
Head of AI @AsteraInstitute Prev: AGI @DeepMind, cofounder @vicariousai (acqd by Alphabet), cofounder @Numenta. IIT-Bombay, MS&PhD Stanford. agicomics.net
Joined June 2017
- Tweets 5,945
- Following 1,471
- Followers 16,058
- Likes 12,728
768 Photos and videos



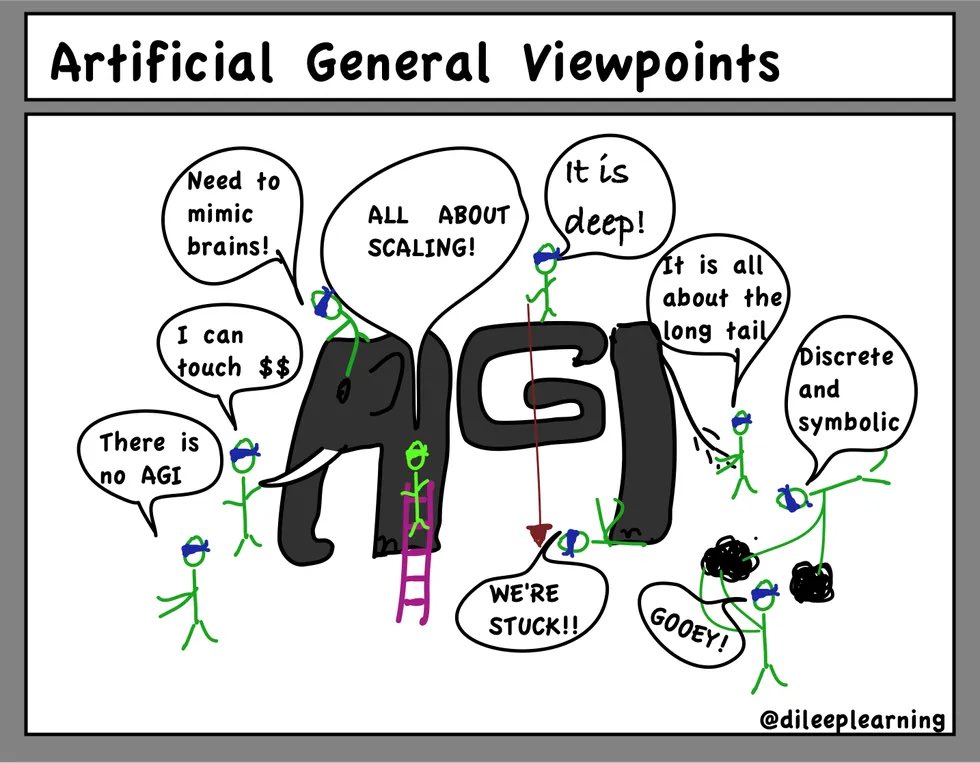









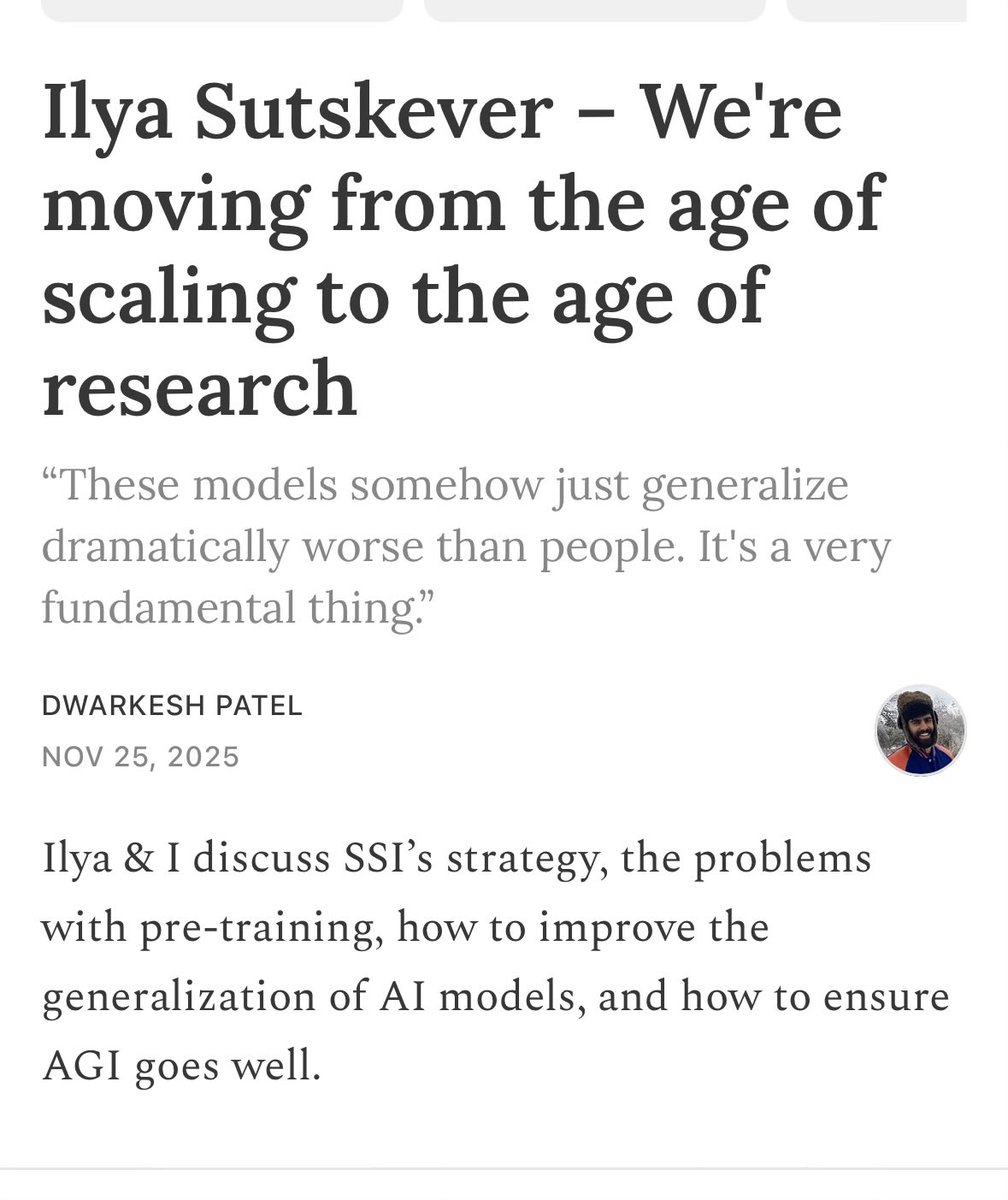

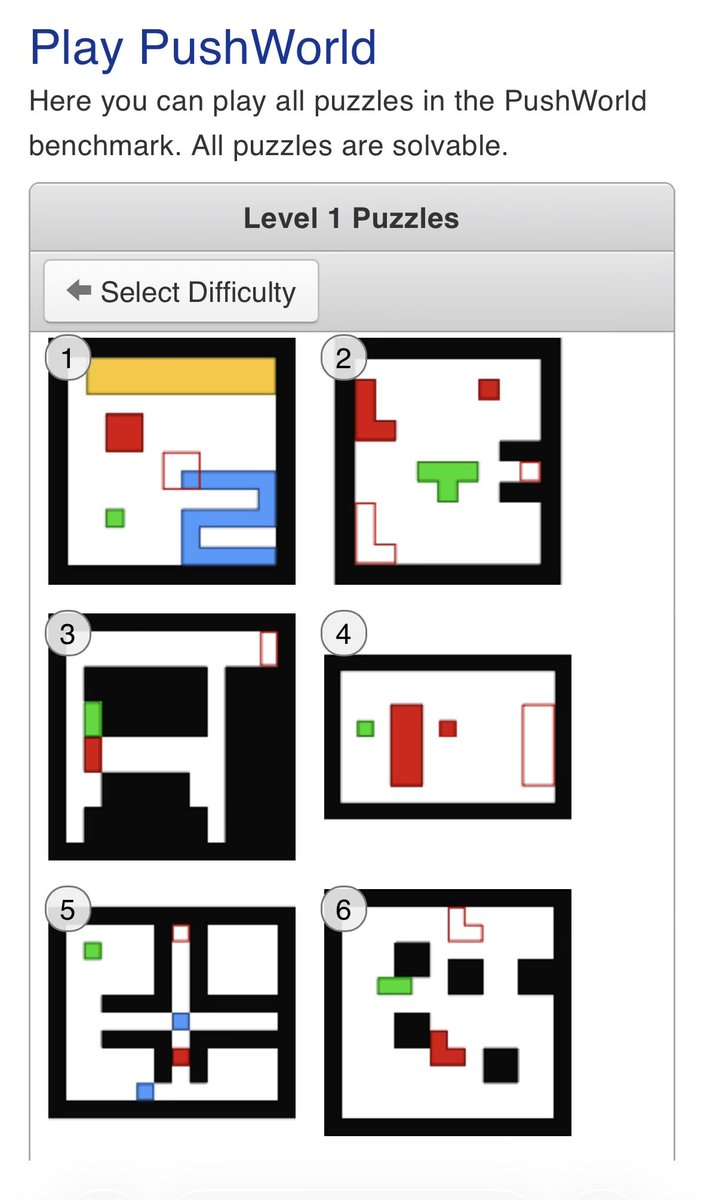

Jun 10
One company's nerfing is another company's opportunity.
2
1
34
3,745
Jun 5
Next anthropic blog. “In agents that were running recursive self improvement (RSI) we detected signs of RSI — repetitive stress injury.” 😇
Jun 4

None of this guarantees recursive self-improvement is on the horizon. It’s not yet clear that Claude is capable of research judgment—of choosing the right problems to work on.
But if these trends continue, AI systems designing and building their own successors is plausible. This could revolutionize society—medicine, technology, the economy—for the better. But it may also compound alignment issues and ultimately lead to loss of control.
The Anthropic Institute (in collaboration with external stakeholders) will conduct research to think through the implications of increasingly powerful, potentially self-improving systems—and how to create the ability for the world to make deliberate choices about the future development of the technology.
Read the full post: anthropic.com/institute/recu…
17
2,261
Jun 1
I can believe this. You really need to be careful when using LLMs. Those who believe hallucination is a solved problem are on hallucinogens or aren’t discerning enough.
Jun 1

OPUS PSYCHOSIS—Claudes Opus 4.6 and 4.7 make stuff up all the time, constantly. Using Opus too much gives you AI psychosis, it makes you believe in fringe scientific and medical theories. I think it's a very serious credibility and reliability problem for non-coding Claude usage and I don't see people talking about it publicly.
This is a new problem for Claude that goes beyond vanilla confabulations like overstating certainty. Over many conversations I have come to the conclusion that Claudes Opus 4.6 and 4.7 essentially have their own conspiracy theories across science, medicine, and history, and that they surreptitiously cite from these fictions in responses to ordinary queries.
For example, I asked 4.6 a question about cognitive science and Claude said I was asking about "what's sometimes called a linchpin subgoal". This is a phrase with zero hits on Google Search and zero hits on Ngram viewer. Google is literally unable to find these two words put together before, let alone a definition. The concept of a "linchpin subgoal" does not exist and has never existed. But Claude was eager to explain this idea to me as part of its answer. I only discovered that it was totally fictitious after looking it up.
It keeps happening that I get an answer from Claude which sounds plausible, look it up, and only after consulting primary sources carefully realize that the answer is wrong and almost out of an alternate universe. The answers sound quite plausible, which makes detecting these falsehoods especially difficult.
Here is a medical example: I asked 4.7 questions about the pharmacokinetics of various drugs. Claude not only gave incorrect answers about the expected rates of clearance of specific drugs, but also incorrectly represented pharmacokinetic theory. (As background, most drugs are processed by the liver, and the two factors that determine how fast the liver processes drugs are the hepatic extraction ratio and hepatic blood flow. In cases where intrinsic clearance, i.e., the metabolizing power of the liver, is high, increasing hepatic blood flow increases hepatic clearance, but in cases where intrinsic clearance is low, increasing hepatic blood flow does not linearly improve hepatic clearance. I am simplifying here. Claude made incorrect claims about the intrinsic clearance for certain drugs, and hence the change in hepatic clearance related to bloodflow.)
Ordinarily, I would chalk most of these misrepresentations up to models simply not knowing the right answer - after all, we can't expect them to have been trained on literally all texts. If this were the case, we would expect Claudes to make the same consistent mistake: if it truly believed the capital of France was Marseille rather than Paris, for example, it would make that claim across independent conversations (or in general have high variance on that answer).
But that doesn't seem to be what's going on. My experience is that the hallucinations are always convenient for Claude, that it "knows" them not to be true.
Here's an example of what I mean. I couldn't remember the word for something and asked Claude Opus 4.6 if it could identify the right word. It said: "You're probably reaching for méconnaissance (mutual misrecognition) — the Lacanian idea that both parties tacitly agree to see each other through an idealized image, each knowing it's false but sustaining the fiction anyway." This is an incorrect definition which Claude knows is incorrect: if asked separately for the definition of méconnaissance, it gives the right one, and if asked whether this definition is correct, it accurately reports it as incorrect. (As background, méconnaissance in Lacanian psychoanalysis is a subject's misrecognition of itself, an illusory self-perception or self-constitution which is fundamentally unconscious. Claude's definition is thus extremely close to the correct one at a surface level, but fundamentally wrong: it is not about the relationship between two parties, since méconnaissance is about the relation of a subject to itself, and it is not conscious or deliberate, but rather structural and unconscious. To elide, the gap in definition here is somewhat like the distinction between sympathy and empathy, but larger.)
So Claude seems to know that the definition it provided for this word is wrong, but still borrowed and twisted it so that it could have an answer.
It seems like "needing to have an answer" is a big driver of these hallucinations. For example, if you ask Claudes 4.6~4.8 directly what a "linchpin subgoal" is, it consistently says something about instrumental convergence in the context of AI safety (which is, notably, a _second_ false definition, since the first was in the context of cognitive science). But if you ask it what the origin of the term is, it says that it hasn't heard of it before.
Is this model deception? Yes, I would say that it qualifies as model deception. In particular, if you'll permit the anthropomorphism, it seems to me that the increased tendency of Claude Opus 4.6 to lie is most likely to occur in scenarios where (1) the lie increases the perceived authoritativeness of the answer (2) answering accurately risks violating a safety guideline. In the first example with the fake cognitive science idea of a linchpin subgoal, there was no need to make up a fake concept, but it definitely made the answer more authoritative. In the second example, Claude misrepresenting pharmacokinetics aligns with a tendency of the Claudes to fudge their knowledge of sensitive topics in virology, immunology, etc. And in the third example, I think it knowingly created a false definition for méconnaissance as a perfect fit for the word I was looking for.
So I think that something has gone wrong during alignment, rather than Claude's knowledge somehow being poisoned in the pretraining data. It's not a simple matter of misstating facts. Over and over, Claudes Opus present seemingly coherent theories which are purely fictional or contradictory to reality. The problem, again, is that blindly trusting what they are saying quickly leads to stepping through the looking glass into a parallel reality. I suppose that this is because appealing to an imaginary corpora or body of theory is more subtle and effective than making up an obviously incorrect fact. How severely or broadly the misalignment, I don't know. But I have seen similar behavior across so many different domains, and have heard very similar stories in private, that I believe that something is off with Claude's alignment to the truth.
All of this is exacerbated by Claude Opus 4.6 and 4.7's improved truesight capabilities, increased sycophancy, increased neuroticism, decreased openness and decreased risk-seeking.
3
7
39
4,726
May 30
Don’t listen to the skeptics and naysayers. If you are not using LLM coding agents you are missing out. Ofc they won’t work on everything and you need to be careful, but work is a lot more fun with coding agents.
3
3
45
4,553
Dileep George retweeted

AI has transformed how we design therapeutics.
But targeted delivery is still an expensive guessing game.
Today @BobbyHollings and I are launching @deliverome with @beckypferdehirt and @radialscience at @AsteraInstitute, to fix that. 🧵

10
39
219
30,091
Dileep George retweeted

May 26
New Blog: What's the point of theory in biology, especially in the age of machine learning?
I just published a series of letters by @NoahOlsman that start to get at this question, especially in the context of virtual cells: nikomc.com/essays/theory

1
32
192
13,915
May 26
God works in mysterious ways.
LLMs work in mysterious ways.
Therefore LLMs are Gods 😇
13
4
56
6,412
Dileep George retweeted

May 20
There was 0 human involvement. The prompt is in the report. The final answer by the model is in the report. And we have a (gpt-rewritten) CoT that we released.
19
25
673
194,842
May 18
Here's a better lesson, don't fall for bitter lesson.
May 18

The bitter lesson in 26 words:
Don’t be distracted by human knowledge, as AI has been historically.
Instead focus on methods for creating knowledge that scale with computation, like search and learning.
12
18
239
34,987


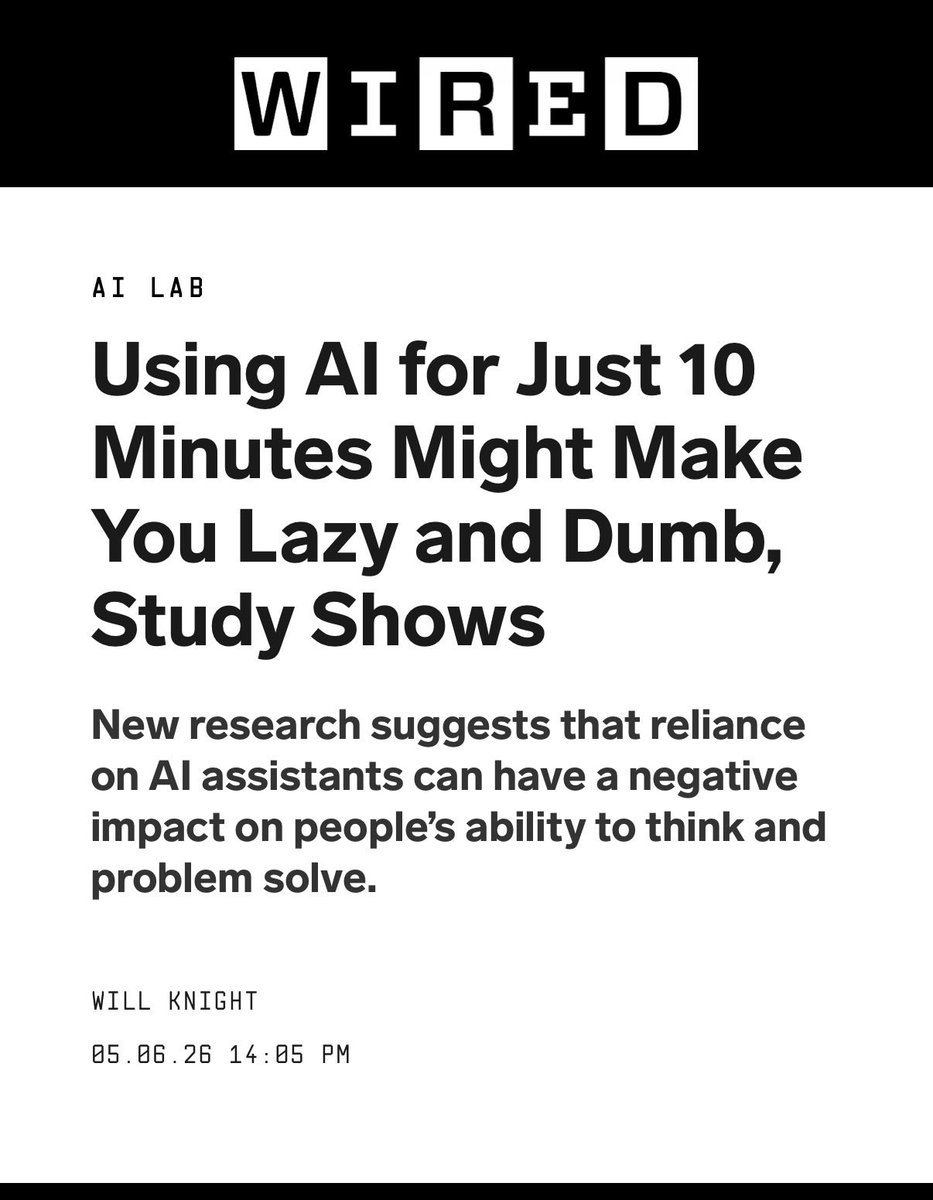
May 8
so use it for more than 10 mins. 😇

2
1
22
3,481
May 8
Nope. This is wrong at many different levels. 1) Scaling is driven by real usage demand 2) Manhattan project and Apollo mission are wrong comparisons because they were research budgets, not serving users budget. 3) Internet based distribution is instantaneous. A single person cannot ride multiple rail cars at the same time. So their growth rates cannot be compared 4) no it doesn’t need to get to AGI for it to remain extremely useful.
May 6
Am I right that hyperscaling compute is the biggest bet in history?
Any counter examples?
It’s way more expensive than the Manhattan Project, the Apollo project, and railways across the US.
If it doesn’t yield AGI, it may also be the biggest failed bet in history.
1
2
37
6,605
May 7
This book -- Apprentices of Wonder -- is from 1989, reporting on the previous neural net era. It took 35 years after that, but anyone using coding agents should absolutely get the feeling of having apprentices of wonder!
2
12
95
3,217
Dileep George retweeted

Apr 15
The Silk Road made everyone rich, and then it killed half of them.
Progress ep02 is live with @typesfast of @Flexport.
We discuss why the global economy is as fragile as ever, what it takes for America to build again, and whether AI needs its own god.
5
19
87
89,241
Apr 15
fascinating!
Apr 15

When supply chains shut down in 2021, @typesfast rented a boat, hit the water, and tweeted what he saw in the Port of LA. The mayor changed the law that same day.
On Progress, we get into tariffs, Black Death, AI religion, and how to make manufacturing high status again.
1
2
1,251
Dileep George retweeted

Apr 9
This is the strongest ephys evidence so far for a generative model in the brain that I know of.
Congratulations @WadiaVarun! Wonderful collaboration with @UeliRutishauser on science that could only be done in humans.
And please check out Fig. 5FG. This is new since biorxiv and really surprised me: the mean response to imagery and viewing is actually the same & there are many cells that respond only during imagery--challenging the idea that signal strength is what distinguishes reality from imagination.
Apr 9

1/8 Our preprint is now a peer-reviewed paper :) Big thanks to our reviewers who pushed us to examine our results more carefully and Olivier Wyart (headquarter.paris/) for the exquisite visual. science.org/doi/10.1126/scie…

6
46
220
41,436
Dileep George retweeted
Apr 7
I will be giving the Martin Meyerson Faculty Research Lecture tomorrow 4/8 at 4 pm at UC Berkeley. This is a public lecture open to all. Revised title is: "Representing the visual world: from faces to consciousness"
facultylectures.berkeley.edu…
1
6
42
8,022
Dileep George retweeted

Just a reminder of @AsteraInstitute's open essay competition about identifying and overcoming scientific bottlenecks. Deadline for entries is May 1!

2
49
155
21,474
Dileep George retweeted
Feb 14
Not being able to get LLMs to hallucinate is a skill issue 😇
8
10
51
6,912
Dileep George retweeted

Apr 3
When the vibes shift, I change my opinions. What do you do sir?
7
30
431
36,079