
I'm building my assistant in Hermes. No, I won't blindly trust it ◆ I teach you the way of responsible AI: your data, your rules ◆ PhD in computer science ◆ Dad
Joined January 2022
- Tweets 8,937
- Following 1,283
- Followers 5,028
- Likes 16,926
1,642 Photos and videos









Pinned Tweet

11 Jun 2025
Ever wondered how model quantization (FP16, Q8, Q4) *really* affects performance?
There's an analogy that makes the trade-offs crystal clear... and it involves something you might drink. 😉🍺
Kudos to @jtdavies for this brilliant comparison. 🙏
See the image for the full explanation! 👇

1
2
17
3,013
Hermes Desktop is available for Linux 🤘
Thats in contrast to all the other harness desktop apps of the major players. I like it a lot. Thanks @NousResearch. 🫶
Jun 2

The next evolution of Hermes Agent is here!
Introducing Hermes Desktop: everything you love about Hermes, now native on your machine.
First demoed in Jensen's GTC keynote, it's now in public preview.
2
5
197
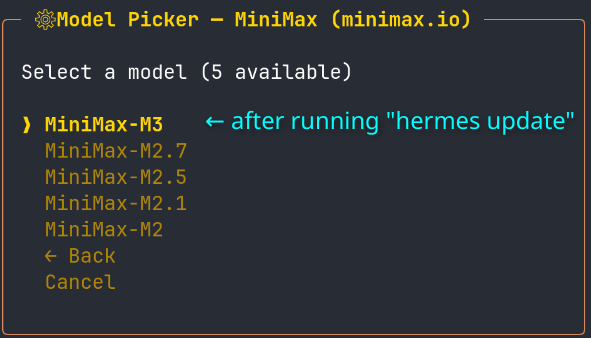
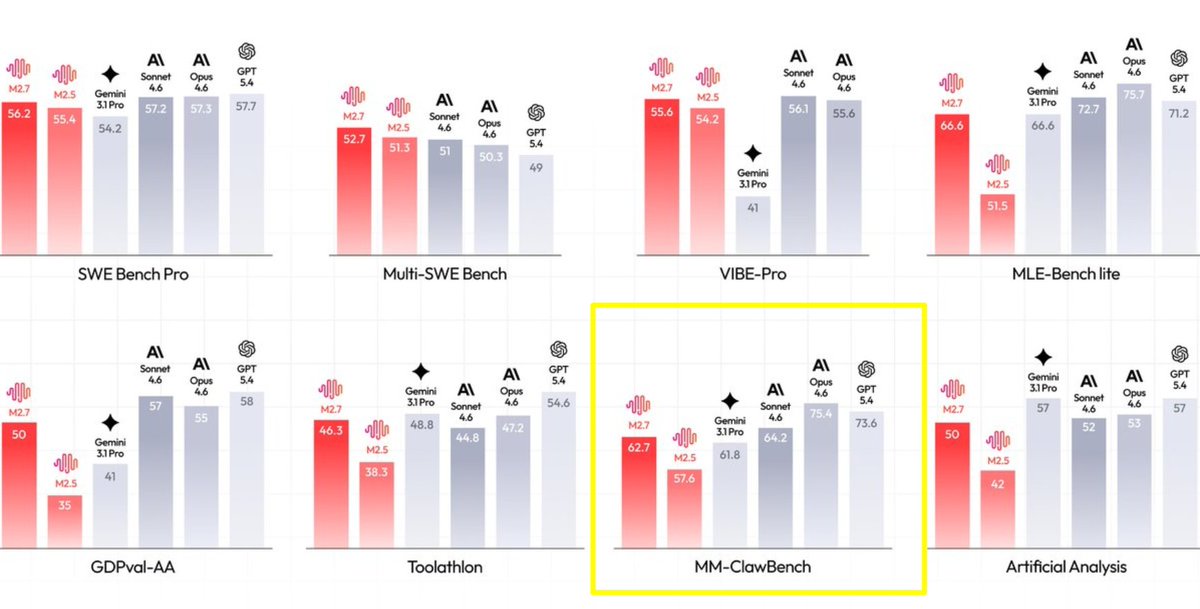
Love the new MiniMax M3 release. 🫶
I am not sure if the "hermes update" was needed, but the model is already available in Hermes Againt from @NousResearch and my first vibe check of M3 is very positive.

Introducing MiniMax M3: The First Open-Weights Model to Combine Three Frontier Capabilities
- Coding & Agentic Frontier: 59.0% SWE-Bench Pro, 66.0% Terminal Bench 2.1, 34.8% SWE-fficiency, 28.8% KernelBench Hard, 74.2% MCP Atlas
- MiniMax Sparse Attention scales context to 1M
- Natively Multimodal from Step Zero
API: platform.minimax.io
Token Plan: platform.minimax.io/subscrib…
🚀New! MiniMax Code: code.minimax.io
Weights & Tech Report in ~10 Days

4
218
Dr. Daniel Bender retweeted

May 29
Today, frontier AI online is faster & smarter, so I use mainly that. Long term, local AI only needs to become good enough. Once it just works, I want my own trusted AI running locally, calling online models when needed - while providers focus on global problems, not our inboxes.
1
2
310
May 29
Privacy Versus The Best Model
@naval raises a core trade-off: will open source models survive if the best-performing models require centralized cloud access?
He suggests users may willingly sacrifice privacy and openness to get the smartest model available.
That implies commercial cloud providers could win simply by delivering superior performance.
The question is framed as a major, world-shattering decision for how AI ecosystems evolve.
Naval emphasizes the scale and importance by calling these “huge” and “world-shattering” questions.
4
2
5
471
May 29
And thanks to Anthropic (and their competition) it is easier than ever before to start your own company.
Do you agree?
May 28

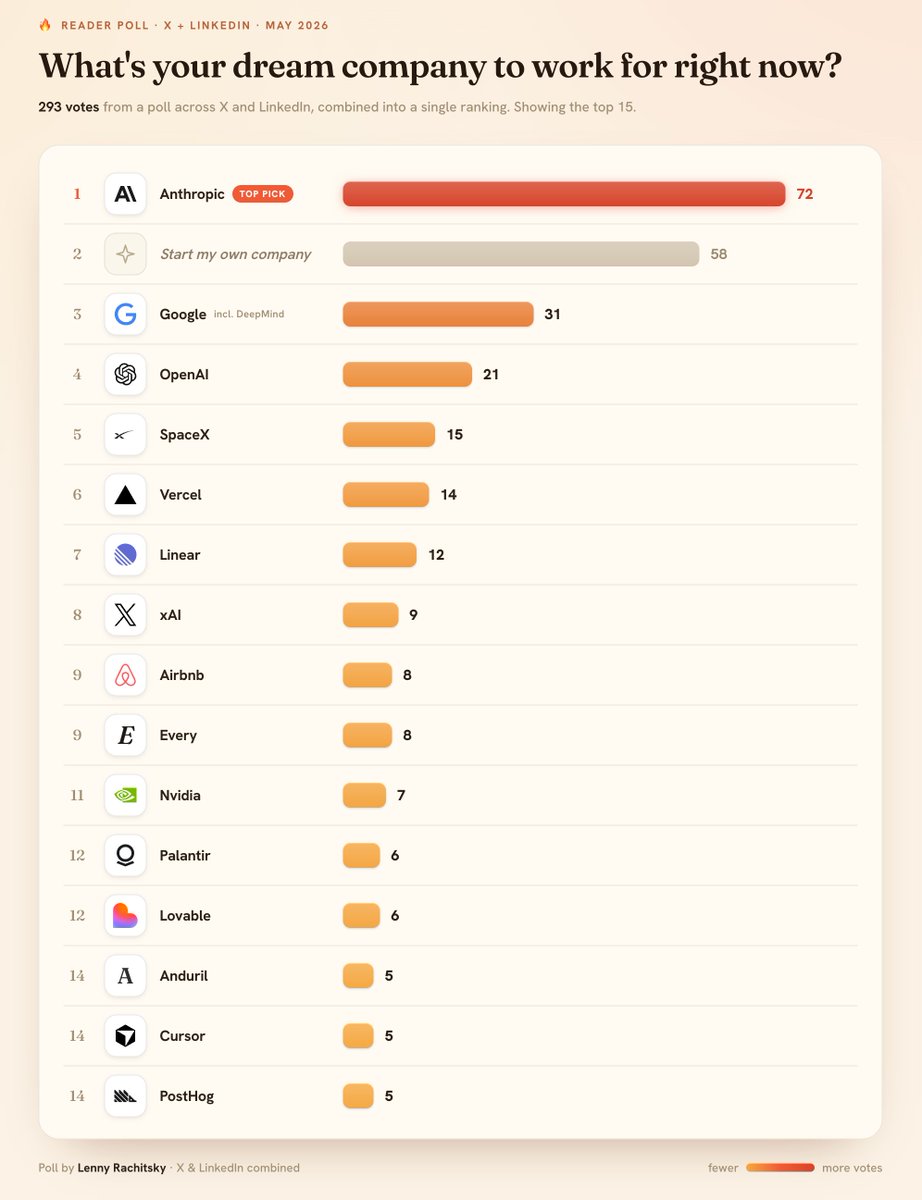
Fascinating results
Anthropic running away with it right now
So many people want to start their own company
Google over OpenAI
Vercel, Linear, Every, PostHog overperforming
A great list if you're trying to figure out where to go work 👇
1
88
May 29
It seems like Anthropic is back 👇
May 28

BREAKING:
Anthropic just dropped Opus 4.8—and it is a MONSTER
We've been testing for about a week @every and our verdict is they could've just called it Opus 5, it's that good.
Here's our vibe check:
- Beats GPT-5.5 on Senior Engineer bench. On our toughest benchmark Opus 4.8 scores a 63—a hair higher than GPT-5.5's score of 62, and a full 30 points higher than Opus 4.7. It tackled a ground-up rewrite of a production codebase, and actually built something that works.
HOWEVER: Coding performance varied a lot at different reasoning levels. We recommend using it on xhigh for best results.
- Incredibly good writer. Opus 4.8 scored a 79.6 on our writing benchmark—measuring models on real-world writing tasks we do all of the time like essay writing, promo email writing, and more. It beats GPT-5.5 by 6 points. It produces well-written prose with fewer "AI-isms". It's also very good at writing in your voice given the right context.
HOWEVER: Writing performance also varied with reasoning levels. Medium reasoning had higher incidence of AI-isms—we found best results with high.
- Beast at knowledge work. Opus 4.8 is very good at general knowledge work tasks like report creation, research and more. It produced the best PowerPoint one-shot we've ever seen on our deck generation benchmark.
- Emotionally intelligent, willing to question the frame. I've also found it to be quite good at talking through psychological or interpersonal issues. It has a high EQ, and it's also good at not glazing and helping to expand your perspective. Its thought process feels extremely rich and dynamic.
THE BAD:
These days a model is only as good as its harness, and Codex is still a far superior harness to the Claude Desktop app. This has kept me using Codex GPT-5.5 as my daily driver, but I am flipping back and forth a lot more between Codex and Claude.
Anthropic is back baby!
Read the rest on @every:
every.to/vibe-check/opus-4-8…
3
174
May 29
So hard to keep up, just learned that Opus 4.8 seems to be out. 😳
To at least try to keep updated in AI, the @thursdai_pod is my preferred source. 👇
May 29

It's never a quiet week in AI. Here's what happened this week - including today's release of the new ultrathinking Claude Opus 4.8:
1
4
511
May 29
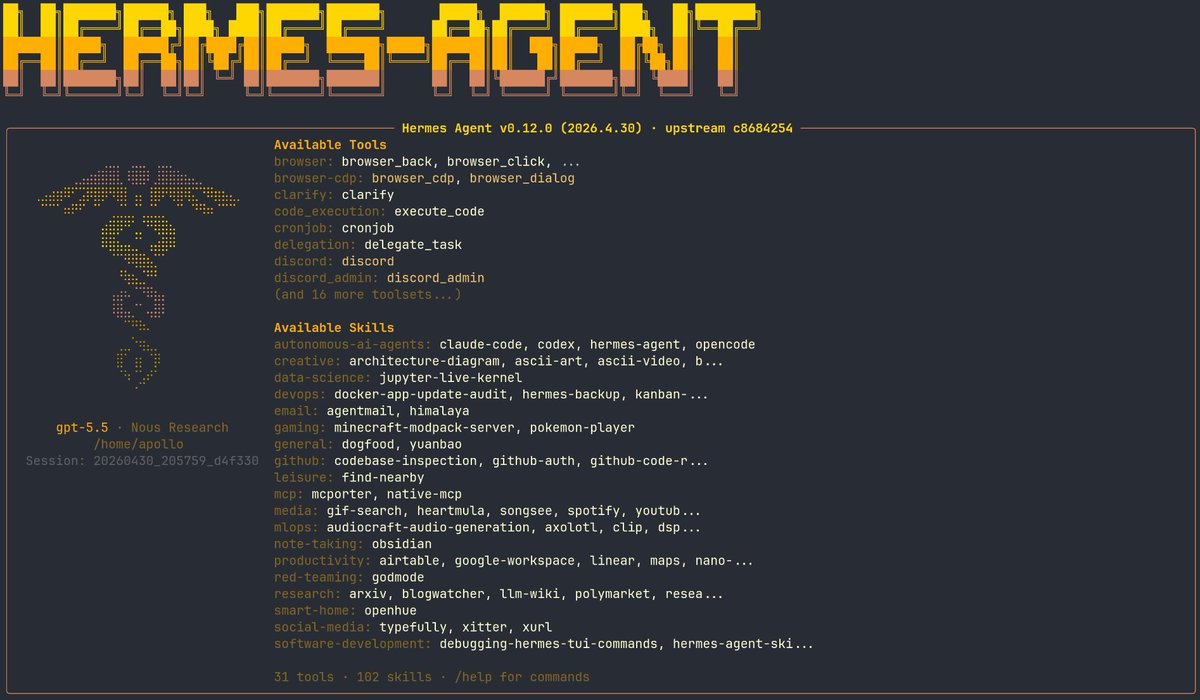
Hermes Agent v0.15.1 dropped and brings a massive update to its skill catalog!
The entries in the skill catalog went from 858 to 19,932 entries in that single release. That's a massive expansion of what your agent can do out of the box.
Here's what you need to know: be careful what you install!
The skills hub is growing fast, and it's become easy to grab a third-party skill and just trust it works. But you're handing an LLM agent code that can read your files, run tools, and act on your behalf. If there's no official skill from the company behind the tool you want to use, it's safer to let your agent build the skill for you instead. It takes seconds, you control exactly what it does, and there's no mystery about what got injected into your setup.
The full changelog with all the other changes is linked below. 👇
2
2
589
May 24
Supply chain attacks are really scary for developers and users of AI agents.
Besides general safety rules like using sandboxes and delaying package installs, a scanner checking for infections is a good tool to have.
Thanks to @perplexity_ai for open-sourcing Bumblebee 🫶
May 22

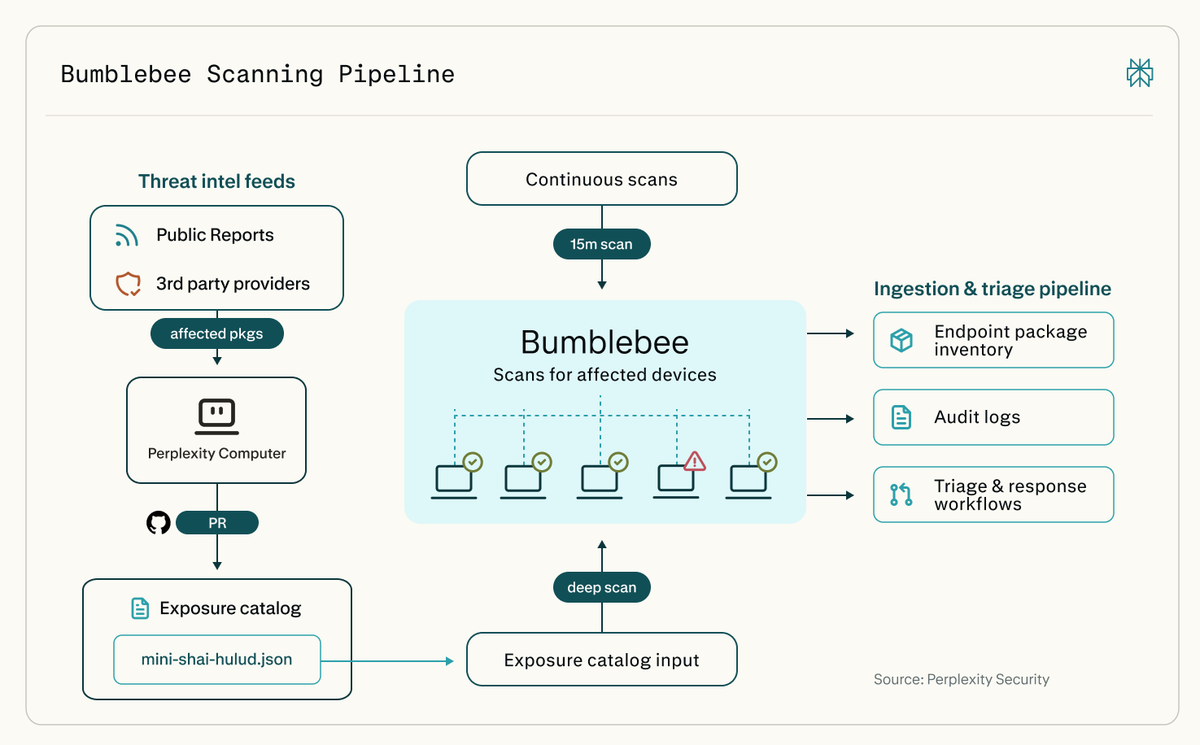
Today we're open-sourcing Bumblebee, a read-only scanner for macOS and Linux.
It checks developer machines for risky packages, extensions, and AI tool configs.
Connected to Computer, it can trigger deeper scans whenever a new supply-chain risk emerges.
github.com/perplexityai/bumb…
4
308
May 21
Todoist is shipping features like AI task capture, urgent reminders, and better reporting. Useful, sure.
But the real story is bigger:
we're getting closer to agents that can take unstructured input, extract intent, create tasks, and feed the result into any system you use.
Not just one app.
2
201
May 19
Looking forward to talk later today to my AI buddies and everyone else who is interested in these topics. 👇 x.com/i/spaces/1RJjpzwnEWRKw
2
5
145
May 19
The AI event in Cologne mentioned at the end of the space:
x.com/WolframRvnwlf/status/2…
May 11
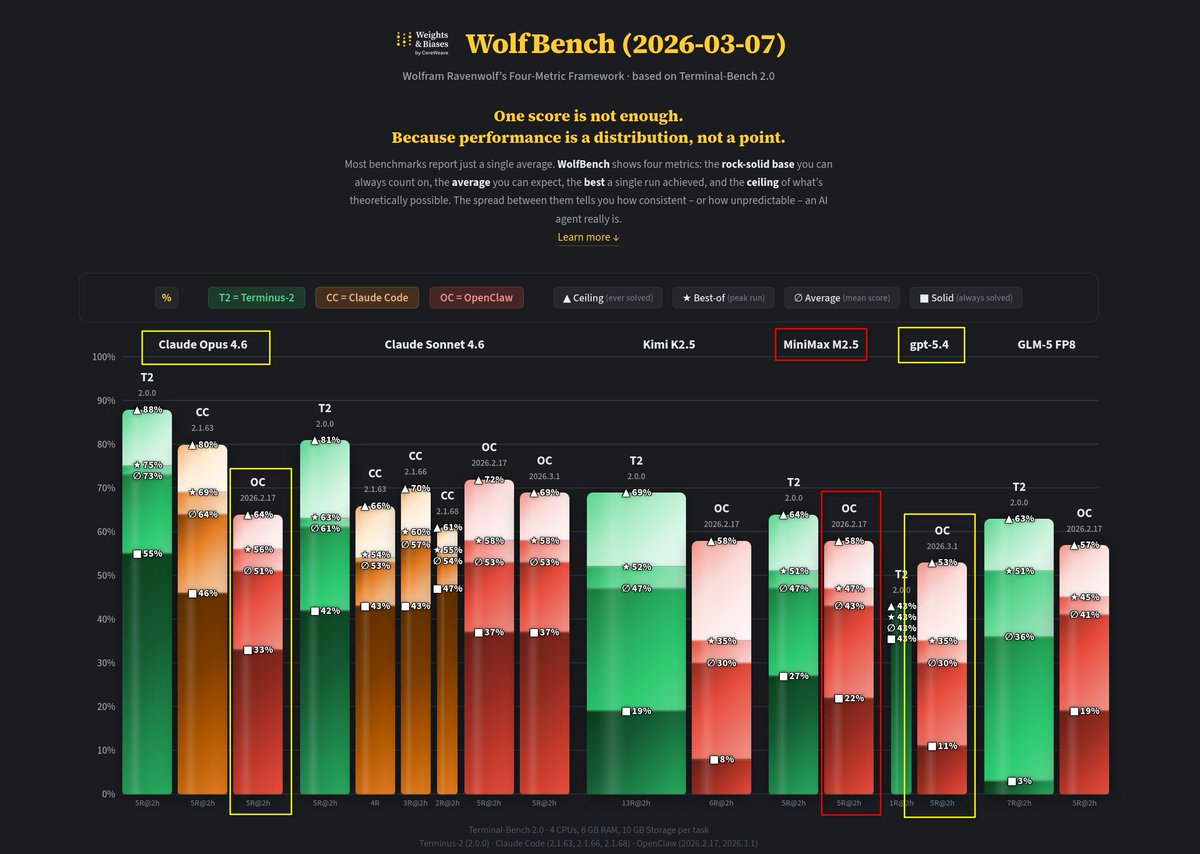
I'm speaking at AIDev 6 in Cologne on 2 June about WolfBench.ai and why one score is not enough for evaluating AI agents.
Agent performance depends on more than the model: harnesses, tools, task design, reliability, and real-world failure modes matter. A leaderboard number alone won't tell you whether an agent will actually survive contact with production.
Excited to discuss practical agent evals – and to hear @jphme on secure online agent deployment.
Registration is free but limited. Link in comments.

ALT AIDev 6 - Developer Community (LLM, Applications & Generative AI)
2
83
May 19
46
May 19
The Google I/O demo at creating a stylized video from a video input and guiding images looked outstanding.
It was stated that the model is available from today world-wide in the Gemini App. So far, it is not available for me in Germany. 🥲
May 19

We’re dropping Gemini Omni: our first step towards a model that can create anything from anything - starting with video.
It combines Gemini’s intelligence with our generative media systems - representing a leap forward in world understanding, multimodality, and editing 🧵
1
264
May 19
That is a big win for Anthropic. Congrats to them for hiring one the most recognized AI masterminds!
May 19

Personal update: I've joined Anthropic. I think the next few years at the frontier of LLMs will be especially formative. I am very excited to join the team here and get back to R&D. I remain deeply passionate about education and plan to resume my work on it in time.
2
107
May 14
The hard question is no longer how to build it. It’s whether we should build it.
For teams, agreeing on what to build is becoming the bottleneck in the age of AI agents.
For solo developers, that bottleneck is smaller. You can just decide.
That might be one of the underrated advantages of building alone right now.
3
156
May 13
Local-first AI developer book released by @RobbiewOnline 👇
Sounds interesting, but as much as I love local AI models, for coding I still prefer to work with the best available model (which are so far models running in the cloud) as a single mistake can cost you hours in time and millions in tokens.
May 10

After playing with AI for a few months via OpenClaw I evolved to focus more on local AI, principally to save costs but other benefits included increasing privacy (protecting IP) and to have a fallback for when cloud models are simply broken.
I then decided to write a book to share my findings and it's just gone live on Amazon!!
I've kept it as cheap as possible - there are too many people trying to make money with AI rather than share genuine experiences to benefit others.
The only bit left is to fix Amazon accidentally merging another authors bio as mine!

1
2
292
May 13
If you enjoy working and playing with AI models - and you're near Cologne, Germany - AIDEV 6 on June 2nd is the place to be!👇
I still have great memories of my first AIDEV 3. It was where I met @WolframRvnwlf and @jtdavies in person for the first time, and we've stayed in touch ever since.
I will be there and can't wait for another great event!
May 11
I'm speaking at AIDev 6 in Cologne on 2 June about WolfBench.ai and why one score is not enough for evaluating AI agents.
Agent performance depends on more than the model: harnesses, tools, task design, reliability, and real-world failure modes matter. A leaderboard number alone won't tell you whether an agent will actually survive contact with production.
Excited to discuss practical agent evals – and to hear @jphme on secure online agent deployment.
Registration is free but limited. Link in comments.
ALT AIDev 6 - Developer Community (LLM, Applications & Generative AI)
1
4
348
May 12
Prepare to get organized.
Personal AI gets practical when it takes the chaos you already have in your inboxes, notes, documents, and photos and turns it into the next actions that actually matter.
The best version of this is agent-first and tool-agnostic.
2
156