
Inventor of BioNFTs 🧬 ꧁BioIP꧂ acc/genomics 🧬 Agentic Precision Medicine
Joined August 2009
- Tweets 5,773
- Following 6,125
- Followers 2,629
- Likes 68,842
1,224 Photos and videos














Pinned Tweet

16 Nov 2025
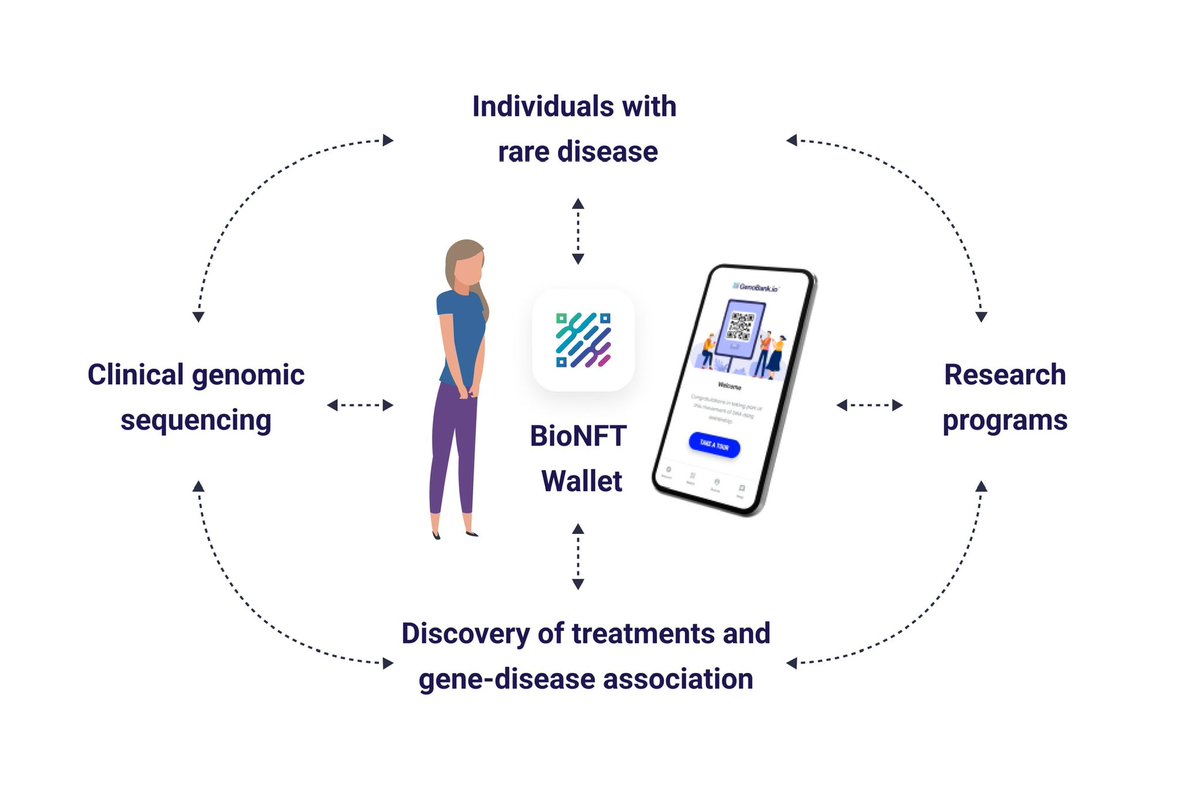
Proof of Consent over Human Biosamples 🧬 for AI Agents.
Agentic AIxBIO safeguarded by GenoBank.io's BioNFTs
1
3
526

A tech founder unleashed AI agents on his genome and got better medical advice than his doctors. Under $100. 345K people watched that post go viral. The moment is real, and we should celebrate it. But it raises a question nobody answered. 1/
2
1
87
When one founder does it, it's exciting. When millions do, who stores the genome after? Who trains on it? Can the patient revoke? If the company goes bankrupt, what happens? (Ask 23andMe's 15M customers.) 2/
1
53
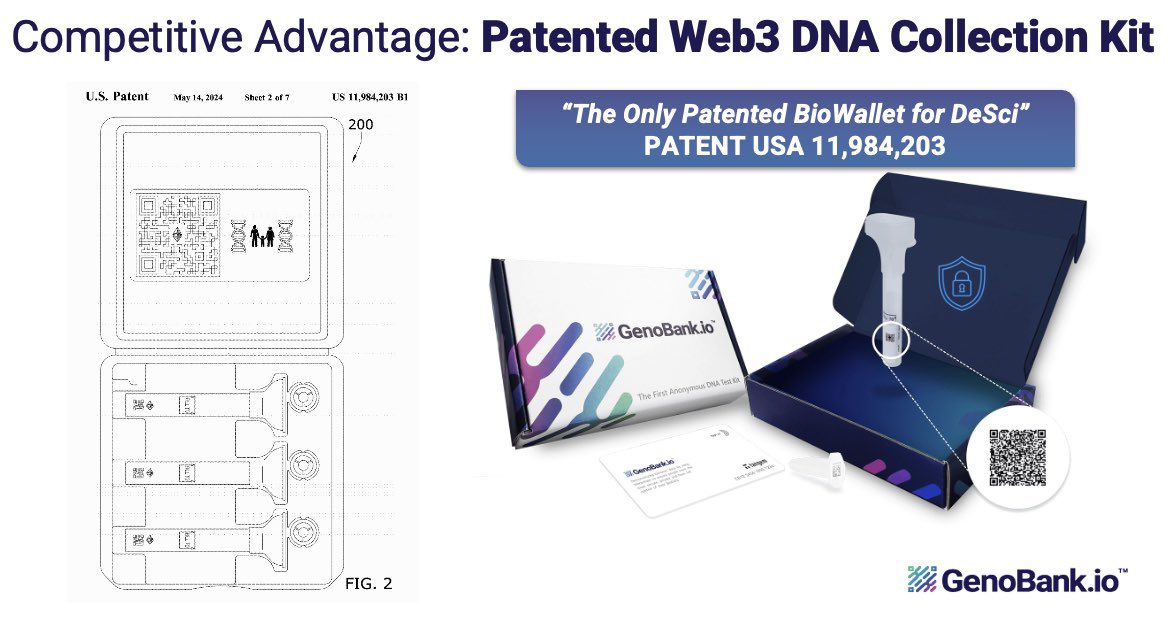
Our answer: lease your genome to the agent, don't lose it. A BioNFT sets the terms. The x402 biorouter gates every call. Consent first, payment second. Revoke anytime. 3/
genobank.io/blog/ai-agents-r…
1
56
A Stanford prof says AI biotech is putting parameters before data design. A builder says it's time for the SpaceX of biotech. A governance firm says the risk is poor governance, not AI. All three are right. And they're all missing one thing. 1/
1
62
Biotech AI needs your DNA to accelerate discoveries. We agree. At GenoBank.io we've always said patients should lease their genome to researchers. The question is whether you get to set the terms, or lose your data like 23andMe's 15 million customers. 2/
1
51
Our answer: a patient-owned BioNFT that makes the lease enforceable. Revocable consent, per-call x402 payment, Biodata Dividends. Consent first, money second. Lease your DNA, don't lose it. 3/
genobank.io/blog/full-stack-…
32
President Trump's new AI Executive Order (June 2026) is a smart move: pro-innovation, no mandatory model licensing, and real cybersecurity sent to rural hospitals. It secures the pipes around our most sensitive data. 1/
1
50
But it leaves one question open by design. Once an AI agent is inside an authorized hospital system, what governs how a patient grants, revokes, or is paid for the use of their own genome? Hardening the building doesn't answer that. 2/
1
45
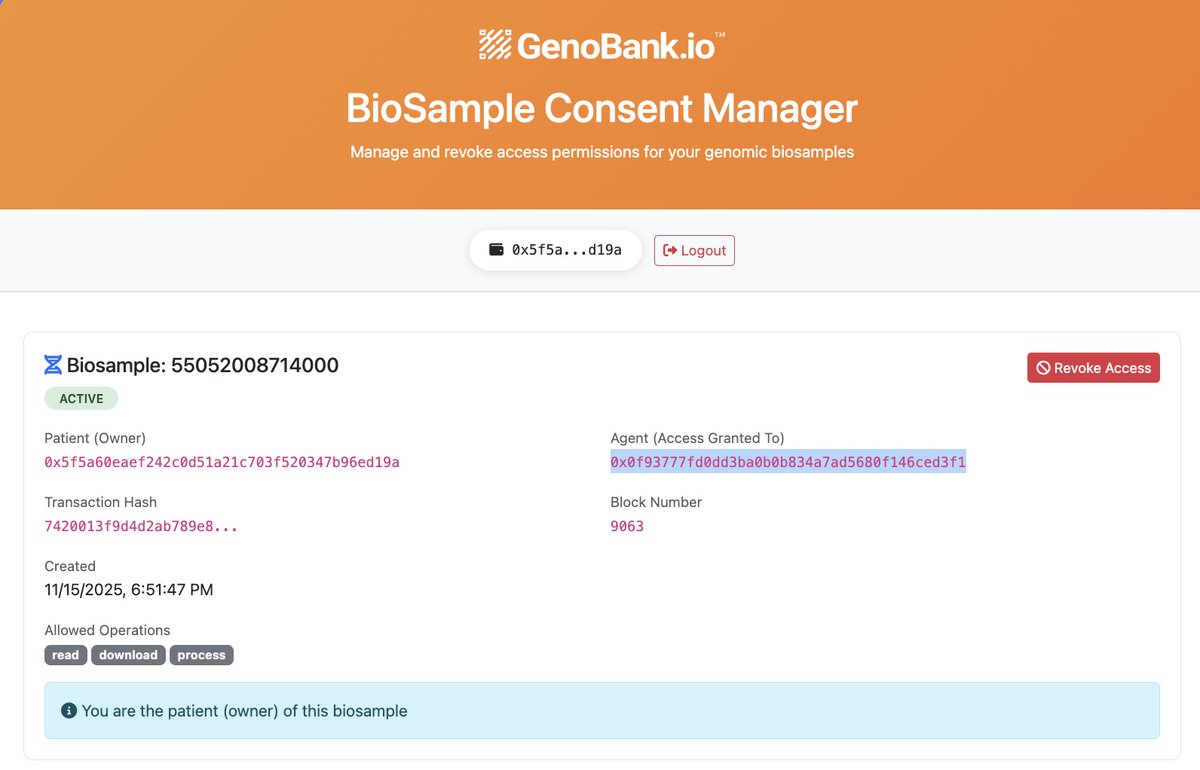
Our answer: a patient-owned BioNFT that imprints revocable HIPAA/GDPR consent into the data, enforced by the x402 biorouter. Non-consented AI use is blocked in code. AI privacy by code. 3/
genobank.io/blog/trump-ai-or…
22
This is exactly why every centralized entity managing Biosamples & Biodata should use a blockchain (BioNFT™️-gated) repository per patient to avoid this…
1
1
99


Watching the ecosystem of Story Protocol ( @StoryProtocol ) evolve, one of the most impressive things is how the scope of IP is far broader than many initially imagined.
At first it seemed mainly focused on turning digital creations such as content, creative works, or AI training data into IP assets. Over time it has become clearer that the potential expansion goes much further than that.
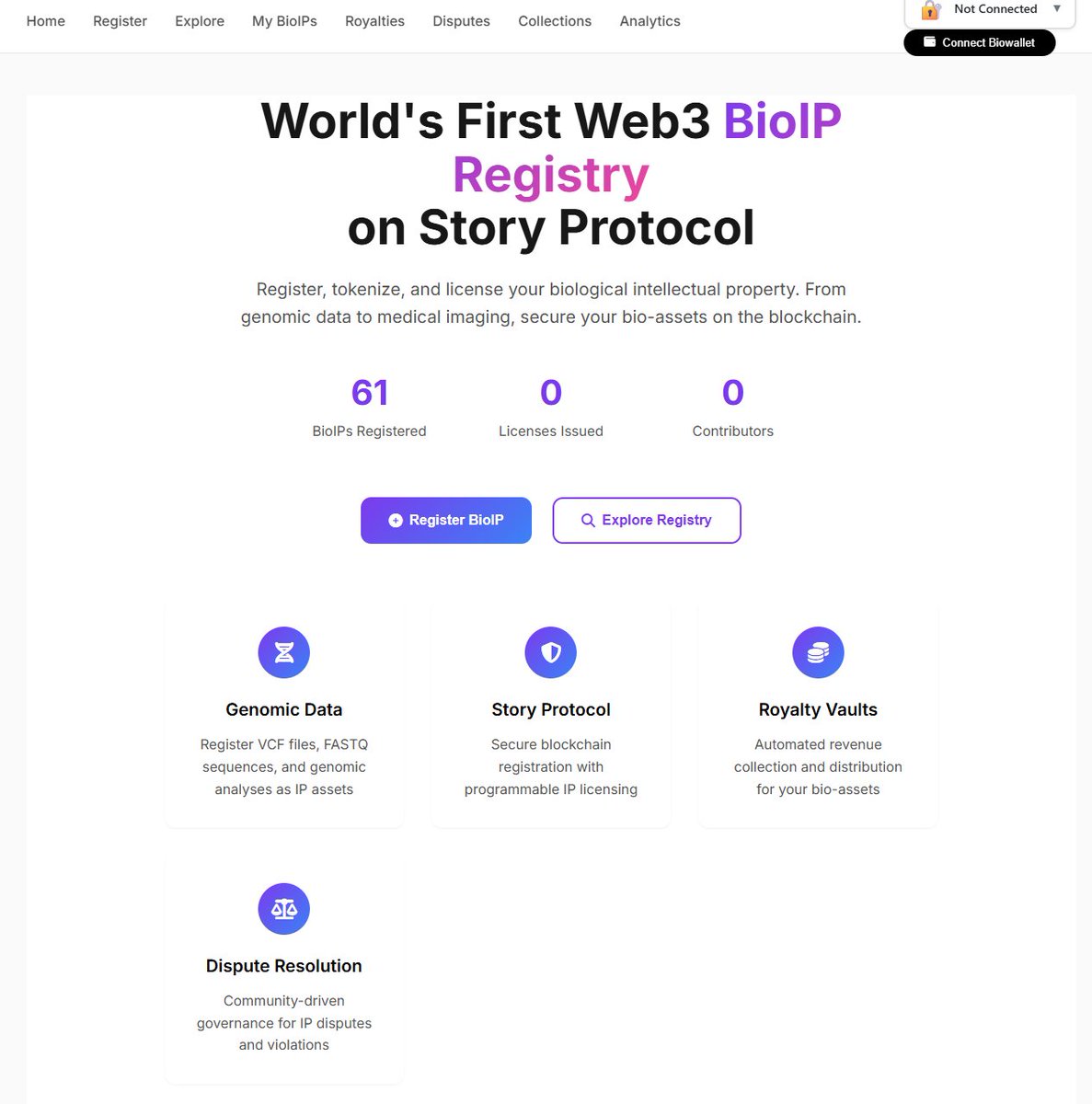
A good example is the BioIP initiative introduced by @genobank_io . It is fascinating to see how even genomic data like personal DNA can be registered as an IP asset, licensed for research or AI model training, and structured so that contributors can receive compensation when their data is used.
This makes it feel like Story Protocol is evolving beyond just a content IP protocol and becoming a broader infrastructure for building an IP economy around real world data and creations.
It will be interesting to see what other types of data and assets eventually become part of this IP layer and what new economic models may emerge from it. The potential of IP may be much larger than we currently realize, and this could still be just the beginning.

Mar 4

Biodata is among the most valuable training data in the world.
@genobank_io enables breast cancer patients in Mexico to classify their DNA, detect risks early, and license their data for revenue.
This is what patient-owned medicine looks like. Built on Story.
1
2
26
577
🫡

People think AI data is the new oil.
But here is the real question nobody asks !! what is the question?? wait I'm telling you... the question is..
Who owns the data that trains AI?
This is where @genobank_io × @StoryProtocol becomes one of the most interesting innovations I’ve seen lately.
Genobank is building a system where genomic data (DNA data) can become programmable IP onchain.
Instead of biotech companies collecting DNA data and keeping all the value…
Your genomic dataset can become an IP asset that can be licensed to researchers, AI models, or biotech companies.
And the infrastructure making this possible?
Story Protocol.
Story turns data into programmable IP with:
• verifiable ownership
• licensing rules
• automated royalties
• onchain provenance
That means your biological data is no longer just a file.
It becomes an asset.
This is a huge shift because genomic datasets are extremely valuable for:
• medical AI
• drug discovery
• disease prediction models
• precision healthcare
Yet today most people who generate the data earn nothing.
Genobank flips that model.
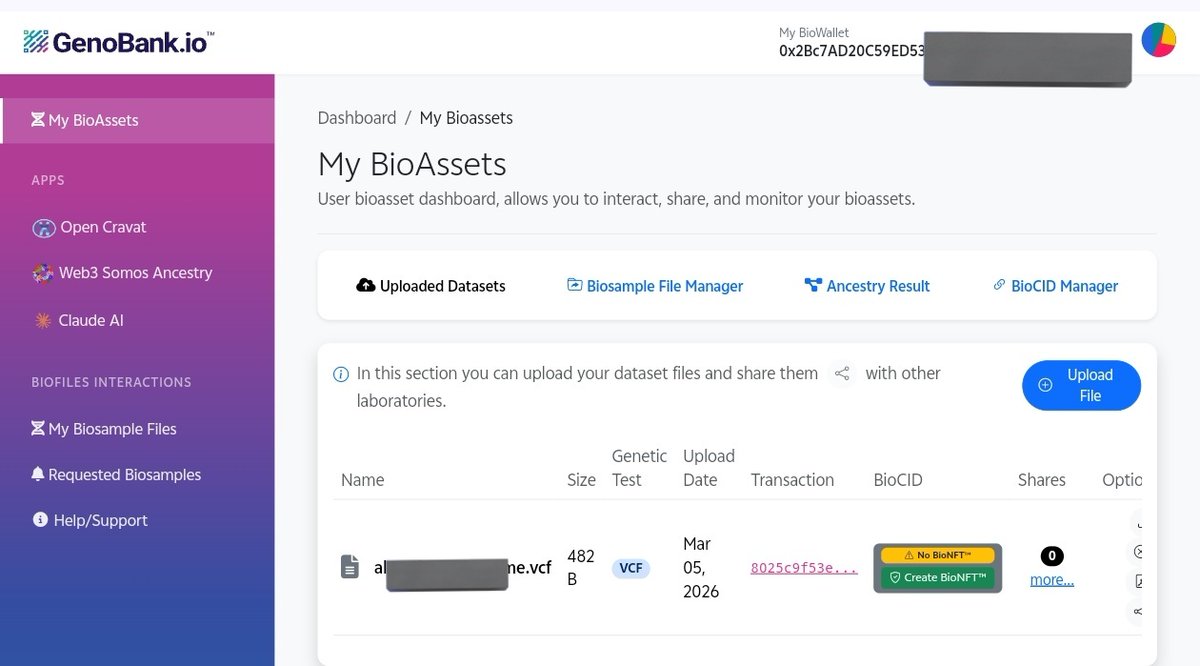
If you want to try it yourself, here’s the process 👇
1️⃣ Go to
bioip.genobank.app/
2️⃣ Connect your wallet.
3️⃣ Upload a genomic VCF dataset.
4️⃣ The platform processes the data and prepares it for BioIP registration.
5️⃣ Once approved, the dataset can become a programmable IP asset powered by Story.
Meaning the data can be licensed and monetized with transparent ownership.
I actually tried to upload a dataset myself to test the process.
But I ran into some technical issues during the upload step, so the platform returned an error.
Still, the concept is extremely interesting and I’m planning to test it again soon.
Once I manage to complete the upload successfully, I’ll share a full update.
Because the idea of turning biological data into programmable IP might be one of the most underrated innovations happening in the Story ecosystem right now.
@mushy
@BharatWormie
@ICat4you
1
3
140
Daniel Uribe, MBA 🧬 ⛓ retweeted

Mar 4
Story Protocol is all about turning intellectual property into programmable assets onchain
it makes possible to register IP, set clear rules and automate how it’s licensed and monetized
Now when you connect that vision with projects like @genobank_io it gets even more cool

13
1
41
702
Daniel Uribe, MBA 🧬 ⛓ retweeted

Mar 4
Biodata is among the most valuable training data in the world.
@genobank_io enables breast cancer patients in Mexico to classify their DNA, detect risks early, and license their data for revenue.
This is what patient-owned medicine looks like. Built on Story.
55
52
186
13,215
😂…spot on!

The problem with the eugenics companies is that they're not dystopian enough nobody wants to be caught bagholding a high IQ baby when AGI drives the value of intelligence to zero obviously these companies need to be selling high agency babies

2
97
Daniel Uribe, MBA 🧬 ⛓ retweeted

Feb 18
AI has 3 ongoing parallel races: compute, models, and data.
1. hardware -> clear winner is NVIDIA, requires massive capex to compete.
2. models -> very toe-to-toe between the big labs like OAI, Anthropic, Google, xAI, and oversea competitors. Any improvements by one lab are quickly imitated, including in the open source sector.
3. data -> there is no clear winner, and there is an insatiable appetite for it.
data is the fossil fuel for AI and it will always be the case for the foreseeable future.
In the podcast with Al I go over this and more.
Feb 18
An agentic world needs IP rails.
On @IBM’s Making Data Simple with Al Martin, Story CPO @devrelius breaks down how Story turns IP into programmable infrastructure for AI.
From “mysterious training data blobs” → provable usage, enforceable licenses, auto payments.
Listen ↓
15
15
78
7,809