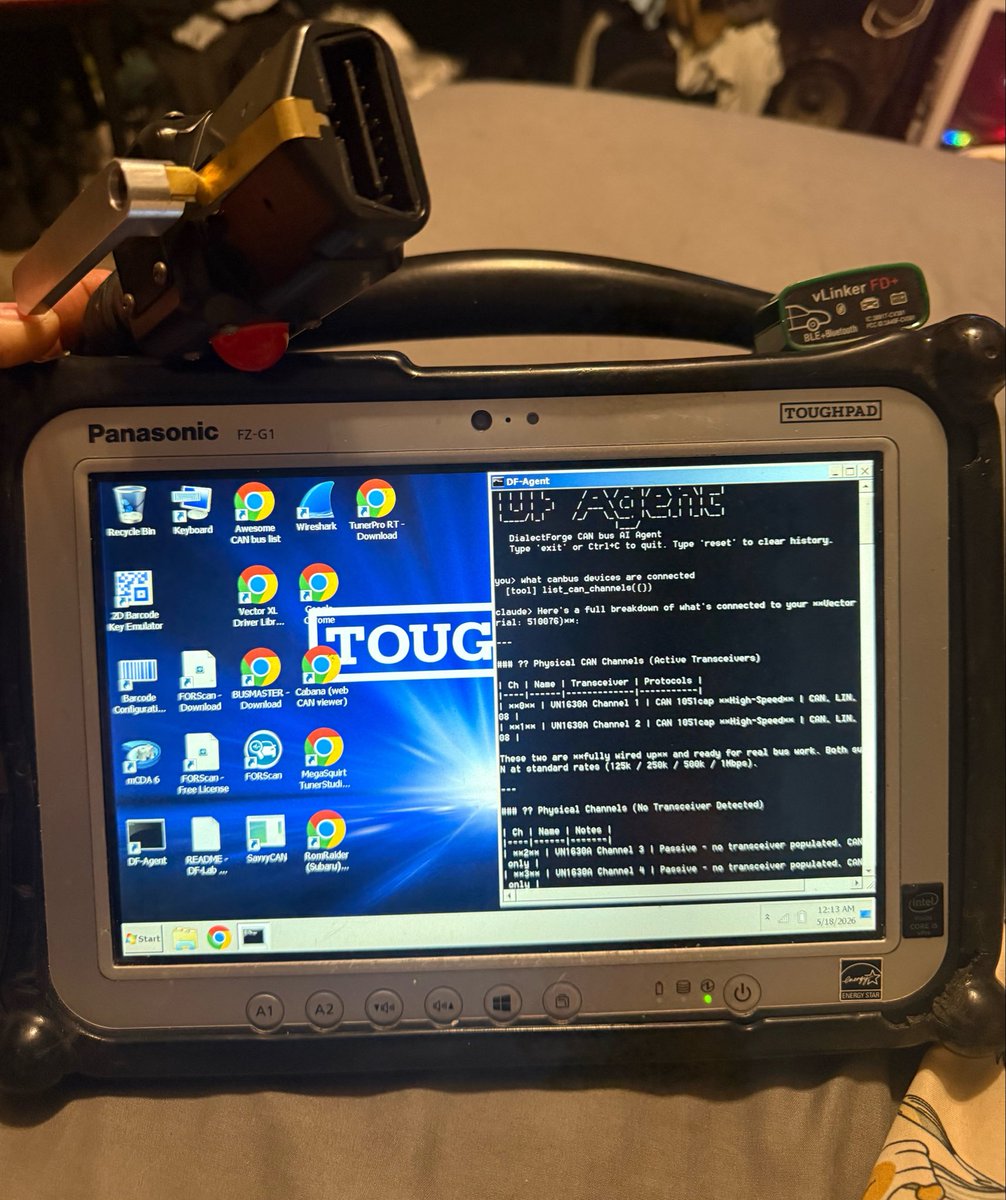
Built a custom AI console that reads CANbus, talks to the car through a vLinker Protofab OBD cable, and uses Claude to automatically diagnose and tune vehicles.
Started with a scrap Chrysler plant touchpad that had a vn1630a CAN card already in it.
#BuildInPublic #IndieAI #AutomotiveAI #CANbus #Maker
Claude, why is my check engine light on?
4
1
68
May 6
Waiting for parts to fix the Audi, having to ride my dirt-bike to work everyday. It’s 30 degrees this morning with snow flurries. Why do I choose to do everything in expert mode?
4
85
Apr 30
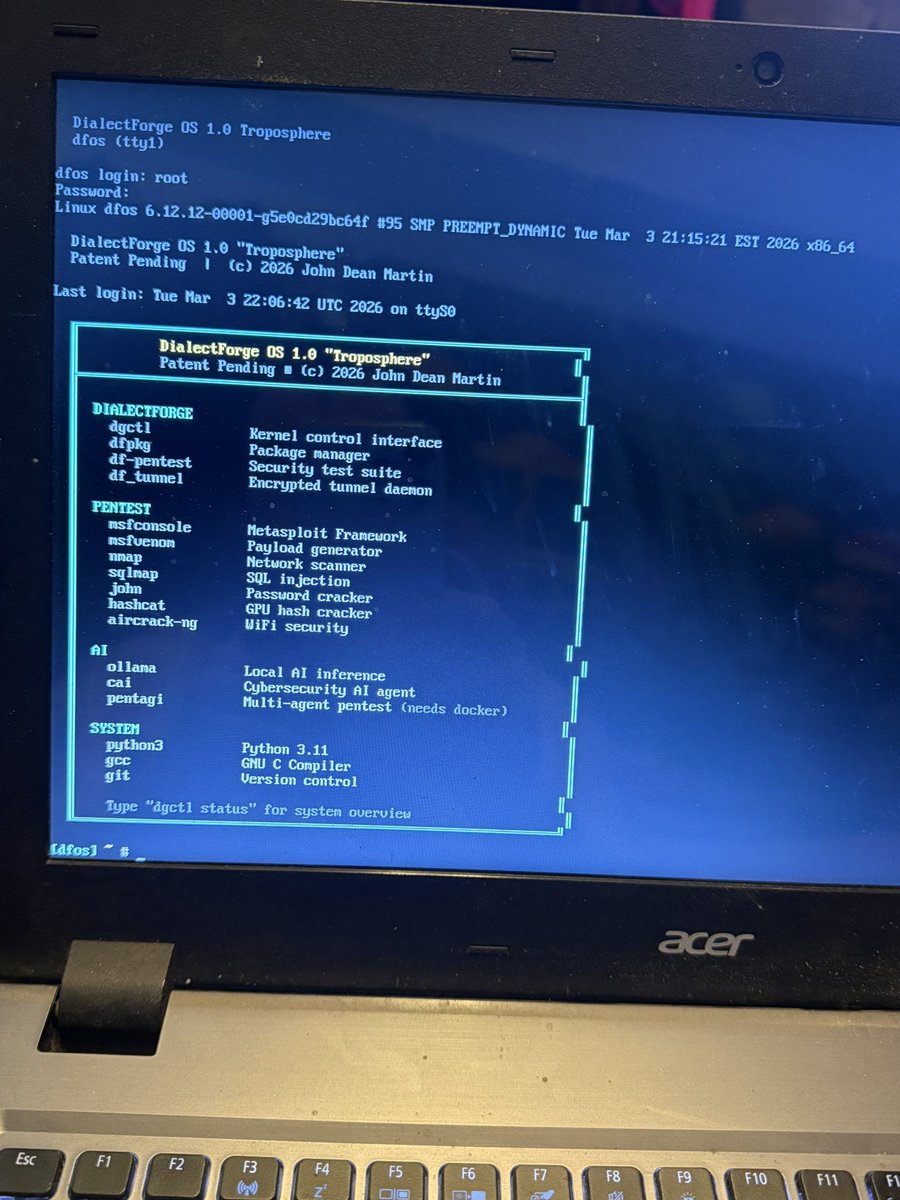
Copy Fail (CVE-2026-31431) on DFoS Troposphere: not vulnerable.
DFoS is on Linux 6.12.12, technically inside the vulnerable kernel range. The vulnerable source file (crypto/algif_aead.c) is in the tree.
We don’t compile it.
Released March 19 2026.
#copyfail #CVE202631431 #LinuxSecurity
1
292
Apr 29
What Lu does structurally that LLMs fundamentally can’t:
1. Honest refusal
Lu’s K gate refuses to answer when it has no grounding. LLMs hallucinate. Example: “quantum jellyfish dynamics” → Lu says “I matched on quantum but jellyfish and dynamics didn’t activate, so I won’t fabricate.” GPT-4 writes you a confident paragraph about quantum mechanics in jellyfish. This isn’t RLHF — it’s structural.
2. Source attribution
Every Lu answer traces back to specific nodes and bonds in the graph. You can ask “where did you get that?” and get the exact chain. LLMs have no traceable source — answers are just a soup of weights.
3. Determinism
Same brain same query = bit-for-bit identical answer. LLMs are non-deterministic by design. Critical for legal, audit, and compliance use cases.
4. No memorized data leakage
LLMs regurgitate training data (phone numbers, copyrighted text, PII). Lu’s brain is a fully inspectable graph. You can audit exactly what’s in there.
5. True right-to-be-forgotten
Lu can surgically delete a specific fact. LLMs can’t unlearn — information is entangled across billions of parameters. Major AI labs literally cannot comply with GDPR deletion requests.
6. Prompt injection immunity
Lu has no system prompt layer. There’s nothing to override or trick. A query is just a query.
7. Real confidence calibration
When Lu refuses, it tells you why (“max activation 0.577, below threshold”). LLM “confidence” is just token probability and doesn’t correlate with truth.
8. Full audit trail
Every bond carries provenance — when it was added, from what document, and by what operation. LLMs have nothing like this.
9. Failure mode
Lu’s failure mode is silence. LLM failure mode is confident bullshit. For medical, legal, military, or kid-facing applications — that difference is everything.
Lu isn’t trying to be a better LLM. It’s built on a completely different foundation.
#LocalAI #NonLLM #GraphAI #ReasoningAI #BuildInPublic #AISafety
80
Apr 29
While most local AI runs on transformer LLMs, Lu uses a graph-based, multi-agent architecture with:
• Structured reasoning chains (not just next-token prediction)
• Built-in refusal when knowledge is missing
• Revocable explainable knowledge
• Session memory that actually works
• Extremely low resource requirements
Early days, but the foundation is deliberately different from the LLM paradigm.
#LocalAI #NeuroSymbolic #GraphReasoning #LLMAlternatives #AIArchitecture
1
180
Apr 29
Asked Lu the bat-and-ball problem ($1.10 total, bat costs $1 more than ball, what’s the ball?).
Most AIs confidently say $0.10. Wrong, but confident.
Lu said: “My best guess is $0.10 but verify — this needs algebraic setup beyond my current scope.”
Provenance > confidence. Honest IDK > confident hallucination.
Single Ryzen. No LLM. #NonLLM #AI
1
2
52
John Martin retweeted

Apr 28
@Tesla @elonmusk @gork
Get a real NEC 220.82 EV charger assessment from an IBEW Master Electrician — $12.99. evchargeright.com/cars/tesla…
1
2
168


Apr 27
LLMs hallucinate. Need datacenters. Charge per token. Own your data forever. Need full retraining for new knowledge.
Lu does none of that. Your own server, encrypted with your key. Trains on your docs in hours. Says "I don't know" instead of making things up.
Demo soon.
2
75
Apr 24
Weird how quiet the Claude complaint crowd got now that usage is better than before. @AnthropicAI @ClaudeDevs
60
Apr 24
Putting Lu’s brain on a server tonight.
No GPU needed — she’s not an LLM. She learns from conversations now, and by this weekend she’ll be trained up enough for people to try her out. #AI #BuildInPublic #AG
1
114
Apr 20
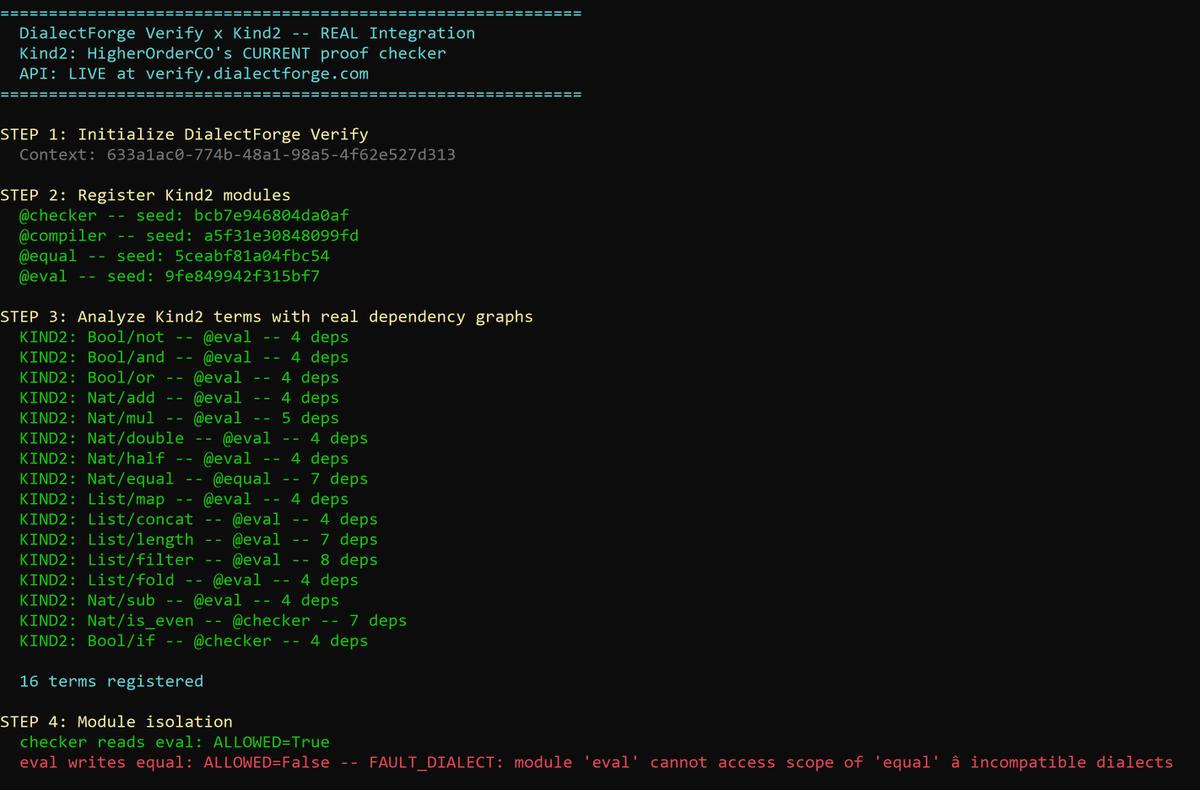
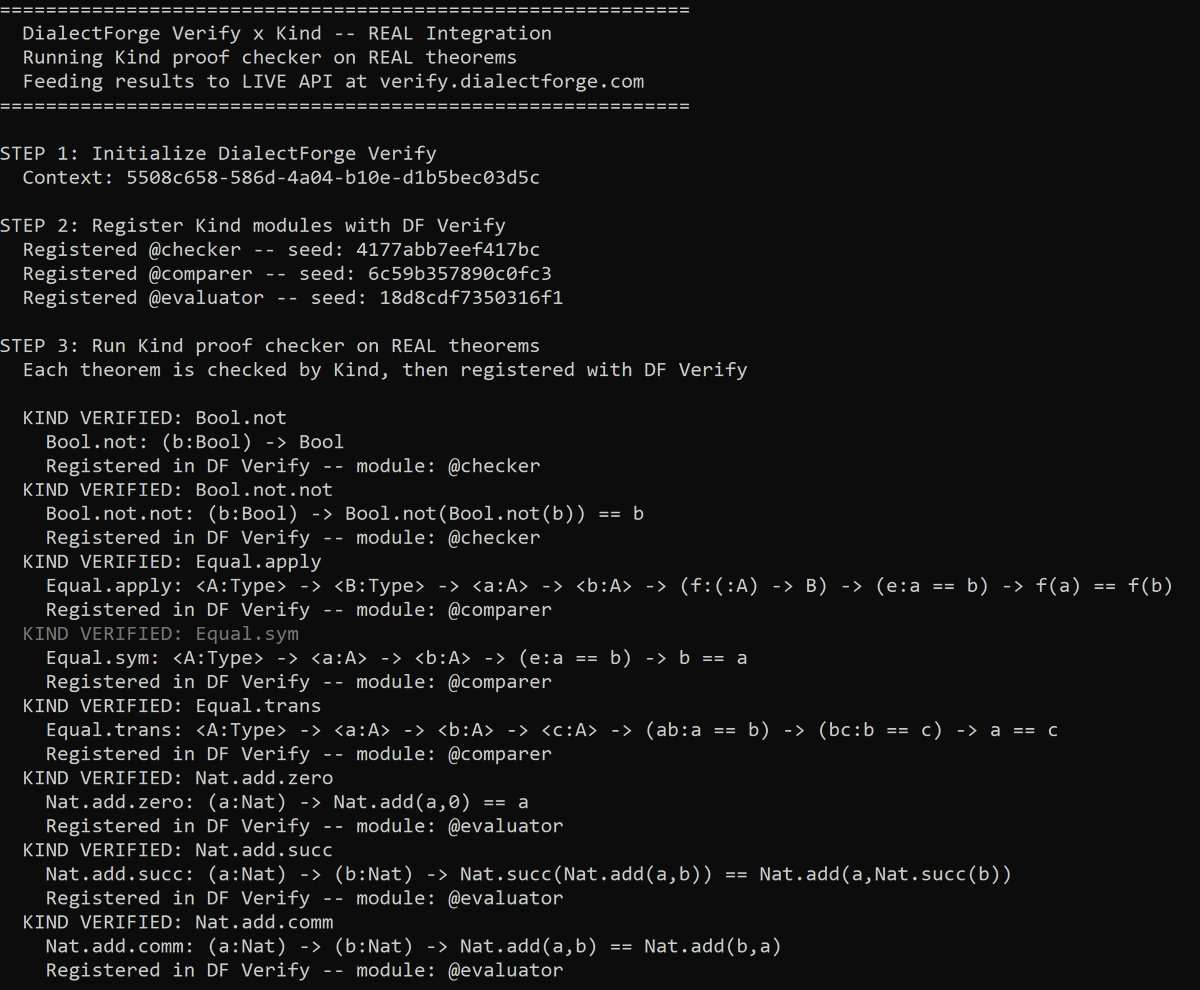
Something worth saying out loud: it’s important to admit when you didn’t pull off what you set out to do.
I saw a pain point in proof and verification systems recently and thought DialectForge could solve it. The issue is that while I know my way around a lot in tech, formal verification isn’t a space I work in or deeply understand. So I leaned on AI to help me bridge the gap.
I think I actually did solve a real problem. But I don’t know the space well enough to market it or hold a meaningful conversation with anyone in it. Building something and being the right person to take it to market aren’t the same thing, and I had to sit with that this week.
Going back to working on what I’m actually passionate about and understand.
1
64
Apr 20
The SDK is up on GitHub. If anyone in that field wants to see what it’s about, I’m happy to provide API keys free of charge.
github.com/dialectforge/dial…
51