
Exec @Arm doing Physical AI, strategy and sw dev tools. BOD member @Teradyneinc. Pilot, Open water swimmer with many Alcatraz swims, never bitten by a 🦈
Joined October 2008
- Tweets 2,558
- Following 192
- Followers 1,077
- Likes 2,116
167 Photos and videos







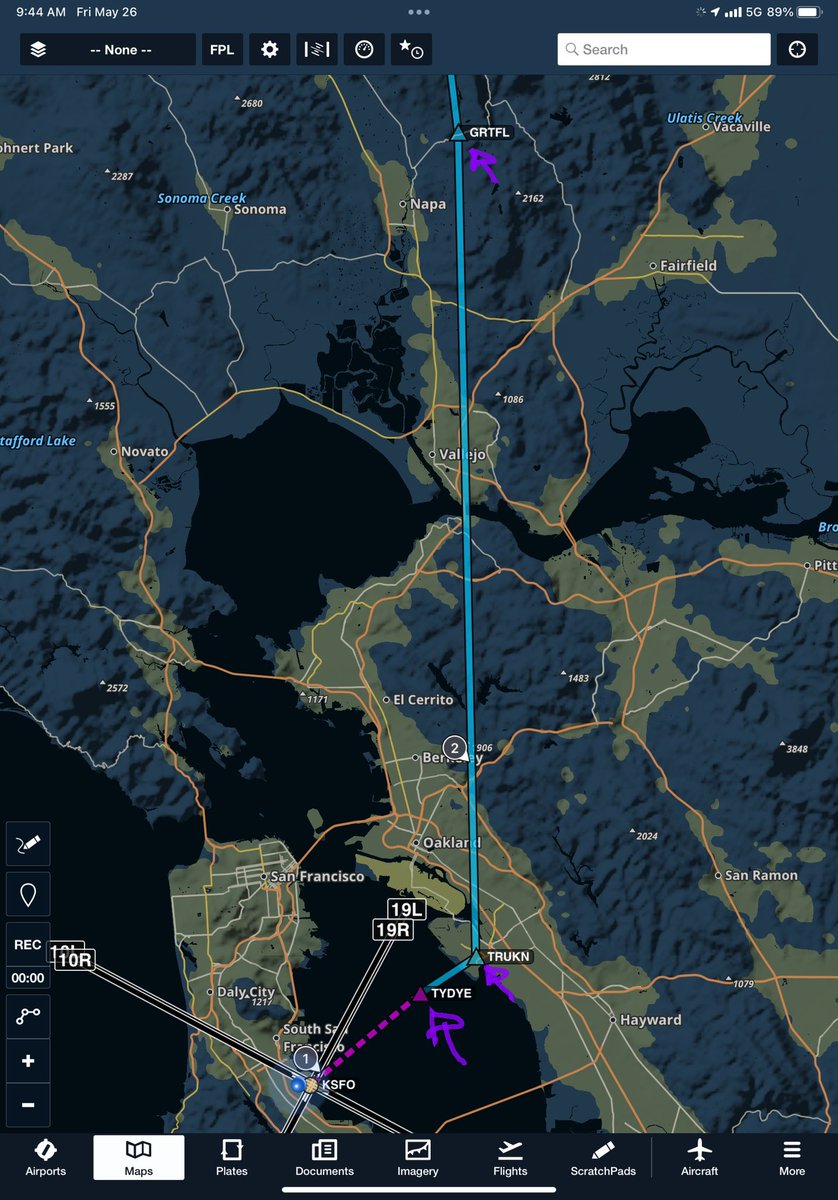


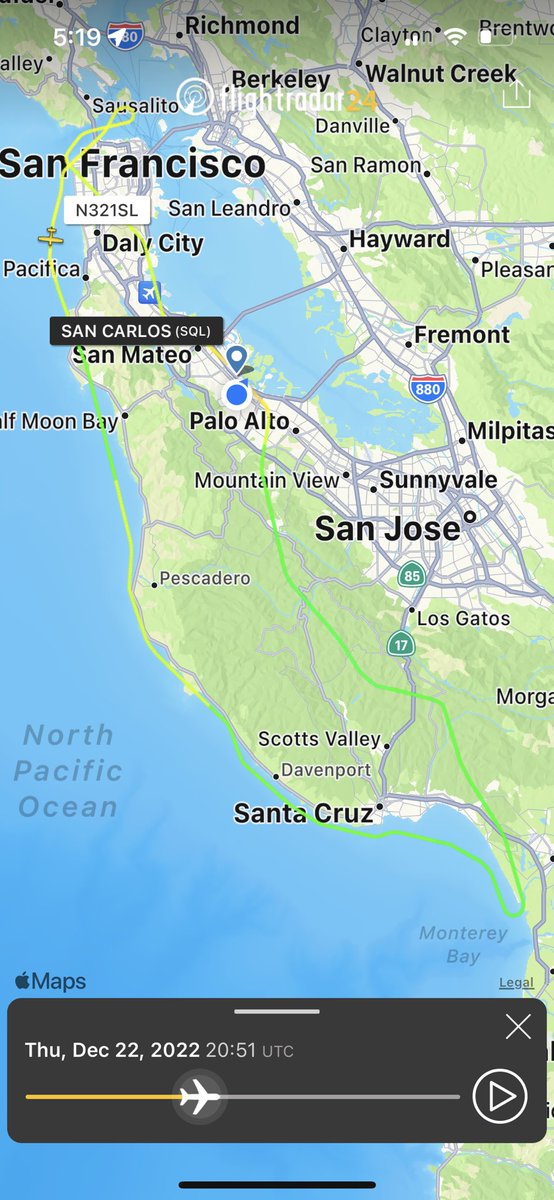



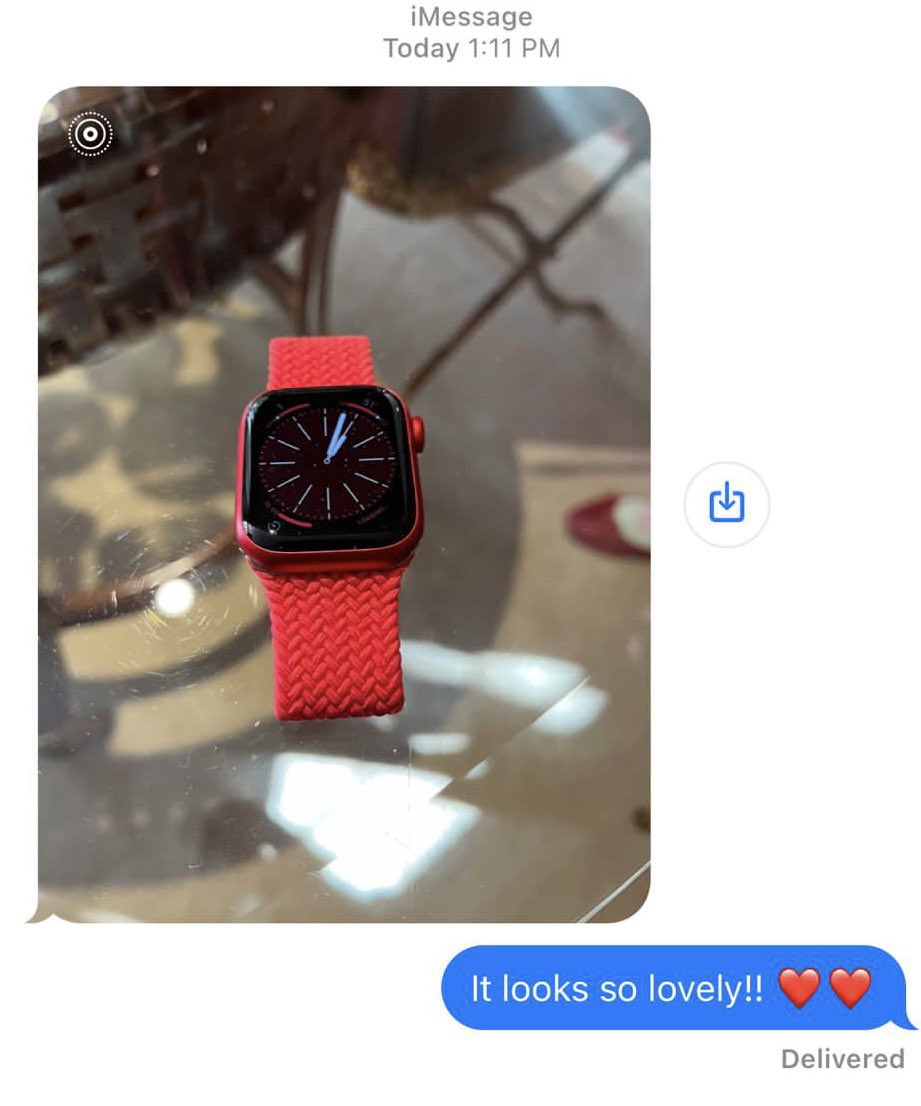

Pinned Tweet

Jun 10
Something super fun that we’ve been working on. World class AI running locally on @Arm GPU powered phones bringing the SOTA of gaming experiences to the world of mobile gaming. Tons of people from across Arm and our partners worked tirelessly to make this happen.
I’m deeply proud of everyone involved. Special thanks to the @SumoDigitalLtd team who did so much to create an experience that is stunning. Thanks also to @EpicGames for building @UnrealEngine, an amazing AI native game engine.

Introducing Neural Dawn. 📱
Developed by Arm and Sumo Digital, Neural Dawn is a new project to deliver a production quality game, showcasing the capabilities of Arm Neural Technology in next-generation Arm Mali GPUs coming to Arm CSS for mobile later this year.
The first mobile game to use @UnrealEngine MegaLights. okt.to/xIagWr
1
4
18
1,535
May 6
Can’t directly speak about LA, but SF is on a rebound. latimes.com/california/story…
6
3
8
3,900
Drew Henry retweeted

Today we’re announcing a new partnership with @Arm to collaborate on the development of multiple generations of purpose-built CPUs to support our compute and AI infrastructure.
The first generation of the chip that we co-developed, the Arm AGI CPU, delivers more than 2x performance per rack compared with x86 platforms. The Arm AGI CPU will also be available to the broader AI ecosystem through Arm and Meta will be releasing our board and rack designs for this CPU under the Open Compute Project later this year.
Learn more about our partnership: go.meta.me/15e3b8

40
130
1,081
83,997
Mar 24
Today is one of those days that you never forget in your career. Our first Arm SOC product built for the AI generation. The team at Arm has built something great. I’m so proud.
A new era for the Arm compute platform begins; we're making silicon. Introducing the Arm AGI CPU.
Designed for a new class of agentic workloads in the data center, the Arm AGI CPU delivers leading performance per rack with the scale and efficiency to match.
This marks a new phase for Arm. Now partners can choose IP, Arm Compute Subsystems or production silicon to accelerate AI-driven infrastructure.
#ArmEverywhere okt.to/QGBJgb

2
14
600

A new era for the Arm compute platform begins; we're making silicon. Introducing the Arm AGI CPU.
Designed for a new class of agentic workloads in the data center, the Arm AGI CPU delivers leading performance per rack with the scale and efficiency to match.
This marks a new phase for Arm. Now partners can choose IP, Arm Compute Subsystems or production silicon to accelerate AI-driven infrastructure.
#ArmEverywhere okt.to/QGBJgb
11
147
633
53,970
A defining moment for AI compute.
See how collaboration across hardware, software, and systems is enabling better computing platforms for everyone.
🎥 Join the livestream | March 24 okt.to/o9ArRc
#ArmEverywhere

8
37
1,712
Feb 26
This was fun! The team @TensorAuto built something that is a true engineering marvel! I love my job!
Watch @drewhenry (EVP, Physical AI, Arm) and Dr. Jewel Li (COO, Tensor) get up close with the Tensor Robocar and take it for a drive. 👀🚗
Today, we announced a multi-year collaboration with @TensorAuto to deliver the foundational compute platform behind the world's first personal AI robocar. Each vehicle features 433 Arm-based cores, helping to distribute safety-capable intelligence across the car.
okt.to/RT790G
2
2
11
2,115
Drew Henry retweeted

Feb 23
We built maps for people. Now, we’re building a new kind of map for robotics and AI. 🤖📍
Niantic Spatial CEO @JohnHanke shares why this foundation will be as essential to the future of AI as digital maps were for the web.
80% of the global economy operates in the physical world. For AI to truly scale, it must move beyond chatbots and synthetic worlds. It needs to navigate, understand, and safely interact with our reality.
Read more: hubs.ly/Q0447MBx0
#PhysicalAI #SpatialIntelligence #NianticSpatial
12
44
256
82,861
Feb 23
Two absolutely amazing games and accomplishments!


3
177
Jan 17
Algorithms will be as key as SOC design. This is an excellent write up.

BREAKING 🚨 TESLA HAS PATENTED A "MATHEMATICAL CHEAT CODE" THAT FORCES CHEAP 8-BIT CHIPS TO RUN ELITE 32-BIT AI MODELS AND REWRITES THE RULES OF SILICON 🐳
How does a Tesla remember a stop sign it hasn’t seen for 30 seconds, or a humanoid robot maintain perfect balance while carrying a heavy, shifting box?
It comes down to Rotary Positional Encoding (RoPE)—the "GPS of the mind" that allows AI to understand its place in space and time by assigning a unique rotational angle to every piece of data.
Usually, this math is a hardware killer. To keep these angles from "drifting" into chaos, you need power-hungry, high-heat 32-bit processors (chips that calculate with extreme decimal-point precision).
But Tesla has engineered a way to cheat the laws of physics. Freshly revealed in patent US20260017019A1, Tesla’s "MIXED-PRECISION BRIDGE" is a mathematical translator that allows inexpensive, power-sipping 8-bit hardware (which usually handles only simple, rounded numbers) to perform elite 32-bit rotations without dropping a single coordinate.
This breakthrough is the secret "Silicon Bridge" that gives Optimus and FSD high-end intelligence without sacrificing a mile of range or melting their internal circuits. It effectively turns Tesla’s efficient "budget" hardware into a high-fidelity supercomputer on wheels.
📉 The problem: the high cost of precision
In the world of self-driving cars and humanoid robots, we are constantly fighting a war between precision and power. Modern AI models like Transformers rely on RoPE to help the AI understand where objects are in a sequence or a 3D space.
The catch is that these trigonometric functions (sines and cosines) usually require 32-bit floating-point math—imagine trying to calculate a flight path using 10 decimal places of accuracy.
If you try to cram that into the standard 8-bit multipliers (INT8) used for speed (which is like rounding everything to the nearest whole number), the errors pile up fast. The car effectively goes blind to fine details.
For a robot like Optimus, a tiny math error means losing its balance or miscalculating the distance to a fragile object. To bridge this gap without simply adding more expensive chips, Tesla had to fundamentally rethink how data travels through the silicon.
🛠️ Tesla's solution: the logarithmic shortcut & pre-computation
Tesla’s engineers realized they didn't need to force the whole pipeline to be high-precision. Instead, they designed the Mixed-Precision Bridge.
They take the crucial angles used for positioning and convert them into logarithms. Because the "dynamic range" of a logarithm is much smaller than the original number, it’s much easier to move that data through narrow 8-bit hardware without losing the "soul" of the information.
It’s a bit like dehydrating food for transport; it takes up less space and is easier to handle, but you can perfectly reconstitute it later.
Crucially, the patent reveals that the system doesn't calculate these logarithms on the fly every time. Instead, it retrieves pre-computed logarithmic values from a specialized "cheat sheet" (look-up storage) to save cycles.
By keeping the data in this "dehydrated" log-state, Tesla ensures that the precision doesn't "leak out" during the journey from the memory chips to the actual compute cores. However, keeping data in a log-state is only half the battle; the chip eventually needs to understand the real numbers again.
🏗️ The recovery architecture: rotation matrices & Horner’s method
When the 8-bit multiplier (the Multiplier-Accumulator or MAC) finishes its job, the data is still in a "dehydrated" logarithmic state. To bring it back to a real angle theta without a massive computational cost, Tesla’s high-precision ALU uses a Taylor-series expansion optimized via Horner’s Method.
This is a classic computer science trick where a complex equation (like an exponent) is broken down into a simple chain of multiplications and additions.
By running this in three specific stages—multiplying by constants like 1/3 and 1/2 at each step—Tesla can approximate the exact value of an angle with 32-bit accuracy while using a fraction of the clock cycles.
Once the angle is recovered, the high-precision logic generates a Rotation Matrix (a grid of sine and cosine values) that locks the data points into their correct 3D coordinates.
This computational efficiency is impressive, but Tesla didn't stop at just calculating faster; they also found a way to double the "highway speed" of the data itself.
🧩 The data concatenation: 8-bit inputs to 16-bit outputs
One of the most clever hardware "hacks" detailed in the patent is how Tesla manages to move 16-bit precision through an 8-bit bus. They use the MAC as a high-speed interleaver—effectively a "traffic cop" that merges two lanes of data.
It takes two 8-bit values (say, an X-coordinate and the first half of a logarithm) and multiplies one of them by a power of two to "left-shift" it.
This effectively glues them together into a single 16-bit word in the output register, allowing the low-precision domain to act as a high-speed packer for the high-precision ALU to "unpack".
This trick effectively doubles the bandwidth of the existing wiring on the chip without requiring a physical hardware redesign. With this high-speed data highway in place, the system can finally tackle one of the biggest challenges in autonomous AI: object permanence.
🧠 Long-context memory: remembering the stop sign
The ultimate goal of this high-precision math is to solve the "forgetting" problem. In previous versions of FSD, a car might see a stop sign, but if a truck blocked its view for 5 seconds, it might "forget" the sign existed.
Tesla uses a "long-context" window, allowing the AI to look back at data from 30 seconds ago or more.
However, as the "distance" in time increases, standard positional math usually drifts. Tesla's mixed-precision pipeline fixes this by maintaining high positional resolution, ensuring the AI knows exactly where that occluded stop sign is even after a long period of movement.
The RoPE rotations are so precise that the sign stays "pinned" to its 3D coordinate in the car's mental map. But remembering 30 seconds of high-fidelity video creates a massive storage bottleneck.
⚡ KV-cache optimization & paged attention: scaling memory
To make these 30-second memories usable in real-time without running out of RAM, Tesla optimizes the KV-cache (Key-Value Cache)—the AI's "working memory" scratchpad.
Tesla’s hardware handles this by storing the logarithm of the positions directly in the cache. This reduces the memory footprint by 50% or more, allowing Tesla to store twice as much "history" (up to 128k tokens) in the same amount of RAM.
Furthermore, Tesla utilizes Paged Attention—a trick borrowed from operating systems. Instead of reserving one massive, continuous block of memory (which is inefficient), it breaks memory into small "pages".
This allows the AI5 chip to dynamically allocate space only where it's needed, drastically increasing the number of objects (pedestrians, cars, signs) the car can track simultaneously without the system lagging.
Yet, even with infinite storage efficiency, the AI's attention mechanism has a flaw: it tends to crash when pushed beyond its training limits.
🔒 Pipeline integrity: the "read-only" safety lock
A subtle but critical detail in the patent is how Tesla protects this data. Once the transformed coordinates are generated, they are stored in a specific location that is read-accessible to downstream components but not write-accessible by them.
Furthermore, the high-precision ALU itself cannot read back from this location.
This one-way "airlock" prevents the system from accidentally overwriting its own past memories or creating feedback loops that could cause the AI to hallucinate. It ensures that the "truth" of the car's position flows in only one direction: forward, toward the decision-making engine.
🌀 Attention sinks: preventing memory overflow
Even with a lean KV-cache, a robot operating for hours can't remember everything forever. Tesla manages this using Attention Sink tokens.
Transformers tend to dump "excess" attention math onto the very first tokens of a sequence, so if Tesla simply used a "sliding window" that deleted old memories, the AI would lose these "sink" tokens and its brain would effectively crash.
Tesla's hardware is designed to "pin" these attention sinks permanently in the KV-cache. By keeping these mathematical anchors stable while the rest of the memory window slides forward, Tesla prevents the robot’s neural network from destabilizing during long, multi-hour work shifts.
While attention sinks stabilize the "memory", the "compute" side has its own inefficiencies—specifically, wasting power on empty space.
🌫️ Sparse tensors: cutting the compute fat
Tesla’s custom silicon doesn't just cheat with precision; it cheats with volume. In the real world, most of what a car or robot sees is "empty" space (like clear sky).
In AI math, these are represented as "zeros" in a Sparse Tensor (a data structure that ignores empty space). Standard chips waste power multiplying all those zeros, but Tesla’s newest architecture incorporates Native Sparse Acceleration.
The hardware uses a "coordinate-based" system where it only stores the non-zero values and their specific locations. The chip can then skip the "dead space" entirely and focus only on the data that matters—the actual cars and obstacles.
This hardware-level sparsity support effectively doubles the throughput of the AI5 chip while significantly lowering the energy consumed per operation.
🔊 The audio edge: Log-Sum-Exp for sirens
Tesla’s "Silicon Bridge" isn't just for vision—it's also why your Tesla is becoming a world-class listener. To navigate safely, an autonomous vehicle needs to identify emergency sirens and the sound of nearby collisions using a Log-Mel Spectrogram approach (a visual "heat map" of sound frequencies).
The patent details a specific Log-Sum-Exp (LSE) approximation technique to handle this. By staying in the logarithm domain, the system can handle the massive "dynamic range" of sound—from a faint hum to a piercing fire truck—using only 8-bit hardware without "clipping" the loud sounds or losing the quiet ones.
This allows the car to "hear" and categorize environmental sounds with 32-bit clarity. Of course, all this high-tech hardware is only as good as the brain that runs on it, which is why Tesla's training process is just as specialized.
🎓 Quantization-aware training: pre-adapting the brain
Finally, to make sure this "Mixed-Precision Bridge" works flawlessly, Tesla uses Quantization-Aware Training (QAT).
Instead of training the AI in a perfect 32-bit world and then "shrinking" it later—which typically causes the AI to become "drunk" and inaccurate—Tesla trains the model from day one to expect 8-bit limitations.
They simulate the rounding errors and "noise" of the hardware during the training phase, creating a neural network that is "pre-hardened". It’s like a pilot training in a flight simulator that perfectly mimics a storm; when they actually hit the real weather in the real world, the AI doesn’t "drift" or become inaccurate because it was born in that environment.
This extreme optimization opens the door to running Tesla's AI on devices far smaller than a car.
🚀 The strategic roadmap: from AI5 to ubiquitous edge AI
This patent is not just a "nice-to-have" optimization; it is the mathematical prerequisite for Tesla’s entire hardware roadmap. Without this "Mixed-Precision Bridge", the thermal and power equations for next-generation autonomy simply do not work.
It starts by unlocking the AI5 chip, which is projected to be 40x more powerful than current hardware. Raw power is useless if memory bandwidth acts as a bottleneck.
By compressing 32-bit rotational data into dense, log-space 8-bit packets, this patent effectively quadruples the effective bandwidth, allowing the chip to utilize its massive matrix-compute arrays without stalling.
This efficiency is critical for the chip's "half-reticle" design, which reduces silicon size to maximize manufacturing yield while maintaining supercomputer-level throughput.
This efficiency is even more critical for Tesla Optimus, where it is a matter of operational survival. The robot runs on a 2.3 kWh battery (roughly 1/30th of a Model 3 pack).
Standard 32-bit GPU compute would drain this capacity in under 4 hours, consuming 500W just for "thinking".
By offloading complex RoPE math to this hybrid logic, Tesla slashes the compute power budget to under 100W. This solves the "thermal wall", ensuring the robot can maintain balance and awareness for a full 8-hour work shift without overheating.
This stability directly enables the shift to End-to-End Neural Networks. The "Rotation Matrix" correction described in the patent prevents the mathematical "drift" that usually plagues long-context tracking.
This ensures that a stop sign seen 30 seconds ago remains "pinned" to its correct 3D coordinate in the World Model, rather than floating away due to rounding errors.
Finally, baking this math into the silicon secures Tesla's strategic independence. It decouples the company from NVIDIA’s CUDA ecosystem and enables a Dual-Foundry Strategy with both Samsung and TSMC to mitigate supply chain risks.
This creates a deliberate "oversupply" of compute, potentially turning its idle fleet and unsold chips into a distributed inference cloud that rivals AWS in efficiency.
But the roadmap goes further. Because this mixed-precision architecture slashes power consumption by orders of magnitude, it creates a blueprint for "Tesla AI on everything".
It opens the door to porting world-class vision models to hardware as small as a smart home hub or smartphone. This would allow tiny, cool-running chips to calculate 3D spatial positioning with zero latency—bringing supercomputer-level intelligence to the edge without ever sending private data to a massive cloud server.

1
323
Jan 9
Humanoids would be boring if they just did things humans can already do. CES 2026 was cool. Expect even cooler @Arm based robots showing up throughout this year.
🤖 Humanoids are about expanding what’s possible — with trust, safety, and responsible autonomy.
▶️ At #CES2026, @DrewHenry shares why power-efficiency and the world's largest software ecosystem make Arm the first-choice platform for scaling these new-forms of autonomous systems.
1
4
237
Jan 7
True
Day 2 of #CES2026 is well underway!
Across the show floor, much of what you’re seeing, touching, and experiencing is already built on Arm—powering devices and systems behind countless technology demos and products.
At our booth, we're showcasing a snapshot of some of the biggest innovations built on Arm. Let us know what you spot, or come early to explore if you’re meeting with us.



1
117
Across the #CES2026 show floor, physical AI is taking shape in machines, robots, and cars.
🎥 @drewhenry explains why it’s happening on Arm — decades of innovation in power-efficient compute, supported by a deeply established software ecosystem to build and scale what’s next.
2
6
44
2,698
Jan 6
Hey @huggingface & @pollenrobotics very well done! My daughter (who’s doing a masters related to robotics) and I built a Reachy Mini over the holiday. The brain is @Arm based! With all the amazing Arm based robots being announced at CES it’s great that dev platforms are also available!


4
7
66
15,302
Jan 6
97% of my driving now is FSD with @Tesla v14.2 in my Model X. I’ve just about used every gen from the start. Started off in early gens with what my wife called at times, “Mr Toad’s Wild Ride”. Now feels like I have a professional driver chauffeuring me. Love working with these guys.
1
151
Jan 1
Congrats to everyone @Tesla who helped architect and design FSD. This is a historic milestone!
31 Dec 2025

I am proud to announce that I have successfully completed the world’s first USA coast to coast fully autonomous drive!
I left the Tesla Diner in Los Angeles 2 days & 20 hours ago, and now have ended in Myrtle Beach, SC (2,732.4 miles)
This was accomplished with Tesla FSD V14.2 with absolutely 0 disengagements of any kind even for all parking including at Tesla Superchargers.

2
152
19 Dec 2025
TTM to app code on Day 1 for a new platform starts with a fully capable dev platform. Few realize how hard this is to make happen. @siemenssoftware and @arm do. That’s why we do things like this. Hard things take time.
@siemenssoftware launches PAVE360 Automotive, a system-level digital twin, integrating Arm Zena CSS to enable faster, day-one full-system development and earlier validation for ADAS, AD & IVI.
Congrats @Siemens 👏news.siemens.com/en-us/sieme…
92
19 Dec 2025
As a pilot you live or die by the fact that no one “raises to the occasion”, you fall to your level of training.
19 Dec 2025

🇺🇸 When the cable snapped, the pilot did not.
An E-2C Hawkeye came within seconds of disaster after an arresting cable failed during carrier landing. One of the most dangerous moments any naval aviator can face.
No panic. No hesitation.
The pilot pushed the throttles forward instantly and fought the aircraft away from the sea, clearing the water by just meters.
Training took over. Skill decided the outcome.
This is why carrier aviation remains one of the hardest jobs in the world.
1
110
13 Dec 2025
Spent the week doing deep dives into new computing architectures for physical ai. Just in time for the holidays!
1
48