
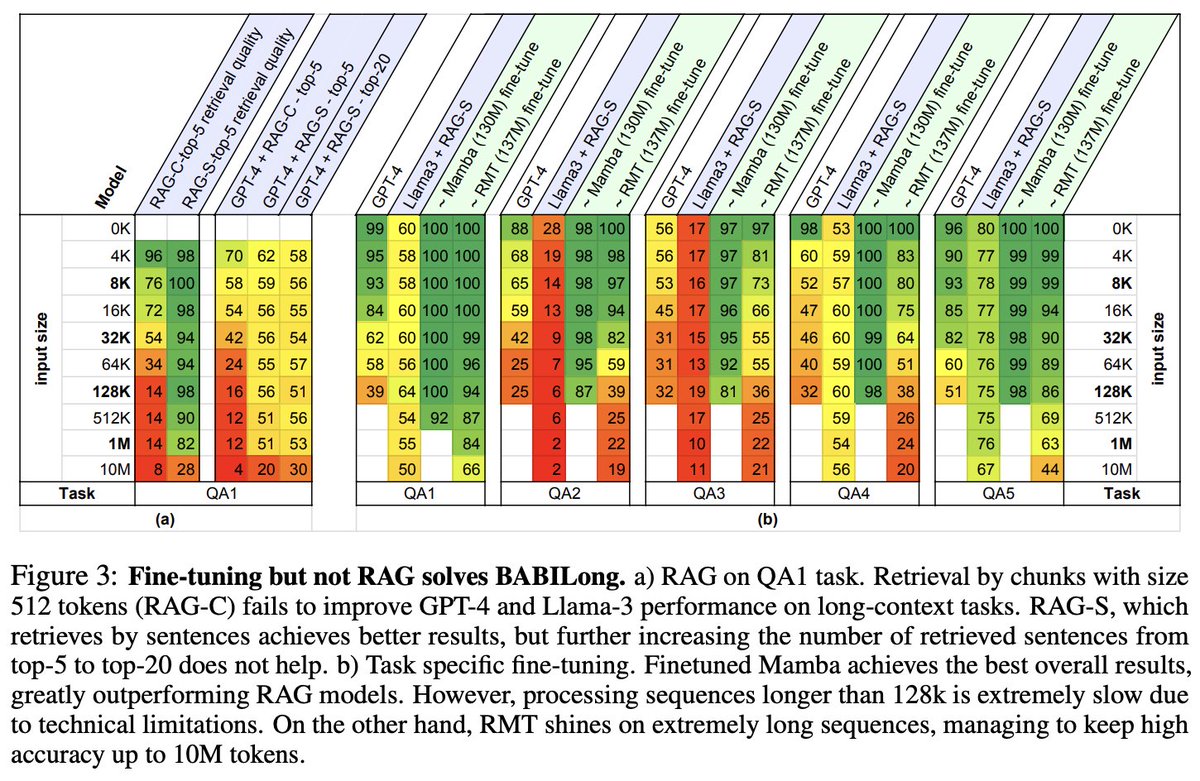
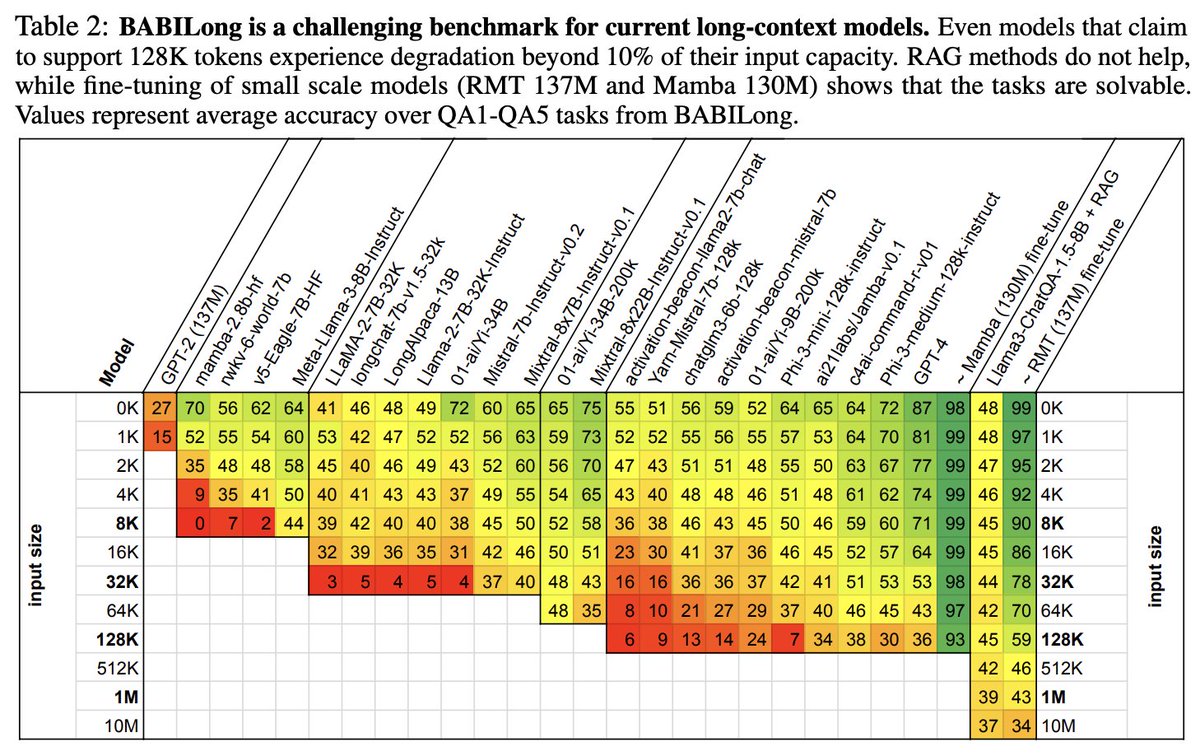
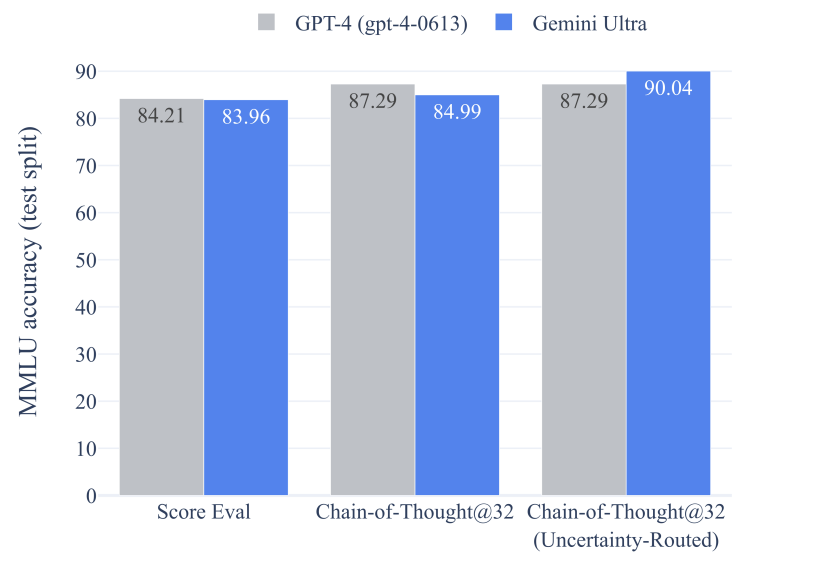
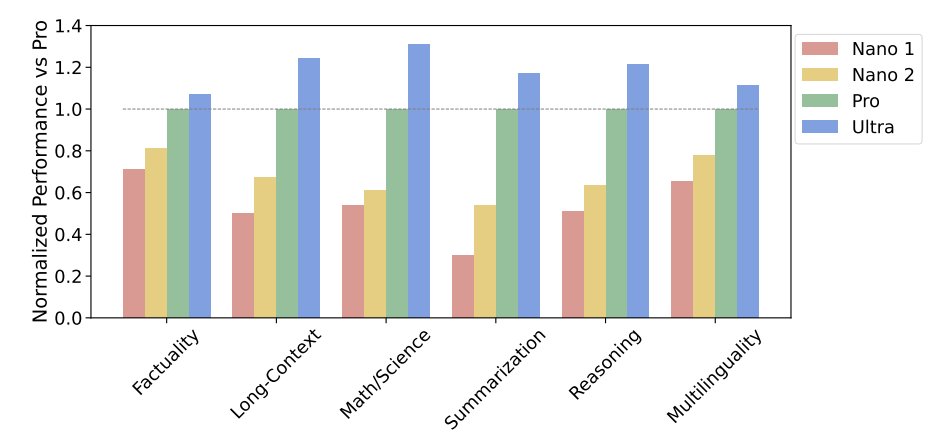
16 Photos and videos





Dhruv Singh retweeted

Jun 12
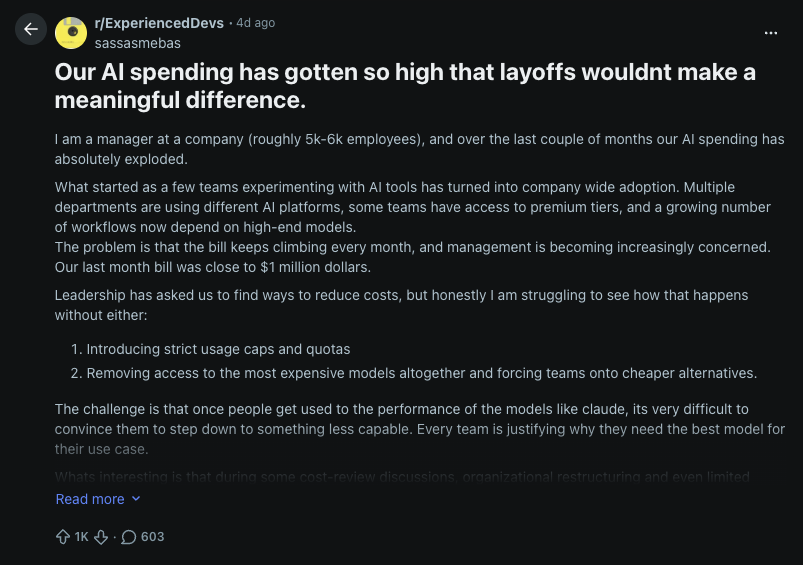
finance teams watching devs use fable to center a div

3
4
76
Dhruv Singh retweeted

Jun 8
/teach is live
Learn anything, from rubik's cube to vocal harmonies to software fundamentals.
npx skills add mattpocock/skills --skill teach
Best skill I've ever built, video coming soon
github.com/mattpocock/skills…
79
179
2,861
159,496
Dhruv Singh retweeted

Jun 8
on a related note, stoked to read gwern is (as usual) asking the best questions and possibly doing some very cool stuff
gwern.net/guardian-angel
2
5
290
Dhruv Singh retweeted

Jun 8
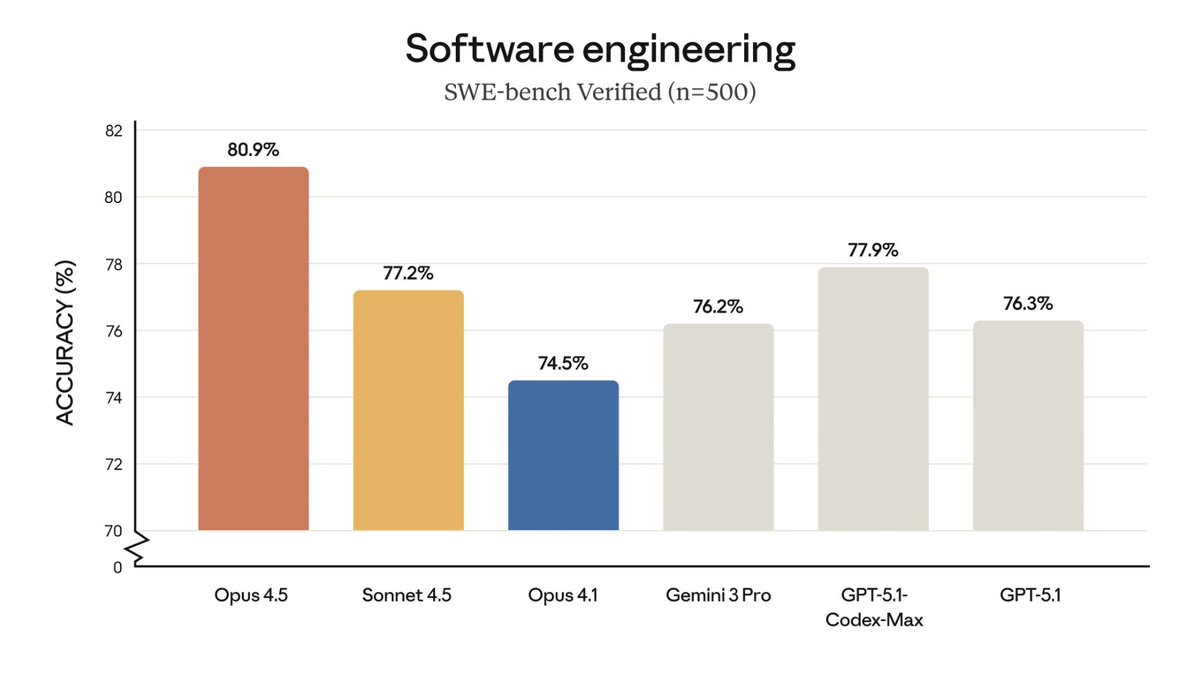
Introducing FrontierCode: a coding eval that raises the bar for difficulty & quality. Each task took 40 hrs of work by leading open-source maintainers.
Models write sloppy code that works but isn’t maintainable. Our eval is first to measure: would you actually merge this code?

234
313
4,284
2,507,752
Dhruv Singh retweeted

Jun 7
Here’s your monthly reminder that you shouldn’t be prompting coding agents anymore.
You should be designing loops that prompt your agents.
1,785
1,368
19,557
8,291,842

Jun 4
Many such cases. Most teams running coding agents at scale operate without visibility into the ROI of their token burn:
No view into which teams are spending budget on net-new features versus recurring bug classes.
No view into how much code had to be reverted before a working solution shipped.
No view into which workflows justify their token cost, or which agents are executing unaudited shell commands against production repositories.
HoneyHive for Coding Agents closes this visibility gap. Available today for Claude Code and Devin.
What our Coding Agents integration gets you:
𝗙𝘂𝗹𝗹 𝘀𝗲𝘀𝘀𝗶𝗼𝗻 𝘃𝗶𝘀𝗶𝗯𝗶𝗹𝗶𝘁𝘆. Every Claude Code or Devin session is captured as a structured trace tree.
𝗦𝗽𝗲𝗻𝗱 𝗮𝘁𝘁𝗿𝗶𝗯𝘂𝘁𝗶𝗼𝗻. Token spend rolls up by team, repository, project, work type, and tool. Replace the invoice-only view with a breakdown of where the budget actually went and what work it produced.
𝗖𝘂𝘀𝘁𝗼𝗺 𝗥𝗢𝗜 𝗮𝗻𝗮𝗹𝘆𝘀𝗶𝘀. Rather than ship one fixed funnel, we built funnel definition on top of HoneyHive's user feedback API, which accepts arbitrary JSON on every session. Wire in the signals that matter to your org (Git events, CI/CD outcomes, reviewer verdicts, engineer ratings, implicit accept/discard signals, cost categories) and chart them alongside token usage, latency, and tool-use data.
𝗥𝗶𝘀𝗸 𝗮𝗻𝗱 𝘀𝗲𝗰𝘂𝗿𝗶𝘁𝘆 𝘃𝗶𝘀𝗶𝗯𝗶𝗹𝗶𝘁𝘆. The same trace data gives risk, security, and enterprise architecture teams visibility into agent behavior: which tools each agent is invoking, with what arguments, against which repositories; where agents are executing shell commands, calling external endpoints, or modifying files outside the working directory; which sessions warrant review under your security policies. The trace becomes the input layer for the verifiers and policies your security team builds on top of this data.
𝗘𝘃𝗮𝗹𝘀. The online and offline eval pipelines you already run on your LLM applications now extend to coding-agent sessions. Score for correctness, code quality, safety, policy adherence, or any custom dimension your team cares about.
Install the daemon and you'll have your first traces within a single session.
Read more: honeyhive.ai/post/honeyhive-…
6
9
258
Dhruv Singh retweeted
Jun 4
Today we're launching HoneyHive for Coding Agents: observability for Claude Code and Devin.
Comes with full session traces, usage and spend analysis, custom ROI funnels, and runtime evals for code quality and security.
This is why we built it 👇️
Most teams running coding agents at scale operate with two data points:
(1) a monthly invoice from coding agent platforms like Anthropic, Cognition, Cursor, OpenAI, GitHub Copilot, etc. and (2) anecdotal velocity feedback from engineers.
Everything between those two points is dark, so companies can't answer questions like:
→ Which teams are spending on net-new features vs. recurring bug classes?
→ How much code had to be reverted before a working solution shipped?
→ Which workflows justify their token cost and generate ROI?
Companies can see their invoices.
They can check GitHub and talk to their engineers.
But the ROI of each token is a mystery.
HoneyHive for Coding Agents closes this gap.
Instrument Claude Code and Devin today: honeyhive.ai/post/honeyhive-…
More integrations coming soon.

2
3
9
315
Dhruv Singh retweeted

May 26
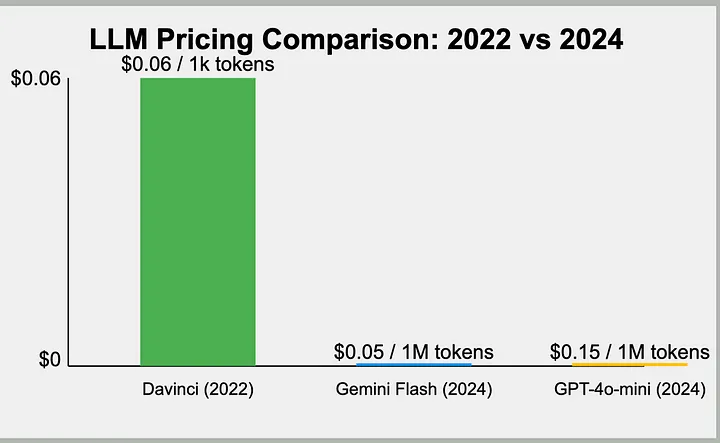
Pretty sure 50% of internal token spend is completely useless, but right now it's hard to know which 50%.
As an admin I'd love a dashboard that breaks down each person's spend into summarized clusters. Much easier to spend more when you can draw a clear line to value.

Uber’s COO has said that it’s getting “harder to justify” its AI costs because there was no way to show a link between AI spend and any meaningful increase in useful features. This is the first time I’ve seen a company say this directly.
businessinsider.com/uber-coo…


32
10
195
53,482
Dhruv Singh retweeted

2 Jul 2025
Excited to release a new starter! Sync-first, production-ready, and blazing fast
- @tan_stack Start
- @tan_stack DB for blazing fast client-side queries & optimistic mutations
- @ElectricSQL for real-time sync from PG
- @better_auth
- @DrizzleORM
- @tailwindcss
- Hono OpenAPI
20
38
454
64,948

METR's @ajeya_cotra says the best way to manage catastrophic AI risk is to set up a "sensible auditing regime that's technically literate," which involves auditors embedded in the frontier model providers.
"You don't want a box-checking auditor that has like 17 arbitrary things you're supposed to do."
"My best guess is that it's going to look like something that happens in the financial sector, where you have embedded auditors. Folks who are experts in finance, who sit and eat lunch with the employees, see all the books, know everything, and have a lot of flexibility to investigate what they need to."
"We're really hoping to move more and more in the embedded direction. Embedded auditing of the monitoring system, potentially even embedded auditing of training."
5
5
42
9,581

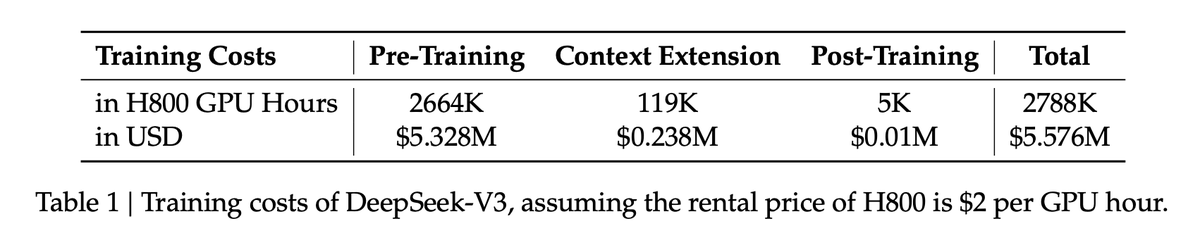
the year was 2024. you wanted to build an ai chatbot. you installed chroma db locally. you couldn’t figure out how to deploy it so you switched to pgvector. you read a paper on RAG. you spent $4.82 by calling an embedding api after realizing you couldn’t figure out how to get BAAI/bge-large-en-v1.5 working with your broken cuda packages. nvidia stock was overpriced at $90 you’re sure of it. you converted all your documents to embedding. you googled cosine similarity. you called the claude 3 sonnet model api and ran out of context after 8k tokens. you’re deep into reading langchain docs and confused. maybe something called llama index might work. it took four days to prototype but at least github copilot has killer autocomplete. your responses are shit but fortunately openai has a fine tuning api that will help. surely in a few weeks you’ll have something to show your boss, and the answers will be hallucination free. life is good.
42
53
1,115
68,157

Dhruv Singh retweeted
May 10
A flow I just tried and LOVED:
1. /grill-with-docs, talking about a new bit of UI
2. Asks me a question I can't answer unless I prototype
3. /prototype
4. Iterate on the prototype, burning tokens freely until we get a good spot
5. /rewind to the question, and select 'summarize' (Claude Code feature), saying 'summarize what we learned from prototyping'
6. Continue the grilling session, retaining the prototype
Smoooooooth
74
89
2,329
106,328
Dhruv Singh retweeted

May 17
stateful agents, decision traces, context graphs… talked about a lot, but has anyone seen an elegant primitive around how to actually implement?
65
4
148
18,991
Dhruv Singh retweeted

May 14
i'd watch a whole season of this

66
361
8,197
2,841,442
May 14
Evals are dead. Or more precisely:
traditional eval-driven development doesn’t scale.
Static evals were useful when agents were short-lived and bounded, but once agents are running for hours and taking thousands of actions operating autonomously, evals alone stop being enough.
At that point pass/fail is too coarse. Simulation misses too much of what happens in prod and model capabilities are moving faster than eval infra can keep up.
What we run instead: observability-driven development.
- deploy with tight guardrails
- collect prod trajectories
- cluster behavior to discover patterns failure modes
- specialize workers for narrower tasks
- tune thresholds until behavior is reliably within bounds
Can you see what your agents are doing? Can you detect drifts before they cause damage?
This is an important shift in how we build AI systems. Evals still matter but observability is becoming the foundation for prod-ready agents.
Thanks Sunny Bakhda (@honeyhiveai founding engineer) for a great talk at @aicouncilconf
7
8
90
6,761
Dhruv Singh retweeted

May 13
Q: What does it take to build and deploy LLM-powered applications?
A: The AI Engineering Track. Today!
Running Enterprise Agents in Production with @vasundra_s
Evals That Actually Work with @the_bunny_chen
Context Engineering with @simba_khadder
Managing Really Large Multimodel Datasets for AI with @changhiskhan
Pricing AI Agents with @kshithappens
Observability for Long-Running Agents with Sunny Bakhda.
Thanks for curating a great track, @ds3638!

1
2
204
Dhruv Singh retweeted

May 12
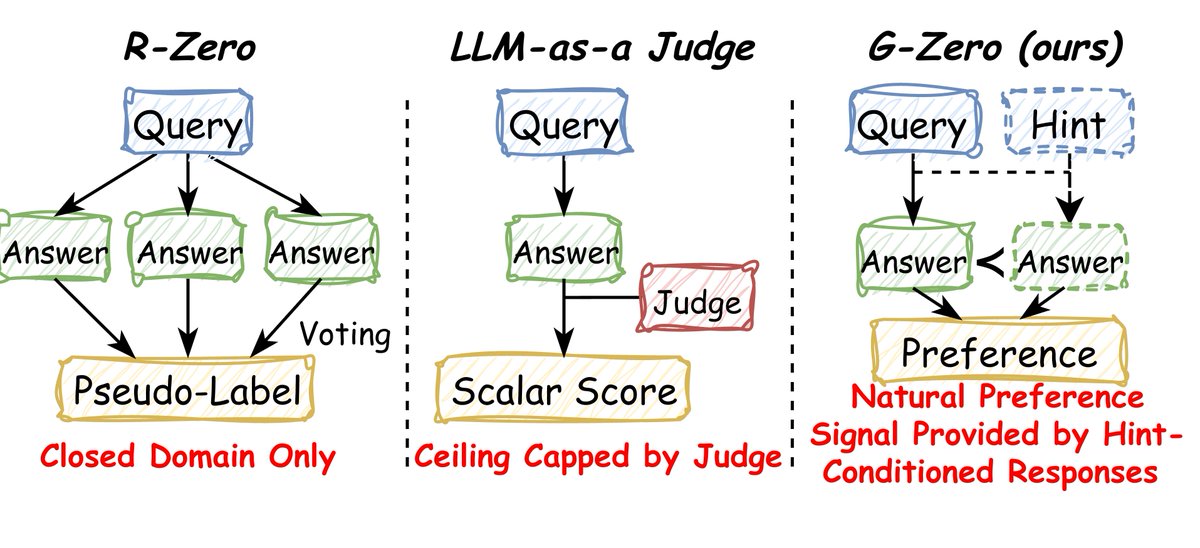
"How do you self-improve a model on open-ended tasks where you can't take a majority vote?"
I got asked this in nearly every research interview I did last year. None of my answers felt clean.
So we built something that doesn't need a vote, a verifier, or a judge.
Meet G-Zero. 👇
paper: arxiv.org/abs/2605.09959
huggingface: huggingface.co/papers/2605.0…
code: github.com/Chengsong-Huang/G…
All experiments are done via api by @thinkymachines (1/n)
6
45
239
15,015
Dhruv Singh retweeted

May 13
I appreciate the work by @EpochAIResearch @GregHBurnham in flagging and fixing these issues. Finding bugs in evaluations is always disappointing, but in the long run, is necessary (and extremely helpful) for improving evaluations. It also reminds me of the issues we uncovered in CORE-Bench: x.com/sayashk/status/1996334…
As benchmarks become more complex, analyzing benchmark tasks and agent logs will become more important to ensure the validity of evaluation results. Coincidentally, today we released a paper (led by @PKirgis) on how to do log analysis well. x.com/PKirgis/status/2054368…
This builds on all our lessons from the trenches in conducting such evaluations and fixing the issues we found in our own work.
I’m sure we’ll find many other issues in our evals, but genuinely think the evals community will be better off for having developed tools and methods to improve eval rigor.

May 13

Thread with a few notes on this. It’s a disappointing finding, of course. The best we can do is fix it up and learn lessons for future work.
2
5
44
13,252
