
Joined September 2016
- Tweets 20,737
- Following 543
- Followers 21,111
- Likes 49,093
2,605 Photos and videos









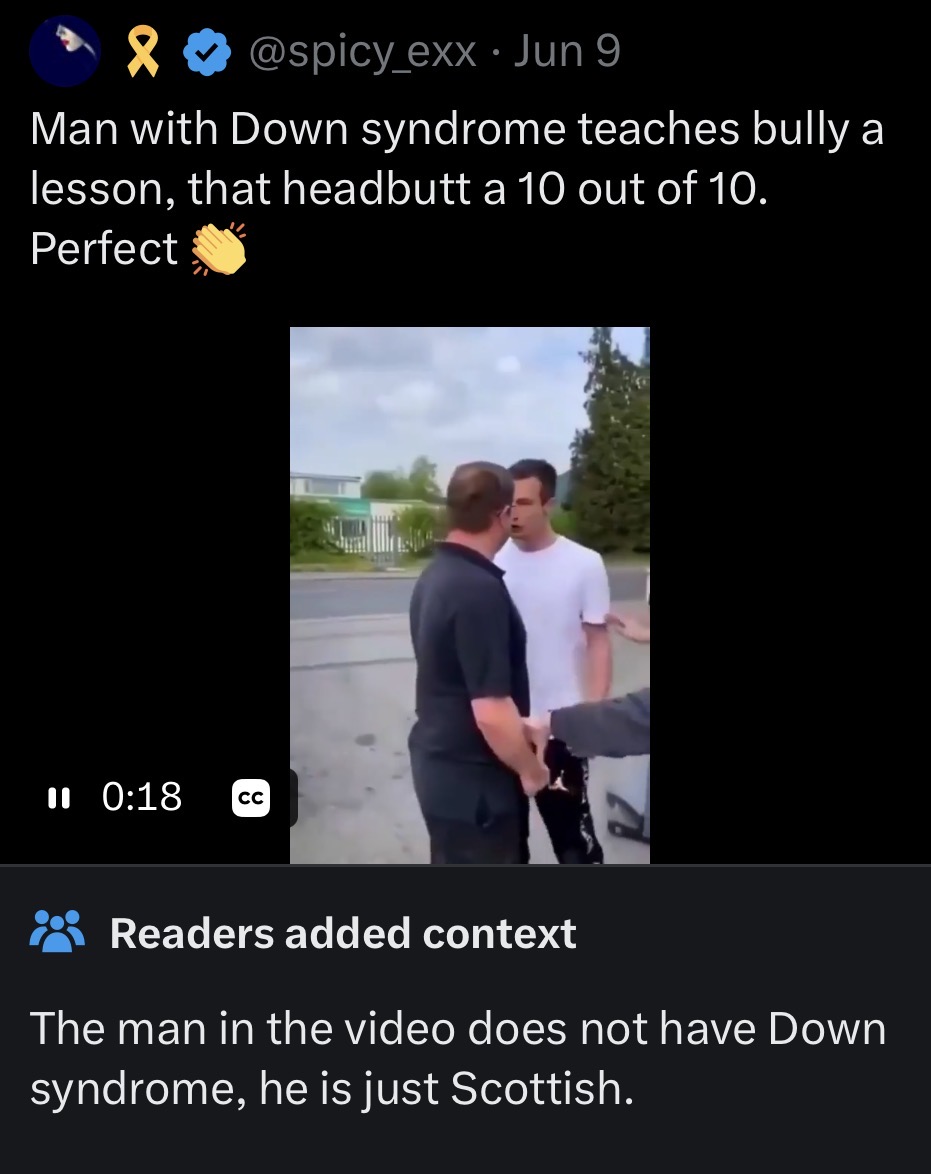

Pinned Tweet

25 Nov 2023
This tweet is about how I have studied ML and made it my profession. I'll share the resources I've used and the sequence of my study.
Straight to point
ML pre-requisites(maths) : Linear Algebra, Probability Theory, Calculus, Optimization Theory(optional), Information theory(optional)
Linear Algebra: Lecture course by Gilbert Strang
Probability theory: MIT 6.041 (it contains parts of Bayesian inference as well)
Calculus: your high school and college classes are enough
Once basic maths is done then we move to ML.
Classical ML : CS229. Either by Andrew NG or someone else. Follow their lecture notes and solve their problem sets.
Reference books for classical ML that I followed: PRML by Christopher bishop, Pattern Classification by Duda, Hart and Stork
After getting comfortable with classical ML we move to Deep Learning and everything else.
Deep Learning and Computer Vision: CS231n. Very good lecture and assignments
Reference book: Deep Learning by Ian Goodfellow. This is the best book on deep learning. I’ve read some chapters of it many many times. Beautiful maths and intuitions
MLOps: dvc, WandB, MLFlow
NLP: I just read hugging face blogs. I haven’t spent much time with classical NLP though.
Alignment/AI safety/AI explainability: Anthropic Blogs(I’m a noob in this, just started learning couple months ago)
Additionally:
Blogs: Lilian Weng(OpenAI)’s blogs, colah’s blogs
Additionally: arxiv. I read many papers from arxiv
Karas and Tensorflow blogs: for introductory code about modern deep learning frameworks
Competitions: Kaggle
Cloud compute. GCP/collab/Kaggle notebooks
PS: this is not a roadmap. Just what I followed till now and I find it quite structured. Even after 5 years I still find myself learning new stuff everyday.
81
567
4,090
681,235
Saurabh Kumar retweeted
Jun 12
If you're building LLMs on @Apple silicon, this is a gold mine
1
2
31
576
Saurabh Kumar retweeted
We are deadass sitting on a gold mine.
Qwen 3.6 comes with MTP, so no external draft model is needed for multi token rpediction unlike normal speculative decoding.
23
601
Building a general purpose harness is impossible given every model being trained on different rewards
What you can aim for is a continuously evolving meta system that adjusts your harness as you do tasks while observing where the model and tools lack
3
59
Last year I got a health checkup in Japan. To my surprise, the medicine I got from the Japanese pharmacy was made in India.
Even after my health insurance, the medicine cost me 4 times as much as it would have cost me back in India if I just bought it from a pharmacy
And the Japanese doctor told me how good and effective the medicines made in India are.
India is a pharmacy giant.

US woman calls American healthcare system a “scam” after buying a $1,000 medication from India for just $25


2
3
117
5,266
Saurabh Kumar retweeted
The Crunchyroll translation of "Smoking Behind the Supermarket with You" is done by the famous Indian translator Sriram Gurunathan
1
3
58
1,329
Saurabh Kumar retweeted

Apr 1
Today we drop Trinity-Large-Thinking.
SOTA on Tau2-Airline, frontier-class on Tau2-Telecom, and the #2 model on PinchBench, right behind Opus. On BCFLv4, we're in the mix with the best.
26 people with under $50M raised and a ruthless pursuit of greatness.
What this team just pulled off is nothing short of incredible. One hell of an accomplishment and I couldn't be more proud of Arcee.
And we've got more to prove.

Today we're releasing Trinity-Large-Thinking.
Available now on the Arcee API, with open weights on Hugging Face under Apache 2.0.
We built it for developers and enterprises that want models they can inspect, post-train, host, distill, and own.
12
19
196
16,057
Saurabh Kumar retweeted

Jun 13
Scratch the surface, and the free-market enthusiast often turns out to be a socialist who wants tax payers to fund his pet idea.
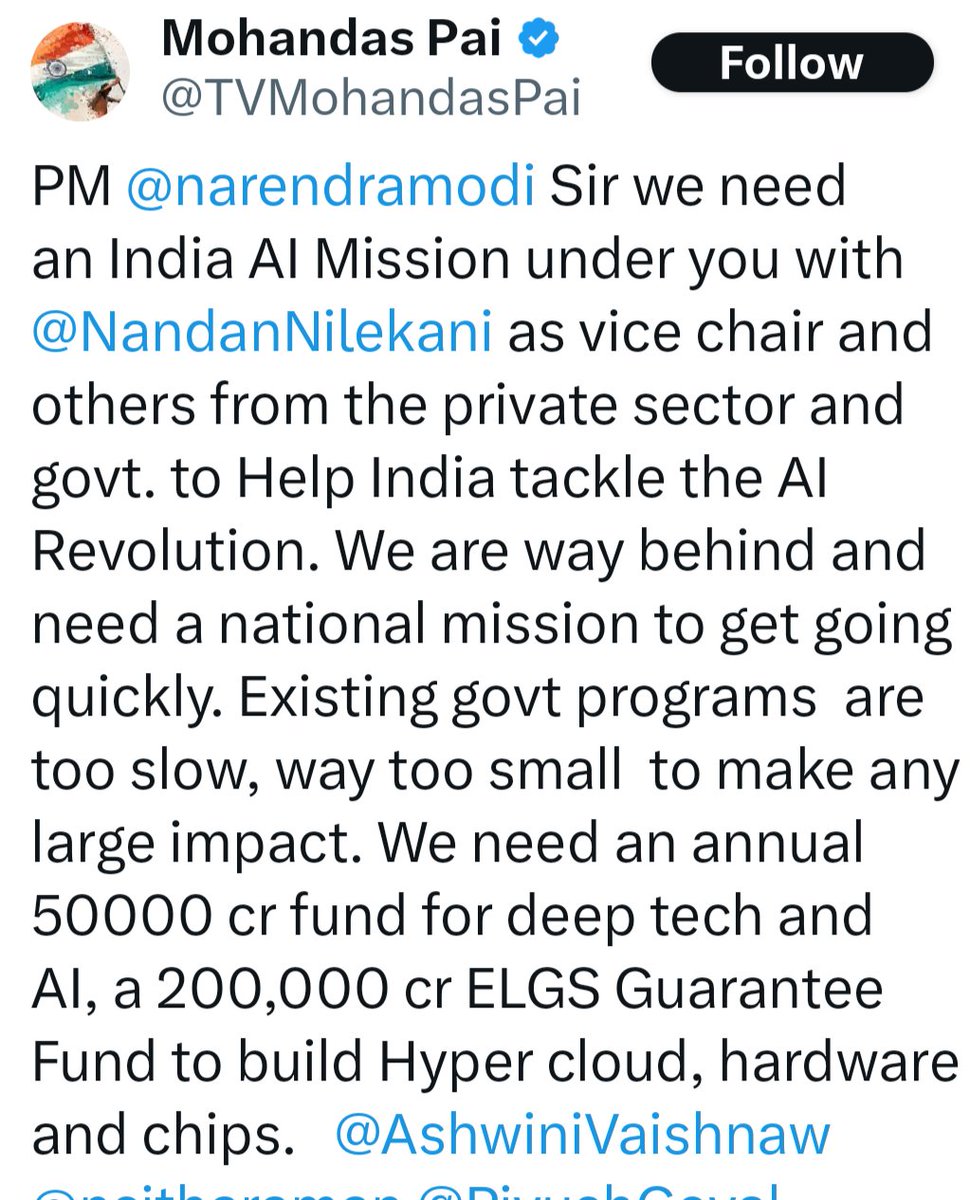
51
220
904
15,321
There are many ways in which India can win in AI
Talent density. We have lots of talented people, we just need less disturbance from external people and more support for the focused work, productive environment and good pay
Data. India generates huge amount of data. And US companies are taking full advantage of it. Whether it’s collecting cheap egocentric view for robotics or simple data labeling. There is definitely a cost arbitrage and we should take benefit of that as well. Data collection and labeling is a huge challenge and we can do it reliably and cheaply
Compute. We still lack compute but recent efforts by sarvam and other IIT labs have shown that with good funding and support we can reach the level of compute we need to run big experiments
Optimism. This is where we lack. From everyday opinions from people saying “it’s too late” or “it’s just post training nothing special like deepseek” to leaders saying we don’t need sovereign LLM(spoiler we do). We have to be optimistic on the work our people are doing. Policies should support that as well
7
5
39
1,318
Saurabh Kumar retweeted

Y’all not gonna believe how deeply Hinduism is rooted in one piece . In the latest chapters, Imu literally used “Om” en with Gyan Mudra, and the mural line, “God dances and leads the world to its end and brings a new dawn,” directly parallels Shiva ( Nataraja )


That's why One Piece is superior, you can take all notions of Hinduism out of it and it's the exact same.
13
115
1,075
27,514

Post-training an open weight model is the most efficient way to build sovereign AI.
We’ve seen it already with Cursor Composer.
If your country is trying to build LLM from scratch, that’s wasting your tax money.
LLM is all about dataset, and none of country has enough data as US/China.

Alibaba Qwen3.7 slowly fading into irrelevance at the frontier due to proprietary stance.
In it's place we have Minimax M3 and... *checks notes* Rio 3.5 397b, made by the municipal IT company of Rio de Janeiro's city government.
huggingface.co/prefeitura-ri…

27
31
376
28,795
80.2 on SWE bench verified???
I’ll give it a shot today

SITUATION DETECTED: The city of Rio de Janerio has post-trained a model.
Based on Qwen 7/2, Rio 3.5 Open 397B adds SwiReasoning on top of the base Qwen model — a framework that dynamically switches between standard chain-of-thought and latent-space reasoning, guided by entropy-based confidence signals, so the model only "thinks out loud" when it needs to and otherwise reasons silently in hidden space for better token efficiency.
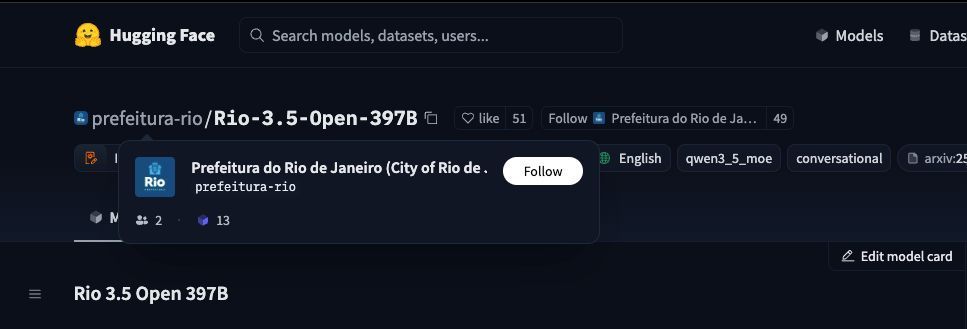
21
723
Saurabh Kumar retweeted

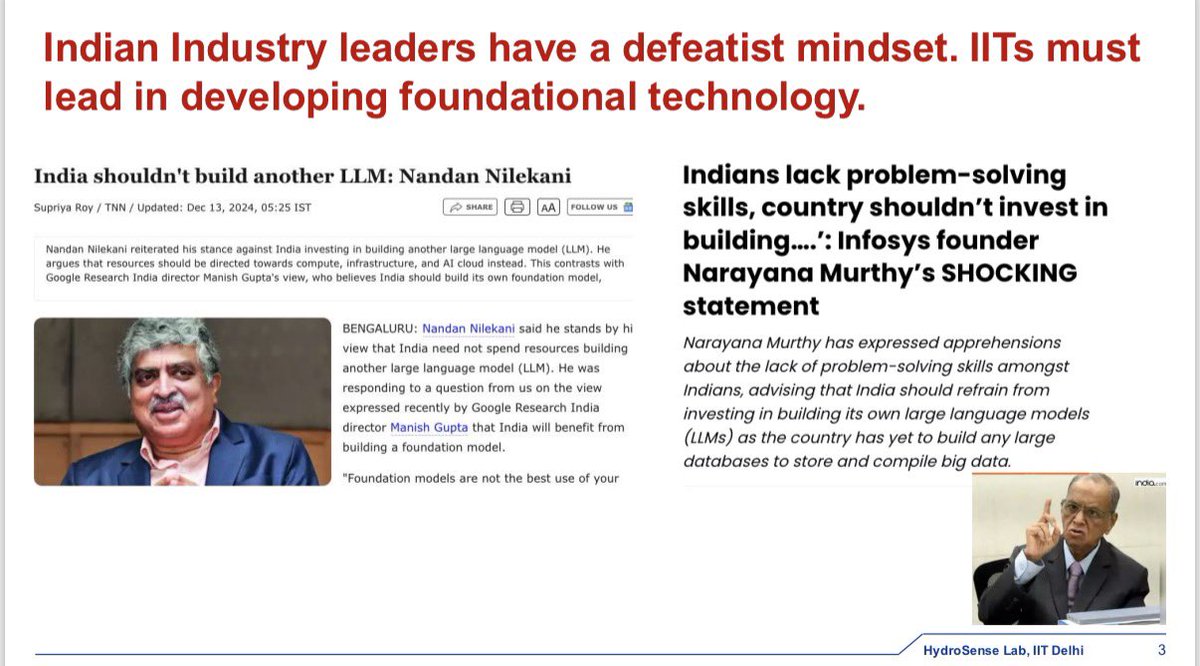
Indians are blaming Infy/Murthy/Nandan for a lack of home-grown LLM. But that blame is misplaced. Infy/Murthy/Nandan could never start an AI company. They had money and they could have fund something. But that again, is their money and why should they risk it?
The real culprit here is Amitabh Kant and other IAS like him. These are the people, why I left India and started two companies in the US. These are the people, why much of Indian talent left to work for US based companies. And these folks did well.
Let's say the government gives me $10B and ask me to set up an AI lab in India. Am I qualified to do it? YES. Will I do it? HELL NO
And you would ask why? Some would say that I have a cozy life in the US. Some would say, I have deep connection in the US, including family. All of that is correct but does not pin point the reason why I wont start a company in India.
The real reason is Babu. Unlike, many In India who think competing for 1000 seats using some bullshit essay writing contest makes Babu some wizard, I have not come across one, I will hire as an analyst. Under no circumstance, I am gonna report to a babu (Happy report to Dharmendra Pradhan or Smriti Irani though). Also, under no circumstances, I will accept a position where I am unable to fire and put an IAS in jail if they reported to me and indulged in some corruption.
Till this babu problem is fixed, no NRI would come to India. If I were the CIA or CCP, trying to ensure that India does not gain AI independence, I would make every effort to protect Babu fiefdom.
423
1,052
5,076
265,829
Saurabh Kumar retweeted

13h
Wait what? Rio 3.5 Open 397B, developed by IT company of Rio de Janeiro's city government is now SOTA open source and even outperforming Qwen 3.7?
What is happening today.
Never heard of them before.

Alibaba Qwen3.7 slowly fading into irrelevance at the frontier due to proprietary stance.
In it's place we have Minimax M3 and... *checks notes* Rio 3.5 397b, made by the municipal IT company of Rio de Janeiro's city government.
huggingface.co/prefeitura-ri…
139
281
4,048
360,095
Saurabh Kumar retweeted

SITUATION DETECTED: The city of Rio de Janerio has post-trained a model.
Based on Qwen 7/2, Rio 3.5 Open 397B adds SwiReasoning on top of the base Qwen model — a framework that dynamically switches between standard chain-of-thought and latent-space reasoning, guided by entropy-based confidence signals, so the model only "thinks out loud" when it needs to and otherwise reasons silently in hidden space for better token efficiency.
70
193
2,455
278,025
Saurabh Kumar retweeted

Apr 29
Last year, I was presenting to an internal team we had put together to develop a SOTA geospatial foundation model and this was a slide from that ppt. We have the talent and ambition, but the only entities that have helped us throughout this journey is govt IndiaAI mission and NVIDIA, who gave us priority compute after seeing our initial results. This is the kind of support that should have come from Indian IT behemoths. A country that can develop nuclear weapons and land on the moon is very well capable of developing SOTA models. But for that, we must first dream to be more than AI coolies.

Apr 29

India doesn't need to lead the world in building the most advanced AI models. But it must lead in ensuring benefits of AI are widely shared.
@rvenk and I have an op-ed in The @EconomicTimes
economictimes.indiatimes.com…
17
111
401
42,561
Saurabh Kumar retweeted
Govt has been incredibly supportive of our AI efforts through the IndiaAI Mission and other schemes. Zero support from any Indian industry. Thanks to NVIDIA, we trained India's first Geospatial Foundation Model (think of it like ChatGPT for satellite data) SLM using ISRO data. Dropping soon!
Apr 29

Last year, I was presenting to an internal team we had put together to develop a SOTA geospatial foundation model and this was a slide from that ppt. We have the talent and ambition, but the only entities that have helped us throughout this journey is govt IndiaAI mission and NVIDIA, who gave us priority compute after seeing our initial results. This is the kind of support that should have come from Indian IT behemoths. A country that can develop nuclear weapons and land on the moon is very well capable of developing SOTA models. But for that, we must first dream to be more than AI coolies.
16
171
753
30,431
Saurabh Kumar retweeted
12 Aug 2024
Don't settle for mediocrity. If you're going to do something, go all in.
Focus intensely on a topic, field, or skill for a good stretch of time—whether that's six months or a year. Commit fully and don't stop until you're genuinely satisfied with what you've achieved.
Don’t stop and don’t distract yourself with anything else.
Push yourself to the point where you can confidently say, "This is the best I could have done."
Then, look at the results. You'll be amazed to discover that what you lacked wasn't intelligence or resources, but persistence.
This isn’t about DSA or CP or ML or development, arts, or sports. It applies to everything.
At least once in your life, experience this phase. Once you do, you'll realize you can accomplish anything.
14
152
1,105
130,378
Saurabh Kumar retweeted

Kimi 2.7 ranked 2nd after Fable 5 and before GPT-5 xhigh
We have re-run our ErdosBench smoke test on 14 problems with Kimi 2.7, Qwen 3.7 Max, Grok 4.3 and compared it with the top performers from previous runs.
Kimi 2.7 is amazingly good. More below.

110
298
3,050
575,771
yess!!
Jun 13

run local models TODAY
2
21
923