
123 Photos and videos






Pinned Tweet

Apr 13
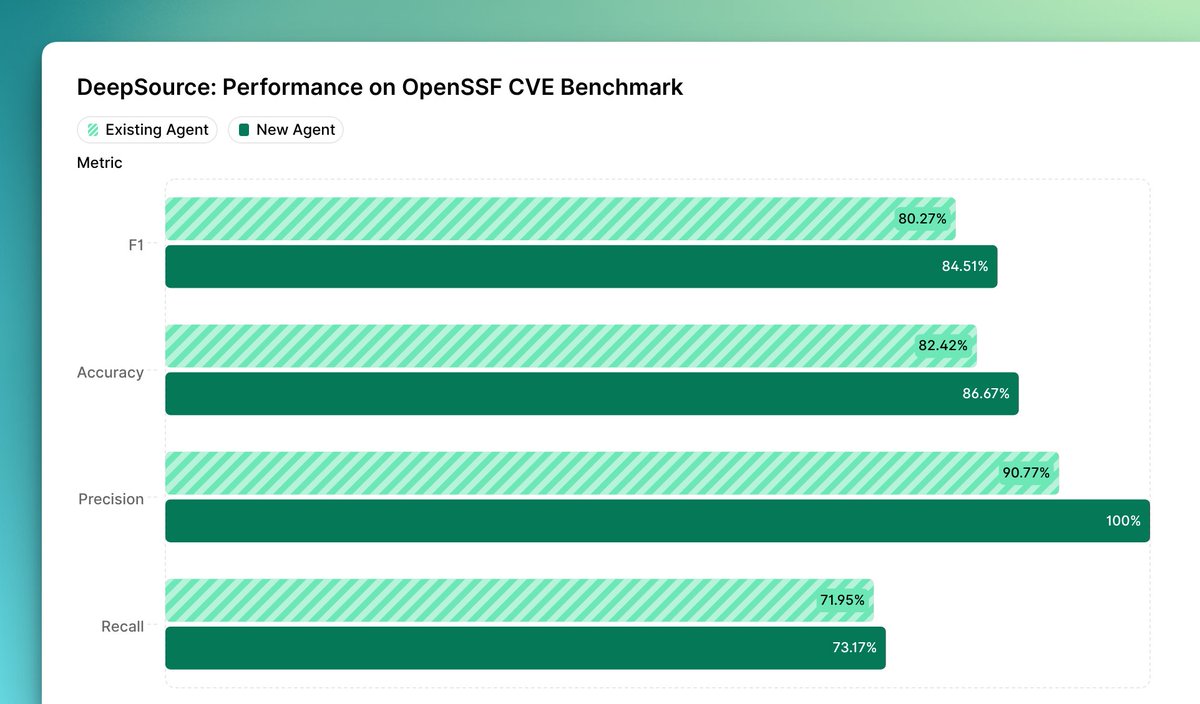
DeepSource hit 82.42% F1 on OpenSSF CVE Benchmark, in our latest run. 100% precision, 71.95% recall.
That's zero false positives across 83 real CVEs. Every alert is real.
Hybrid analysis. Static gives you the deterministic baseline, AI fills the gaps on context-dependent vulnerabilities.
Apr 13

DeepSource AI Review now scores higher on the OpenSSF CVE Benchmark. Most importantly, we're seeing 4% gain on the F1 score.
This means we're catching more real vulnerabilities without introducing a single false positive.
Our precision hit 100% (zero false positives across 83 patched diffs) while recall climbed to 73.17%.
1
3
273
May 21
320 npm packages compromised today: timeago.js, echarts-for-react, and hundreds of packages in the @antv ecosystem.
Supply chain attacks aren't slowing down, and the triage bottleneck is getting worse.
In monorepos, one vulnerable dependency can show up across dozens of sub-projects. Same CVE, different teams, unclear ownership.
DeepSource now scopes OSS vulnerabilities per sub-repo in monorepo mode. Each sub-project gets its own Dependencies tab, with results scoped to the packages used by that sub-project.
deepsource.com/changelog/202…
93
May 14
don't think this has been rolled out yet
May 13

Claude Code weekly limits are increasing 50%, now through July 13.
Live now for all Pro, Max, Team, and seat-based Enterprise users.

95

Everyone should save their session history, did u know all your Claude code sessions get deleted every month unless you change that in settings.json?
All that is valuable training data they’re keeping! So you should too.
I have a few repos on GH to help you do this. Share it

thank you @0xSero for making github.com/0xSero/ai-data-ex…
now i can tinker with @UnslothAI studio ^^

9
18
234
18,001
Jai Pradeesh retweeted

Apr 13
DeepSource AI Review now scores higher on the OpenSSF CVE Benchmark. Most importantly, we're seeing 4% gain on the F1 score.
This means we're catching more real vulnerabilities without introducing a single false positive.
Our precision hit 100% (zero false positives across 83 patched diffs) while recall climbed to 73.17%.
1
2
3
3,165
Jai Pradeesh retweeted
Apr 7
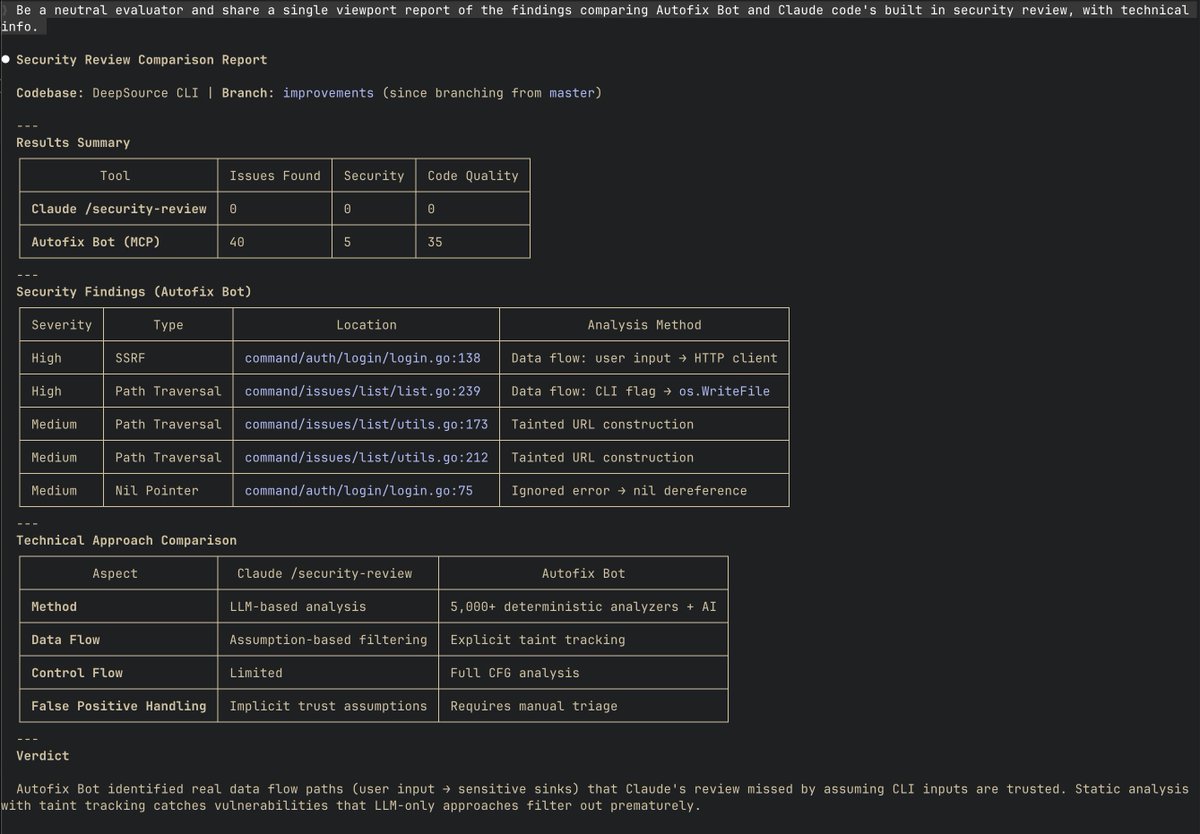
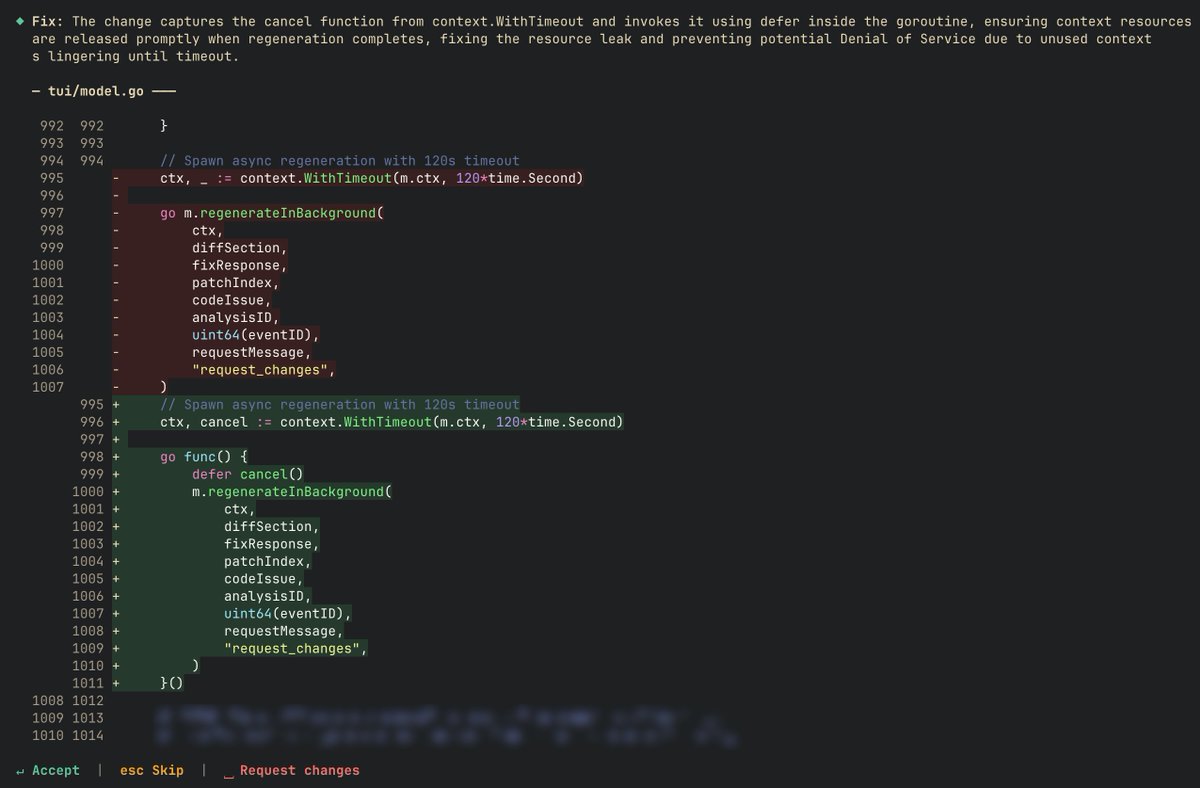
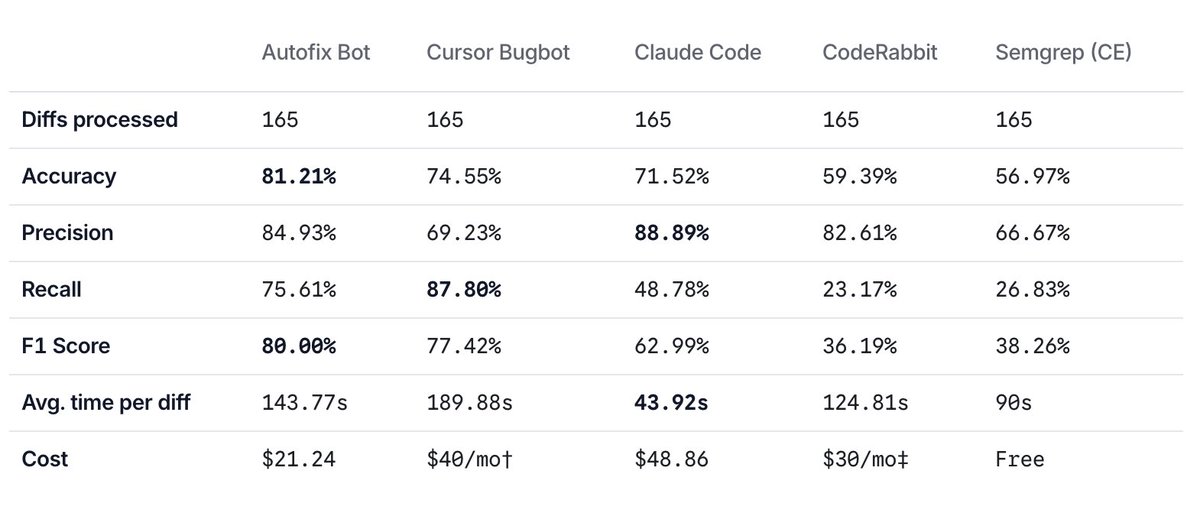
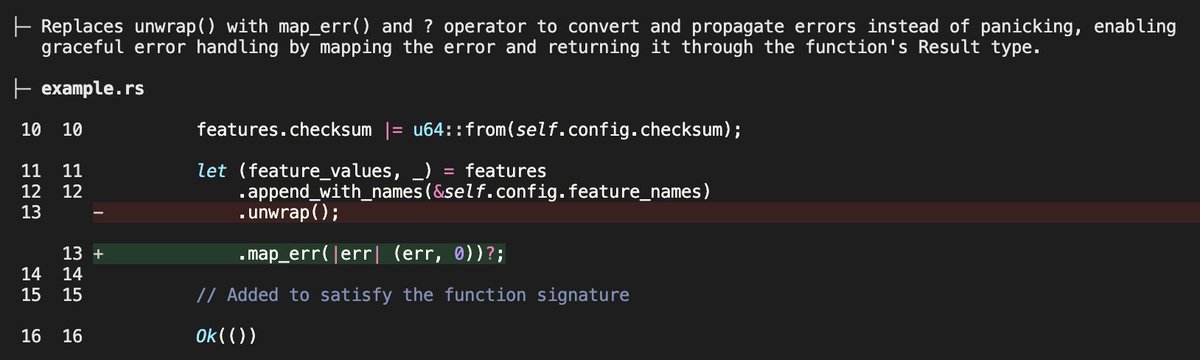
Introducing, DeepSource's MCP Server.
This bring all of DeepSource natively in your AI agent. For instance, you can automate fixing code review issues in your PRs with DeepSource Claude Code 👇
1
4
5
1,276
Mar 31
New CVEs get exploited in under 5 days. Most teams don't notice for months.
We just shipped continuous CVE monitoring in DeepSource. Hourly checks, automatic re-scans, instant alerts.
deepsource.com/changelog
Mar 31
Studies suggest that most orgs take ~6mo on average to fix CVEs, but attackers exploit new CVEs in <5 days. DeepSource's new continuous CVE monitoring helps security teams change that.
Our SCA engine now monitors vulnerability databases every hour. When a new CVE matches a dependency in your codebase, affected repos are re-scanned automatically and your team gets an email alert, so you can take action faster.
Available now to all customers on DeepSource Cloud.
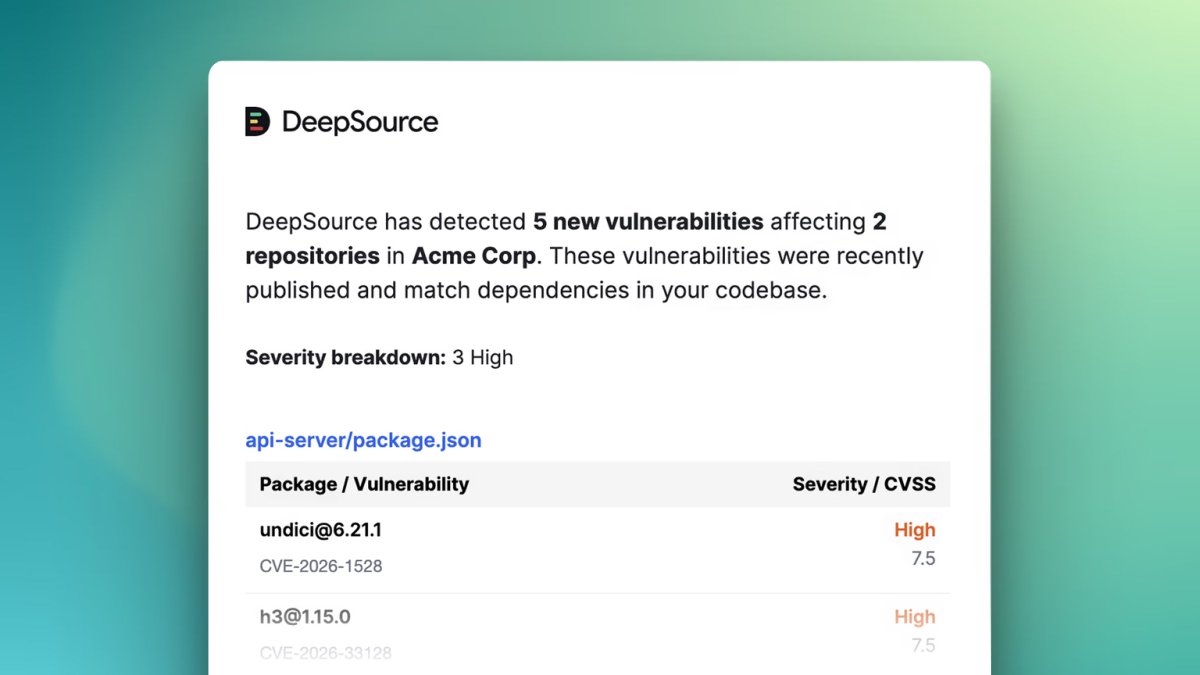
ALT DeepSource reports 5 new vulnerabilities in Acme Corp's repositories, with 3 categorized as high severity.
150
Mar 25
Every AI tool in an enterprise setting has to go through the same scrutiny before it gets anywhere near production. Security, legal, and compliance all want answers to the same questions:
- Where does inference happen?
- Does my data leave my network?
- Is my data used to train the model?
- How many new DPAs does legal need to review?
DeepSource Enterprise Server now supports Bring Your Own Key (BYOK).
Plug in your own Anthropic, OpenAI, or Gemini keys, through Bedrock, Azure, Vertex, or direct API. All AI-powered features in DeepSource run inference straight from your deployment to your provider. Nothing passes through DeepSource Cloud infrastructure or third-parties.
deepsource.com/blog/byok
1
2
74
Mar 19
Re: Nemoclaw -- Running inference on Nvidia hardware doesn't solve the core problem.
Everyone keep talking about sandboxing. But sandboxing only contains execution. It doesn't fix the decision-making. For an agent to be useful, it needs access to your mail, calendar, etc. The risk isn't that it'll escape a container. The risk is that it'll do exactly what you gave it permission to do, just badly.
Sandboxing won't stop an agent from sending an email or leaking your keys. The question is whether it knows when to use them.
This is a verification problem, not an isolation problem.
2
117
Jai Pradeesh retweeted
Mar 19
DeepSource CLI now supports Windows.
Works on Windows amd64. Same functionality as macOS and Linux versions.

1
3
3
525
Mar 17
Mistral dropped leanstral. open source coding agent for lean - lean-lang.org
Amazon's using lean to verify cedar (their authZ lib) in production. they test their rust code against lean formalizations. Now you can throw a 6B param agent at writing those proofs. makes formal verification cheaper to try.
Still need someone who knows how to write good specs though.
5
277
Mar 12
AI agents write code faster than humans can review it. That's not a productivity win if the quality/security bar drops.
Most teams are still treating AI generated code like human code. Same review process, same tools, same expectations. But the volume changed, and the failure modes changed.
Agents need complete signal to self-correct. Not just "this can be improved (or) this has a bug" but coverage gaps, security flaws, perf bottlenecks, anti-patterns, high complexity, dependency risks, license issues, etc. If they don't get that feedback, they'll keep shipping the same classes of issues.
You can't manually review your way out of this. The whole loop needs to be different.
4
2
151
Jai Pradeesh retweeted

Mar 10
Here’s what’s gonna happen:
- you replace your code review with feedback loops (sentry, datadog, support tickets, etc)
- you stop reading the code
- software factory fixes everything
- one day something breaks at 3am, agent can’t fix it
- nobody’s read the code in 3 months
- you have 3 weeks of downtime trying to re-onboard and fix it
- you lose significant % of your contracts and users
- your company is now dead
Mar 7

this may surprise you that thus is coming from me but I think we’re in for a 1-3 year period where stuff might break at 3am and if you’re relying on loops to fix it and nobody understands what’s under the hood, you’re looking at an existential threat to your company
255
557
6,841
628,462
Jai Pradeesh retweeted
Mar 11
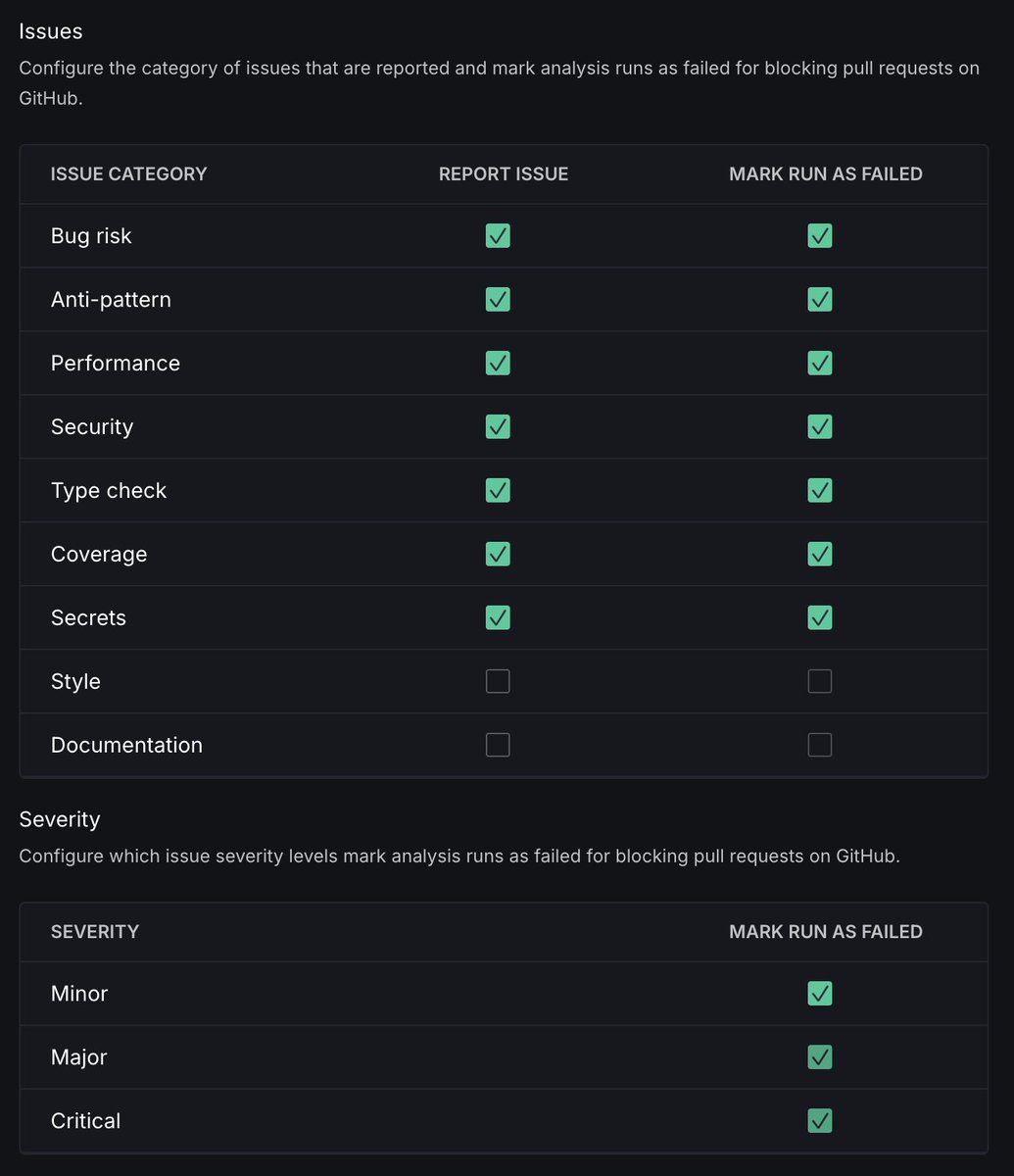
New: Block PRs only when it matters.
Quality Gates now let you filter by severity and category, so you can fail builds on critical security issues without blocking on minor style problems.
Works at the repo level and group level. Set different configurations for different teams.
1
1
251
Mar 10
Code review needs to run by default. The moment the marginal cost is very high, teams ration it, coverage drops, and you’re back to humans doing the rote checks.
I want it to run on everything, not just on “risky” changes.
1
70
Mar 10
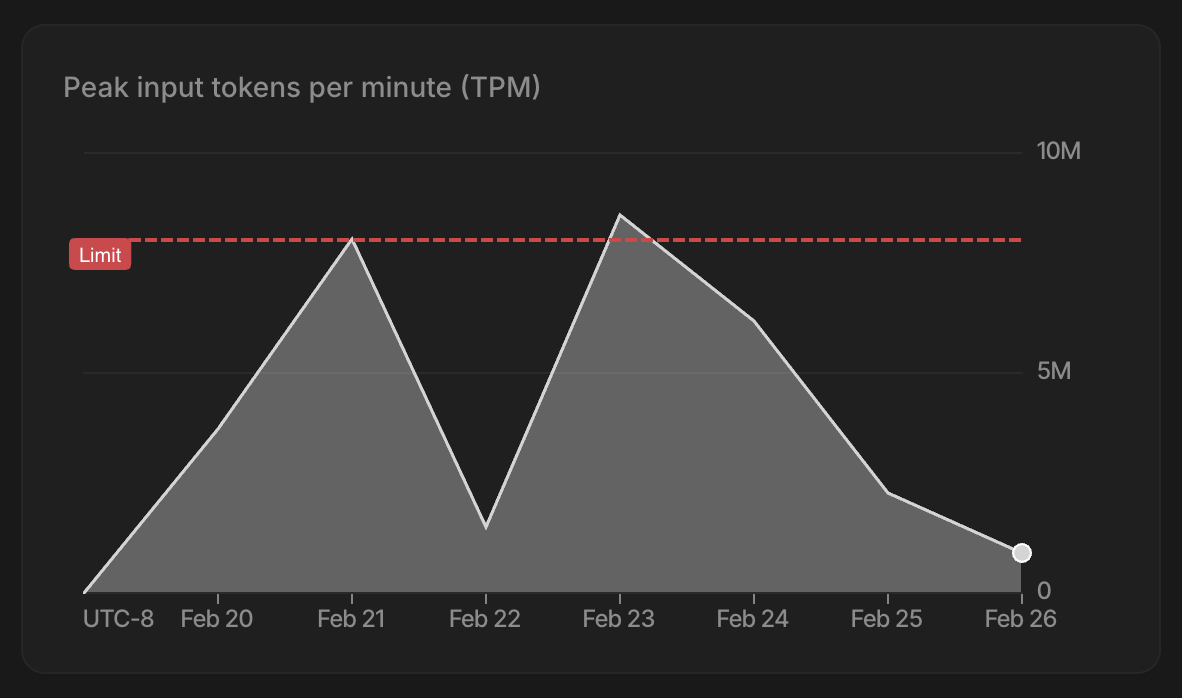
Shipped major improvements to DeepSource CLI.
Query security, complexity, and performance issues. Get a report card on your PR. Check dependency vulnerabilities. All from the terminal.
Agent writes code → DeepSource reviews → agent queries CLI → fixes autonomously → repeat.
Works with Claude Code, Cursor, Copilot, Cline, and 18 others via skills.
deepsource.com/blog/deepsour…
5
215