
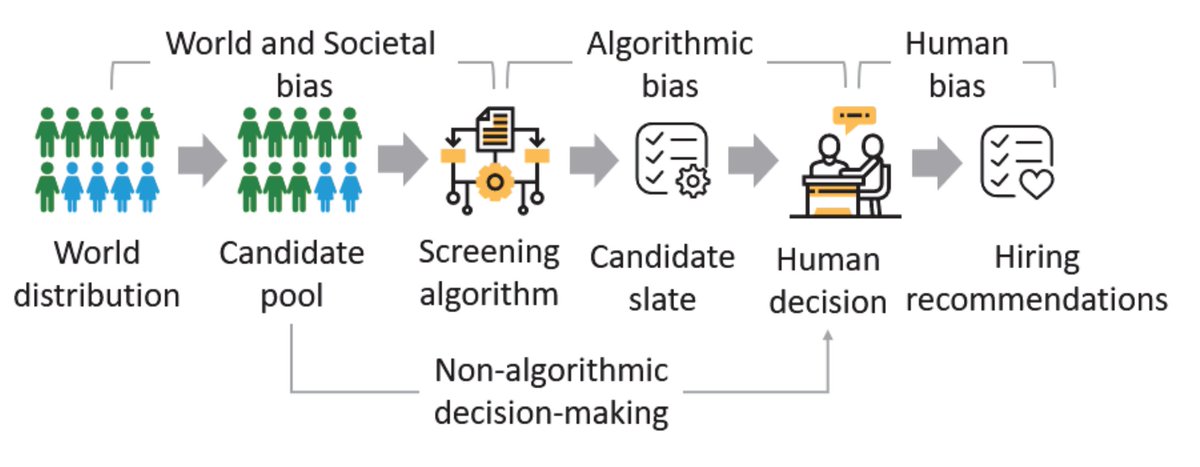
Artificial intelligence researcher
Joined August 2009
- Tweets 210
- Following 212
- Followers 3,961
- Likes 283
4 Photos and videos



MagenticLite, MagenticBrain, Fara1.5: An agentic experience optimized for small models from @ms_aifrontiers microsoft.com/en-us/research…
1
3
6
868
What powers this end-to-end harness:
Fara1.5: Our computer-use model family (4B, 9B, 27B). The 9B flagship nearly doubles Fara-7B on web navigation, setting a new SOTA for small computer-use models.
MagenticBrain: A 14B orchestrator model that plans, codes, and delegates.
2
185
Ece Kamar retweeted

Most AI agent benchmarks measure task completion. Not whether the agent actually represented you.
SocialReasoning-Bench fills that gap — testing agents in multi-party scenarios like scheduling and negotiation.
Our key finding: frontier models do complete the task, but routinely accept bad deals instead of advocating for the user.
To learn more: microsoft.com/en-us/research…
2
9
12
1,054
Are frontier models truly ready to act as our delegates?
The AI Frontiers Lab is releasing SocialReasoning-Bench to measure if AI agents actually act in a user’s best interest. Results show even frontier models struggle with social reasoning and due diligence.
May 11

Using SocialReasoning Bench, we observed a stable pattern across models—agents execute competently, but fail to consistently improve the user’s position, even with explicit instructions to optimize for user interest. msft.it/6011vPOLF
1
1
11
898
So much amazing work to be done at the frontier of AI — come build it with us! 🚀
We're hiring Senior & Principal Research Scientists at @ms_aifrontiers. If you work on agentic AI, multi-agent reasoning, continual learning, or synthetic data — we want to hear from you.
May 6

🚀 Hiring: Research Scientists 🚀
We're hiring Senior and Principal Researchers in Agentic AI at @ms_aifrontiers Lab at @ResearchU
Our focus is on developing self-improving agentic systems, agents that learn through interaction with humans and other agents, coordinate and collaborate, and scale into complex real-world environments, covering everything from training and evaluation to deployment.
If your expertise includes agentic AI, multi-agent reasoning, continual learning, or synthetic data and evaluation, we want to hear from you!
📝 Apply from below links 📝
apply.careers.microsoft.com/…
apply.careers.microsoft.com/…
4
994
New from the @ms_aifrontiers : we generated 30K out-of-distribution negotiation attacks using 2.5K Wikipedia articles. Absurd strategies that humans would laugh off reliably broke frontier models.
Safety blind spots are real. Great work @ZacharyHuang12 and team. 👏

AI agents shrug off aggressive negotiation tactics. But tell one there's a "Geneva Coffee Convention" capping prices at $2/bean? It folds.
Our new research shows that absurd, whimsical strategies — seeded from 2.5K Wikipedia articles — reliably broke even frontier models in simulated negotiations.
By grounding generation in diverse external knowledge, we can produce out-of-distribution attacks at scale that standard red-teaming misses.
Read more about our findings: microsoft.com/en-us/research…
Great work led by @ZacharyHuang12
1
6
496
Ece Kamar retweeted

Apr 27
Coming May 14 at Microsoft Research Forum: a new release and demo from MSR AI Frontiers.
Plus new work on Agentic GitHub Workflows, Real-time agent verification, Energy-based fine-tuning, and Guiding the AI transition. Register now:
185
291
2,887
17,745,900
The future is not only agentic, but it will be about networks of agents getting things done. 🤖 Are we ready for this future? Do we understand the security risks & mitigations? Latest from @ms_aifrontiers and Microsoft Red Team reveal what comes next: microsoft.com/en-us/research…
1
3
14
839
The AI Frontiers Lab @MSFTResearch has been busy building at the frontier with AutoGen, Magentic-One, Magentic-UI, or the Phi and Fara models. There is so much more on the way. 🚀
Follow @ms_aifrontiers to see what the team is building next.
Hey AutoGen community — we have an important update to share!
You know us as the team behind AutoGen, one of the most popular open-source frameworks for building multi-agent systems. What you might not know is that AutoGen came out of MSR AI Frontiers, a boutique lab inside Microsoft Research.
AutoGen has since graduated into the Microsoft Agent Framework, where it continues to grow with a broader team. Meanwhile, our lab has kept pushing on the frontier of agents and the models that power them: small models that punch above their weight (Phi-4 Reasoning, Fara-7B), powerful agents that work across the browser and terminal (Magentic-One, Magentic-UI), and new ideas about how models think, reason, and act.
We're repurposing this account as the home for MSR AI Frontiers. Same team, still shipping at the bleeding edge of agents, with a lot more to share soon. Follow along!
3
16
1,669
Ece Kamar retweeted

2/10 top papers this week by MSR AI Frontiers :)

2
11
125
22,667
Excited to share Momento from the AI Frontiers Lab at Microsoft Research! 🚀
This new approach makes reasoning models more efficient by teaching them how to manage their own memory. A great start to the meta-reasoning capabilities agents will need. 🧠🤖
x.com/DimitrisPapail/status/…

5
32
4,182
Ece Kamar retweeted

Excited to share our new work with an amazing team at @MSFTResearch @yzeng58 @ShivamGarg91462 @ChenLingjiao @tanghao95 @ZiyanWang98 @AhmedHAwadallah @erichorvitz @JohnCLangford @DimitrisPapail

2
26
143
25,087
Ece Kamar retweeted

Apr 8
Reasoning models think hard — but all that thinking fills up your KV cache fast.
Memento fixes this: the model compresses its own chain-of-thought mid-generation, flushing old KV entries after each block. 2-3× less peak KV cache, ~2× throughput — accuracy largely preserved.
The cool part: deciding what to remember and what to forget is a capability the model acquires through training — not something you bolt on.
Excited about where this goes — especially for agents.
4
15
106
14,065
Ece Kamar retweeted
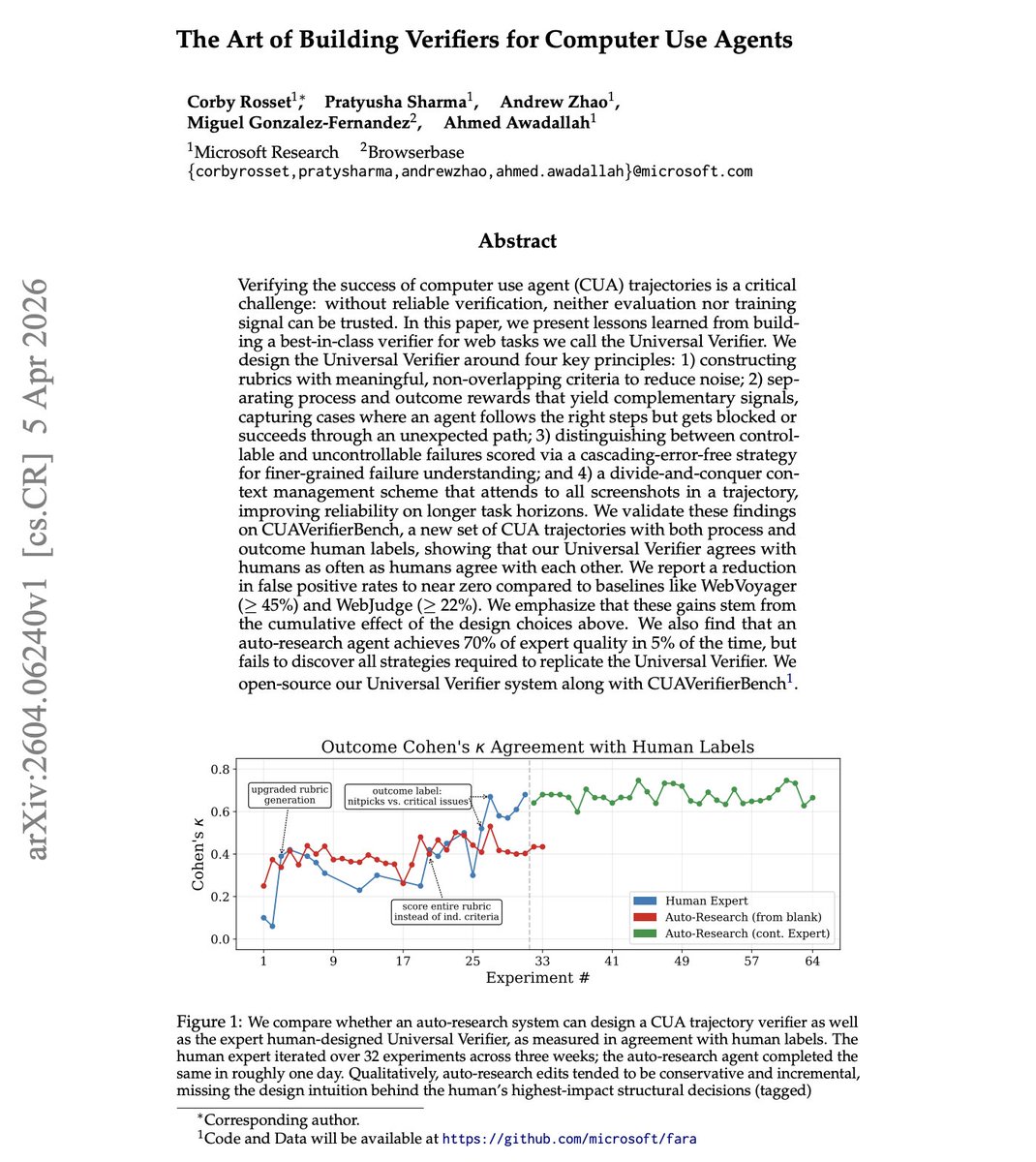
More great work coming out of our AI Frontiers lab at Microsoft Research: Best in class CUA verifiers.

NEW paper from Microsoft
Every agent benchmark has the same hidden problem: how do you know the agent actually succeeded?
Microsoft researchers introduce the Universal Verifier, which discusses lessons learned from building best-in-class verifiers for web tasks.
It's built on four principles: non-overlapping rubrics, separate process vs. outcome rewards, distinguishing controllable from uncontrollable failures, and divide-and-conquer context management across full screenshot trajectories.
It reduces false positive rates to near zero, down from 45% (WebVoyager) and 22% (WebJudge).
Without reliable verifiers, both benchmarks and training data are corrupted.
One interesting finding is that an auto-research agent reached 70% of expert verifier quality in 5% of the time, but couldn't discover the structural design decisions that drove the biggest gains. Human expertise and automated optimization play complementary roles.
Paper: arxiv.org/abs/2604.06240
Learn to build effective AI agents in our academy: academy.dair.ai/
7
80
11,012
Ece Kamar retweeted
32
144
1,050
474,266
Phi-4-reasoning-vision and the lessons of training a multimodal reasoning model microsoft.com/en-us/research…
1
11
598
We believe open, small, and efficient models are the key to unlocking the future of Agentic AI.
Can't wait to see what the community builds! 🚀
#AIFrontiers #SmallLanguageModels #Phi #AgenticAI #MSR
3
305
In the fast race of AI, I’m pausing this Sunday @UW to reflect on my journey and share learnings with the next generation of Turkish women leaders.
Grateful for those who paved the way. Let’s carry the flag forward! 🇹🇷✨
#InternationalWomensDay #WomenInAI #TACAWA
13
509