
Hepatologist @michiganliver @vaannarbor; #cirrhosis; encephalopathy; frailty; quality improvement; father; husband. #livertwitter Co-EIC of @HepCommJournal
Joined September 2011
- Tweets 15,388
- Following 662
- Followers 43,102
- Likes 32,072
2,893 Photos and videos








Elliot Tapper retweeted

Some brief thoughts on this study (longer reflections later) about how the frontier model vs domain-specific model conversation interacts with the broader notion of AI in clinical practice.
1. The ability to personally manipulate how models respond is remains underrated
Any trainee through the medical system will know that the way information is communicated, analyzed, and acted on can vastly differ from physician and speciality.
That aspect of communication -- what details to reinforce, what values to skip, how to communicate differential diagnoses in an objective manner -- is a function of many factors, one of which is trust in the presenter.
As each physician uses these tools to augment their own personal style of thinking, the ability to shape and structure the manner in which these tools convey answers will directly impact how effective and preferable using these tools will be.
To that extent -- frontier LLMs, which offer at least some degree of steering model outputs via custom instructions, projects, etc. -- will naturally have an advantage. Allowing clinicians to manipulate these workflows such that they can better intuit where the tools may fail vs be useful will be huge. [0]
[0] x.com/samarthrawal/status/20…
2. LLMs are superhuman persuaders
"i expect ai to be capable of superhuman persuasion well before it is superhuman at general intelligence" - Sam Altman
We have definitely crossed this point, at least with using LLMs to answer clinical questions: for a particular question, chances are there will be some paper on some data that can positively affirm the implicit bias within that question.
And since models are remarkably capable at synthesizing complex information into a cohesive narrative, they will be able to give a very reasonable-sounding answer to a clinical question, whether or not it is truly applicable in that scenario (ie, has reasonable external validity).
Relying on personal clinical "preference" to select an LLM tool of choice can therefore be quite dangerous, because a style of answer may not correlate with the applicability of the answer.
This is something I try to be cognizant of whenever I use LLMs, particularly in the clinical setting, in order to be watchful against this error mode.
([1] Related slides - How I use LLMs in Clinical Research & Practice - x.com/samarthrawal/status/19…)
3. The boundary between answering a question and clinical reasoning is blurry
even before the adoption of LLMs, there was always a bit of grey area between looking up information and clinical decision-making. For example: an article on UpToDate will give you basic facts and data about a particular condition, but also segue into next steps (thereby helping clinicians reason about problems). By itself, this is not a bad thing - in fact, it can be very valuable.
Now though, tools are able to remarkably synthesize facts, studies, empiric results, and clinical guidelines into a single, cohesive answer.
Where does answering a question stop, and making a decision based on explicit and implicit phrasing of the clinical question end? This undoubtedly reshapes how we think about clinical practice, and therefore being aware of this process will be extremely important to clinicians moving forward, in my opinion.
(some more on this topic here - [2] samrawal.com/blog/augmenting…)
Jun 12

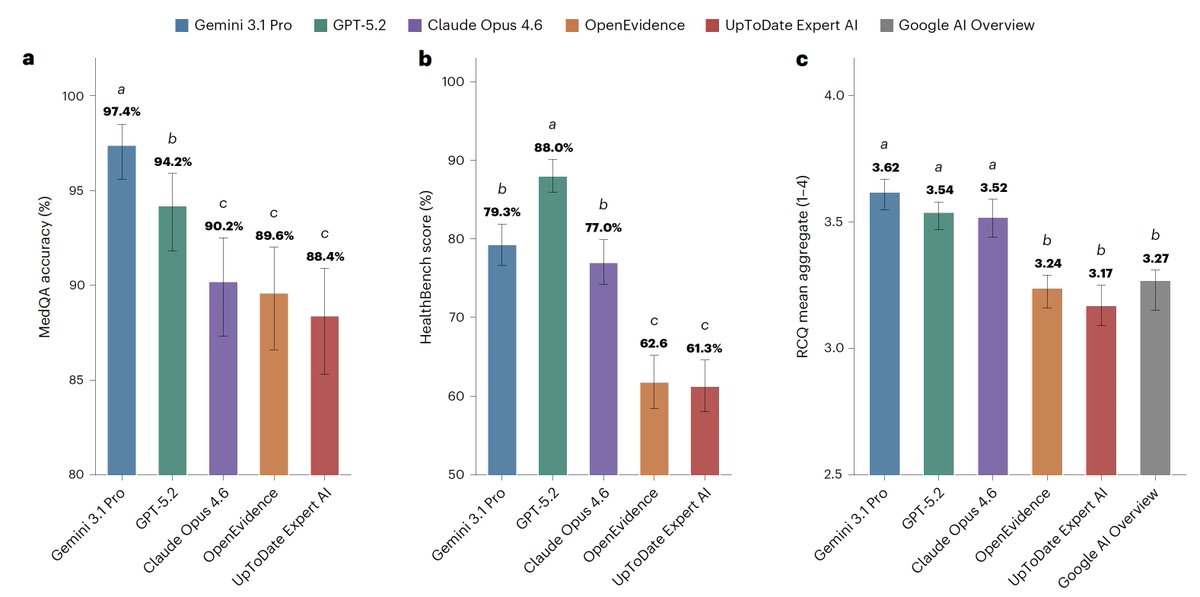
For medical information, general AI frontier models (Google, OpenAI, Anthropic) outperformed specialized @EvidenceOpen and @UpToDate as assessed by 12 US clinicians, randomized and blinded to which model and extensive testing/benchmarks. This was not anticipated. @NatureMedicine
nature.com/articles/s41591-0…
1
2
23
4,550
Elliot Tapper retweeted

We are back! 🚨🚨🚨new pod
GLP drugs from lizard spit to liver fibrosis
Check it out here or on your preferred pod catcher
podcasts.apple.com/au/podcas…
3
8
860

Jun 13
There are too many studies in the medical literature comparing AI models
It doesn’t add anything meaningful and these models are often obsolete or replaced by the time of publication
Jun 12
For medical information, general AI frontier models (Google, OpenAI, Anthropic) outperformed specialized @EvidenceOpen and @UpToDate as assessed by 12 US clinicians, randomized and blinded to which model and extensive testing/benchmarks. This was not anticipated. @NatureMedicine
nature.com/articles/s41591-0…
2
6
39
5,720
Elliot Tapper retweeted

Jun 11
The NEJM just joined Roon and to celebrate this question surfaced: what is your favorite NEJM article. Lots of great answers were posted covering all different aspects of medicine. I went with Besarab's normalization of Hct paper. I was just a resident when it came out but it left a deep suspicion of the facts my attending were teaching me and gave me tremendous respect for the power of a RCT to cut through bull shit and provide clarity.
roon.com/doctors/rounds/YJkR…
2
4
18
3,836
Elliot Tapper retweeted

🎉 Enhorabuena @JesusMBanales por recibir el Premio Mark R. Clements 2026, la máxima distinción otorgada por @curecc (EEUU).
El Dr. Bañales es investigador Ikerbasque en @biogipuzkoa y en el Centro de Investigación Biomédica en Red de Enfermedades Hepáticas y Digestivas (CIBEREHD), además de miembro de nuestro Comité Médico y Científico.
Este reconocimiento destaca su liderazgo internacional y sus contribuciones pioneras a la investigación del cáncer de vías biliares, una labor que está impulsando avances clave en el conocimiento, diagnóstico y tratamiento de esta enfermedad. 🔝
Desde ATUVIBI, nos sentimos orgullosos de contar con el asesoramiento de profesionales de referencia como el Dr. Bañales, cuyo compromiso con la investigación contribuye a mejorar el futuro de los pacientes con tumores de vías biliares. 💚
#TumoresDeLasVíasBiliares #Colangiocarcinoma #InvestigaciónOncológica #Confía

2
10
34
6,450
Elliot Tapper retweeted

Jun 10
Just published in @HEP_Journal from NASH CRN. 200 IU/d of vit E is as good as 800 IU/d in improving liver injury markers in MASLD/ suspected MASLD. VitE for MASH is a neglected beauty @AASLDtweets @HepCommJournal

2
13
34
4,133
Jun 7
This
Jun 6

EMR note templates suck
Just start with a blank page and type what you saw, did, and thought about
1
7
4,418
Jun 7
👇 on addressing alcohol use disorder with empathy
Jun 6

Denise- I say this to everyone. The thing that was killing me more than anything else was not the crack it was the vodka. Alcohol is the worst drug of them all. I was drinking a handle a day while smoking crack. It’s the hardest to stop and the easiest to start. It’s the only drug (outside of benzos) you can die withdrawing from. And I know why you drink. You drink because at first it works. Don’t want to feel the way you feel. Well for people like us we know the answer. But you can stop- but rarely alone. Ask for help. Get honest with someone you trust and tell them you need help. We are never alone. I see you. I hear you. The one thing we all have in common is pain. We think we are alone but we are not. I have faith in you. I really do and I don’t even know you. It’s so much better on the other side.
1
14
6,803
Jun 6
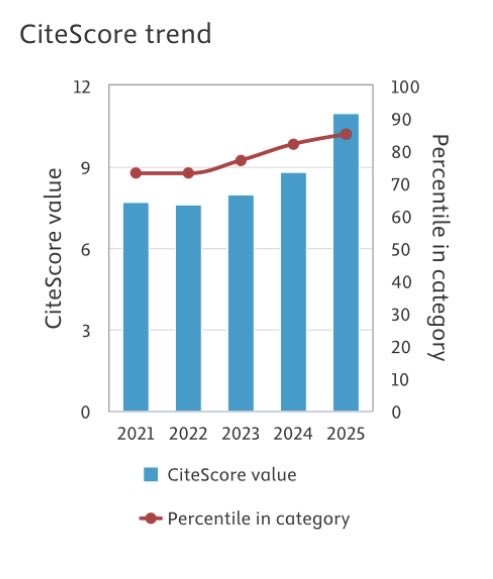
Citescore is an alternative metric to the clarivate impact factor (coming out soon)
Here is what is happening at hep comm
With many thanks to those who submit, review, and enjoy our publication
1
12
1,720
Jun 6
The lived experience of dialysis
2 in 3 have chronic pain
1 in 2 suffer from muscle cramps
Supportive care - palliative care - needs strengthening with interventions proven to address these needs
pubmed.ncbi.nlm.nih.gov/4218…
4
926
Elliot Tapper retweeted

Jun 6
🎉 Join us in celebrating the #AASLD 2026 Distinguished Award recipients!
Learn more about their remarkable contributions and accomplishments in #hepatology: bit.ly/4vzuhrN




1
5
22
2,223
Elliot Tapper retweeted

Jun 5
The #LEECenter administers the Leonidas Berry Health Equity Research Award, supporting actionable science to reduce health/healthcare disparities. Consider donating to help fund grantees like 2026 recipient @LaurenNephewMD.
➡️ gi.org/donate
#ACGInstituteWeek

2
8
984
Elliot Tapper retweeted

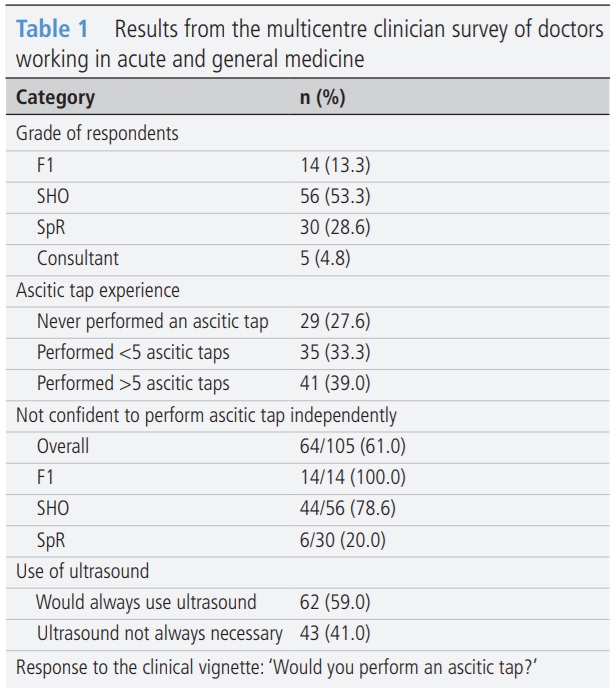
🟡 Who is doing the tap?
Diagnostic paracentesis should be performed early in patients admitted with cirrhosis ascites — but this multicentre audit and trainee survey highlights important gaps.
📋 105 doctors surveyed
⚠️ 61% not confident to perform an ascitic tap independently
🩺 Only 51.4% would perform a tap in the clinical vignette
🕒 207 admissions audited
⏱️ Median time to paracentesis: 10 h 51 min
❌ No centre met the 6-hour standard
Delays correlated with longer waits for clerking, antibiotics and specialist review. A clear call for earlier training, better awareness and system-level pathways to improve care for patients with decompensated cirrhosis.
🔗 fg.bmj.com/content/early/202…
#FrontlineGastroenterology #Hepatology #Cirrhosis #MedEd #PatientSafety #LiverTwitter
@basl_events @heppharm @livernursing @LiverAHPs @Liver4Lifeuk @f4liverresearch @IQILS_Liver @LiverTrust @EASLedu @EASLnews @BritSocGastro @BavenoCoop @BCLC_group @ILCAnews @APASLnews @liverfellow @my_ueg @UKCPAGastro
@PhilSmithIsBack @OTavabie @dr_aditi_kumar @TrevorTabone @eathar_s @IrenePerezMD @KGananandan @zare_benjamin @medicalreg @dtleiberman @BSGtrainees @drkeithsiau @ebtapper @DrLChina @acv69cardenas @GeriKeane @jamesbmaurice @ClinicLiver
1
10
26
2,826
Elliot Tapper retweeted
It is of great interest to evaluate if PNPLA3 G-allele modifies response to MASH therapies. In our @HEP_Journal article, histological response to effruxifermin (FGF21 agonist) is PNPLA3 genotype agnostic. Await sema, tirza, and resmetirom data.

1
10
23
2,972
Elliot Tapper retweeted
Jun 2
Grantee: Adjoa Anyane-Yeboa, MD, MPH | @AdjoaGIMD
2024: Junior Faculty Development Award
2024: K08 Career Development Award, NCI
2025: Clinical Research Leadership Program

1
3
12
1,320
Elliot Tapper retweeted

Boom - @UMichGIHep strikes again
Well done Nik on your @AmCollegeGastro CDA and ongoing success.
Equally important - Nik is also super fun to hang out with.
Jun 2

Grantee: Nikhilesh R. Mazumder, MD, MPH
2022: Junior Faculty Development Award
2024: K23 Career Development Award, NIDDK
2025: Clinical Research Leadership Program

1
11
1,474
Jun 3
Great doctor. Brilliant
@AmCollegeGastro ROI for real
Jun 2
Grantee: Nikhilesh R. Mazumder, MD, MPH
2022: Junior Faculty Development Award
2024: K23 Career Development Award, NIDDK
2025: Clinical Research Leadership Program
2
2
21
4,133
Elliot Tapper retweeted
12 Aug 2020
What is asterixis?
👋Described~60 yrs ago by Adams/Foley
👋Methods:60pts w/impending hepatic coma vs controls
👋Flapping flexion/extension, best @ the🤚but happens even 2 the 👁️lids! Has intervening tremor (mini-asterixis)
Look 4 it while checking handgrip!
#livertwitter
1/4




12
163
405
Elliot Tapper retweeted

Excellent exhibit on the Etruscans @legionofhonor SF. This is a bronze model to scale of a sheep’s liver. The writing in Etruscan helps with the art of reading entrails to divine the future. @ebtapper @norahterrault


1
3
1,345
Elliot Tapper retweeted

May 28
🚨Alert for new research on one of public health's most overlooked measurement problems — and the numbers are hard to ignore. 🚨
Across 182 countries, we examined how each defines a 'standard drink.' The short answer: most don't.

3
13
1,519