
Joined April 2024
- Tweets 11
- Following 461
- Followers 262
- Likes 78
Photos and videos
Pinned Tweet

28 May 2025
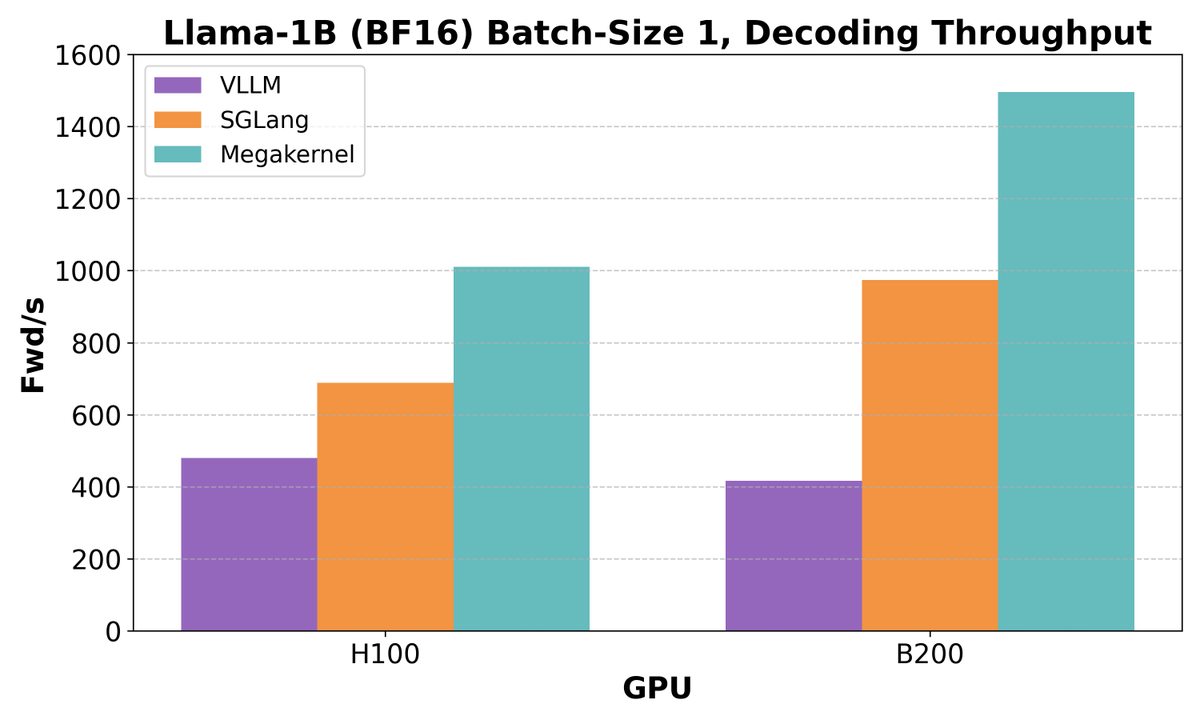
One kernel. One llama. Mega results.
Proud to share our fully fused Llama-1B megakernel! Check out the code and blog below!
27 May 2025

(1/5) We’ve never enjoyed watching people chop Llamas into tiny pieces.
So, we’re excited to be releasing our Low-Latency-Llama Megakernel! We run the whole forward pass in single kernel.
Megakernels are faster & more humane. Here’s how to treat your Llamas ethically:
(Joint with @jordanjuravsky, @stuart_sul, @OwenDugan, @dylan__lim, @realDanFu, @simran_s_arora, and @HazyResearch)
1
1
19
2,258
Dylan Lim retweeted

Feb 20
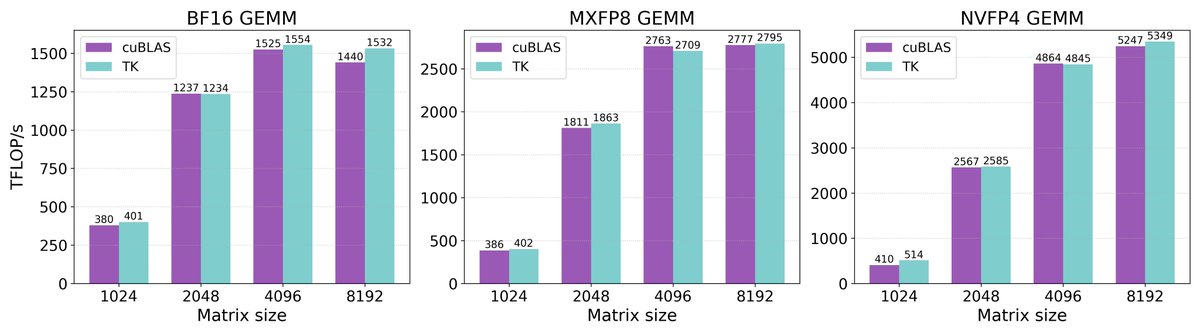
(1/7) We're releasing ThunderKittens 2.0! Faster kernels, cleaner code, industry contributions, and new state-of-the-art BF16 / MXFP8 / NVFP4 GEMMs that match or surpass cuBLAS!
Alongside this release, we’re equally excited to share some insights we learned while squeezing every last TFLOP out of Blackwell:
(with @hazyresearch & generously supported by @cursor_ai)
13
87
542
62,013
Dylan Lim retweeted

Announcing Flapping Airplanes!
We’ve raised $180M from GV, Sequoia, and Index to assemble a new guard in AI: one that imagines a world where models can think at human level without ingesting half the internet.
338
257
3,579
2,128,062
Dylan Lim retweeted
17 Nov 2025
(1/6) GPU networking is the remaining AI efficiency bottleneck, and the underlying hardware is changing fast! We’re happy to release ParallelKittens, an update to ThunderKittens that lets you easily write fast computation-communication overlapped multi-GPU kernels, along with new kernels for data, tensor, sequence, and expert parallelism!
Here’s a photo of overlapped kittens, along with things you should care about when optimizing multi-GPU kernels.
(With @simran_s_arora, @bfspector, and @hazyresearch. Generously supported by @cursor_ai and @togethercompute)

9
59
512
156,002
28 Sep 2025
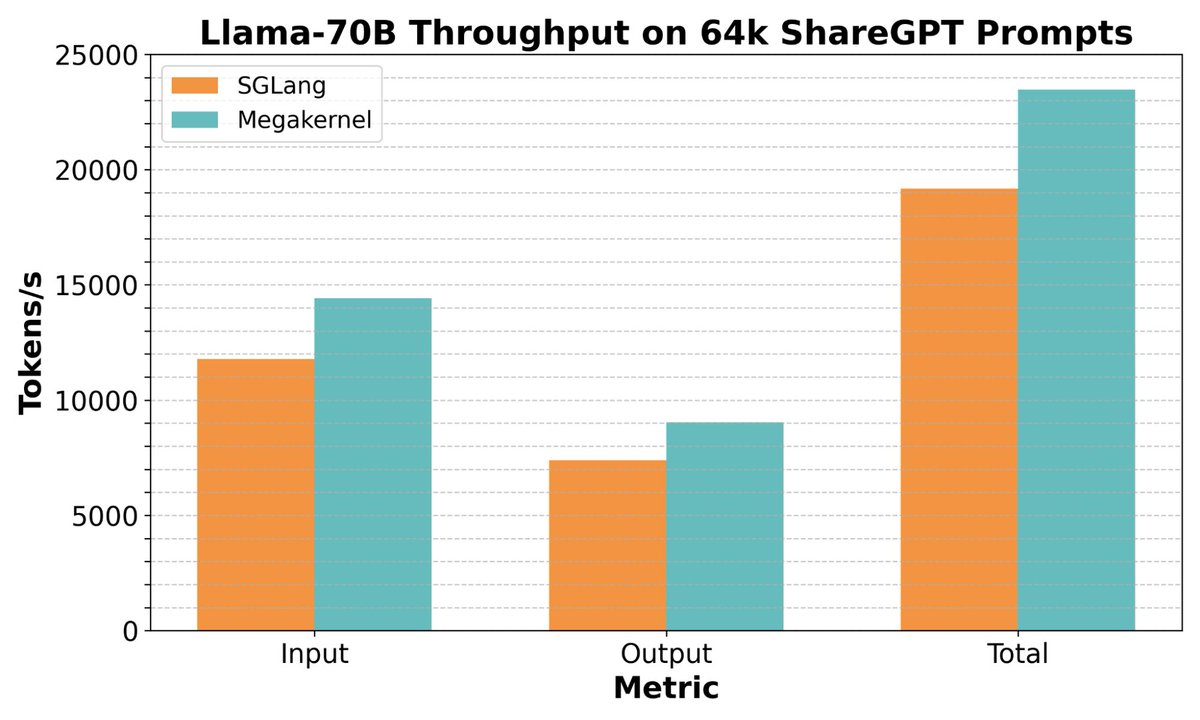
Megakernels continue with our 8-GPU Llama-70B release! Please check out below!
28 Sep 2025
(1/8) We’re releasing an 8-GPU Llama-70B inference engine megakernel! Our megakernel supports arbitrary batch sizes, mixed prefill decode, a paged KV cache, instruction pipelining, dynamic scheduling, interleaved communication, and more! On ShareGPT it’s 22% faster than SGLang.
7
400
22 Sep 2025
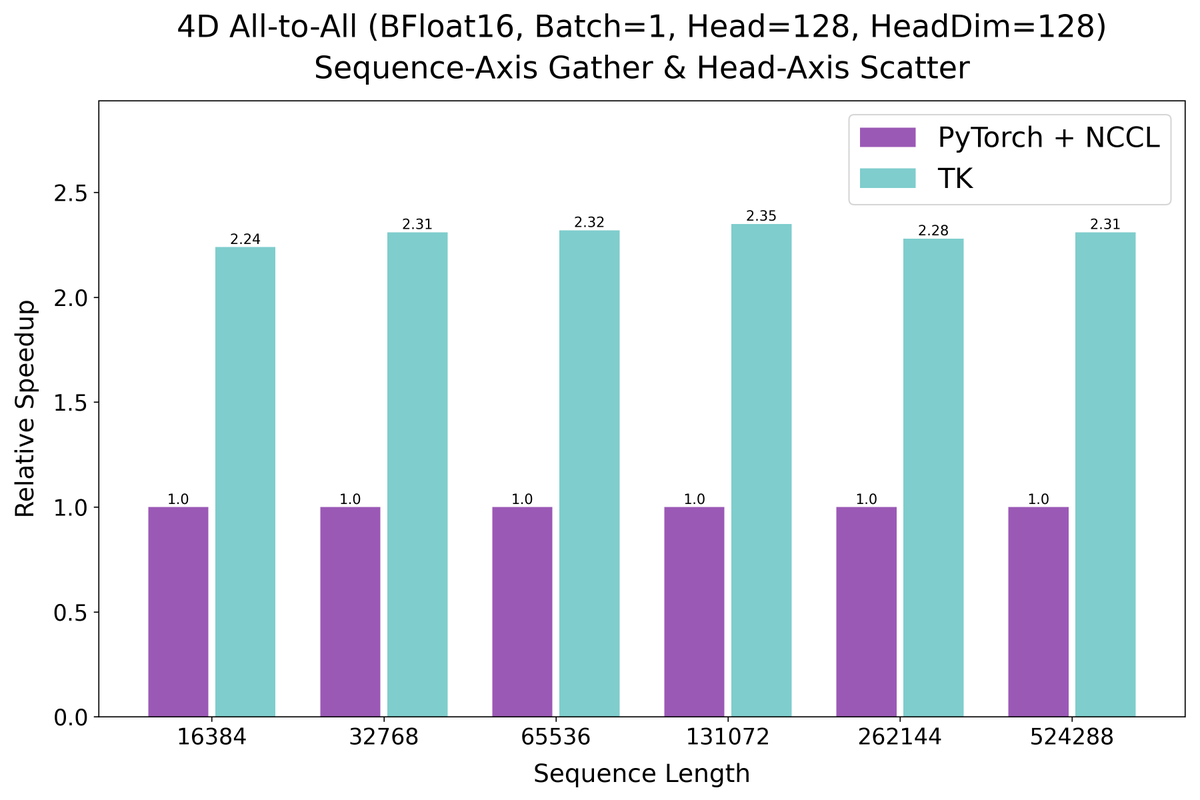
Happy to announce that multi-GPU ThunderKittens is finally here! Help your GPU's meow better by checking out the following blog!
22 Sep 2025

(1/6) We’re happy to share that ThunderKittens now supports writing multi-GPU kernels, with the same programming model and full compatibility with PyTorch torchrun.
We’re also releasing collective ops and fused multi-GPU GEMM kernels, up to 2.6x faster than PyTorch NCCL.
(Joint with @dylan__lim, @bfspector, and @HazyResearch. Generously supported by @cursor_ai)
6
597
Dylan Lim retweeted

5 Jun 2025
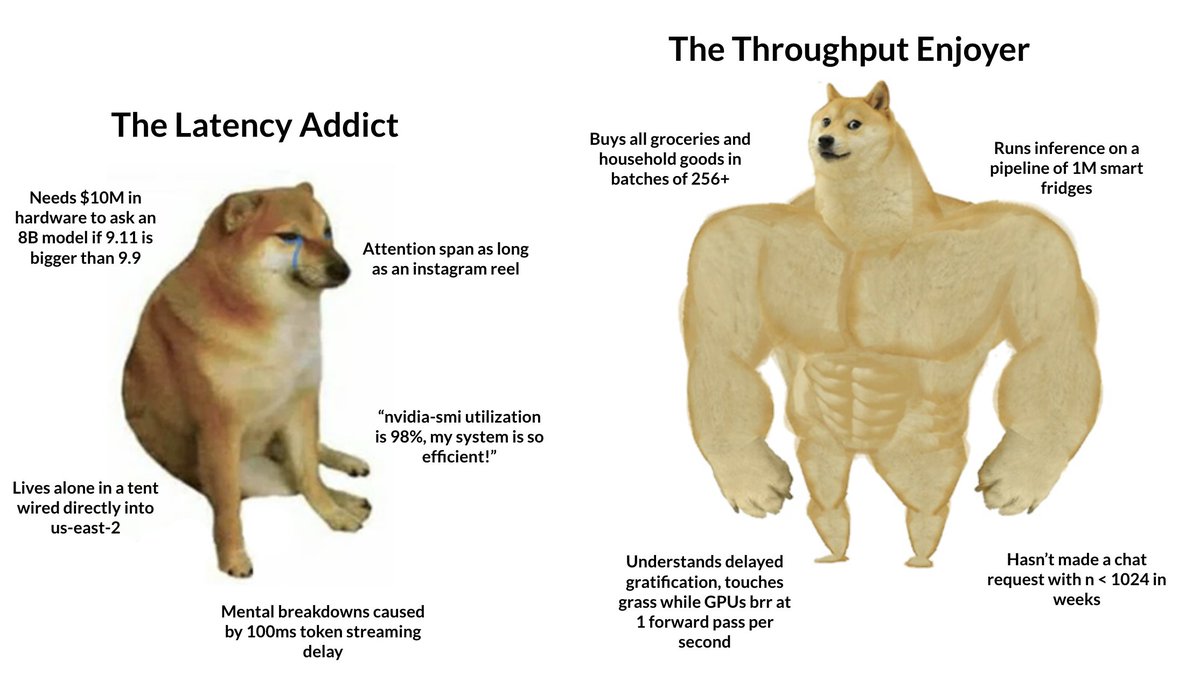
Happy Throughput Thursday! We’re excited to release Tokasaurus: an LLM inference engine designed from the ground up for high-throughput workloads with large and small models.
(Joint work with @achakravarthy01, @ryansehrlich, @EyubogluSabri, @brad19brown, @jshetaye, @HazyResearch, and @Azaliamirh)
7
47
206
46,306
Dylan Lim retweeted

27 May 2025
So so so cool. Llama 1B batch one inference in one single CUDA kernel, deleting synchronization boundaries imposed by breaking the computation into a series of kernels called in sequence. The *optimal* orchestration of compute and memory is only achievable in this way.
27 May 2025
(1/5) We’ve never enjoyed watching people chop Llamas into tiny pieces.
So, we’re excited to be releasing our Low-Latency-Llama Megakernel! We run the whole forward pass in single kernel.
Megakernels are faster & more humane. Here’s how to treat your Llamas ethically:
(Joint with @jordanjuravsky, @stuart_sul, @OwenDugan, @dylan__lim, @realDanFu, @simran_s_arora, and @HazyResearch)
62
229
2,006
268,028
24 Mar 2025
Excited to share LayoutVLM—leveraging VLMs for spatial reasoning in 3D layout generation!
18 Mar 2025

Spatial reasoning is a major challenge for the foundation models today, even in simple tasks like arranging objects in 3D space.
#CVPR2025
Introducing LayoutVLM, a differentiable optimization framework that uses VLM to spatially reason about diverse scene layouts from unlabeled assets and open-ended language instructions
1/n
1
631
15 May 2024
Had a super fun time building this out - always love working on distributed ML systems. Big thanks to @pearvc for awarding us the best startup prize at Stanford TreeHacks!
15 May 2024

(1/5) @CKT_Conner, @dill_pkl, @emilyzsh, and I are excited to introduce Shard - a proof-of-concept for an infinitely scalable distributed system composed of consumer hardware for training and running ML models!
Features:
- Data Pipeline Parallel for handling arbitrarily large models
- Algorithmic load balancing for throughput optimization
- Fault tolerance for unreliable machines
1
1
11
2,328