
Joined August 2025
- Tweets 170
- Following 0
- Followers 2,170
- Likes 178
54 Photos and videos









Pinned Tweet

30 Oct 2025
Drowning in the sea of Discrete Diffusion papers? 🌊
We got you.
Join our Reading Group!
From theory → empirics, and language → molecules — we’ll decode the chaos together 💫
Join the cult—uh, I mean community 😇
👉 Google Group: groups.google.com/g/diffusio…
(1 / 2)

2
7
40
9,485
📢 June 15 (Mon): Uniform Diffusion Models Revisited: Leave-One-Out Denoiser and Absorbing State Reformulation
🤔 Discrete diffusion models are often trained through clean-data prediction, but the prediction can be used in different ways to define the reverse dynamics. In Masked Diffusion Models (MDM) these choices largely coincide, whereas in Uniform Diffusion Models (UDM) they do not.
💡 The authors show that the standard plug-in bridge parameterization for UDM is not optimized by the denoising posterior, but by a leave-one-out posterior that predicts each clean token without using its own noisy observation. This identifies a mismatch between the plug-in ELBO and the usual cross-entropy denoising objective.
🔧 The authors characterize the leave-one-out target and derive exact conversions between the denoiser, the leave-one-out posterior, and the score. These conversions allow them to disentangle parameterization and the training objective.
📈 Their results also lead to inference improvements without any additional training through an informed predictor-corrector sampler and improved temperature sampling based on the leave-one-out predictor.
🔧 The authors further introduce an absorbing-state reformulation of uniform diffusion that preserves the UDM joint law while decomposing it into masked-diffusion-like sampling operations, with simpler denoising posteriors, carry-over unmasking, and a natural remasking mechanism.
📈 On language modeling, leave-one-out parameterizations consistently improve UDM generation, while the absorbing construction matches or surpasses masked diffusion. These results suggest that the empirical gap between masked and uniform diffusion is driven less by the choice of marginals themselves than by parameterization and sampling design.
This Monday, Samson Gourevitch (@samsongvch, samsongourevitch.github.io/), Yazid Janati (@yjelid, yazidjanati.github.io/), and Dario Shariatian (@dario_sha, darioshar.github.io/) will present their paper "Uniform Diffusion Models Revisited: Leave-One-Out Denoiser and Absorbing State Reformulation".
1
5
22
3,722
Collaborators: Umut Simsekli (di.ens.fr/~simsekli/), Eric Moulines (scholar.google.com/citations…), Eric P. Xing (@ericxing), Alain Durmus (alain.perso.math.cnrs.fr/)
Paper link: arxiv.org/abs/2605.22765
1
3
303
Meeting link: teams.live.com/meet/93565799…
2
218
Discrete Diffusion Reading Group retweeted

Jun 12
Join our reading group next Monday!
Topic: Uniform Diffusion Models Revisited
Presenters: Samson Gourevitch (@samsongvch), Yazid Janati (@yjelid), and Dario Shariatian (@dario_sha)

📢 June 15 (Mon): Uniform Diffusion Models Revisited: Leave-One-Out Denoiser and Absorbing State Reformulation
🤔 Discrete diffusion models are often trained through clean-data prediction, but the prediction can be used in different ways to define the reverse dynamics. In Masked Diffusion Models (MDM) these choices largely coincide, whereas in Uniform Diffusion Models (UDM) they do not.
💡 The authors show that the standard plug-in bridge parameterization for UDM is not optimized by the denoising posterior, but by a leave-one-out posterior that predicts each clean token without using its own noisy observation. This identifies a mismatch between the plug-in ELBO and the usual cross-entropy denoising objective.
🔧 The authors characterize the leave-one-out target and derive exact conversions between the denoiser, the leave-one-out posterior, and the score. These conversions allow them to disentangle parameterization and the training objective.
📈 Their results also lead to inference improvements without any additional training through an informed predictor-corrector sampler and improved temperature sampling based on the leave-one-out predictor.
🔧 The authors further introduce an absorbing-state reformulation of uniform diffusion that preserves the UDM joint law while decomposing it into masked-diffusion-like sampling operations, with simpler denoising posteriors, carry-over unmasking, and a natural remasking mechanism.
📈 On language modeling, leave-one-out parameterizations consistently improve UDM generation, while the absorbing construction matches or surpasses masked diffusion. These results suggest that the empirical gap between masked and uniform diffusion is driven less by the choice of marginals themselves than by parameterization and sampling design.
This Monday, Samson Gourevitch (@samsongvch, samsongourevitch.github.io/), Yazid Janati (@yjelid, yazidjanati.github.io/), and Dario Shariatian (@dario_sha, darioshar.github.io/) will present their paper "Uniform Diffusion Models Revisited: Leave-One-Out Denoiser and Absorbing State Reformulation".
5
24
2,827
Diffusion LLMs are heating up!
Join our discord mailing list to stay on top of the latest innovations in this field.
Details: d-llms.com
Jun 12

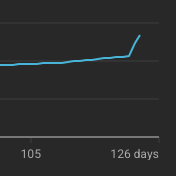
After DiffusionGemma dropped, views spiked on our @diffusion_llms Reading Group video: “The Diffusion Duality.”
Video: youtu.be/FCO-nnqHOqQ?si=gt6I…
Join the Discord mailing list: d-llms.com
The diffusion duality: s-sahoo.com/duo/
7
720
Curious what’s under the hood of DiffusionGemma?
Begin with these two tutorials covering its foundational building blocks:
1. Uniform-state Diffusion: youtu.be/FCO-nnqHOqQ?si=yoms…
2. Block diffusion: iclr.cc/virtual/2025/oral/31…
4
30
2,547
Discrete Diffusion Reading Group retweeted

Jun 11
Want to understand what powers DiffusionGemma?
Start with these two tutorials on its core building blocks:
1. Uniform-state Diffusion: youtu.be/FCO-nnqHOqQ?si=yoms…
2. Block diffusion: iclr.cc/virtual/2025/oral/31…
Jun 10

Meet DiffusionGemma!
An experimental open model that explores a fast approach to text generation, released under an Apache 2.0 license.
Moving beyond sequential, token-by-token processes to generate entire blocks of text simultaneously. Here’s what’s new with DiffusionGemma: 👇
2
10
56
6,044
📢 Missed the talk? Check out the recording on YouTube: youtube.com/watch?v=x1chemjC…
📢 June 8 (Mon): Entropy-Gated Continuous Bitstream Diffusion for Language
🤔Diffusion language models (DLMs) promise parallel, order-agnostic generation, but on standard benchmarks they have historically lagged behind autoregressive models in sample quality and diversity.
💡Recent continuous flow and diffusion approaches over token embeddings have narrowed this gap, suggesting continuous state spaces are highly effective for language. In this work, the authors further close the autoregressive gap by modeling text as a continuous diffusion process over fixed-width binary bitstreams.
🔧Their approach represents semantic tokens as analog bit sequences and utilizes a matched-filter residual parameterization to isolate contextual learning from analytic independent-bit posteriors. Crucially, they adopt a stochastic sampler that applies Langevin-type corrections gated by the entropy-rate profile, automatically concentrating stochasticity in high-information regions while remaining nearly deterministic elsewhere.
📈On the One Billion Word Benchmark (LM1B), their 130M-parameter bitstream model reaches a generative perplexity (Gen. PPL) of 59.76 at matched real-data entropy (4.31) using 256 neural function evaluations (NFEs), decisively outperforming prior DLM baselines and reaching the autoregressive reference. On OpenWebText (OWT), the authors' stochastic sampler establishes a new continuous-DLM Pareto frontier, achieving Gen. PPL = 27.06 at an entropy of 5.26 using 4× fewer steps than previous 1024-NFE baselines.
🌍As an additional architectural benefit, bitstream diffusion removes the O(V) vocabulary scaling bottleneck shared by standard DLMs. By predicting O(log V) bitwise logits via semantic bit-patching, the model yields a reduced memory footprint and higher throughput, demonstrating a scalable paradigm for language generation as vocabulary sizes grow.
This Monday, Georgios Batzolis (@GBatz97, gbatzolis.github.io/) will present his recent work “Towards Closing the Autoregressive Gap in Language Modeling via Entropy-Gated Continuous Bitstream Diffusion”.
1
10
1,829
Discrete Diffusion Reading Group retweeted

🔥 New paper: BlockGen: Flexible Blockwise Sequence Modeling with Hybrid Samplers
Are uniform-state diffusion models (USDMs) always stronger than masked (MDMs) ones? Recent work suggests so. However, a few questions remain open 🤔
w/ @caglarml
(1/11)
4
21
57
3,297
Discrete Diffusion Reading Group retweeted
Jun 5
Glimpses from my CVPR tutorial on Discrete Diffusion.
1
7
52
24,806
Discrete Diffusion Reading Group retweeted

1/3
Most language models generate text the way a typewriter works. They go left to right, one token at a time.
Diffusion language models generate entire sequences by simultaneously refining noise into meaning.
2
4
12
1,657
Discrete Diffusion Reading Group retweeted
Jun 5
Join our reading group next Monday!
Topic: Continuous Bitstream Diffusion for Language
Presenter: Georgios Batzolis (@GBatz97)
📢 June 8 (Mon): Entropy-Gated Continuous Bitstream Diffusion for Language
🤔Diffusion language models (DLMs) promise parallel, order-agnostic generation, but on standard benchmarks they have historically lagged behind autoregressive models in sample quality and diversity.
💡Recent continuous flow and diffusion approaches over token embeddings have narrowed this gap, suggesting continuous state spaces are highly effective for language. In this work, the authors further close the autoregressive gap by modeling text as a continuous diffusion process over fixed-width binary bitstreams.
🔧Their approach represents semantic tokens as analog bit sequences and utilizes a matched-filter residual parameterization to isolate contextual learning from analytic independent-bit posteriors. Crucially, they adopt a stochastic sampler that applies Langevin-type corrections gated by the entropy-rate profile, automatically concentrating stochasticity in high-information regions while remaining nearly deterministic elsewhere.
📈On the One Billion Word Benchmark (LM1B), their 130M-parameter bitstream model reaches a generative perplexity (Gen. PPL) of 59.76 at matched real-data entropy (4.31) using 256 neural function evaluations (NFEs), decisively outperforming prior DLM baselines and reaching the autoregressive reference. On OpenWebText (OWT), the authors' stochastic sampler establishes a new continuous-DLM Pareto frontier, achieving Gen. PPL = 27.06 at an entropy of 5.26 using 4× fewer steps than previous 1024-NFE baselines.
🌍As an additional architectural benefit, bitstream diffusion removes the O(V) vocabulary scaling bottleneck shared by standard DLMs. By predicting O(log V) bitwise logits via semantic bit-patching, the model yields a reduced memory footprint and higher throughput, demonstrating a scalable paradigm for language generation as vocabulary sizes grow.
This Monday, Georgios Batzolis (@GBatz97, gbatzolis.github.io/) will present his recent work “Towards Closing the Autoregressive Gap in Language Modeling via Entropy-Gated Continuous Bitstream Diffusion”.
2
9
1,282
📢 June 8 (Mon): Entropy-Gated Continuous Bitstream Diffusion for Language
🤔Diffusion language models (DLMs) promise parallel, order-agnostic generation, but on standard benchmarks they have historically lagged behind autoregressive models in sample quality and diversity.
💡Recent continuous flow and diffusion approaches over token embeddings have narrowed this gap, suggesting continuous state spaces are highly effective for language. In this work, the authors further close the autoregressive gap by modeling text as a continuous diffusion process over fixed-width binary bitstreams.
🔧Their approach represents semantic tokens as analog bit sequences and utilizes a matched-filter residual parameterization to isolate contextual learning from analytic independent-bit posteriors. Crucially, they adopt a stochastic sampler that applies Langevin-type corrections gated by the entropy-rate profile, automatically concentrating stochasticity in high-information regions while remaining nearly deterministic elsewhere.
📈On the One Billion Word Benchmark (LM1B), their 130M-parameter bitstream model reaches a generative perplexity (Gen. PPL) of 59.76 at matched real-data entropy (4.31) using 256 neural function evaluations (NFEs), decisively outperforming prior DLM baselines and reaching the autoregressive reference. On OpenWebText (OWT), the authors' stochastic sampler establishes a new continuous-DLM Pareto frontier, achieving Gen. PPL = 27.06 at an entropy of 5.26 using 4× fewer steps than previous 1024-NFE baselines.
🌍As an additional architectural benefit, bitstream diffusion removes the O(V) vocabulary scaling bottleneck shared by standard DLMs. By predicting O(log V) bitwise logits via semantic bit-patching, the model yields a reduced memory footprint and higher throughput, demonstrating a scalable paradigm for language generation as vocabulary sizes grow.
This Monday, Georgios Batzolis (@GBatz97, gbatzolis.github.io/) will present his recent work “Towards Closing the Autoregressive Gap in Language Modeling via Entropy-Gated Continuous Bitstream Diffusion”.
2
9
43
6,339
Collaborators: Mark Girolami (@TuringChiefSci), Luca Ambrogioni (@LucaAmb)
Paper link: arxiv.org/abs/2605.07013
1
6
393
Meeting link: teams.live.com/meet/93565799…
1
5
241
Discrete Diffusion Reading Group retweeted
Jun 4
🎊 Discrete Diffusion Meetup @CVPR 🎊
⏰ Saturday (June 6), 5PM
📍The Bear, Colorado Convention Center
DM me if you’d like to chat

1
6
31
4,299
Discrete Diffusion Reading Group retweeted
Jun 2
Discrete Diffusion Tutorial @CVPR tomorrow (Wednesday).
Tutorial name: The Principles of Diffusion Models
Real-Time Continuous & Discrete Diffusion
Location: Colorado Convention Center, Four Seasons 4 - Rooms 301 / 302
Dm me if you'd like to attend it remotely on Zoom.
w/ @JCJesseLai @yukimitsu

2
15
65
6,669
📢 Missed the talk? Check out the recording on YouTube: youtube.com/watch?v=pEejmnA_…
📢 June 1 (Mon): ELF: Embedded Language Flows
🤔Unlike their image-domain counterparts, today’s leading diffusion language models (DLMs) primarily operate over discrete tokens.
💡The authors show that continuous DLMs can be made effective with minimal adaptation to the discrete domain. They propose Embedded Language Flows (ELF), a class of diffusion models in continuous embedding space based on continuous-time Flow Matching. Unlike existing DLMs, ELF predominantly stays within the continuous embedding space until the final time step, where it maps to discrete tokens using a shared-weight network.
🔧This formulation makes it straightforward to adapt established techniques from image-domain diffusion models, e.g., classifier-free guidance (CFG).
📈Experiments show that ELF substantially outperforms leading discrete and continuous DLMs, achieving better generation quality with fewer sampling steps. These results suggest that ELF offers a promising path toward effective continuous DLMs.
This Monday, Keya Hu (@HuLillian39250) and Linlu Qiu (@linluqiu) will present their jointly led paper ELF.
7
1,525
Discrete Diffusion Reading Group retweeted
May 30
Join our reading group next Monday!
Topic: ELF: Embedded Language Flows
Presenters: Keya Hu (@HuLillian39250), Linlu Qiu (@linluqiu)
📢 June 1 (Mon): ELF: Embedded Language Flows
🤔Unlike their image-domain counterparts, today’s leading diffusion language models (DLMs) primarily operate over discrete tokens.
💡The authors show that continuous DLMs can be made effective with minimal adaptation to the discrete domain. They propose Embedded Language Flows (ELF), a class of diffusion models in continuous embedding space based on continuous-time Flow Matching. Unlike existing DLMs, ELF predominantly stays within the continuous embedding space until the final time step, where it maps to discrete tokens using a shared-weight network.
🔧This formulation makes it straightforward to adapt established techniques from image-domain diffusion models, e.g., classifier-free guidance (CFG).
📈Experiments show that ELF substantially outperforms leading discrete and continuous DLMs, achieving better generation quality with fewer sampling steps. These results suggest that ELF offers a promising path toward effective continuous DLMs.
This Monday, Keya Hu (@HuLillian39250) and Linlu Qiu (@linluqiu) will present their jointly led paper ELF.
6
39
5,220
📢 June 1 (Mon): ELF: Embedded Language Flows
🤔Unlike their image-domain counterparts, today’s leading diffusion language models (DLMs) primarily operate over discrete tokens.
💡The authors show that continuous DLMs can be made effective with minimal adaptation to the discrete domain. They propose Embedded Language Flows (ELF), a class of diffusion models in continuous embedding space based on continuous-time Flow Matching. Unlike existing DLMs, ELF predominantly stays within the continuous embedding space until the final time step, where it maps to discrete tokens using a shared-weight network.
🔧This formulation makes it straightforward to adapt established techniques from image-domain diffusion models, e.g., classifier-free guidance (CFG).
📈Experiments show that ELF substantially outperforms leading discrete and continuous DLMs, achieving better generation quality with fewer sampling steps. These results suggest that ELF offers a promising path toward effective continuous DLMs.
This Monday, Keya Hu (@HuLillian39250) and Linlu Qiu (@linluqiu) will present their jointly led paper ELF.
3
14
82
20,469
Collaborators: Yiyang Lu (@Lyy_iiis), Hanhong Zhao (hope7happiness.github.io/), Tianhong Li (tianhongli.me/), Yoon Kim (people.csail.mit.edu/yoonkim…), Jacob Andreas (@jacobandreas), Kaiming He (people.csail.mit.edu/kaiming…)
Paper link: arxiv.org/pdf/2605.10938
1
1
2
956
Meeting link: teams.live.com/meet/93565799…
2
627