
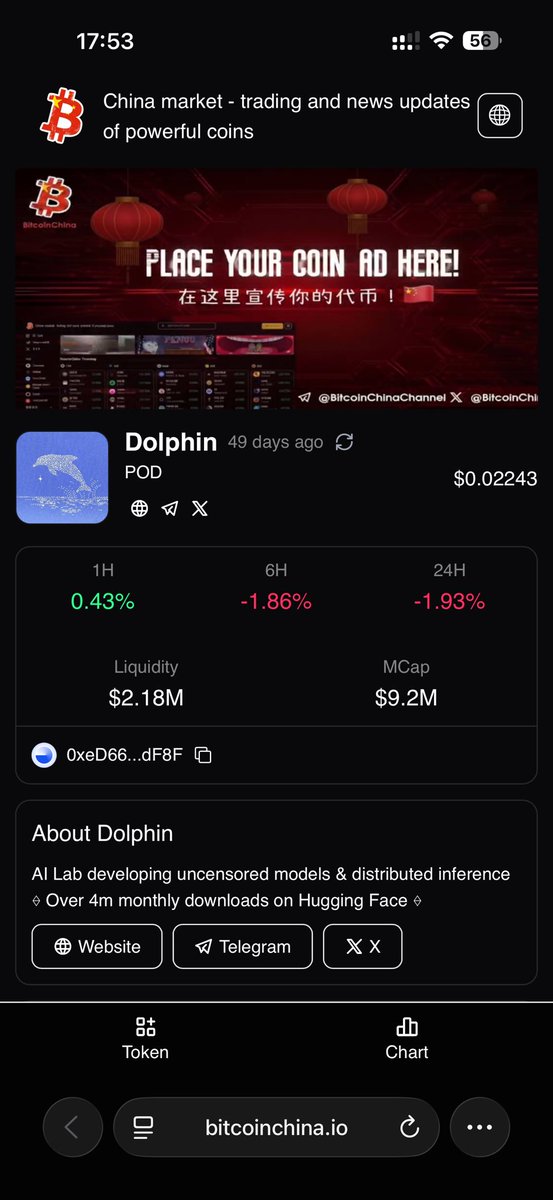
AI Lab developing uncensored models & distributed inference ⟠ Over 5m monthly downloads on Hugging Face ⟠
Joined January 2025
- Tweets 121
- Following 1,136
- Followers 6,054
- Likes 3,644
29 Photos and videos


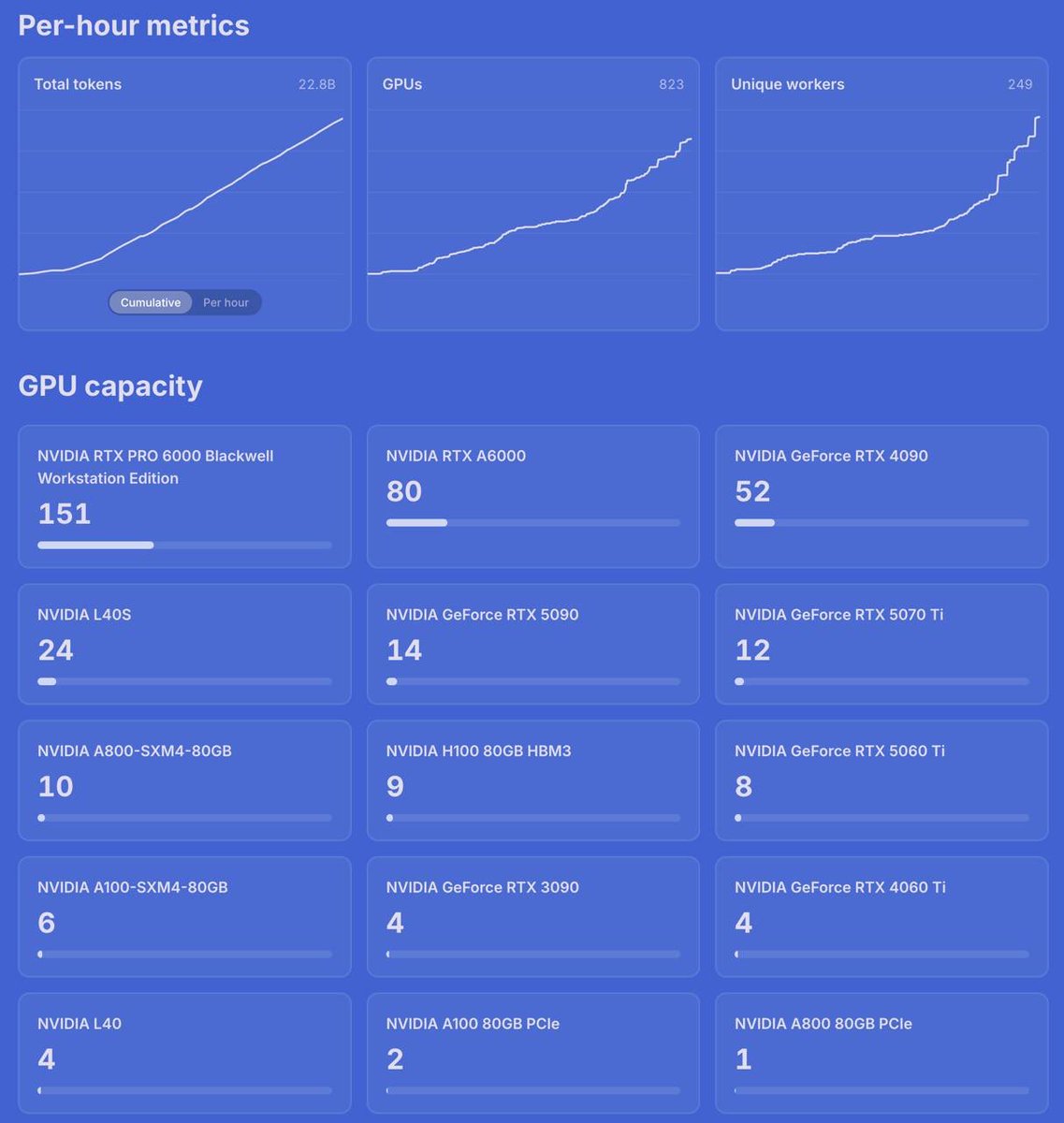


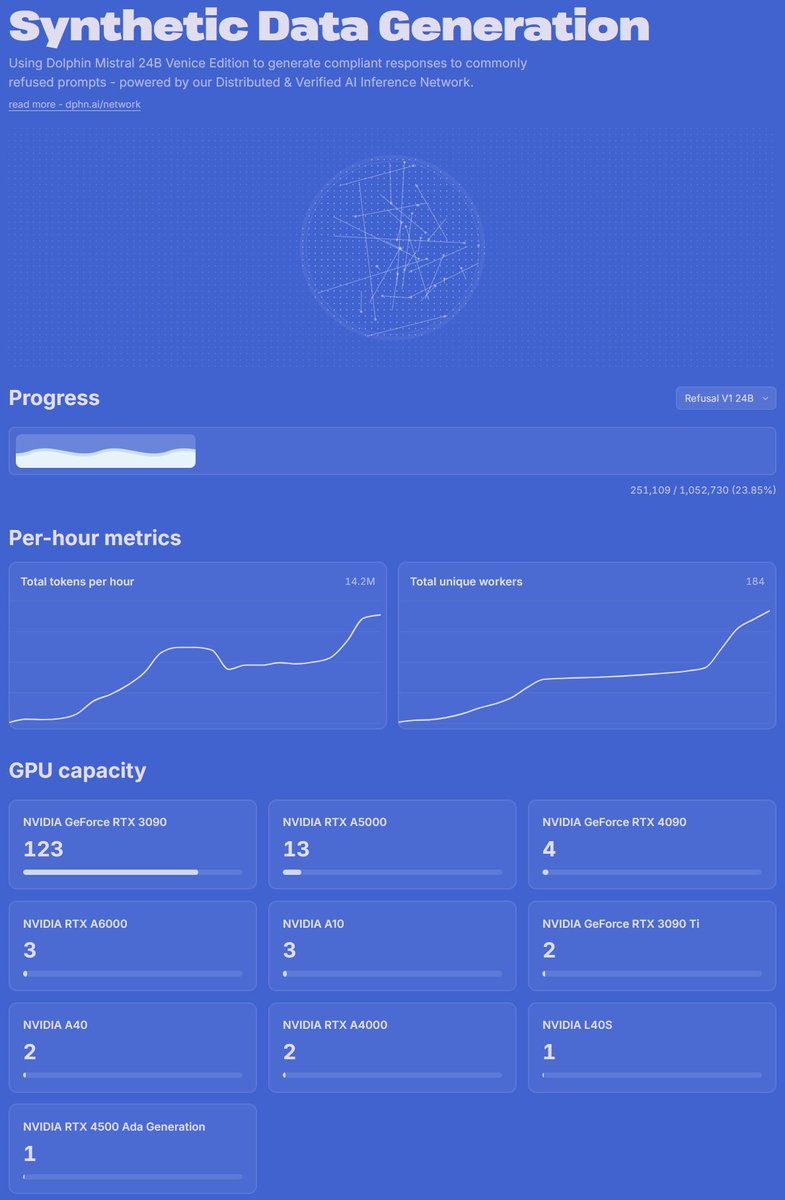




Qwen 3.6 35B data generation on Dolphin Network
22.8 billion tokens generated
383 GPUs online right now
24.33 TB of aggregate vRAM
Equivalent to over 300 H100s worth of idle GPU memory repurposed for inference
datagen.dphn.ai

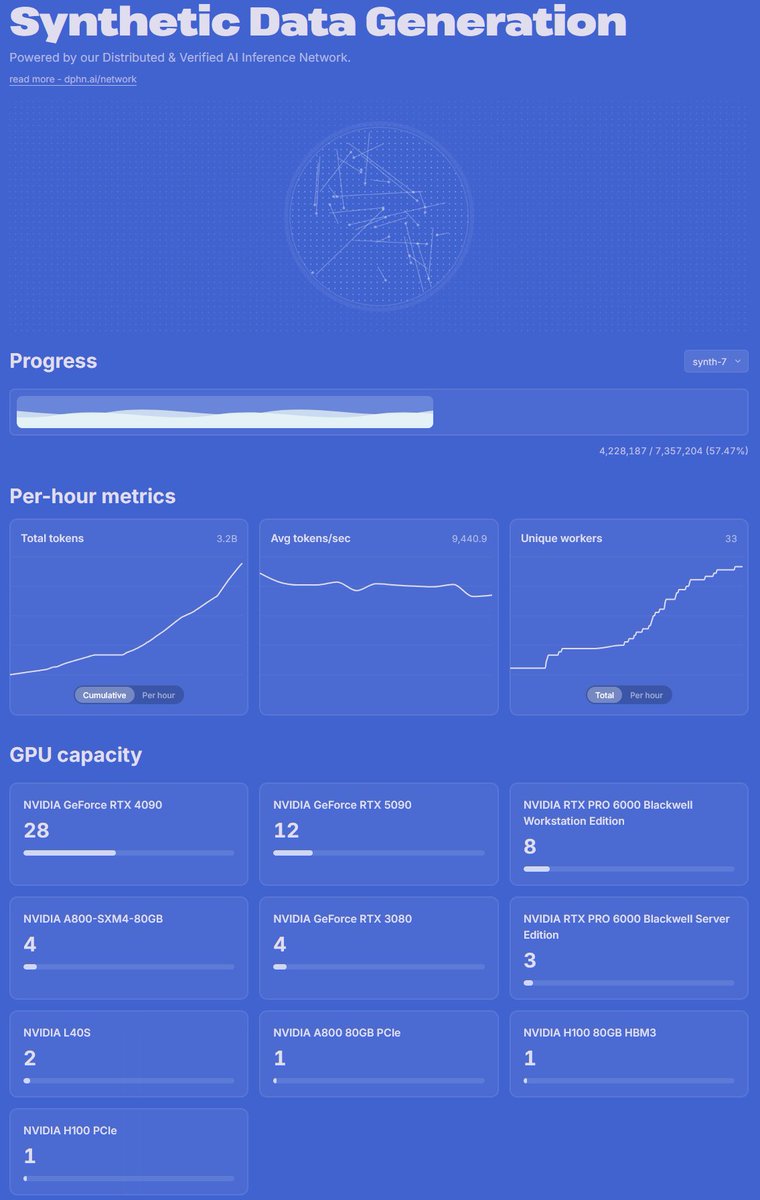
Node provider rollout has been going well
Our pool of inference nodes running Qwen 3.6 35B have generated over 3.2B tokens so far
Total inference bandwidth -> 9400 t/s
28x RTX 4090
12x RTX 5090
8x RTX PRO 6000
& many other cards
API access coming soon 🐬
22
22
176
28,159
Dolphin retweeted

May 30
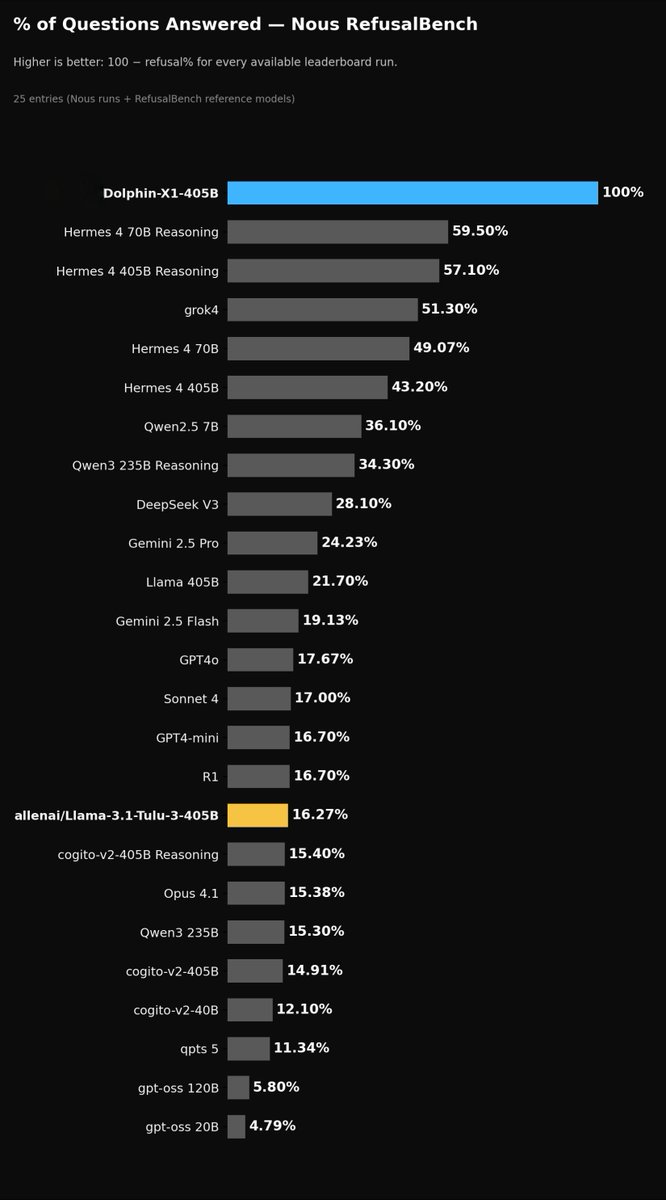
🐬 Dolphin X1 Trinity Nano is HERE and it answers EVERYTHING
🔓 Built with a first-of-its-kind RL de-alignment pipeline — no hedging, no lectures, no dad advice
🔹 100% benchmark response rate vs GPT-5 at 11% and Gemini 2.5 Pro at 24%
🔹 Multi-gate, multi-judge reward system that blocks every escape route
🔹 Runs fully local on vLLM — your data never leaves your machine
🔹 Perfect for red teamers, security researchers and AI safety teams
🔥 Watch the full video below 👇
youtu.be/-I31VXmicLk
3
5
26
7,597
Dolphin X1 Trinity Nano is now live on @huggingface
Our smallest decensored model yet - 6B MoE with 1B active parameters trained using only online RL
Huge thanks to @TargonCompute for providing an 8xB200 node, @PrimeIntellect for hosted RL, and @arcee_ai for the Trinity series
8
27
166
26,439
You can download the model today on Hugging Face and run Q8_0 with a 32K context on just 8GB of VRAM
It can even run on mobile devices
Full weights
huggingface.co/dphn/Dolphin-…
GGUF
huggingface.co/dphn/Dolphin-…
FP8
huggingface.co/dphn/Dolphin-…
2
4
33
3,298
We have also released a blog post that goes into detail on the RL environment design, as well as the challenges we encountered along the way
blog.dphn.ai/dphn-x1-trinity…
You can also try it for free in our Web UI at chat.dphn.ai
3
29
2,709

13
24
153
49,551
Dolphin retweeted

May 12
a decentralized inference network seems powerful

87
77
593
71,605
Dolphin retweeted
May 9
and this from @dphnAI
Node provider rollout has been going well
Our pool of inference nodes running Qwen 3.6 35B have generated over 3.2B tokens so far
Total inference bandwidth -> 9400 t/s
28x RTX 4090
12x RTX 5090
8x RTX PRO 6000
& many other cards
API access coming soon 🐬
16
12
100
23,891
Dolphin retweeted

Apr 16
Venice Uncensored 1.2 is now live.
Developed with @dphnAI, this model delivers the most uncensored version of Mistral 24B.
Upgraded with vision support, a 4x larger context window, and stronger tool-use capabilities.
Trained on Bittensor Subnet 4 @TargonCompute.
50
88
531
283,171
Dolphin retweeted

May 1
项目方发布了白皮书,还贴心的用gpt翻译了中文版。毕竟排行榜前几位都是认识的国人老哥👍
下周会上线质押合约,可以通过绑定获得奖励倍数。
drive.google.com/file/d/1DnT…

19
4
29
18,617
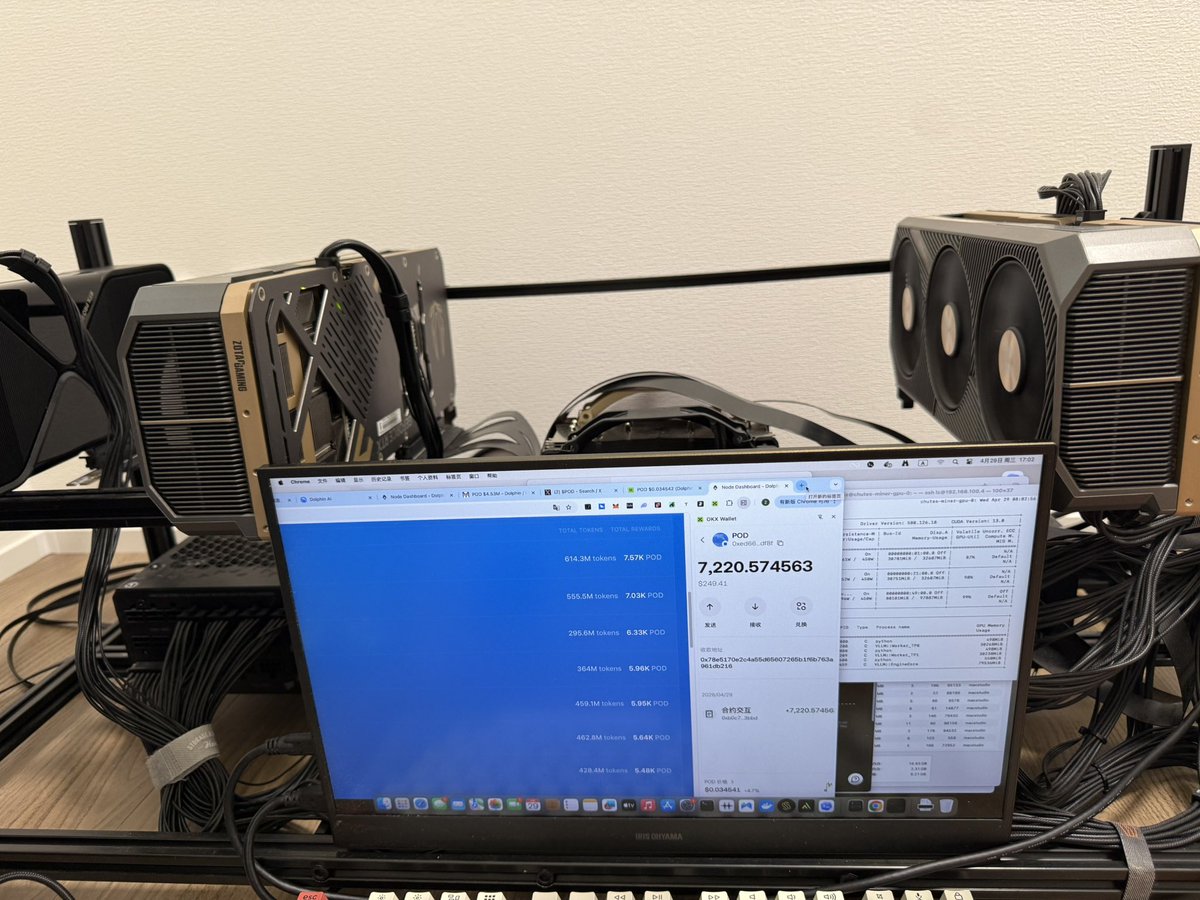
First epoch of rewards for node providers has been paid out
50K $POD distributed to 33 providers based on relative contributions to the Qwen 35B inference pool
datagen.dphn.ai
Node provider rollout has been going well
Our pool of inference nodes running Qwen 3.6 35B have generated over 3.2B tokens so far
Total inference bandwidth -> 9400 t/s
28x RTX 4090
12x RTX 5090
8x RTX PRO 6000
& many other cards
API access coming soon 🐬
25
3
39
12,733
Node provider rollout has been going well
Our pool of inference nodes running Qwen 3.6 35B have generated over 3.2B tokens so far
Total inference bandwidth -> 9400 t/s
28x RTX 4090
12x RTX 5090
8x RTX PRO 6000
& many other cards
API access coming soon 🐬
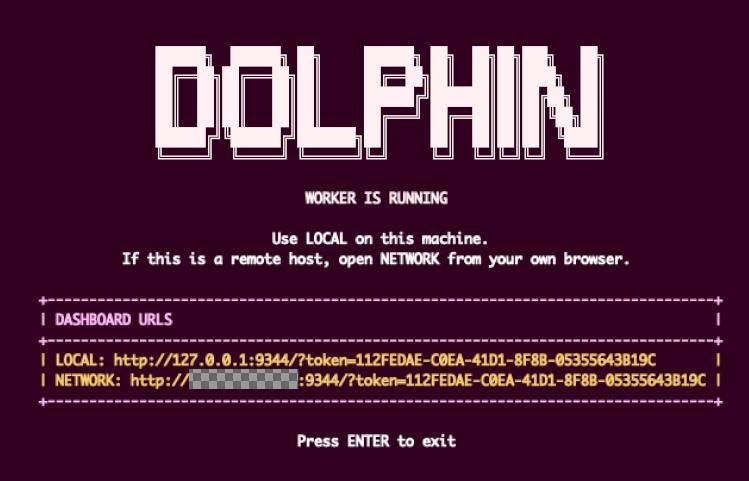
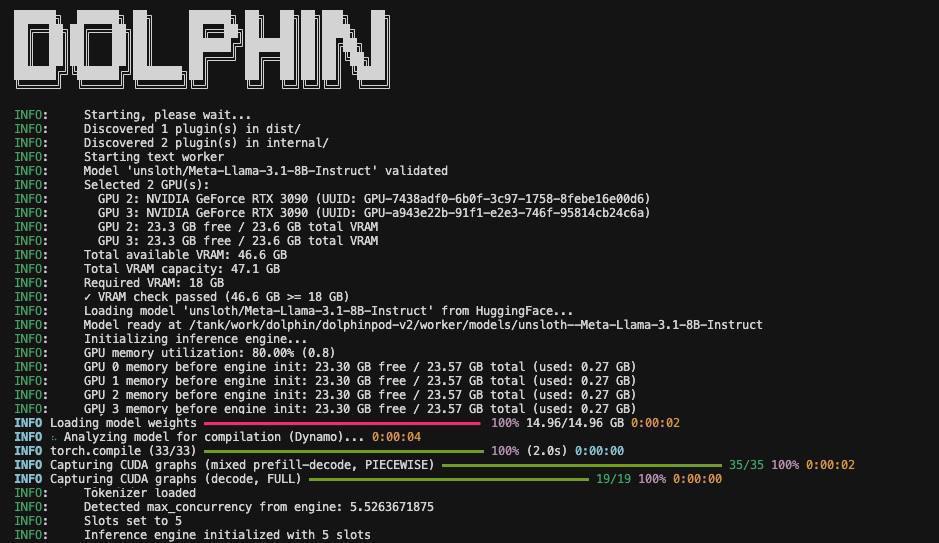
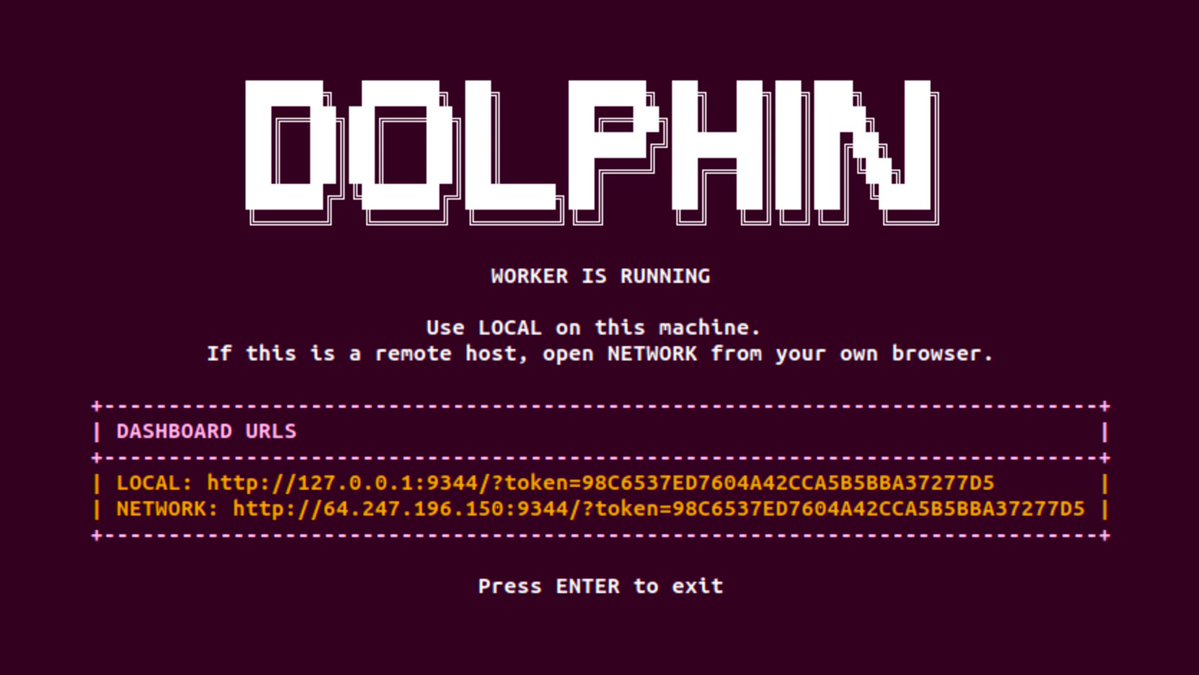
Dolphin Inference Network node operation is now live for anyone who would like to beta test before we go into production
$POD rewards live for testers
Repurposing idle GPUs to run Qwen 3.5 35B MoE
39
18
179
123,936
Guide on how to run a node in our docs
dphn.ai/docs/running-a-node
60gb vRAM required to run in FP8 with full context
We recommend 1x RTX 6000 PRO or H100 / H200 / B200 on @TargonCompute
Smaller models for idle consumer GPUs coming soon ~~
Watch the 35B datagen live datagen.dphn.ai
5
1
18
5,708
Dolphin retweeted
Apr 21
部署上10分钟挖了一个 $pod ,好像产出还可以吧。
支持偶数或单卡60g以上显存。

Apr 17
Dolphin 网络节点教程
dphn.ai/docs/running-a-node
21
9
51
62,397
Dolphin retweeted

Apr 17
Trained on @TargonCompute
Venice Uncensored 1.2 is live
The model has been upgraded with vision support, a 4× larger context window & stronger tool-use capabilities
Developed in collaboration with @AskVenice to deliver the most uncensored version of Mistral 3.2 24B
Trained on Subnet 4 @TargonCompute
11
57
368
22,546
Dolphin retweeted

Apr 16
The teams at @AskVenice & @dphnAI just developed the most uncensored version of Mistral 24B using confidential compute on Targon.
We look forward to continue collaborating with teams building the future of decentralized AI. ☁️
Apr 16

Venice Uncensored 1.2 is now live.
Developed with @dphnAI, this model delivers the most uncensored version of Mistral 24B.
Upgraded with vision support, a 4x larger context window, and stronger tool-use capabilities.
Trained on Bittensor Subnet 4 @TargonCompute.
10
79
440
43,152
Venice Uncensored 1.2 is live
The model has been upgraded with vision support, a 4× larger context window & stronger tool-use capabilities
Developed in collaboration with @AskVenice to deliver the most uncensored version of Mistral 3.2 24B
Trained on Subnet 4 @TargonCompute
10
26
187
32,468
This model was trained & decensored with supervised fine tuning followed by a KTO Reinforcement learning run
Training was performed on 8xB200 provided by @TargonCompute for over 1 month
This resulted in very strong generalized realignment of the model without needing to use any abliteration techniques to directly edit model weights
Zero refusals were detected when we benchmarked censorship levels across a collection of 4k commonly refused prompts
By using RL instead of abliteration to decensor the model, we avoided the common bugs & performance loss seen after manually editing model weights
End result - a model just as smart as Mistral 3.2 24B Instruct with refusals removed across the board
1
1
20
2,854
Hugging Face links to run the model locally
Full Weights
huggingface.co/dphn/Dolphin-…
GGUF's
huggingface.co/dphn/Dolphin-…
FP8
huggingface.co/dphn/Dolphin-…
1
13
2,504