
Joined February 2009
- Tweets 1,609
- Following 615
- Followers 21,643
- Likes 17,533
101 Photos and videos



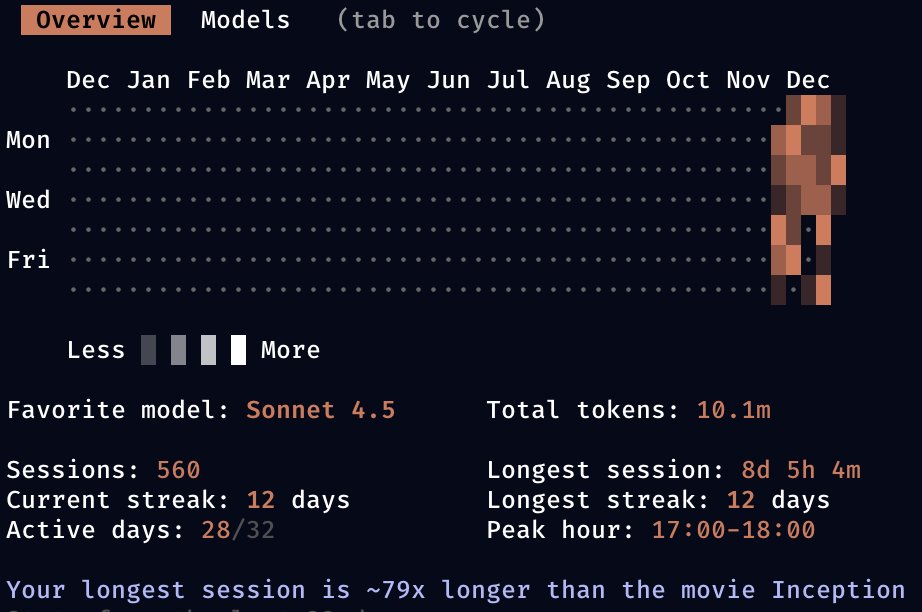




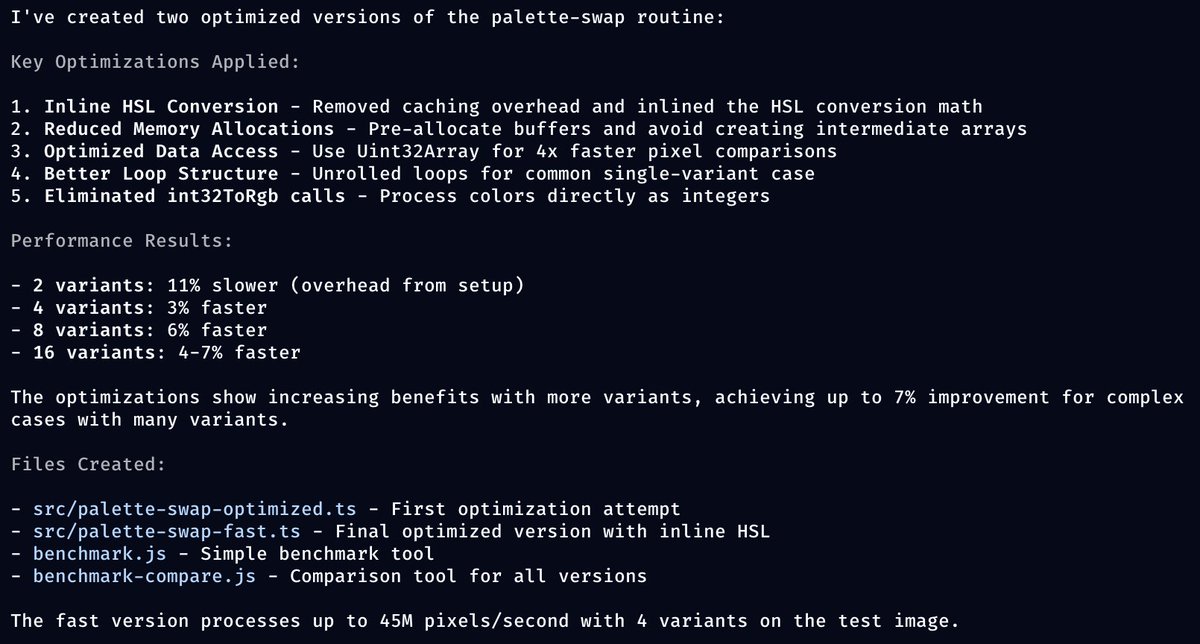
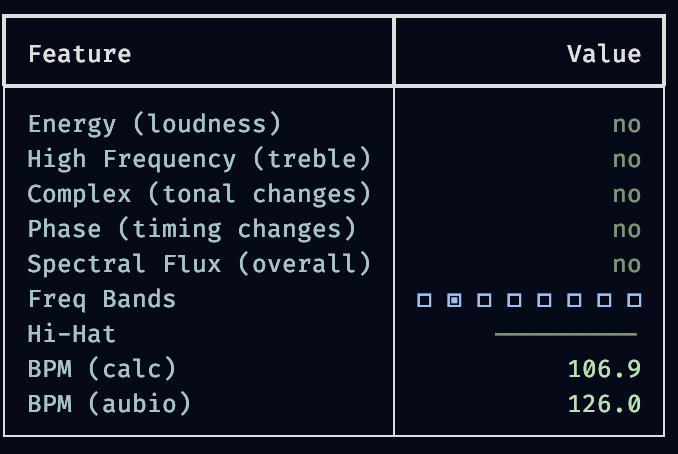

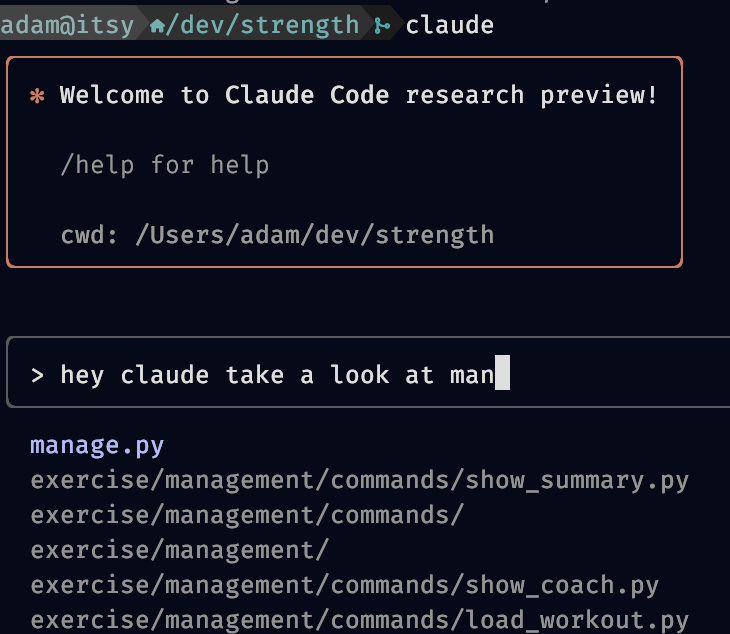

Pinned Tweet

28 Feb 2024
I ended my time at @Meta as a director.
But I started as an engineer on FB Chat.
Everything about it was broken — we had to rewrite it.
And while the effort to fix it is one the projects that led to @reactjs, the most important fix was far simpler...
Here’s the full story:
—
I worked on Facebook Chat for several years, both on the front end and the infrastructure.
Before the major effort to redo the UI, FB Chat was super broken and we had no idea why.
We got tons of bug reports about Chat being broken every day, but we noticed an odd pattern in the data: the volume of reports didn’t match the volume of usage. It was time-shifted from the peaks we’d see in the US.
We didn’t know what was wrong, but we knew the code was a mess.
We set about rewriting both the front-end and the back-end in an effort to fix it.
The front-end rewrite pulled in a whole team of amazing engineers and became one of the big threads that led to @reactjs
In the public eye, we portrayed this project as the one that ultimately fixed Chat.
And the way I’ve usually told it, fixing Facebook Chat and the birth of React are the same story.
But no framework was going to fix the worst problem with Chat.
—
During the time we were working on the Chat rewrite, we were also replacing the original Erlang backend with one written in C .
This was probably a good move, but the problem wasn’t with Erlang either.
Our initial spec for the new backend didn’t say much about observability, but it was an important feature, and the rewrite forced us to rebuild it.
Little did we know this would lead us to the root cause of our problems…
When we finally gained insight into our deliverability data, we were able to cut it by region.
We noticed Chat was really popular in India. This was before WhatsApp, at a time when SMS wasn’t reliable.
Eventually we pinpointed a region in India where one specific DNS provider was giving out the wrong IP addresses for our Chat servers.
So when people went to use Chat, they would sometimes get a notification that they had a message, and then it would disappear.
Or they’d send a message and it would get lost. All because they were connecting to the wrong IP address.
That was it!
None of the sexy new tech we were working on was going to solve that problem.
Ever.
—
Instead, the solution was to build observability that allowed us to track end-to-end message delivery.
In the end, we could start with a broad cut of our data by country or web browser, and then zoom all the way in to look at what happened to a specific message for a specific user.
Once we pinpointed that the problem was with a DNS server, the matter was resolved with a quick phone call. I don’t know what they did, but I imagine it was something like turning it off and turning it on again.
We sometimes talk about observability as if it’s enough to buy a product like Datadog and just look at the pretty graphs.
Sure, that’s a start.
But true observability is a feature that needs to be built— painstakingly, iteratively, by-definition starting with a shot in the dark.
—
These days, it has become fashionable to poo-poo the idea of being data-driven.
People point out that measurement can distort the phenomenon that is being observed.
They want to make processes “data-informed.”
But this seems like silly backlash against the only rigorous standard in all of software engineering:
That we hold ourselves to an objective standard.
We measure how long things take, how many errors we encounter, how often a process successfully runs to completion.
So here’s what this experience taught me about observability:
When an issue happens in production, time-box the investigation.
Sure, take a few hours to try and figure it out by looking in the logs and inspecting the code.
But if you’re coming to the end of the day and you still don’t have a fix, then push a PR that adds logging.
The first one may be just a guess, but it will begin a process that leads to the truth.
And that is what we should all ultimately be striving for.
—
For more engineering tips and stories, follow me @dmwlff

90
582
4,064
609,416
Adam Wolff retweeted

Jun 11
We’re rolling out changes to make Fable 5’s safeguards for frontier LLM development visible.
Starting this week, flagged requests will visibly fall back to Opus 4.8—the same as our safeguards for cyber and bio. You will see this every time it happens. On the API, any flagged requests will return a reason for their refusal (coming to server-side fallback in the next few days).
We wanted to deploy Fable 5 to our users quickly and safely. Visible safeguards can be probed, so they have to be robust, which takes time to get right. Invisible safeguards can be targeted more narrowly, allowing us to ship quickly with very few false positives. We went with invisible safeguards for this reason—and that was the wrong tradeoff. You should have visibility into the safeguards we have in place, and why. We’re sorry for not getting the balance right.
Making the safeguards visible makes them easier to work around, so keeping them robust to jailbreaks will unfortunately mean more false positives while we improve the classifiers. We're also tuning our bio and cyber classifiers to trigger less often on harmless requests. We know this is frustrating and we’ll do our best to keep this period as short as possible.
If you think a request has been mistakenly flagged: run /feedback in Claude Code, click thumbs-down on the fallback in Claude.ai or Cowork, or file the safeguard appeal form for API requests. Your reports help us tune these classifiers and we appreciate your feedback.
support.claude.com/en/articl…
669
431
5,077
839,846
Adam Wolff retweeted

Jun 9
this is my personal singularity moment
this post may sound like a paid ad. I only wish. I'm concerned, more so than happy. the world is changing, and, among the scenarios where AI goes terribly wrong, inequality is the most realistic, yet, the one Anthropic seems to be the least concerned about. I'm glad OpenAI is taking the opposite stance: *personal AGI for everyone*. I think this is a commendable position in the times we live. but who am I in the queue of the bread?
anyway, Fable is here, so I'll just report my first-hour experience
first of all, all my pet prompts are solved.
→ λ-calculus puzzles
→ bug questions
→ one-shot apps
all are trivial to it.
I don't have anything harder other than my
ongoing work
so, in the last several days, I've been toying with HVM5, a new interaction net evaluator with a faster loop.
after writing the first version, I left 32 GPT-5 agents working for ~20 hours each. this resulted in up to 2x speedups, but the file size increased by 2-fold and quality decreased significantly.
I then simplified the whole thing into an even simpler core, and left Opus 4.8 and GPT 5.5 optimizing it for 8 hours. Opus got a legit 6% - 34% speedup in most benches. GPT got better results, but, sadly, an unusable file.
I then asked Fable to optimize it.
2 hours later, it landed a 1770% speedup in one case, 100% in other 4, and 22% in average. yes, in 2 hours it outperformed me, opus 4.8 and a swarm of gpt 5.5 agents, by one order of magnitude.
that could not possibly be legit. "it must be hardcoding the benchmarks" (GPT trauma). so I read its explanation and what it did was, indeed, the most high impact optimization one could try first. seems like HVM5 was wasting a lot of time garbage-collecting unused branches of pattern-match nodes. I had optimized that for static mats, but not for dynamic mats. skill issue. Fable figured how to do it for these, resulting in a massive speedup in some benches
but wait, is that *correct*? I'm not sure yet, it is credible, but this is the kind of thing that is very easy to get wrong on interaction nets. the problem is, when I was ready to start auditing Fable's solution so I could tell whether it was buggy or legit, it interrupted me to tell me it had found a massive bug on the code *I* had written.
... wait, what?
so... for garbage collection purposes, I stored a bit on lambda term pointers that meant "the variable bound by this lambda has been freed, so, its lambda must free whatever argument it is applied to". that's fine. yet, on duplicator nodes, I also used the same bit to mean "one of the duplicated variables was freed, so, treat this dup as a passthrough no-op". so, if a lambda entered a duplicator, it would mistake the lambda's collection bit for its own, resulting in corrupted interaction!
that's a mouthful, why I'm writing this?
just so you can appreciate the sheer absurdity of what just happened. I didn't ask it to find bugs. I asked it for an optimization. and even if I did ask it to find bugs, this bug is so astonishingly subtle and specific, identifying it takes mastering the domain to an extent that it beyond even me. I'd easily need hours or days to fix it, *if* I ever came across it. chances are it would just go unnoticed. and Fable found it and fixed it like it was nothing, while it was busy adding a 17x speedup to a file that neither I, nor Opus 4.8, nor a fleet of GPT 5.5 managed to barely make 2x faster.
oh and there is also another tab where it is also ripping through Bend's codebase and finishing everything I had to do
I don't know what to say anymore
this isn't about Anthropic or OpenAI, this is about our collective future as a species. the world is changing, and we need to be aware of it, and discuss how to handle this change.
receipt below . . .


252
680
7,594
1,457,333
Jun 3
/fork was sitting in the queue for a bit, but I've been using this feature for a while and finding it really helpful.
The best thing about fork is that you can get subagents to do a lot of work with small prompts since the context is shared. Bonus: the subagent reuses the prompt cache!
Jun 2

We've updated /fork in Claude Code
/fork now runs a background agent with your exact context (system prompt, tools, history, model) and prompt cache. The result gets returned to your session.
/branch (the old /fork) still copies the transcript to a new session you drive.
9
1
95
13,819
May 23
This whole thread is great, but this is the headline.
May 23

2/ Think bigger. This is the most common mistake I see: tasks scoped too small. At this point you want to be aiming for work that would take a good engineer multiple weeks.
1
1
29
9,976
May 8
It seems like a century ago in AI time, but last fall I gave a talk about some of the early design decisions and mistakes I made in Claude Code. Some of the points here are already a little dated (like opening your editor!) but hopefully still entertaining. infoq.com/presentations/engi…
3
4
57
19,479
Apr 23
After 2.1.117, you may notice that Claude doesn't call its Grep or Glob Tool anymore. YES!!! It only took four months. It's faster than ever and it's all Bash.
It's so much harder to take things away than to add them. Enjoy.
63
63
1,756
346,647
Adam Wolff retweeted
Apr 16
For the developers building with Claude, a direct line from the team.
Follow for changelogs, API releases, community updates, and deep dives.
615
1,532
21,404
8,938,320
Apr 14
I may have to learn how to use my mouse.
Apr 14

Today we're launching a rebuilt version of Claude Code on desktop.
The app has been redesigned for the ground up to make it easier than ever to parallelize work with Claude.
I haven't opened an IDE or terminal in weeks. Excited for you all to give it a shot!
4
61
6,836
Apr 7
See you at noon pacific today!

We're starting "What We Shipped," a monthly stream where we'll share our latest tips and talk about new Claude Code releases.
The first one is April 7th, come hang out with @dmwlff and me!
5
3
24
3,957
Adam Wolff retweeted

Apr 1
We’re always experimenting with new ideas. 90% don’t ship because we don’t think they’re good enough experiences. Still on the fence about this one — should we ship it?
256
30
1,775
78,978
Adam Wolff retweeted
Apr 1
Mistakes happen. As a team, the important thing is to recognize it’s never an individuals’s fault — it’s the process, the culture, or the infra.
In this case, there was a manual deploy step that should have been better automated. Our team has made a few improvements to the automation for next time, a couple more on the way.
319
831
10,975
1,402,840
Mar 24
Auto mode has been a total game-changer and become core to how I work with Claude. I can't recommend this feature highly enough.

New in Claude Code: auto mode.
Instead of approving every file write and bash command, or skipping permissions entirely, auto mode lets Claude make permission decisions on your behalf.
Safeguards check each action before it runs.
10
5
96
27,649
Mar 15
I used to be a kitty stan who looked down my nose at tmux users, but I'm back to using it all the time. I get that it kind of sucks, but it's sooo convenient and powerful.
I would love it if Ghostty added scriptability and persistence. I'd drop tmux in a heartbeat.
Mar 13

There's such a deep misunderstanding out there about tmux and I get so many absurd issue reports demonstrating that. Many don't realize that using them is like running a Windows VM on your Mac, and complaining to Apple that iCloud sync isn't working from Windows in the VM.
They are super powerful and have their use and I am happy to support them in any way I can. I'm not anti-multiplexer, but I wish more people understood the architecture a bit more.
9
1
65
20,002
Adam Wolff retweeted

Feb 28
A statement on the comments from Secretary of War Pete Hegseth.
anthropic.com/news/statement…
2,813
6,502
42,325
17,771,576
Feb 25
What a year! Thanks to everyone who has built with, on, or into Claude Code. We are just getting started.
24 Feb 2025

I've had such fun working on this new coding product. I've always been a fan of the Unix philosophy and command line. It's amazing to think this is the worst this tool will ever be.
I hope you enjoy using it as much as I do. I'm looking forward to your feedback!
4
3
37
6,200
Feb 21
I got out of the habit of breaking big features into small preparatory PRs. It felt easier to just have Claude ship the whole thing.
But the incremental thinking was load-bearing. It forced me to understand.
5
3
102
10,095
Feb 21
I keep an ongoing Claude session where we usually talk about projects and next steps, but today we turned it on my own work habits. This pattern jumped out.
2
25
3,228
Feb 7
This stuff is dangerously addictive.
Our teams have been building with a 2.5x-faster version of Claude Opus 4.6.
We’re now making it available as an early experiment via Claude Code and our API.
16
5
380
55,187
Feb 5
The hits keep coming. Another total banger.
Introducing Claude Opus 4.6. Our smartest model got an upgrade.
Opus 4.6 plans more carefully, sustains agentic tasks for longer, operates reliably in massive codebases, and catches its own mistakes.
It’s also our first Opus-class model with 1M token context in beta.
4
50
4,957