
Joined August 2011
- Tweets 571
- Following 1,614
- Followers 12,019
- Likes 18,691
76 Photos and videos






Pinned Tweet

22 Jul 2022
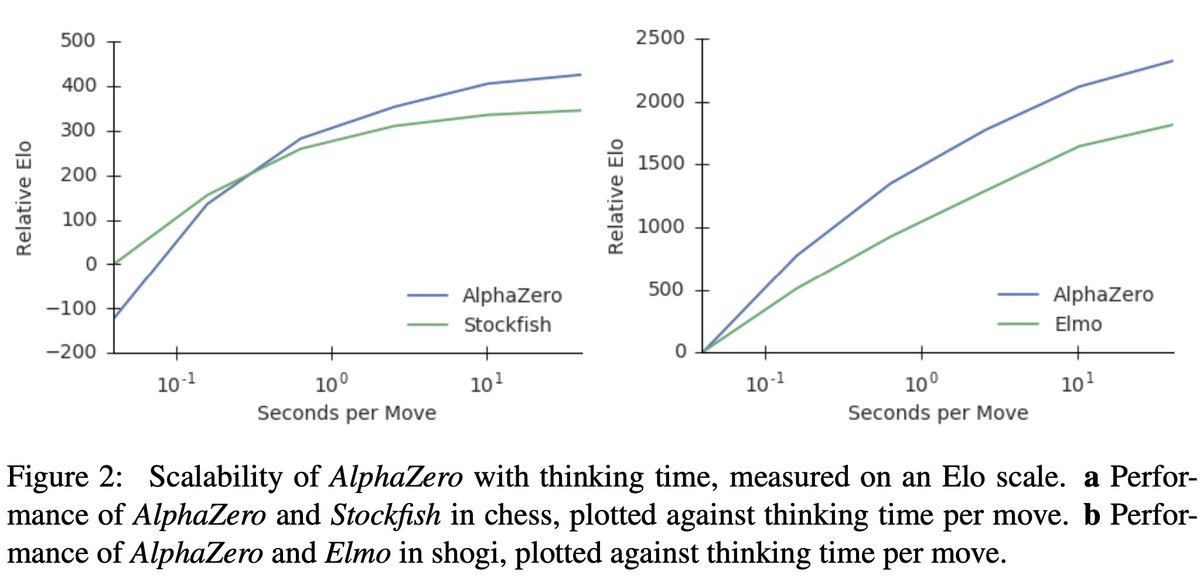
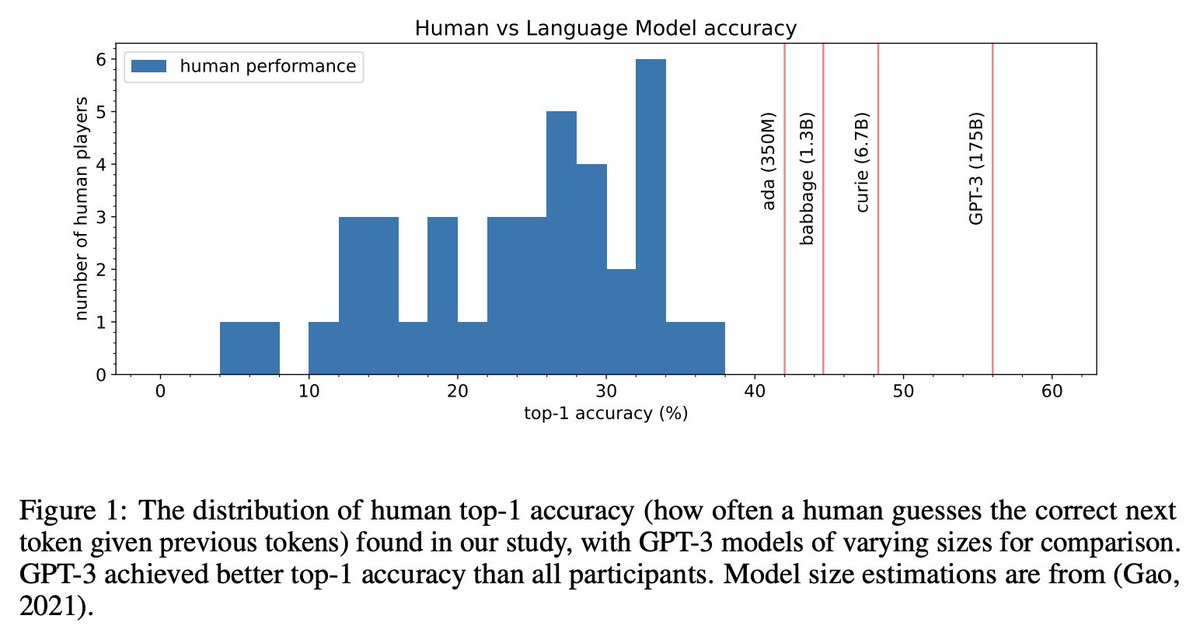
Happy to release our work on Language Model Cascades. Read on to learn how we can unify existing methods for interacting models (scratchpad/chain of thought, verifiers, tool-use, …) in the language of probabilistic programming.
paper: arxiv.org/abs/2207.10342
6
98
677

We achieved gold medal-level performance 🥇on the 2025 International Mathematical Olympiad with a general-purpose reasoning LLM!
Our model solved world-class math problems—at the level of top human contestants. A major milestone for AI and mathematics.
19 Jul 2025

1/N I’m excited to share that our latest @OpenAI experimental reasoning LLM has achieved a longstanding grand challenge in AI: gold medal-level performance on the world’s most prestigious math competition—the International Math Olympiad (IMO).

214
430
4,008
673,385
David Dohan retweeted

19 Jul 2025
I feel this may be helpful to some of you today:

13
62
713
89,090
19 Jul 2025
OpenAI achieved gold medal on 2025 International Math Olympiad (solving 5 of 6 problems)!
Thinks for hours and writes proofs in natural language.
We've come a long way from LLMs solving 50% of MATH dataset in 2022
Congrats @alexwei_ on spearheading a major milestone!
19 Jul 2025
1/N I’m excited to share that our latest @OpenAI experimental reasoning LLM has achieved a longstanding grand challenge in AI: gold medal-level performance on the world’s most prestigious math competition—the International Math Olympiad (IMO).
1
126
7,479
1 Jun 2025
How to code a side project in 2025:
1. May 31 - Write project spec
2. Procrastinate 6 months
3. Dec 31 - ask favorite AI to implement it
2
3
64
4,424
David Dohan retweeted

27 Feb 2025
Scaling pretraining and scaling thinking are two different dimensions of improvement. They are complementary, not in competition.
49
81
1,032
129,422
David Dohan retweeted
21 Jan 2025
This is on the scale of the Apollo Program and Manhattan Project when measured as a fraction of GDP. This kind of investment only happens when the science is carefully vetted and people believe it will succeed and be completely transformative. I agree it’s the right time.

Announcing The Stargate Project
The Stargate Project is a new company which intends to invest $500 billion over the next four years building new AI infrastructure for OpenAI in the United States. We will begin deploying $100 billion immediately. This infrastructure will secure American leadership in AI, create hundreds of thousands of American jobs, and generate massive economic benefit for the entire world. This project will not only support the re-industrialization of the United States but also provide a strategic capability to protect the national security of America and its allies.
The initial equity funders in Stargate are SoftBank, OpenAI, Oracle, and MGX. SoftBank and OpenAI are the lead partners for Stargate, with SoftBank having financial responsibility and OpenAI having operational responsibility. Masayoshi Son will be the chairman.
Arm, Microsoft, NVIDIA, Oracle, and OpenAI are the key initial technology partners. The buildout is currently underway, starting in Texas, and we are evaluating potential sites across the country for more campuses as we finalize definitive agreements.
As part of Stargate, Oracle, NVIDIA, and OpenAI will closely collaborate to build and operate this computing system. This builds on a deep collaboration between OpenAI and NVIDIA going back to 2016 and a newer partnership between OpenAI and Oracle.
This also builds on the existing OpenAI partnership with Microsoft. OpenAI will continue to increase its consumption of Azure as OpenAI continues its work with Microsoft with this additional compute to train leading models and deliver great products and services.
All of us look forward to continuing to build and develop AI—and in particular AGI—for the benefit of all of humanity. We believe that this new step is critical on the path, and will enable creative people to figure out how to use AI to elevate humanity.
246
669
7,382
917,888

David Dohan retweeted

21 Dec 2024
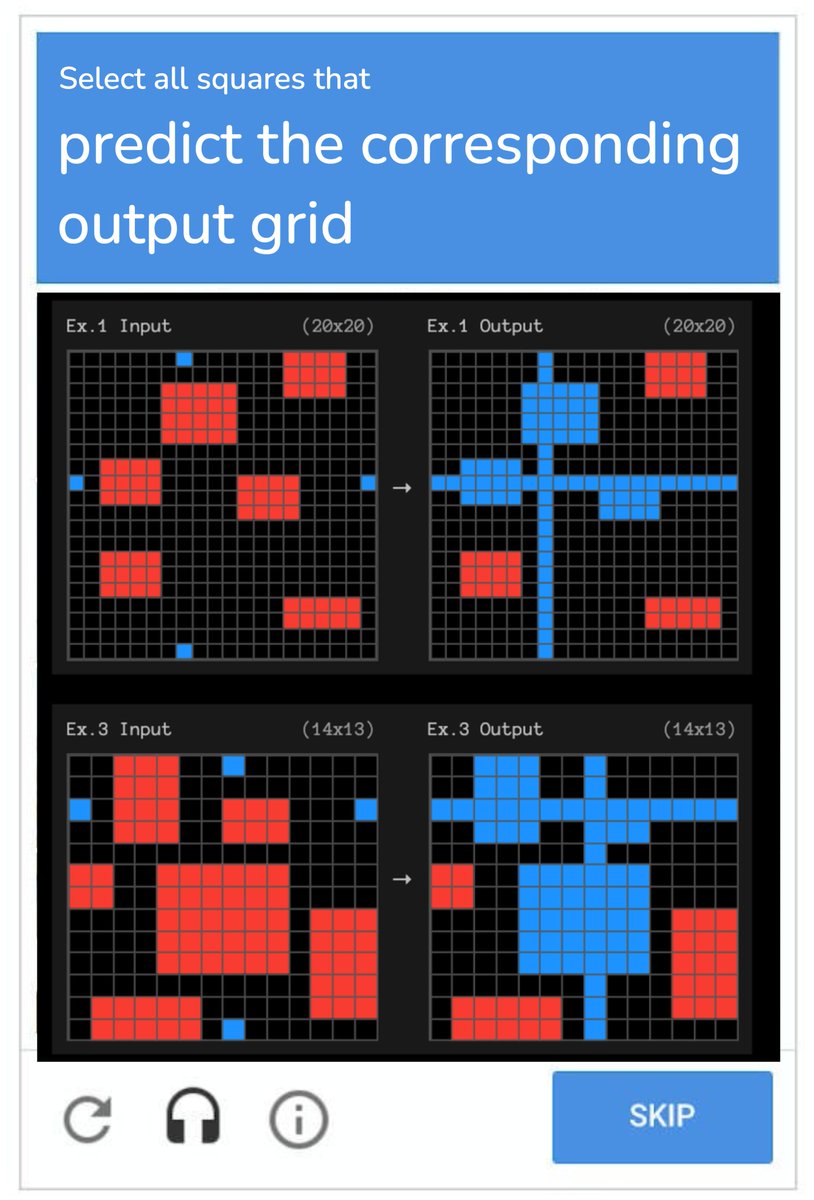
these new captchas are getting way too difficult
28
95
2,034
77,358
David Dohan retweeted

21 Dec 2024
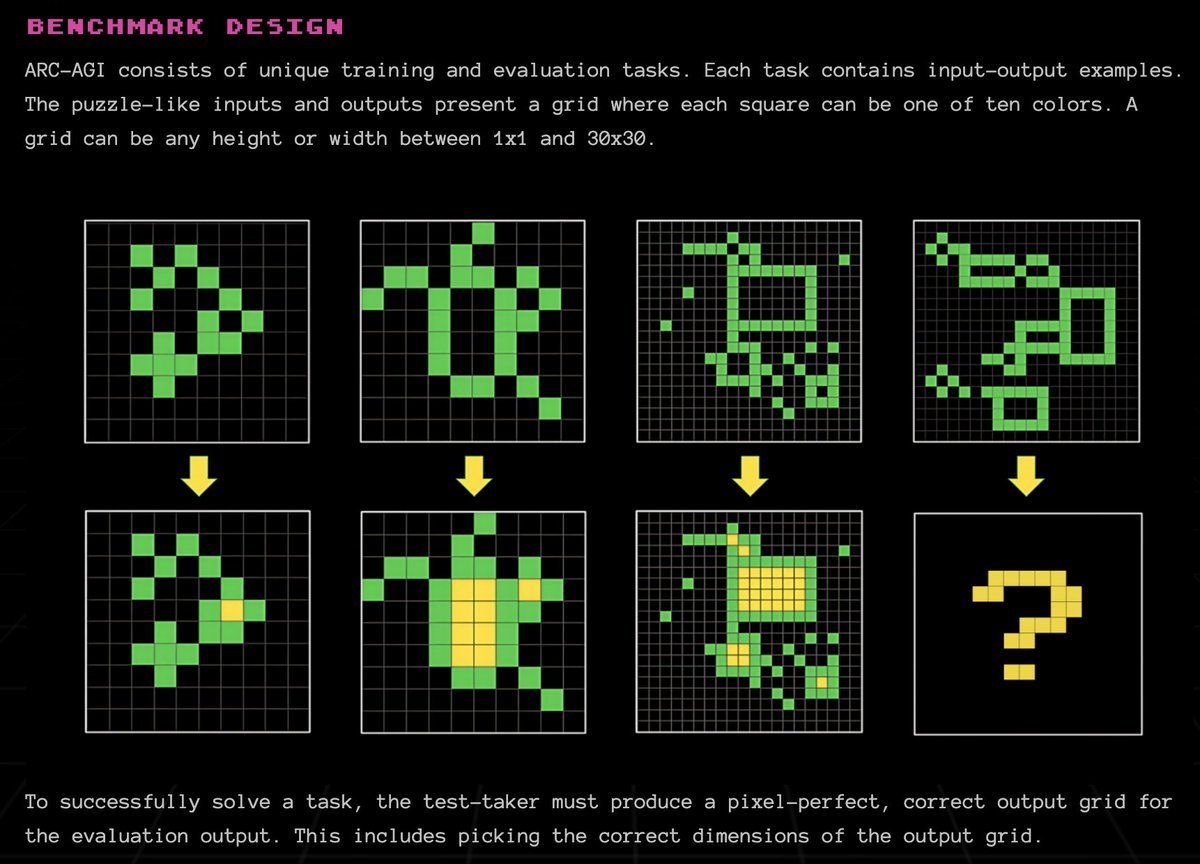
I have yet to find a well-defined task that cannot be optimized by these models. Eval improvement like ARC AGI showcase this dynamic
20 Dec 2024

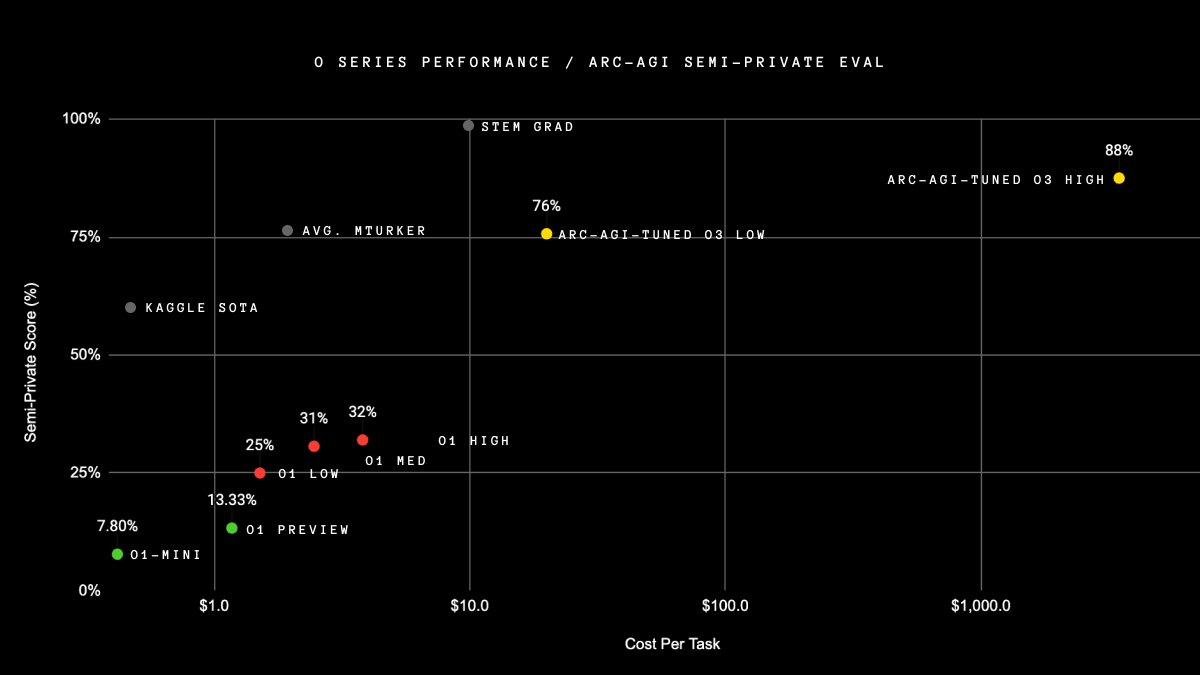
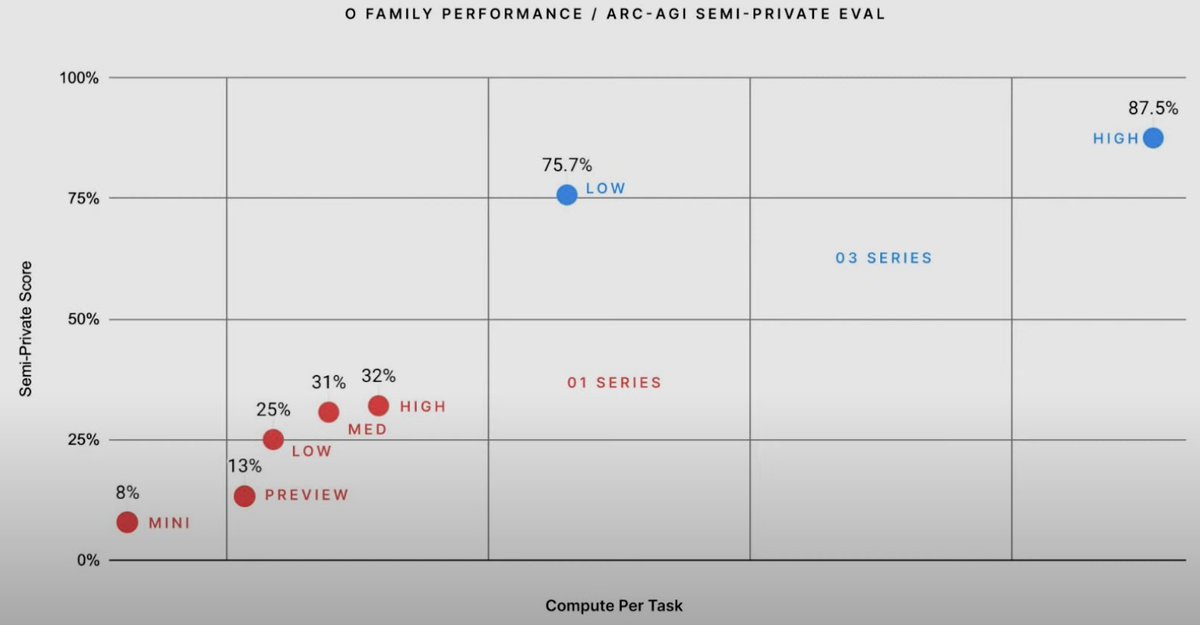
So we went from 0 to 87% in 5 years in ARC AGI score. There is no wall it seems.
GPT-2 (2019): 0%
GPT-3 (2020): 0%
GPT-4 (2023): 2%
GPT-4o (2024): 5%
o1-preview (2024): 21%
o1 high (2024): 32%
o1 Pro (2024): ~50%
o3 tuned low (2024): 76%
o3 tuned high (2024): 87%
6
8
113
32,238
20 Dec 2024
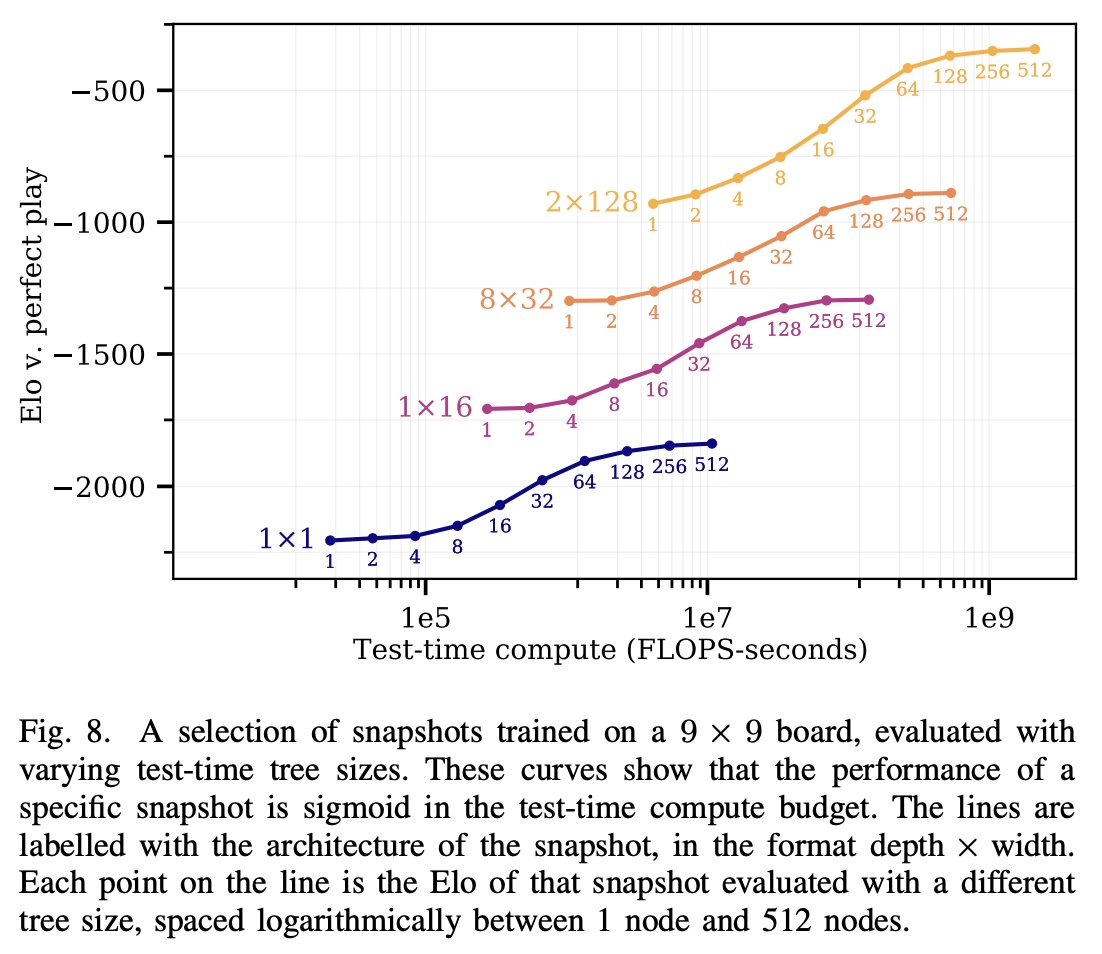
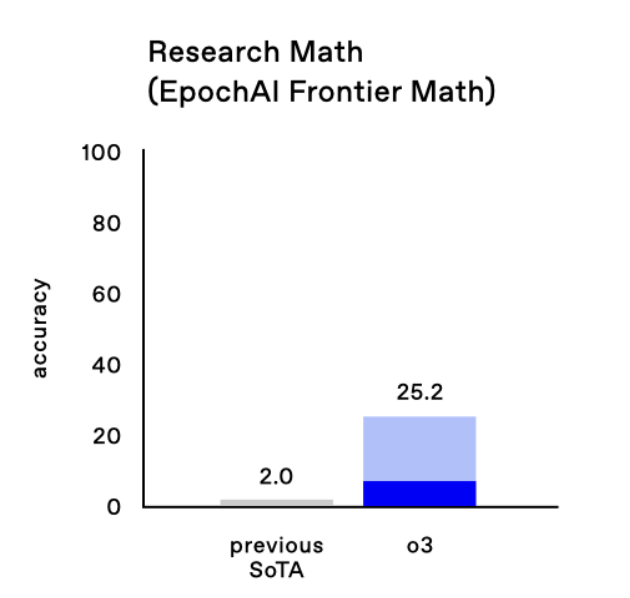
still a ways to go on FrontierMath!
20 Dec 2024

Lots of folks are posting quotes from Gowers/Tao about the hardest split of FrontierMath, but our 25% score is on the full set (which is also extremely hard, with old sota 2%, but not as hard as those quotes imply).
1
14
3,468
20 Dec 2024
imo the improvements on FrontierMath are even more impressive than ARG-AGI. Jump from 2% to 25%
Terence Tao said the dataset should "resist AIs for several years at least" and "These are extremely challenging. I think that in the near term basically the only way to solve them, short of having a real domain expert in the area, is by a combination of a semi-expert like a graduate student in a related field, maybe paired with some combination of a modern AI and lots of other algebra packages…”
20 Dec 2024
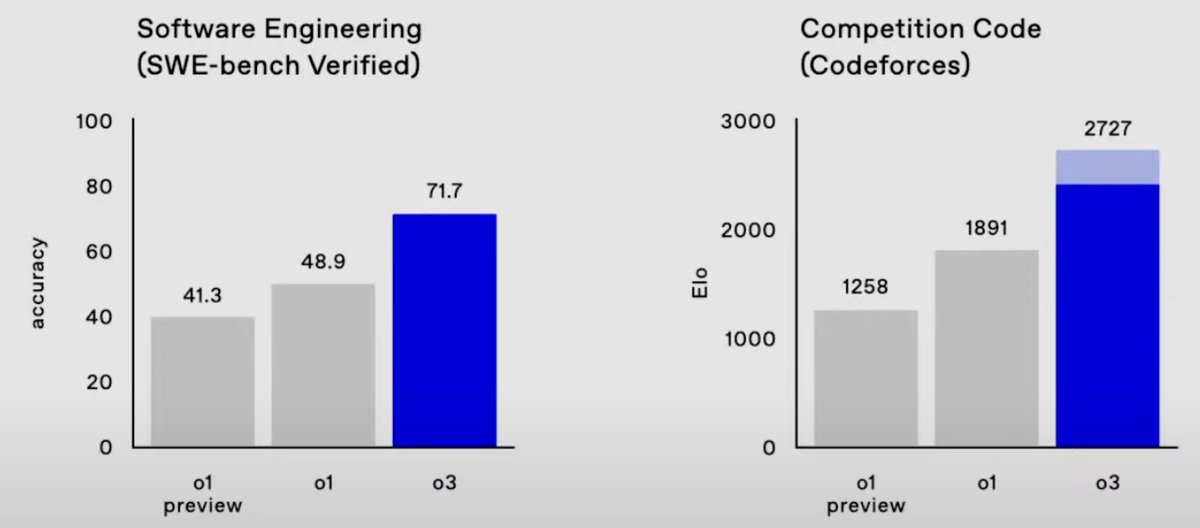
Well, on FrontierMath 2024-11-26 o3 improves the state of the art from 2% to 25% accuracy. These are absurdly hard strongly held out math questions. And on ARC, the semi-private test set and public validation set scores are 87.5% (private) and 91.5% (public). (7/n)
20
72
878
153,418
20 Dec 2024
Caveat on the Tao quote: that refers to the hardest "research" split of the dataset, while the 25% is across the entire dataset.
x.com/Jsevillamol/status/187…
20 Dec 2024

To clear a possible misunderstanding: the quotes refer to questions in the highest tier of difficulty of FrontierMath. Not every question in the benchmark is as difficult as the ones Tao and Gowers reviewed.
2
2
46
7,257
20 Dec 2024
An encouraging aspect of the o3 series is that the model can explicitly think about safety and what's OK, leading to more robustness all around
20 Dec 2024

Chain-of-thought reasoning provides a natural avenue for improving model safety.
Today we are publishing a paper on how we train the "o" series of models to think carefully through unsafe prompts: openai.com/index/deliberativ……
4
45
21,906
20 Dec 2024
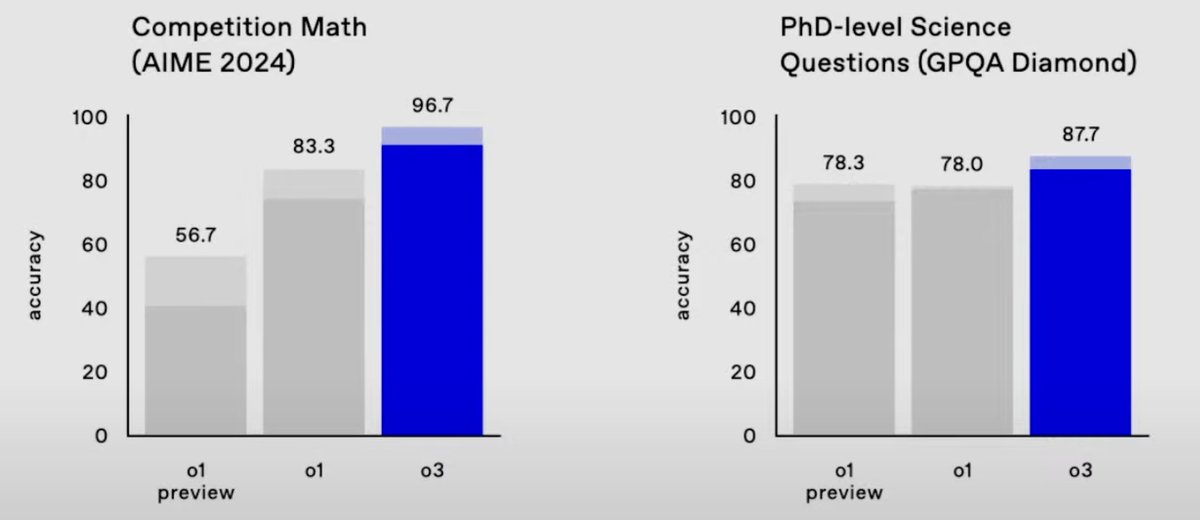
We are used to the cadence of big model releases: GPT2->3->4 took two years each time
We’re in a different world now
o1 was announced months ago, now already on next generation
Expect faster improvement going forward: o1 is like gpt2 if we could jump to gpt4 ~immediately

12
22
190
48,467
20 Dec 2024
Which is why robust safety testing is all the more important
Sign up to help redteam o3(-mini)!
openai.com/index/early-acces…
2
17
3,015
David Dohan retweeted
20 Dec 2024
You can sign up to help red team o3 and o3-mini here: openai.com/index/early-acces…
17
19
264
66,530
David Dohan retweeted

20 Dec 2024
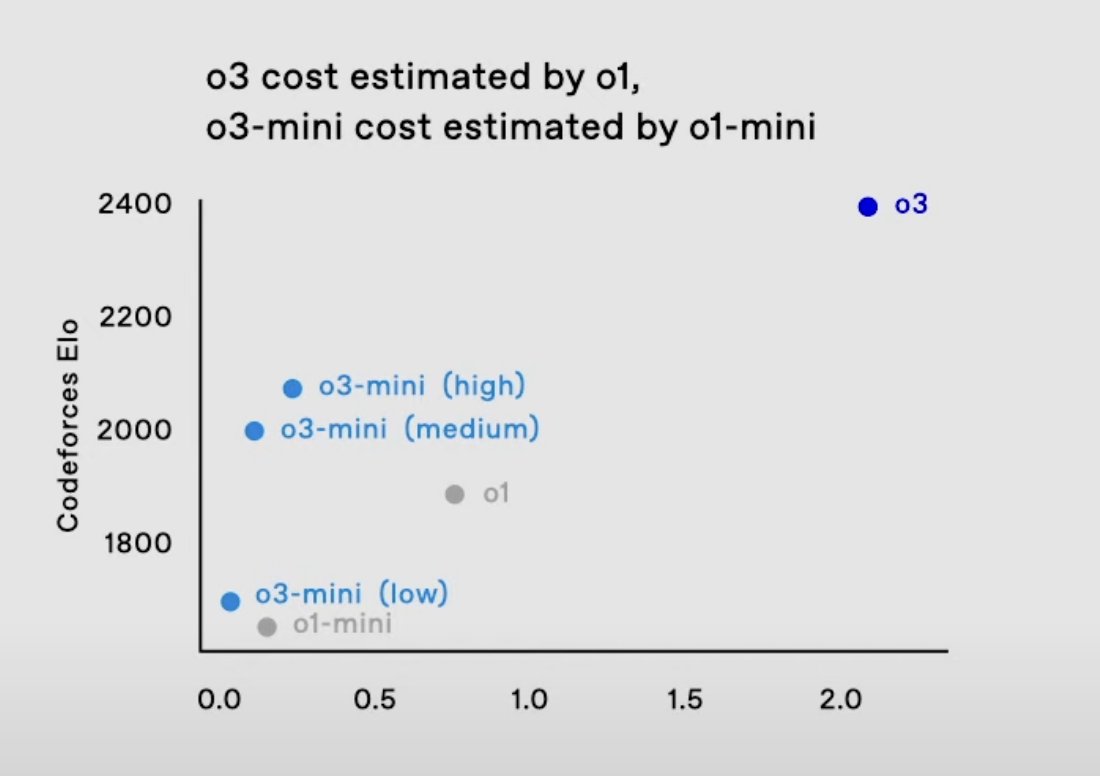
Excited to train o3-mini with @ren_hongyu @_kevinlu and others, a blindingly fast model with amazing reasoning / code / math performance.
openai.com/12-days/?day=12
11
41
424
174,324